
【总结笔记】WebServer 深度问题探讨
https://www.nowcoder.com/discuss/939267
https://www.nowcoder.com/discuss/945403
https://zhuanlan.zhihu.com/p/368154495
https://blog.csdn.net/weixin_44484715/article/details/120825122
https://blog.csdn.net/daaikuaichuan/article/details/100514401
线程的数目如何设置
· 对于 CPU 密集型,线程数是 CPU 数目 + 1
· 对于 I/O 密集型,线程数可以大一点 = CPU 数目 + CPU*(线程等待时间/线程CPU时间)
多进程模型与多线程模型
多进程模型
为每个客户端分配一个进程来处理请求。可能出现的问题:当子进程退出时,实际上内核里会保留进程的一些信息,也会占用内存,因此需要父进程去回收子进程的一些资源,否则会沦为僵尸进程,耗尽系统资源。(SIGKILL 信号捕捉函数)
多线程模型
使用多线程模型的好处是线程切换开销小,但为了多线程竞争,线程在操作任务队列时需要加锁。
大端序小端序
网络序是大端字节序
Nginx
Nginx 如何实现异步非阻塞
Nginx 采用的是 ET 模式的 epoll。Epoll 是同步的,那 Nginx 如何实现异步呢?
正常情况下,我们调用 read() 如果数据未到达,主线程会一直占用 CPU 询问,数据是否到达,而不陷入阻塞态,直到有数据到达,主线程才读取数据,这是同步。对于 Nginx 而言,它是若调用 read() 无数据到达,会注册一个事件,然后接着处理其他事情,等到数据到达后,事件触发,主线程才读取这个数据,这是异步。
Nginx 反向代理
Nginx 作为 Web 服务器的 3 个功能:反向代理、静态 web 服务器、负载均衡
反向代理【转发请求】
接受客户端请求,若请求是访问静态文件,则 Nginx 作为 web 服务器直接返回请求内容;若请求访问后台服务逻辑,则 Nginx 将请求转发给内部服务器处理。
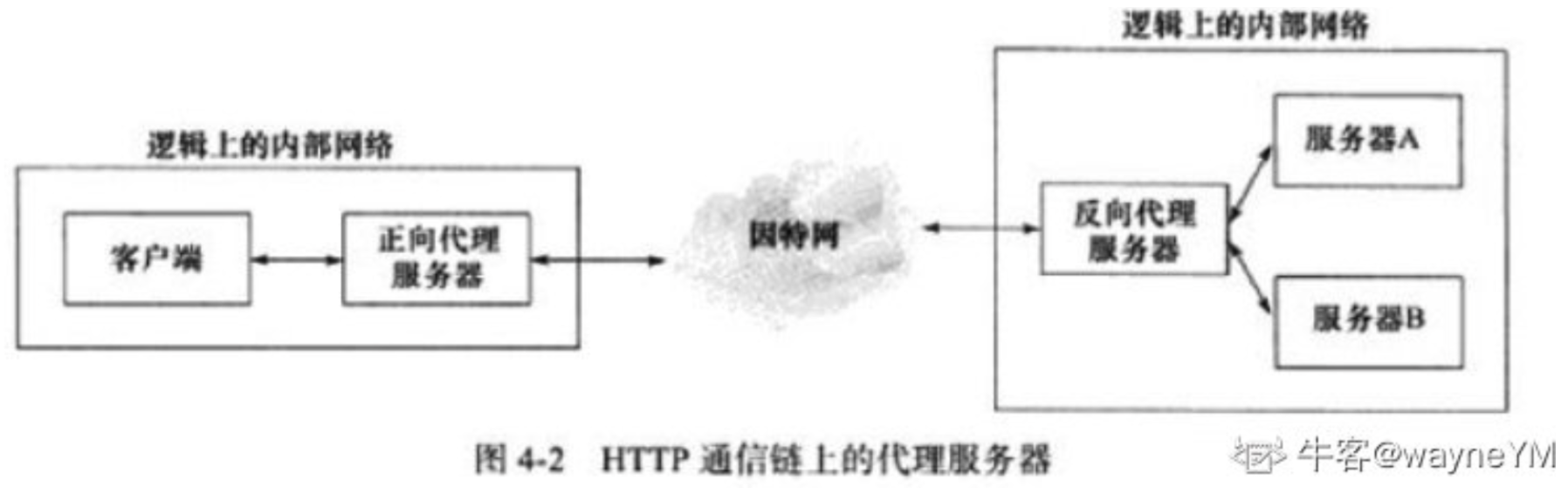
反向代理的作用:
1)配合 upstream 实现负载均衡;
2)提高安全性,增加中间屏障,客户端不能直接访问后端服务;
3)提升性能,通过异步非阻塞的方式把请求传给后端,提升了并发处理能力;
4)利用缓存,提高响应速度
负载均衡
https://blog.csdn.net/zhangzeyuaaa/article/details/120810743
当有多个服务器时,根据规则随机的将请求分发到指定的服务器上处理。负载均衡配置一般都需要同时配置反向代理,通过反向代理跳转到负载均衡。
负载均衡方案主要有 3 种:1)基于 DNS 负载均衡;2)基于硬件负载均衡;3)基于软件负载均衡。DNS 负载均衡可以实现在地域上的流量均衡,硬件负载均衡主要用于大型服务器集群;软件负载均衡是基于机器层面的流量均衡。Nginx 负载均衡属于在应用层流量分发任务。
常见负载均衡策略:
1)轮询:平均分配
2)加权轮询:在轮询的基础上,增加一个权重的概念。
3)哈希法:
4)最少连接数:动态负载均衡的策略。维护活动中的连接数量,然后取最小的返回。
5)最快响应:动态负载均衡的策略。若根据每个节点过去一段时间的响应情况来分配,响应越快,分配越多。
