
词嵌入
什么是embedding?什么是word embedding?
embedding就是一个映射,将一个空间映射到另一个空间。
行为:word embedding就是把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。Embedding在数学上表示一个maping, f: X -> Y, 也就是一个function,其中该函数是injective(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)。那么对于word embedding,就是将单词word映射到另外一个空间,其中这个映射具有injective和structure-preserving的特点。
动机:
①distributed representation使单词的表征在数学上有捕捉单词间关系的可能。
原来单词的one-hot表示不可能捕捉到不同单词(word type)之间的关系。因为one-hot之间是正交的。
可以实现”北京-中国 = 巴黎-法国”。
说明embedding很好的捕捉到了语义和语法。语义相似的词有相似embedding
②降维,提高计算效率。one-hot表达太过稀疏,低效。embedding后的表达是稠密的。
③嵌入到连续向量空间,具有更强的表征能力。(算是对①的解释补充)
原来的one-hot码的每一维上只能是0或者1,表达力弱。(可以表达某个属性有或者没有)
连续的向量的每一维上都是实数,可以表征力强(可以表达某属性有多少)
假如一只宝可梦的战斗力是用one-hot编码,0是强,1是弱。喷火龙很强,战斗力是1;超梦更强,战斗力也是1。如果没看过宝可梦的人,看着这两个的数值面板,他会觉得应该一样强,至少他没法确定谁更强。
那如果是用连续的实数来表达,区分宝可梦的战斗力的强弱程度就很简单了。

word embedding主流方法
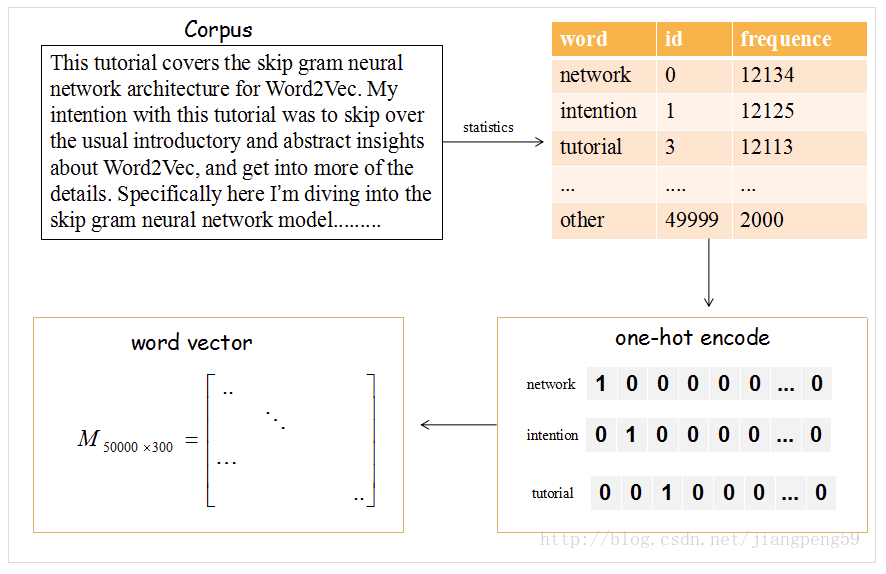
那么这个Embedding矩阵M怎么获得呢??
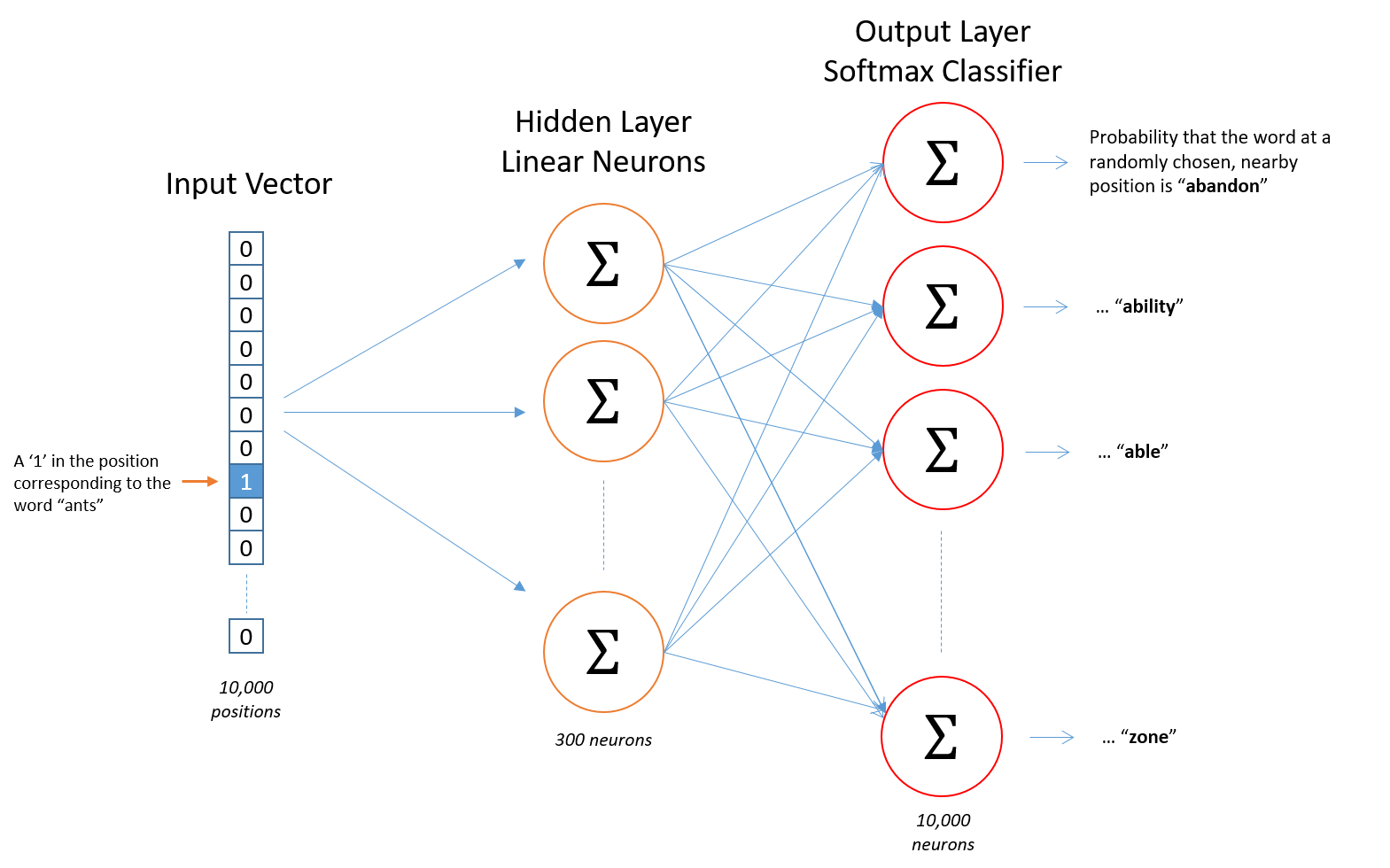
word2vec-Skip-Gram模型
原论文有两篇:
Efficient Estimation of Word Representations in Vector Space
这篇讲了加快训练的方法:Distributed Representations of Words and Phrases and their Compositionality
在Skip-gram模型中,我们会随机初始化它,然后使用神经网络来训练这个权重矩阵。
Glove
原论文:Glove: Global Vectors for Word Representation
NLP中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert

 浙公网安备 33010602011771号
浙公网安备 33010602011771号