牛客网题库爬虫
完整代码
import requests from urllib.parse import urlencode from multiprocessing.pool import Pool from lxml import etree headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } def get_page(page): params = { 'tpId': '80', 'tqId': str(29677 + int(page)), 'query': '', 'asc': 'true', 'order': '', 'page': page # 1 begin } base_url = 'https://www.nowcoder.com/ta/review-frontend/review?' url = base_url + urlencode(params) f = open('save.md','a+', encoding='utf-8') try: resp = requests.get(url, headers=headers) print (url) if resp.status_code == 200: selector = etree.HTML(resp.text) question = '### ' + str(page) + '、' + ''.join(selector.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[2]//text()')).replace('\n','').strip() + '\n' answer = selector.xpath('/html/body/div[1]/div[2]/div[2]/div[2]/div[1]//text()') answer = "".join(answer) answer = '```\n' + answer.replace('\n','').strip() + '\n```\n' f.write(question + answer) f.close() except Exception as e: print (e) def main(page): get_page(page) if __name__ == '__main__': # pool = Pool() # pool.map(main, [i for i in range(1,501)]) # pool.close() # pool.join() for i in range(1,501): main(i)
修改事项
打开元素审查
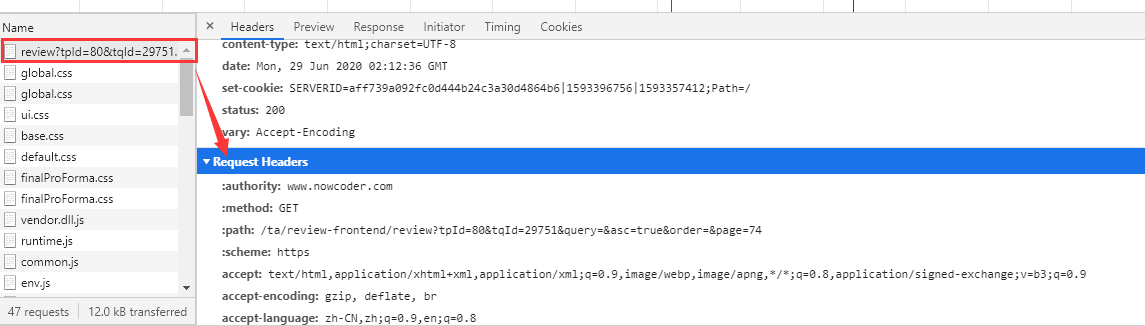
headers
headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' }
浏览器对照key值修改value就行。
params
参数设置参考
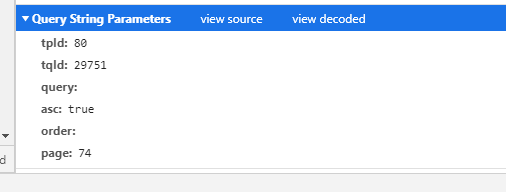
通过观察可以看到:tqld = 29677+page
params = { 'tpId': '80', 'tqId': str(29677 + int(page)), 'query': '', 'asc': 'true', 'order': '', 'page': page # 1 begin }
base_url

如果不介意题目顺序,可以把多线程的注释取消。
效果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号