Transformer block拆解
基本结构
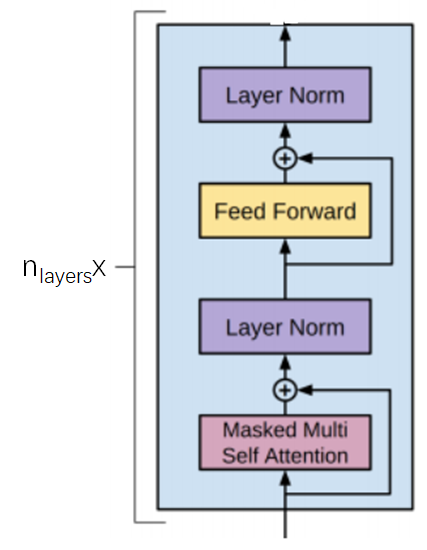
basic参数
or
: total number of transformer blocks
or
: number of units in each bottleneck layer, and number of units of each Q/K/V input
or
: number of heads of each transformer block
or
: input sequence length
derived参数
: dimension of each attention head,
: intermediate layer units of feed forward layer,

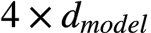
各参数在transformer block中的详细示意图如下(可双击放大):
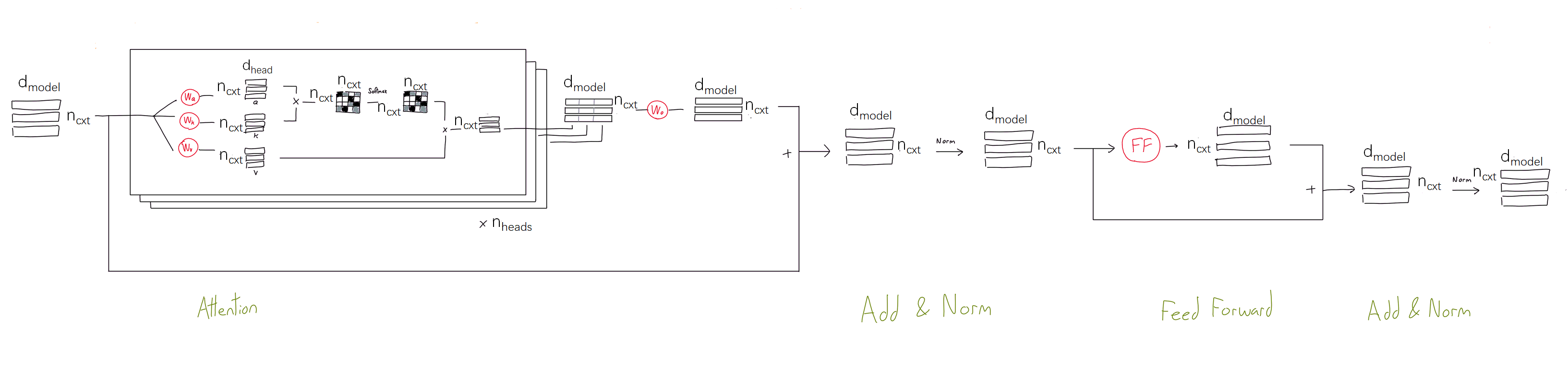
Zoom in Feed Forward子模块
典型模型基本参数
| 应用 | 模型 | |
|
|
 |
| NLP | GPT-3 | 96 | 12288 | 96 | 2048 |
| NLP | BERT_Base | 12 | 768 | 12 | 128/512 |
| NLP | BERT_Large | 24 | 1024 | 16 | 128/512 |
| RecSys | BST | 1 | 128(max) | 8 | 20 |
-
BST: Behavior Sequence Transformer


 浙公网安备 33010602011771号
浙公网安备 33010602011771号