CPU AMX 详解
CPU AMX 详解
概述
2016 年开始,随着 NV GPU AI 能力的不断加强,隐隐感觉到威胁的 Intel 也不断在面向数据中心的至强系列 CPU 上堆砌计算能力,增加 core count 、提高 frequency 、增强向量协处理器计算能力三管其下。几乎每一代 CPU 都在 AI 计算能力上有所增强或拓展,从这个方面来讲,如果我们说它没认识到势,没有采取行动,也是不公平的。
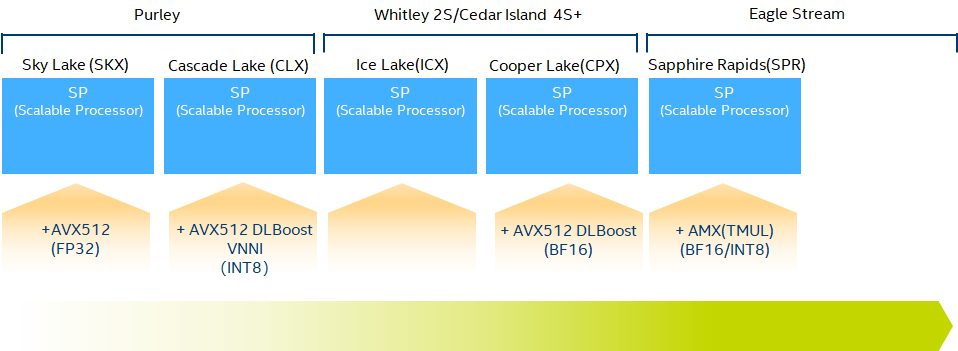
从上图不难看到,2015年的 Sky Lake 首次引入了 AVX-512 (Advanced Vector eXtensions)向量协处理器,与上一代 Broadwell 的 AVX2 相比, 每个向量处理器单元的单精度浮点乘加吞吐翻倍。接着的Cascade Lake 和 Cooper Lake又拓展了 AVX-512 ,增加了对 INT8 和 BF16 精度的支持,奋力想守住 inference 的基本盘。一直到 Sapphire Rapids,被市场和客户用脚投票,前有狼(NVIDIA)后有虎(AMD),都把自己的食盆都快拱翻了,终于意识到在AI的计算能力上不能在按摩尔定律线性发育了,最终也步Google和NVIDIA的后尘,把AVX升一维成了AMX(Advanced Matrix eXtension),即矩阵协处理器了。充分说明一句老话,你永远叫不醒一个装睡的人,要用火烧他。不管怎么样,这下总算是赛道对齐了,终于不是拿长茅对火枪了。
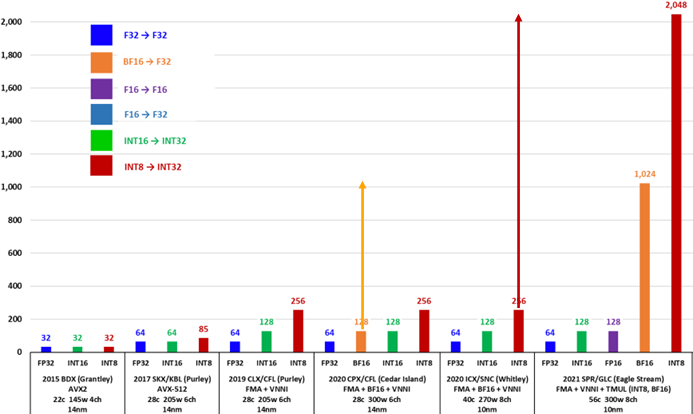
算力如何
AI 工作负载 Top-2 的算子:
-
Convolution
-
MatMul/Fully Connected
这俩本质上都是矩阵乘。怎么计算矩阵乘,有两种化归方法:
-
化归成向量点积的组合,这在CPU中就对应AVX
-
化归成分块矩阵乘的组合,这在CPU就对应AMX
我们展开讲讲。
问题定义
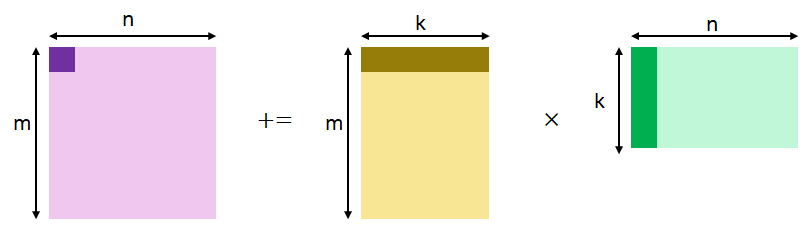
假设有如下矩阵乘问题:
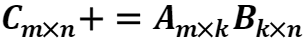
AVX如何解决矩阵乘问题
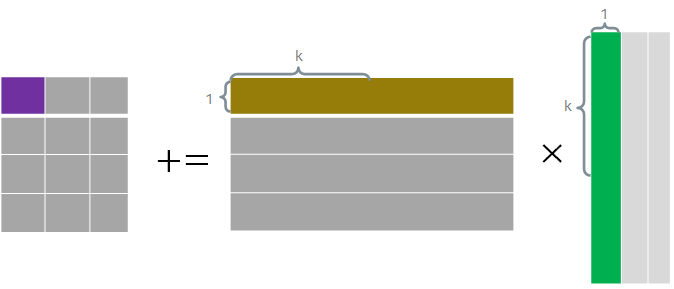
