CPU TFLOPS 计算
深度学习等计算密集型任务很关注设备的峰值算力,落实到具体指标,就是大家都很关心T(FL)OPS (Tera (FLoat) OPerations per Second)。这里,operations具体指的就是乘加操作。该指标在GPU上是明确标示供查的,但CPU目前并不会在spec中暴露TOPS指标。
一种方法可以通过跑BLAS的benchmark来测量的,这种方法有两个问题:一是需要一定的操作成本,二是受软件优化的影响(所以,如果出了问题就容易不知道这是硬件能力不行还是软件优化没到位)。因此,需要一个对硬件能力的直接估计。
这里提供一个计算CPU峰值算力的公式来解决这个问题。
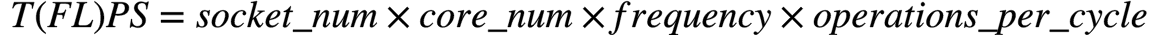
浮点算力
FP64 TFLOPS计算
AVX FP64 FMA
FP64 FMA乘加指令vfmadd132pd执行以下操作:

如: 一个AVX-512寄存器可以存放8个FP64 (
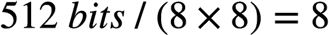 ), 那么
), 那么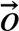 ,
,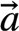 ,
, 和
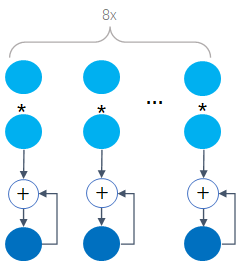
和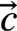 的长度就均为8,一个AVX-512 FMA每个clock cycle可以做8个乘加操作,如下:
的长度就均为8,一个AVX-512 FMA每个clock cycle可以做8个乘加操作,如下:
因此,FP64的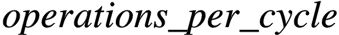 可以计算如下:
可以计算如下:
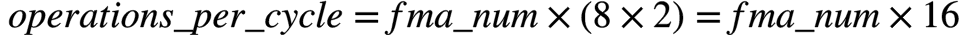
举个栗子
Xeon SkyLake 8180,一个socket有28个core,每个core有一个AVX-512协处理器,每个AVX-512协处理器配有2个FMA。因此:


所以,一个双路(dual-socket) SkyLake 8180系统的FP64峰值TFLOPS (Tera FLoat OPerations per Second)为:
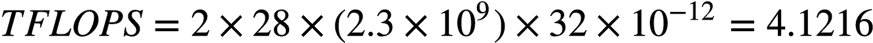
FP32 TFLOPS计算
AVX FP32 FMA
FP32 FMA乘加指令vfmadd132ps执行以下操作:
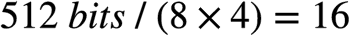 ), 因此,,和的长度均为16,一个AVX-512 FMA每个clock cycle可以做16个乘加操作,如下:
), 因此,,和的长度均为16,一个AVX-512 FMA每个clock cycle可以做16个乘加操作,如下:
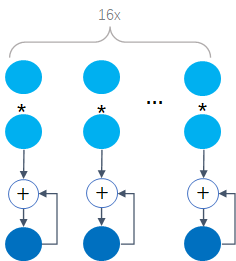
因此,FP32的可以计算如下:
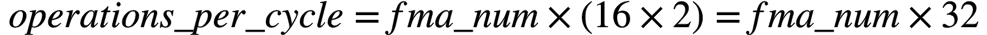
举个栗子
Xeon SkyLake 8180,一个socket有28个core,每个core有一个AVX-512协处理器,每个AVX-512协处理器配有2个FMA。因此:
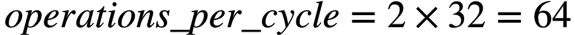
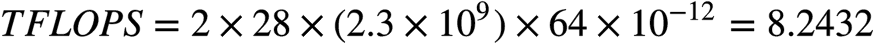
FP16 TFLOPS计算
Using AVX FP32 FMA
Xeon CPU在SapphirRapids(SPR)之前不支持FP16的原生FMA运算,需要先通过vcvtph2ps指令将FP16转换成FP32,再通过FP32的FMA运算来完成。此时,FP16的峰值TFLOPS与FP32的峰值TFLOPS是相等的。
AVX FP16 FMA
从SPR开始,AVX512引入了vfmadd132ph指令用于FP16的FMA运算。凡是CPU Flag中有AVX512_FP16的CPU均支持原生FP16乘加。一个AVX-512寄存器可以存放32个FP16 (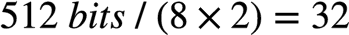 ),一个AVX-512 FMA每个clock cycle可以做32个乘加操作,如下:
),一个AVX-512 FMA每个clock cycle可以做32个乘加操作,如下:
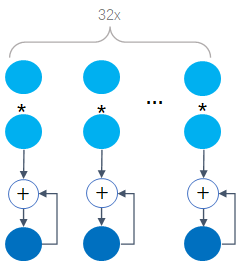
此时,FP16的可以计算如下:
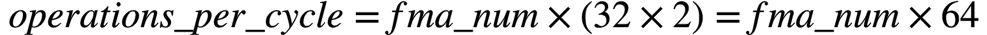
BF16 TFLOPS计算
Xeon CPU从CooperLake(CPX)开始支持BF16的乘加运算,凡是CPU Flag中有AVX512_BF16的CPU均支持原生BF16乘加。但因为其复用了FP32的FMA,所以暴露出来的BF16指令并不是标准的FMA,而是DP(Dot Product)。
AVX BF16 DP
BF16 DP指令vdpbf16ps操作如下:
一个AVX-512寄存器可以存放32个BF16 ()。因此,一个AVX-512 BF16 DP每个clock cycle可以做32个乘加操作。
因此,可以计算如下:
整型算力
INT32 TOPS计算
AVX INT32 MA
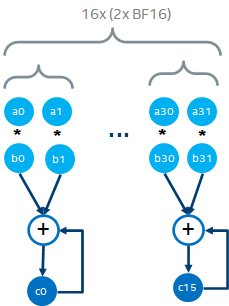
CPU通过两条指令vpmuldq + vpaddq完成INT32的乘加操作,如下:
一个AVX-512寄存器可以存放16个INT32 ()。因此,一个AVX-512 FMA每2个clock cycle可以做16个INT32乘加操作,即平均每个clock cycle可以做8个INT32乘加操作。
因此,可以计算如下:
INT16 TOPS计算
pre-VNNI MA
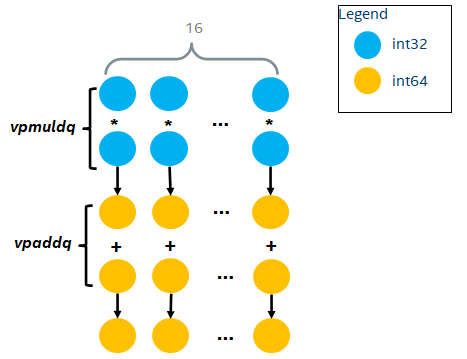
在支持VNNI(Vector Neural Network Instructions)指令前,CPU通过两条指令vpmaddwd + vpaddd完成INT16的DP操作(原因也是为了复用INT32的FMA,所以选择不支持INT16的FMA,而只支持Multiply Add), 如下:
一个AVX-512寄存器可以存放32个INT16 ()。因此,每2个clock cycle可以做32个INT16乘加操作,即平均每个clock cycle做16个INT16乘加操作。
因此,可以计算如下:
post-VNNI DP
在支持VNNI指令后,CPU通过一条指令vpdpwssd完成INT16的乘加操作, 如下:
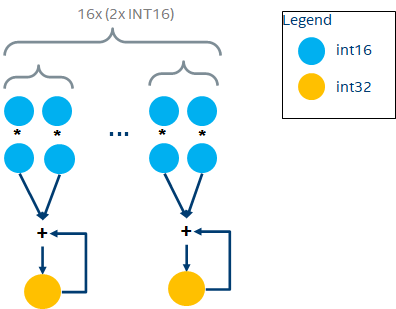
因此,一个AVX-512 FMA每个clock cycle可以做32个INT16乘加操作,可以计算如下:
INT8 TOPS计算
pre-VNNI MA
在支持VNNI指令前,CPU通过三条指令vpmaddubsw + vpmaddwd + vpaddd完成INT8的DP操作, 如下:
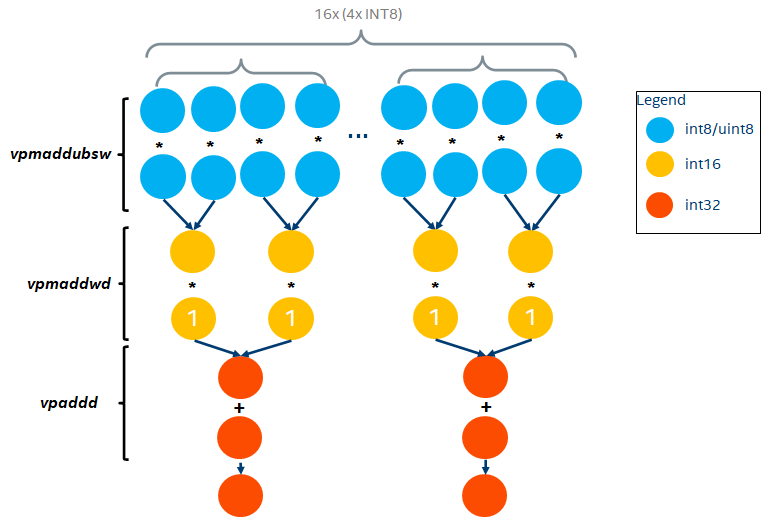
一个AVX-512寄存器可以存放64个INT8 (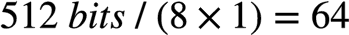 )。因此,一个AVX-512 FMA每3个clock可以做64个INT8乘加操作,即平均每个clock做
)。因此,一个AVX-512 FMA每3个clock可以做64个INT8乘加操作,即平均每个clock做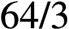 个INT8乘加操作。
个INT8乘加操作。
因此,可以计算如下:
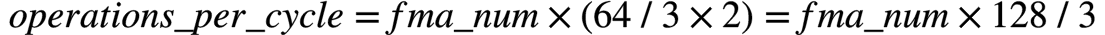
post-VNNI DP
在支持VNNI指令后,CPU通过一条指令vpdpbusd完成INT8的DP操作, 如下:
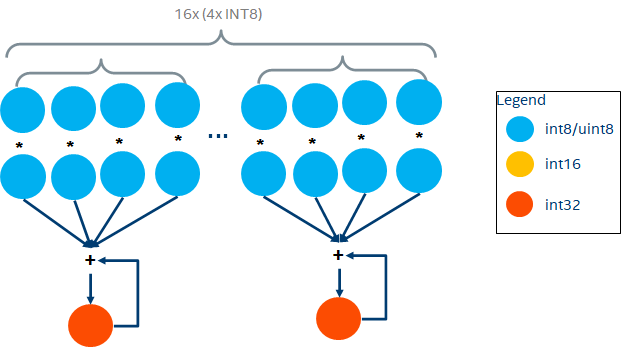
一个AVX-512寄存器可以存放64个INT8 ()。因此,一个AVX-512 FMA每个clock cycle可以做64个INT8乘加操作。
因此,可以计算如下:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号