[专题论文阅读]【分布式DNN训练系统】 FireCaffe
FireCaffe
Forrest N. Iandola FireCaffe: near-linear acceleration of deep neural network training on computer clusters 2016.1
Problem statements from data scientists
4 key pain points summarized by Jeff Dean from Google:
1. DNN researchers and users want results of experiments quickly.
2. There is a “patience threshold”: No one wants to wait more than a few days or a week for result.
3. This significantly affects scale of problems that can be tackled.
4. We sometimes optimize for experiment turn-around time, rather than absolute minimal system resources for performing the experiments

Problem analysis
The speed and scalability of distributed algorithm are almost always limited by the overhead of communicating between servers; DNN training is not an exception to this rule.
So the design focuses on the communication enhancement, including:
2. Decrease the data transmission volume while training, which includes:
a) Balance carefully between data parallelism and model parallelism
b) Increase batch size to reduce communication quantity. And identify hyperparameters suitable for large batch size.
c) Communication data quantity balance among nodes to avoid single point dependency.
Key take-aways
Parallelism Scheme: Model parallelism or Data Parallelism
Model parallelism
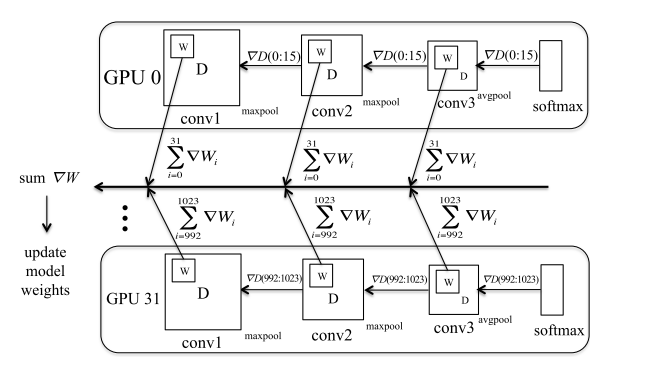
Each worker gets a subset of the model parameters, and the workers communication by exchanging data gradients ![]() and exchanging activations
and exchanging activations ![]() .
. ![]() and
and ![]() data quantity is:
data quantity is:

Data parallelism
Each worker gets a subset of the batch, and then the workers communicate by exchanging weight gradient updates ![]() , where
, where ![]() and
and ![]() data quantity is:
data quantity is:
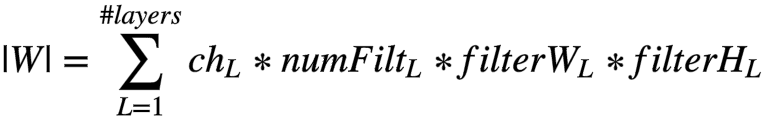
Convolution layer and fully connection layer have different characteristics in data/weight ratio. So they can use different parallelism schemes.

So a basic conclusion is: convolution layers can be fitted into data parallelism, and fc layers can be fitted into model parallelism.
Further more, for more advanced CNNs like GoogLeNet and ResNet etc., we can directly use data parallelism, as this paper is using.
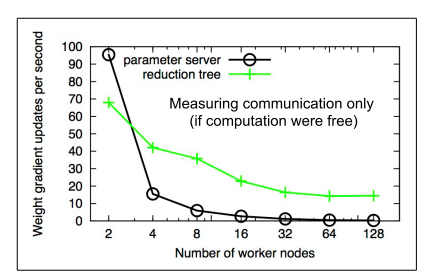
Gradient Aggregation Scheme: Parameter Server or Reduction Tree
One picture to show how parameter server and reduction tree work in data parallelism.
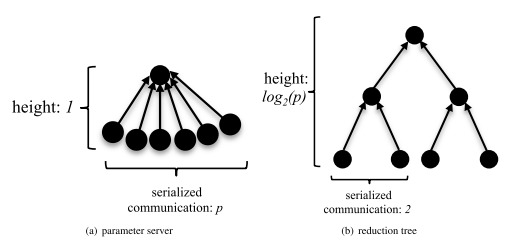
Parameter Server
Parameter communication time with regard to worker number ![]() in parameter server scheme.
in parameter server scheme.
Microsoft Adam and Google DistBelief relief this issue by defining a pool of nodes that collectively behave as a parameter server. The bigger the parameter server hierarchy gets, the more it looks like a reduction tree.
Reduction Tree
The idea is same as allreduce in message passing model. Parameter communication time with regard to worker number ![]() in reduction tree scheme.
in reduction tree scheme.
Batch size selection
Larger batch size lead to less frequent communication and therefore enable more scalability in a distributed setting. But for larger batch size, we need identify a suitable hyperparameter setting to maintain the speed and accuracy produced in DNN training.
Hyperparameters includes:
1. Initial learning rate![]()
2. learning rate update scheme
3. weight delay![]()
4. momentum![]()
![]()
Weight update rule used, here means iteration index:
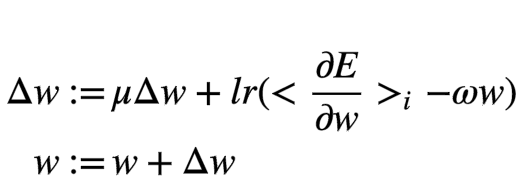
Learning rate update rule:
![]()
On how to get hyperparameters according to batch size, I will write another article for this.
Results
Final results on GPU cluster w/ GoogleNet.

More thinking
1. 以上方案基本上是无损的,为了更进一步减少通信开销,大家开始尝试有损的方案,在训练速度和准确度之间进行折衷。典型的有:
1). Reduce parameter size using 16-bit floating-point - Google2). Use 16-bit weights and 8-bit activations.
3). 1-bit gradients backpropagation - Microsoft
4). Discard gradients whose numerical values fall below a certain threshold - Amazon
5). Compress(e.g. using PCA) weights before transmitting
6). Network pruning/encoding/quantization - Intel, DeePhi
2. 使用新的底层技术来减少通信开销 - Matrix
1) RDMA rather than traditional TCP/IP?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号