HTTP 有哪些优化方案:
1)内容缓存
2)数据压缩:采用某种编码方式
3)SSL 加密:从安全性优化
4)TCP 复用:基于流 ID
压力测试服务器
压测工具:WebBench 性能压力测试工具,它展示服务器的两项内容——每秒钟响应请求数、每秒种传输数据量
压测基本原理
Webbench 首先 fork 出多个子进程,每个子进程循环做 web 访问测试。子进程把访问的结果通过管道告诉父进程,父进程做统计。
由于我们在虚拟机跑,所以并发量差不多最大 7000 多,不到 1w,QPS 才 1w出头。【无法达到百万 QPS】
常见多线程多进程服务器
1)Apache;2)Nginx;3)Tomcat
可以多个线程/进程监听同一个端口吗?
1)5 元组(源IP,源端口,协议,目的IP,目的端口)唯一确认一个连接。对于一个端口,可以被 TCP 也可以被 UDP 监听;
2)使用端口复用,一个端口可以被多个 TCP、多个UDP 监听。【所以会出现惊群现象:accept 的时候】
主机上最多能保持多少个连接
https://www.zhihu.com/question/361111920
https://www.nowcoder.com/discuss/945403
连接通过 5 元组唯一识别(源IP,源端口,协议,目的IP,目的端口),协议包括 TCP、UDP。主要 5 元组不同,就是不同的 socket 连接。申请连接后,返回文件描述符用于通信。
瓶颈1:端口号限制 —— 通过如下指令修改端口号限制,假设为 60000
cat /proc/sys/net/ipv4/ip_local_port_range

在虚拟机上,总共才不到 3 万个端口可用
理论端口号是 16 位,范围是 1~65535,但实际并不是所有端口号都可以用,首先普通用户无法访问 1024 以下的端口。如果始终向同一目标 IP 和同一目标端口发出连接请求,首先会遇到端口号限制。
此时如果不断更换目标 IP 和目标端口号,可以继续发出连接请求。
瓶颈2:文件描述符限制
Linux 对文件描述符的限制有 3 个级别:
1)系统级:当前系统可打开的最大数量;通过 cat /proc/sys/fs/file-max 查看

系统可用文件描述符不到 4 万个
2)用户级:指定用户可打开的最大数量;通过 cat /etc/security/limits.conf 查看
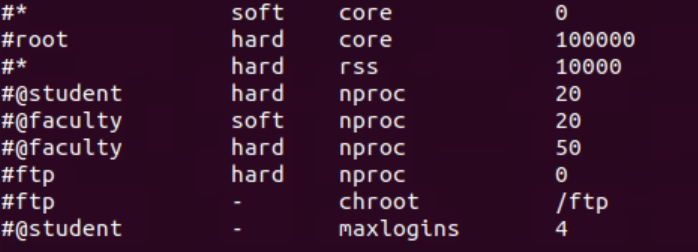
root 用户有 10 万个可用文件描述符,普通用户才有极其少个文件描述符
3)进程级:单个进程可打开的最大数量;通过 cat /proc/sys/fs/nr_open 查看

单个进程可打开 10 万个文件描述符
文件描述符的真正可用限制受系统级、用户级、进程级约束。
瓶颈3:内存限制
每个文件描述符都有一个缓冲区,若文件描述符过多,会导致内存溢出
瓶颈4:CPU 限制
看 CPU 占用率多高
写在最后:最大TCP连接数实验https://mp.weixin.qq.com/s/f_CMt2ni0vegB3-pf2BTTg
谈谈跨域问题
跨域,就是浏览器不能执行其他网站的脚本,或者说阻止接口请求,它是由浏览器的同源策略造成,是浏览器施加的安全限制。所谓同源是指:域名、协议、端口均相同。只要有个不同,就是跨域。
解决办法:后端设置解决、前端设置解决
怎样支持长连接?
