.Net栈和堆详解
什么是栈堆
在计算机领域,堆栈是一个不容忽视的概念,栈堆是两种数据结构。堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除。要点:堆,队列优先,先进先出(FIFO—first in first out);栈,先进后出(FILO—First-In/Last-Out)。
堆栈是一个在计算机科学中经常使用的抽象数据类型。堆栈中的物体具有一个特性: 最后一个放入堆栈中的物体总是被最先拿出来, 这个特性通常称为后进先出(LIFO)队列。
栈和堆的区别
堆栈空间分配
栈(操作系统):由操作系统自动分配释放,存放函数的变量值,局部变量的值等等,其操作方式类似于数据结构中的栈;
堆(操作系统):一般由开发者分配释放,若不释放,程序结束时可能会有OS回收,分配方式倒是类似于链表;
堆栈的缓存方式
栈使用的是一级缓存,通常是被调用时处于储存空间,调用完后自动释放;
堆使用的是二级缓存,生命周期有虚拟机的垃圾回收算法来决定(并不一定成为孤儿对象就被立即释放)。所以调用这些对象的速度相对来得慢一些;
堆栈数据结构的区别
堆(数据结构):堆可以看做是一棵树;例如:堆排序;
栈(数据结构):一种先进后出的数据结构;
区别介绍
栈负责保存我们的代码执行(或调用)路,而堆则负责保存对象(或者说数据)的路径。
可以将栈想象成一堆从顶向下堆叠的盒子。当每调用一次方法时,我们将应用程序中所要发生的事情记录在栈顶的一个盒子中,而我们每次只能够使用栈顶的那个盒子。当我们栈顶的盒子被使用完之后,或者说方法执行完毕之后,我们将抛开这个盒子然后继续使用栈顶上的新盒子。堆的工作原理比较相似,但大多数时候堆用作保存信息而非保存执行路径,因此堆能够在任意时间被访问。与栈相比堆没有任何访问限制,堆就像床上的旧衣服,我们并没有花时间去整理,那是因为可以随时找到一件我们需要的衣服,而栈就像储物柜里堆叠的鞋盒,我们只能从最顶层的盒子开始取,直到发现那只合适的。
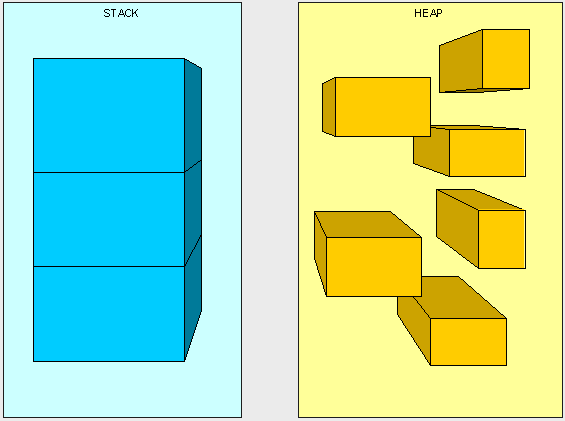
以上图片并不是内存中真实的表现形式,但能够帮助我们区分栈和堆。
栈是自行维护的,也就是说内存自动维护栈,当栈顶的盒子不再被使用,它将被抛出。相反的,堆需要考虑垃圾回收,垃圾回收用于保持堆的整洁性,没有人愿意看到周围都是赃衣服,那简直太臭了!
当我们的代码执行的时候,栈和堆中主要放置了四种类型的数据:值类型(Value Type),引用类型(Reference Type),指针(Pointer),指令(Instruction)。
1.值类型
bool,byte ,char,decimal,double,enum,float,int,long,sbyte,short,struct,uint,ulong,ushort
2.引用类型
class,interface,delegate ,object ,string
3.指针
在内存管理方案中放置的第三种类型是类型引用,引用通常就是一个指针。我们不会显示的使用指针,它们由公共语言运行时(CLR)来管理。指针(或引用)是不同于引用类型的,是因为当我们说某个事物是一个引用类型时就意味着我们是通过指针来访问它的。指针是一块内存空间,而它指向另一个内存空间。就像栈和堆一样,指针也同样要占用内存空间,但它的值是一个内存地址或者为空。