AVX把向量作为一等公民,每次计算一个输出元素 ,而该元素等于
,而该元素等于 的第
的第 行与
行与 的第
的第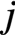 列的点积,即有:
列的点积,即有:

 的块,多做几次就好了。这个就是区分AVX各代的主要因素。下面以AVX2为例浅释一下。
的块,多做几次就好了。这个就是区分AVX各代的主要因素。下面以AVX2为例浅释一下。
AVX2 FP32 (k=8)
AVX2使用的寄存器长度为256 bit,也就是8个FP32数,此时。AVX的乘加> 指令操作示意如下:
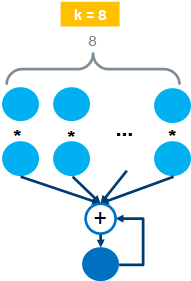
一个时钟周期可以完成两个8维向量的点积操作,也叫FMA(Fused Multiply > Add)操作。因此每个AVX单元的FLOPS为:16 FLOPS/cycle。
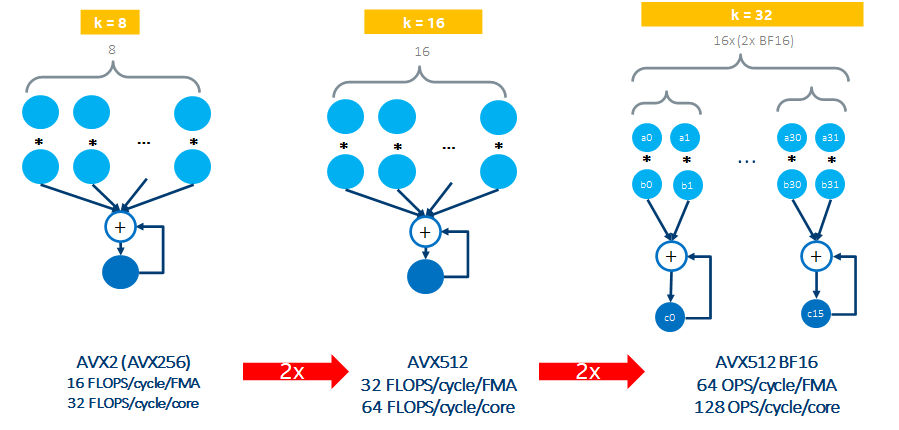
以FP32/BF16为例,AVX算力的代际演进如下,可以看出相邻代际增长是平平无奇的2倍。
AMX如何解决矩阵乘问题
以BF16为例,AMX把矩阵乘操作化归为若干个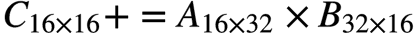 的分块矩阵乘的组合,如下所示。
的分块矩阵乘的组合,如下所示。
需要注意的是整个操作需要16个cycle完成,因此不难计算每个AMX单元的FLOPS为:1024 OPS/cycle。这下单AMX单元与单AVX单元的每时钟周期的算力提高了16倍,有点像样了。目前Sapphire Rapids每个核有一个AMX单元,而有两个AVX单元,因此每核的每时钟周期算力提高倍数为8倍。
如何计算含有AMX CPU的peak TFLOPS
公式:
假设你有一个56核,每核有1个AMX单元,且AMX频率为1.9 GHz的CPU。其BF16 peak TFLOPS应为:
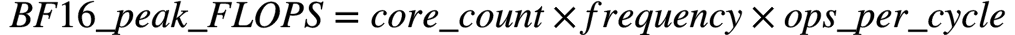
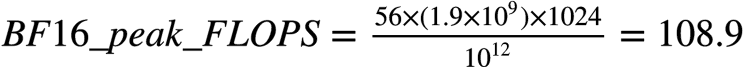
如何实现的
AMX围绕矩阵这一一等公民的支持分为计算和数据两个部分。

-
计算部分:目前仅有矩阵乘支持,由称为TMUL(Tile Matrix mULtiply Unit)的模块来实现。但也为后面支持其他的矩阵运算留了想像。