HTTP/1.1 默认支持长连接,HTTP 基于 TCP,TCP 协议使用保活计数器来支持长连接,每隔一段时间向客户端发送探测报文,检测客户端是否保持连接。
如何应对服务器的大量流、高并发?
1)从 HTTP 优化客户端请求角度讲,就是减少 HTTP 向服务器请求的次数。1)设置代理服务器,能够减少一定程度的请求次数,尤其是客户端对静态资源的访问,代理服务器这层就可以直接返回;2)使用缓存。通过缓存控制协议,浏览器通过读取本地缓存从而减少对服务器的访问次数。
2) 从服务端角度讲,1)增加资源供应,如更大的网络带宽、更高配置的服务器等;2)使用集群 web 服务器,并搭配 Redis 缓存层,实现请求分流;3)SQL 优化数据库,或使用 EES 等中间件来实现数据分析和搜索,提高数据访问速度;4)优化业务逻辑代码、优化线程数等。
epoll 线程安全吗?
结论:epoll 通过锁来保证线程安全,epoll 用自旋锁 ep->lock(spinlock) 保护就绪队列【对应 epoll_wait()】,互斥锁 ep->mtx 保护红黑树【对应 epoll_ctl()】。
备注:主线程同步非阻塞效率高,而主线程调用的是 epoll_wait(),因此使用自旋锁;工作线程调用 epoll_ctl(),就算陷入阻塞也无所谓,而且通常将文件描述符加入红黑树时间较长,因此使用互斥锁。
epoll 核心数据结构
struct eventpoll {
...
// 自旋锁
spinlock_t lock;
// 互斥锁
struct mutex mtx;
// 就绪队列
struct list_head rdlist;
// 红黑树
struct rb_root_cached rbt;
...
};
epoll 主要考虑是否线程安全的接口是 epoll_ctl() 和 epoll_ctl()
epoll_clt()
epoll_clt 在操作红黑树时,通过互斥锁 ep->mtx 保证线程安全。
SYSCALL_DEFINE4(epoll_ctl, int epfd, int op, int fd, struct epoll_event __user *, event)
{
// 获得 mtx 锁
mutex_lock_nested(&ep->mtx, 0);
...
epi = -EINVAL;
switch(op) {
case EPOLL_CTL_ADD:
// 通过 ep_insert() 接口来完成 EPOLL_CTL_ADD
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_inset(ep, &epds, tf.file, fd, full_check);
}
else
error = -EEXIST;
if (full_check)
clear_tfile_check_list();
break;
case EPOLL_CTL_DEL:
// 通过 ep_remove() 接口完成 EPOLL_CTL_DEL 操作
if (epi)
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
case EPOLL_CTL_MOD
// 通过 ep_modify() 接口完成 EPOLL_CTL_MOD 操作
if (epi) {
if (!(epi->event.events & EPOLLEXCLUSIVE)) {
epds.events |= POLLERR | POLLHUP;
error = ep_modify(ep, epi, &epds);
}
else
error = -ENOENT;
break;
}
if (tep != NULL)
mutex_unlock(&tep->mtx);
mutex_unlock(&ep->mtx);
...
}
}
epoll_wait()
epoll_wait() 通过 ep_poll() 接口来等待就绪的 fd 队列。
static int ep_poll(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
...
// 获得自旋锁 ep->lock来保护就绪队列
spin_lock_irqsave(&ep->lock, flags);
将就绪事件添加到 rdllist
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake_rcu(epi);
}
}
HTTP 请求怎么拆包?
