

C++ 按照字典序实现combination
C++ 按照字典序实现combination
引言
C++ STL提供了permutation相关的函数(std::next_permutation和std::prev_permutation),但是没有提供combination相关的函数,本文将基于字典序的方法实现一个combination相关的函数。
算法回顾
1.permutation用法
C++的permutation是基于字典序实现的,从一个初始有序的序列出发对元素进行重新排列,当排列到最后一个字典序的时候该函数返回false,否在返回true,具体如下:
std::vector vec = { 1, 2, 3 };
std::sort(vec);
do {
// ...
} while (std::next_permutation(vec.begin(), vec.end()));
2.字典序
假设S是由连续的整数构成的序列:
设A和B是集合S的两个r子集,其中r是满足 的固定整数。如果在并集但不在交集中的最小整数在A中,我们就认为在字典序中A先于B。
举个例子:假设,不难发现,其中4是在中但是不在中的最小整数,它在A中,所以A的字典序是小于B的。
3.元素重复问题
组合数是不关注元素顺序的,对于和是俩个相同的集合。所以我们约定当我们书写集合时,必有。这样对于对于和来说,它们最终的写法都是。按照这种方式,我们回顾一下刚才的俩个集合
我们将A和B对齐之后不难发现在第三个元素的位置4是小于5的,所以A的字典序是小于B的。
算法实现
1.算法原理
假设初始序列是,我们需要求解3子集的字典序,第一个3子集是最后一个3子集是。那么的后继是多少呢?
不难发现此时的以1开始的序列中3, 4已经是最大值了,那么接下来应该是以2开头的序列,即
定理:设是的子集。在字典序中,第一个子集是。最后一个子集是。假设。设是满足且使得的最大整数,那么在字典序中,的直接后继子集是。
2.算法证明
根据字典序的定义,是在字典序的第一个子集,而是最后一个子集。现在,设是任意一个子集,但不是最后一个子集,确定出定理中的。于是
其中
因此,是以开始的最后的子集。而下面的子集
是以开始的第一个子集,从而是的直接后继。
3.具体实现
我们首先按照STL风格来定义我们的函数接口:
template <typename I, typename Comp>
constexpr bool combination(I first, I middle, I last, Comp comp);
和permutation不同的是,combination需要一个参数告诉我们子集的大小,比如对于一个有6个元素的序列的4子集来说,我们可以通过以下方式去调用我们的函数:
combination(sequence.begin(), sequence.begin() + 4, sequence.begin() + 6, std::less<>());
接下来我们来梳理一下算法。
假设,从子集开始。
当时执行下列操作:
(1) 确定最大的整数使得且。
(2) 用子集替换。

我们使用来指向,由于左半部分是递增序列,我们可以通过反向遍历左半部分来获其所在的位置:
auto left = middle, right = last;
--right; --left;
for (; left != first && !comp(*left, *right); --left);