-
数据部分:由一组称为TILES的二维寄存器来承担。
其系统框图如下:
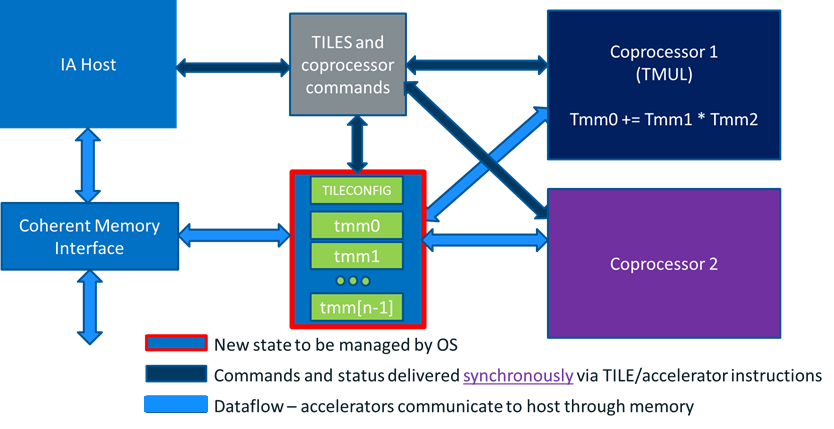
计算部分
TMUL 硬件层面的实现也比较直观,是一个典型的systolic array设计。比较好的是array的每一行都复用了原来的AVX-512 BF16的设计,堆叠了16个AVX-512 BF16单元,在一个cycle内完成了一个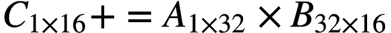 的运算,因此完成整个的计算需要16个cycle。
的运算,因此完成整个的计算需要16个cycle。
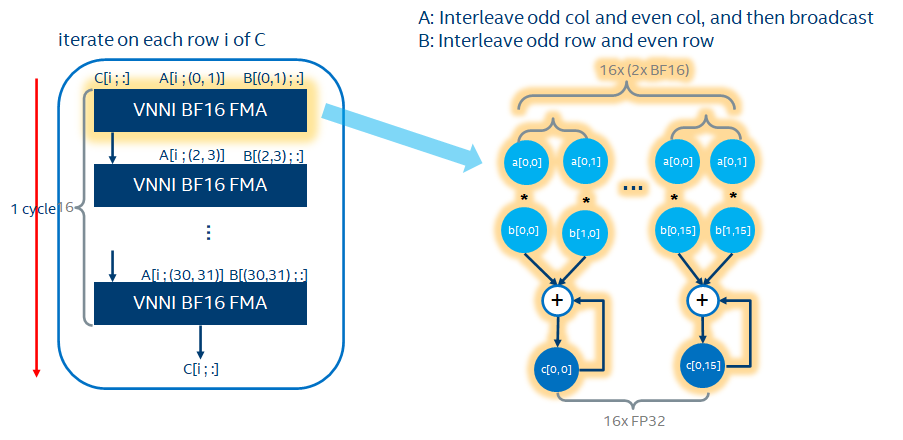
Systolic形式的逻辑图,如下。可以看出每个cycle输出  的一行结果。
的一行结果。
数据部分
每个AMX单元共有8组TILES寄存器,TILE寄存器可以存放一个二维矩阵的子矩阵,有专门的load/store指令。
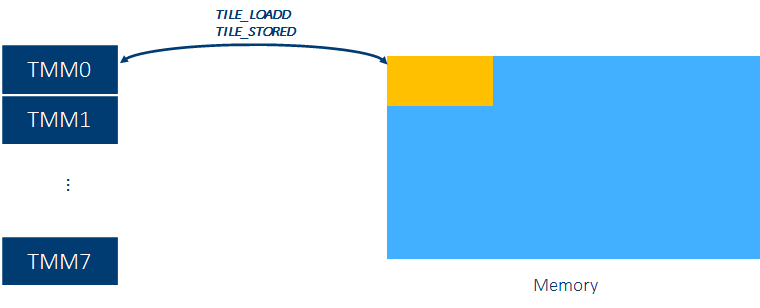
每个TILE寄存器容量为:16行  64 bytes,因此可用于存放:
64 bytes,因此可用于存放:
-
 的 FP32 矩阵
的 FP32 矩阵 -
 的 BF16 矩阵
的 BF16 矩阵 -
 的 INT8 矩阵
的 INT8 矩阵
路才开始
迈出脚只是路的开始,而不是结束。后面有的是路(问题):
-
HW
-
TILE 和 memory 之间的 load 和 save 带宽与TMUL计算能力的匹配度
-
AI workload 一般都是矩阵操作(matmul, conv等)与向量操作混杂,而向量操作有分为 element-wise 操作和 reduce 类操作
-
这3类操作算力的匹配度
-
矩阵寄存器与向量寄存器之间的 data path 通畅度如何
-
-
……
-
-
SW
-
如何提高SW efficiency
-
如何摆平AI框架要求的plain data layout与AMX硬件要求的data layout之间的re-layout开销
-
……
-
让我们边走边看!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号