
消息队列 kafka
kafka基础详解
分布式事务的四种解决方案 - 无敌是多么寂寞啊 - 博客园 (cnblogs.com)
面试官:RabbitMQ 和 Kafka选哪个? - 知乎 (zhihu.com)
我以为我对Kafka很了解,直到我看了这篇文章 (qq.com)
全面解析kafka架构与原理 - 简书 (jianshu.com)
Kafka设计解析(一) Kafka背景及架构介绍 - 知乎 (zhihu.com)
Kafka设计解析(二)- Kafka High Availability (上) - 知乎 (zhihu.com)
Kafka设计解析(三)- Kafka High Availability (下) - 知乎 (zhihu.com)
Kafka设计解析(四)- Kafka Consumer设计解析 - 知乎 (zhihu.com)
kafka集群partition分布原理分析 - _1900 - 博客园 (cnblogs.com)
Kafka文件存储机制那些事 - 美团技术团队 (meituan.com)
端到端一致性,流系统Spark/Flink/Kafka/DataFlow对比总结(压箱宝具呕血之作) - 知乎 (zhihu.com)
美团数据平台Apache Kafka系统实践 (slidestalk.com)
《我想进大厂》之kafka夺命连环11问 - 简书 (jianshu.com)
基于SSD的Kafka应用层缓存架构设计与实现 - 美团技术团队 (meituan.com)
kafka的leader选举过程 - 简书 (jianshu.com)
快手万亿级别Kafka集群应用实践与技术演进之路 | 机器之心 (jiqizhixin.com)
LinkedIn的Kafka:我是如何做到1秒发布450万+条消息! (qq.com)
万亿级消息队列Kafka在滴滴的实践 - 在线工具 (tool.lu)
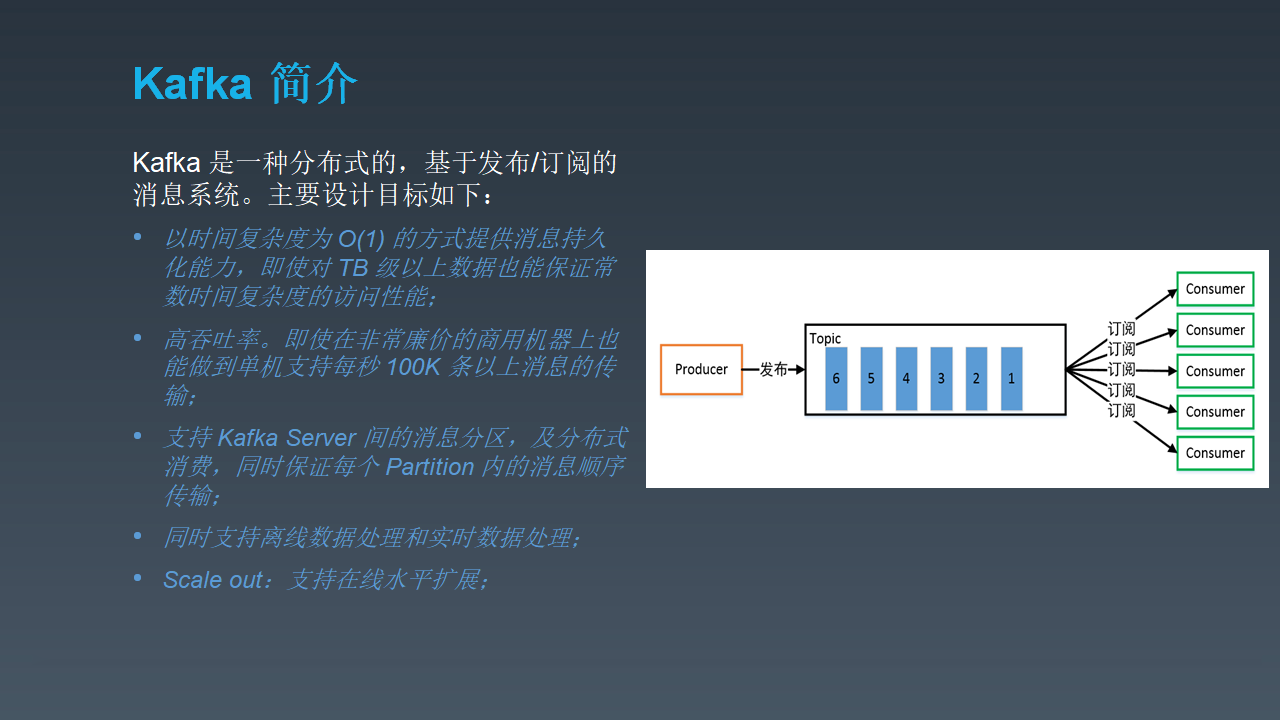
Kafka(一)Kafka的简介与架构 - Frankdeng - 博客园 (cnblogs.com)
两万字长文,彻底搞懂Kafka! - bucaichenmou - 博客园 (cnblogs.com)


Kafka 的消息是存在于文件系统之上的。Kafka 高度依赖文件系统来存储和缓存消息,一般的人认为 “磁盘是缓慢的”。
操作系统还会将主内存剩余的所有空闲内存空间都用作磁盘缓存,所有的磁盘读写操作都会经过统一的磁盘缓存(除了直接 I/O 会绕过磁盘缓存)。
Kafka 正是利用顺序 IO,以及 Page Cache 达成的超高吞吐。
任何发布到 Partition 的消息都会被追加到 Partition 数据文件的尾部,这样的顺序写磁盘操作让 Kafka 的效率非常高。
Kafka 集群保留所有发布的 message,不管这个 message 有没有被消费过,Kafka 提供可配置的保留策略去删除旧数据(还有一种策略根据分区大小删除数据)。
例如,如果将保留策略设置为两天,在 message 写入后两天内,它可用于消费,之后它将被丢弃以腾出空间。Kafka 的性能跟存储的数据量的大小无关, 所以将数据存储很长一段时间是没有问题的。
Offset:偏移量。每条消息都有一个当前 Partition 下唯一的 64 字节的 Offset,它是相当于当前分区第一条消息的偏移量,即第几条消息。
消费者可以指定消费的位置信息,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。

对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 Follower 全部接受成功。只有被 ISR 中所有 Replica 同步的消息才被 Commit,但Producer 发布数据时,Leader 并不需要 ISR 中的所有 Replica 同步该数据才确认收到数据。
0:Producer 不等待 Broker 的 ACK,这提供了最低延迟,Broker 一收到数据还没有写入磁盘就已经返回,当 Broker 故障时有可能丢失数据。
1:Producer 等待 Broker 的 ACK,Partition 的 Leader 落盘成功后返回 ACK,如果在 Follower 同步成功之前 Leader 故障,那么将会丢失数据。
-1(all):Producer 等待 Broker 的 ACK,Partition 的 Leader 和 Follower 全部落盘成功后才返回 ACK。但是在 Broker 发送 ACK 时,Leader 发生故障,则会造成数据重复。






 浙公网安备 33010602011771号
浙公网安备 33010602011771号