
Ajax爬取百度图片
目标网址
Ajax分析
打开审查元素,查看类型为XHR的文件
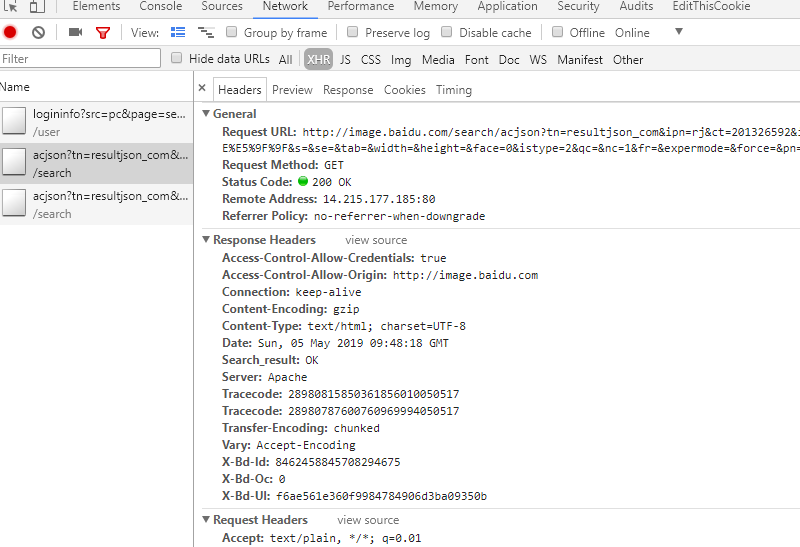
观察得到:
一 请求链接
http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%88%80%E5%89%91%E7%A5%9E%E5%9F%9F&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%E5%88%80%E5%89%91%E7%A5%9E%E5%9F%9F&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1557049697443=
二 请求报头
Host:image.baidu.com Referer:http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1557044650972_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E5%88%80%E5%89%91%E7%A5%9E%E5%9F%9F User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 X-Requested-With:XMLHttpRequest
三 请求参数
tn:resultjson_com ipn:rj ct:201326592 is: fp:result queryWord:刀剑神域 cl:2 lm:-1 ie:utf-8 oe:utf-8 adpicid: st:-1 z: ic: hd: latest: copyright: word:刀剑神域 s: se: tab: width: height: face:0 istype:2 qc: nc:1 fr: expermode: force: pn:30 rn:30 gsm:1e 1557049697443:
对比请求参数和请求链接,得到百度图片的base_url
https://image.baidu.com/search/acjson?
去掉请求参数中无效参数(对于我们现在的查询来说)
tn:resultjson_com ipn:rj ct:201326592 fp:result queryWord:刀剑神域 cl:2 lm:-1 ie:utf-8 oe:utf-8 st:-1 word:刀剑神域 face:0 istype:2 nc:1 pn:30 rn:30 gsm:1e
加载分析
注意观察请求参数的pn,多个XHR文件观察得到,参数以0开始,每加载一次就增加30,因此是一个0为首项,30为公差的函数。
网页数据获取与处理
接着打开preview看到
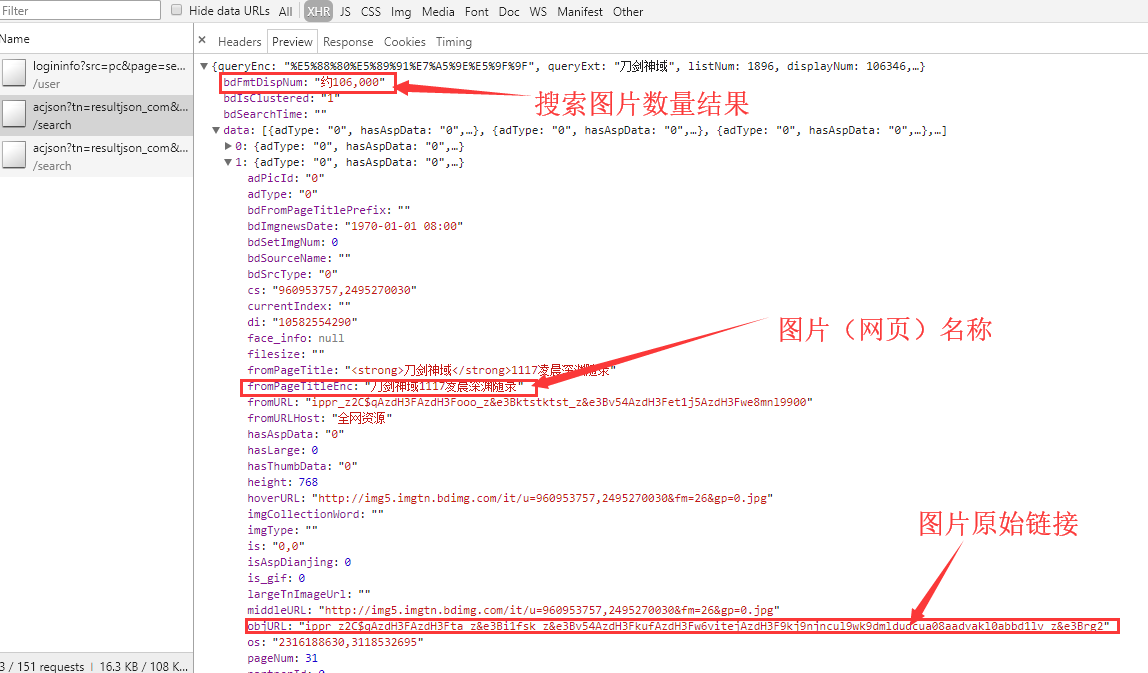
很明显objURL是有反扒机制的,链接经过加密,这里我使用了前辈现成的解密函数
引用链接:点击进入
a ='ippr_z2C$qAzdH3FAzdH3Ffb_z&e3Bftgwt42_z&e3BvgAzdH3F4omlaAzdH3FaamK8iwuzy0kbFPb4D1d0&mla' # a = '_z2C$q' str_table = { '_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/', } """ char_table = { 'w': 'a', 'k': 'b', 'v': 'c', '1': 'd', 'j': 'e', 'u': 'f', '2': 'g', 'i': 'h', 't': 'i', '3': 'j', 'h': 'k', 's': 'l', '4': 'm', 'g': 'n', '5': 'o', 'r': 'p', 'q': 'q', '6': 'r', 'f': 's', 'p': 't', '7': 'u', 'e': 'v', 'o': 'w', '8': '1', 'd': '2', 'n': '3', '9': '4', 'c': '5', 'm': '6', '0': '7', 'b': '8', 'l': '9', 'a': '0' } """ # char_table = {ord(key): ord(value) for key, value in char_table.items()} in_table = '0123456789abcdefghijklmnopqrstuvw' out_table = '7dgjmoru140852vsnkheb963wtqplifca' # 将in和out中每个字符转化为各自的ascii码,返回一个字典(dict) char_table = str.maketrans(in_table, out_table) print('char_table:',char_table) # for t in a: #解码 if True: for key, value in str_table.items(): a = a.replace(key, value) print(a) a = a.translate(char_table) print(a,end='')
程序步骤与细节
爬虫程序的总的步骤分为
- 获取网页的json格式代码
- 处理json格式代码,筛选出图片原始链接与图片名称
- 使用原始链接下载图片并保存
其中我们需要注意的点
- 获取图片名称时,处理相同名称与没有名字的图片。
- 图片名称不能违反文件命名规则。
- 获取的图片原始链为加密链接,需要解密。
代码