这里有两个问题需要注意:
1、如何找到。
实际上可以看成是原序列中的后面那一个元素,比如当时,后面的元素是3。当时,后面的元素是4。
由于右半部分也是递增序列,我们可以通过正向遍历右半部分来获取其位置
for (right = middle; right != last && !comp(*left, *right); ++right);
2、如何准确的找到来替换。
我们可以使用强大的观察法来尝试发现规律。
我们使用来指向, 使用来指向,同时我们将这两个元素标红。同时,我们将处于和内的元素标蓝。
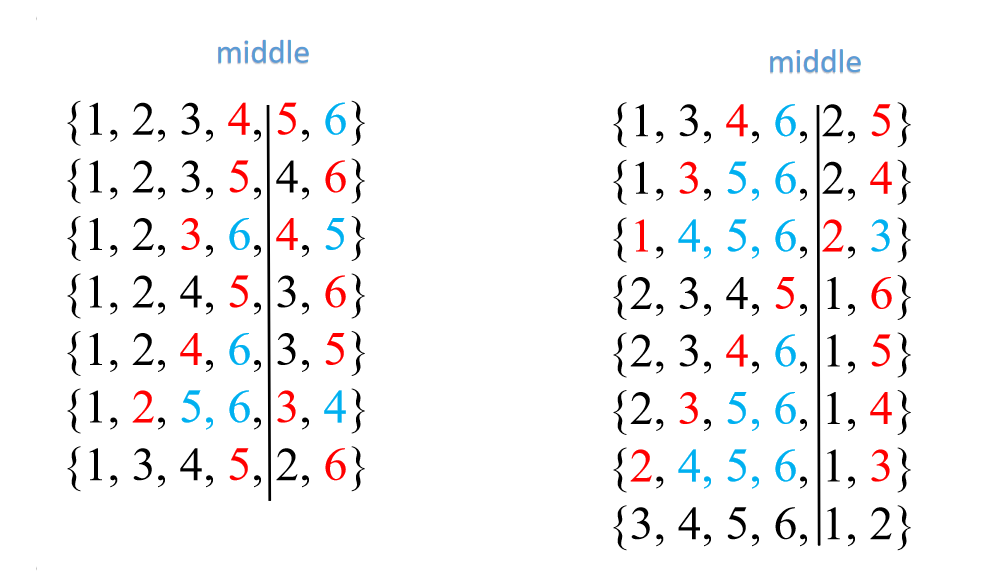
不难发现,我们只需要将红色的元素交换,并将蓝色的元素左移就可以获得该序列的后继序列。
比如,我们首先交换红色部分得到,然后将蓝色部分的左移2个单位得到最后再放回该序列就可以得到
代码如下:
bool is_over = left == first && !comp(*first, *right);
right = middle;
if (!is_over)
{
for (; right != last && !comp(*left, *right); ++right);
std::iter_swap(left++, right++);
}
shift_left(left, middle, right, last);
关于shift_left的代码我们只需要将std::rotate中的相关变量名称修改一下即可,这里不再考虑具体实现和优化。
template <typename I>
void shift_left(I first1, I last1, I first2, I last2)
{
if (first1 == last1 || first2 == last2)
return;
std::reverse(first1, last1);
std::reverse(first2, last2);
while (first1 != last1 && first2 != last2)
{
std::iter_swap(first1, --last2);
++first1;
}
if (first1 == last1)
{
std::reverse(first2, last2);
}
else
{
std::reverse(first1, last1);
}
}
全部代码如下:
template <typename I>
void shift_left(I first1, I last1, I first2, I last2)
{
if (first1 == last1 || first2 == last2)
return;
std::reverse(first1, last1);
std::reverse(first2, last2);
while (first1 != last1 && first2 != last2)
{
std::iter_swap(first1, --last2);
++first1;
}
if (first1 == last1)
{
std::reverse(first2, last2);
}
else
{
std::reverse(first1, last1);
}
}
template <typename I, typename Comp>
constexpr bool combination(I first, I middle, I last, Comp comp)
{
if (first == middle || middle == last)
return false;
auto left = middle, right = last;
--right;
--left;
// The left should less than right.
for (; left != first && !comp(*left, *right); --left);
// If all elements in left are greater than right, the iteration should be stopped.
bool is_over = left == first && !comp(*first, *right);
right = middle;
if (!is_over)
{
// Find a_k + 1
for (; right != last && !comp(*left, *right); ++right);
std::iter_swap(left++, right++);
}
// Replace (a_1, ..., a_{k-1}) with (a_k + 1, ..., a_k + r - k + 1)
shift_left(left, middle, right, last);
// Return false to stop do-while loop.
return !is_over;
}
我们可以使用leetcode90来验证算法的正确性:
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
vector<vector<int>> res;
auto comp = less<>();
res.emplace_back(nums);
for (int i = 0; i < nums.size(); ++i) {
sort(nums.begin(), nums.end(), comp);
do {
res.emplace_back(nums.begin(), nums.begin() + i);
} while (combination(nums.begin(), nums.begin() + i, nums.end(), comp));
}
return res;
}
};
参考文献
Introductory Combinatorics (5th Edition) by Richard A. Brualdi (Author)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具