如上图,可以帮我们更加好理解堆和栈,在装箱和拆箱中也能体现
堆栈使用情况
1. 引用类型总是放在堆中。
2.值类型和指针总是放在它们被声明的地方。
就像我们先前提到的,栈是负责保存我们的代码执行(或调用)时的路径。当我们的代码开始调用一个方法时,将放置一段编码指令(在方法中)到栈上,紧接着放置方法的参数,然后代码执行到方法中的被“压栈”至栈顶的变量位置。通过以下例子很容易理解...
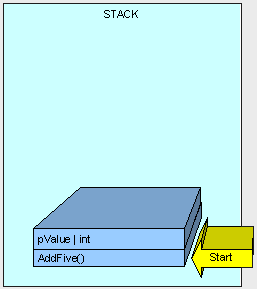
定义一个方法
public int AddFive(int pValue) { int result; result = pValue + 5; return result; }
现在就来看看在栈顶发生了些什么,记住我们所观察的栈顶下实际已经压入了许多别的内容。
首先方法(只包含需要执行的逻辑字节,即执行该方法的指令,而非方法体内的数据)入栈,紧接着是方法的参数入栈。

接着,控制(即执行方法的线程)被传递到堆栈中AddFive()的指令上

当方法执行时,我们需要在栈上为“result”变量分配一些内存

方法执行完成,然后方法的结果被返回。

通过将栈指针指向AddFive()方法曾使用的可用的内存地址,所有在栈上的该方法所使用内存都被清空,且程序将自动回到栈上最初的方法调用的位置。

在这个例子中,我们的"result"变量是被放置在栈上的,事实上,当值类型数据在方法体中被声明时,它们都是被放置在栈上的。
值类型数据有时也被放置在堆上。记住这条规则--值类型总是放在它们被声明的地方。好的,如果一个值类型数据在方法体外被声明,且存在于一个引用类型中,那么它将被堆中的引用类型所取代。
来看另一个例子:
//假如我们有这样一个MyInt类(它是引用类型因为它是一个类类型): public class MyInt { public int MyValue; } //然后执行下面的方法: public MyInt AddFive(int pValue) { MyInt result = new MyInt(); result.MyValue = pValue + 5; return result; }
就像前面提到的,方法及方法的参数被放置到栈上,接下来,控制被传递到堆栈中AddFive()的指令上。
接着会出现一些有趣的现象...
因为"MyInt"是一个引用类型,它将被放置在堆上,同时在栈上生成一个指向这个堆的指针引用。

在AddFive()方法被执行之后,我们将清空...

我们将剩下孤独的MyInt对象在堆中(栈中将不会存在任何指向MyInt对象的指针!)

这就是垃圾回收器(后简称GC)起作用的地方。当我们的程序达到了一个特定的内存阀值,我们需要更多的堆空间的时候,GC开始起作用。GC将停止所有正在运行的线程,找出在堆中存在的所有不再被主程序访问的对象,并删除它们。然后GC会重新组织堆中所有剩下的对象来节省空间,并调整栈和堆中所有与这些对象相关的指针。你肯定会想到这个过程非常耗费性能,所以这时你就会知道为什么我们需要如此重视栈和堆里有些什么,特别是在需要编写高性能的代码时。
当我们使用引用类型时,我们实际是在处理该类型的指针,而非该类型本身。当我们使用值类型时,我们是在使用值类型本身。
案例:
执行以下方法
public int ReturnValue()
{
int x = new int();
x = 3;
int y = new int();
y = x;
y = 4;
return x;
}
最后结果为3
假如我们首先使用MyInt类
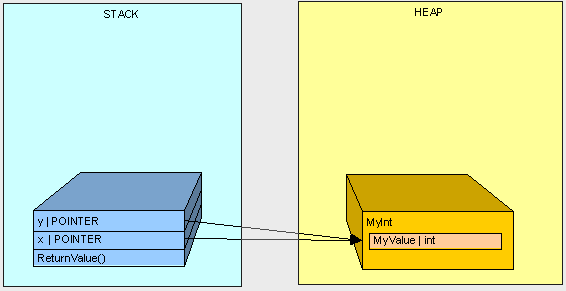
public class MyInt { public int MyValue; } //接着执行以下的方法: public int ReturnValue2() { MyInt x = new MyInt(); x.MyValue = 3; MyInt y = new MyInt(); y = x; y.MyValue = 4; //此时操作的是堆 return x.MyValue; }
最后结果为4
为什么?... x.MyValue怎么会变成4了呢?... 看看我们所做的然后就知道是怎么回事了:
在第一例子中,一切都像计划的那样进行着:

在第二个例子中,我们没有得到"3"是因为变量"x"和"y"都同时指向了堆中相同的对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号