import requests from urllib.parse import urlencode import os from multiprocessing.pool import Pool import time headers={ 'Host': 'image.baidu.com', 'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1556979834693_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E5%88%80%E5%89%91%E7%A5%9E%E5%9F%9F', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', } def get_page(page): #请求参数 params={ 'tn':'resultjson_com', 'ipn':'rj', 'ct':'201326592', 'fp':'result', 'queryWord':'刀剑神域', 'cl':'2', 'lm':'-1', 'ie':'utf-8', 'oe':'utf-8', 'st':'-1', 'word':'刀剑神域', 'face':'0', 'istype':'2', 'nc':'1', 'pn':page, 'rn':'30', } base_url = 'https://image.baidu.com/search/acjson?' #将基本网页链接与请求参数结合在一起 url = base_url + urlencode(params) print(url) try: #获取网页代码 resp = requests.get(url, headers=headers) #返回json数据格式代码 if 200 == resp.status_code: print(resp.json()) return resp.json() except requests.ConnectionError: print('获取网页代码出现异常!') return None def decry(url): '''破解图片链接''' str_table = { '_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/', } in_table = u'0123456789abcdefghijklmnopqrstuvw' out_table = u'7dgjmoru140852vsnkheb963wtqplifca' # 将和out中每个字符in转化为各自的ascii码,返回一个字典(dict) char_table = str.maketrans(in_table, out_table) # print(char_table) # for t in a: # 解码 if True: for key, value in str_table.items(): url = url.replace(key, value) # print(a) url = url.translate(char_table) # print(a, end='') return url n = 1 def get_image(json): if(json.get('data')): data=json.get('data') number = json.get('bdFmtDispNum') print(number) for item in data: if item.get('objURL'): imageurl = decry(item.get('objURL')) title = item.get('fromPageTitleEnc') if title == None: title = 'pic'+str(n) n = n + 1 #返回"信息"字典 yield { 'title':title, 'images':imageurl, } #文件命名规则 def replace(pic_name): pic_name = pic_name.replace('\\', '-') pic_name = pic_name.replace('/', '-') pic_name = pic_name.replace(':', '-') pic_name = pic_name.replace(':', '-') pic_name = pic_name.replace('?', '-') pic_name = pic_name.replace('?', '-') pic_name = pic_name.replace('"', '-') pic_name = pic_name.replace('“', '-') pic_name = pic_name.replace('<', '-') pic_name = pic_name.replace('>', '-') pic_name = pic_name.replace('|', '-') return pic_name def save_page(item): #文件夹名称 file_name = '刀剑神域全集' if not os.path.exists(file_name): os.makedirs(file_name) #获取图片链接 response=requests.get(item.get('images')) #储存图片文件 if response.status_code==200: pic_name = item.get('title') pic_name = replace(pic_name) file_path = file_name + os.path.sep + pic_name + '.jpg' #判断图片是否已经被下载过 if not os.path.exists(file_path): with open(file_path, 'wb') as f: f.write(response.content) else: print('已经下载', file_path) def main(page): json = get_page(page) for item in get_image(json): print(item) save_page(item) #time.sleep(3) if __name__ == '__main__': pool = Pool() pool.map(main, [i for i in range(0, 1800, 30)]) pool.close() pool.join()
需要修改搜索结果的话,直接修改word关键词就行,或者你自己也要写一个函数,输入搜索的关键词。