HTTP 请求内容:请求行、请求头、空行、请求体
一个请求体的请求报文的请求头有 content_length 字段,指定报文大小。若报文很大,将报文分开进行发送。在这个过程,如果有其他请求发送,就会出现粘包现象。服务器通过 content_length 字段的大小进行拆包。
pthread 库的 pthread_detach() 作用
线程有 2 种状态,joinable 和 unjoinable。若线程是 joinable 状态,则线程退出时,不会释放掉线程所占用的堆栈数据和线程描述符,只有调用了 pthread_join() 后才会方式。若调用 pthread_detach() 将线程设置为 unjoinable 状态,线程退出时,资源会立即被回收。
线程池拒绝策略
2 种情况会触发线程池拒绝执行任务。
1)线程池调用了 shutdown() 进行关闭,线程池不再执行任务;
2)线程池的线程数达到最大线程数,且缓冲队列的任务已满,还有新任务提交。
4 种决绝策略:
1)AbortPolicy(异常策略)
遇到拒绝任务时,抛出一个异常进行通知。
2)DiscardPolicy(丢弃策略)
遇到拒绝任务时,完全不理睬,不执行也不通知。
3)DiscardOldestPolicy(淘汰最久任务策略/牺牲策略)
遇到拒绝任务时,将线程队列中存活时间最久的任务给牺牲掉,让新任务进来。
4)CallerRunsPolicy(执行策略)
遇到拒绝任务时,让提交任务的线程自身去执行该任务。
大文件传输方法
1)基于 socket 进行传输【编程难度大】
由于 socket 限制缓冲区大小为 4KB,因此传输大数据时客户端需要进行分包,在目的地进行重新组包。
2)使用中间件
通过中间件 broker 来传输大文件。
3)基于 FTP 协议【简单易用,在符合使用场景时首选】
为什么我们用 epoll_ctl() 注册某事件时,发生了该事件,就会唤醒线程?原理是什么?
答:epoll_ctl() 在注册事件的时候,向内核注册了一个回调函数。当有数据到来时,即 socket 收到数据(在写事件中,我们也是将内容写到 socket),内核会通知网卡将 socket 的数据拷贝到网卡缓冲区。网卡收到数据,就会触发一个硬中断。而我们将一个回调函数绑定给了一个硬中断,这个回调函数的操作就是将线程从阻塞态激活。
TCP 连接如何与 socket 对应?
首先一个 TCP 连接由一个四元组唯一确定,当我们在 accept 的时候,就是将四元组与一个 socket 唯一确定。当网卡有数据来时,产生中断,内核会将网卡的数据拷贝到 socket 缓冲区。
thread() 中 join() 和 detach() 的区别
1)使用 join() 函数时,主线程阻塞,等待被调线程终止,然后由主线程回收被调线程。
2)使用 detach() 时,主线程继续运行,子线程与主线程彻底分离。子线程结束时,其相关资源由运行时库负责清理。
谈谈TCP 连接的优雅关闭
http://wang_da_shen.gitee.io/myblogs/2021/06/08/%E4%BC%98%E9%9B%85%E5%85%B3%E9%97%AD%E8%BF%9E%E6%8E%A5/
TCP 连接的关闭过程有 2 种,一种是优雅关闭,一种是强制关闭。
· 优雅关闭是指,若发送缓存中还有数据未发出去,则需等待其发出后,并收到所有数据的 ACK 之后,才发送 FIN 包,然后才将套接字从内存删除。
· 强制关闭是指若缓存中还有数据,则这些数据都将被丢弃,并发送 RST(reset 包,表示连接异常终止,对方收到 RST 包无需发送ACK应答报文) 包,直接重置 TCP 连接,即直接将套接字从内存删除。
高并发场景下如何实现系统限流?
限流是服务降级的一种手段。限流策略与线程池的拒绝策略类似,包括拒绝服务、延迟处理、随机拒绝等。
高并发服务的优化思路
1)使用非关系型数据库
2)使用多级缓存
· 第一层是本地缓存 local cache。本地缓存如果找不到请求数据,则走第二层;
· 第二层是 MemCache。MemCache 是多线程的,拥有比 redis 更好的并发能力,并且天然可以解决热点问题;
· 第三层是 Redis。Redis 是单线程,但会存在热点问题,导致缓存击穿和缓存穿透问题。
备注:
谈谈热点问题
单个 Redis 分片所能接收的 QPS 是有限的,一旦到了这个阈值,请求就会落在数据库服务器上,造成缓存击穿、缓存穿透、缓存雪崩。之所以有阈值的限定,是因为若针对某一key 的请求太多,整个 redis 服务器的其他服务就无法提供,CPU 被该请求占满,导致无法执行其他任务。
热点问题的解决办法
· 设置多级缓存,redis 之前用 local cache、memcache 抵挡一下;
· 将热 key 分散到不同的服务器中。即使用分片,副分片拷贝主分片的数据。当请求到来时,可以将分摊到多个分片。
· 将不同的热 key 进行拆分存储。
3)使用多线程
4)限流、降级和熔断。
限流:限制并发的请求访问量,超过阈值则拒绝。限流策略与线程池的拒绝策略类似,包括拒绝服务、延迟处理、随机拒绝等。
降级:服务分优先级,牺牲非核心服务,保证核心服务文档;
熔断:当调用链路的某个微服务响应时间太长时,会进行服务熔断,不再提供该节点的微服务调用,快速返回错误的响应信息。
高并发场景下线程池锁的优化有哪些?
锁优化一个重要的思路是降低冲突域。锁的粒度越小,冲突就越小。一个可行的思路是将数据分块,每块单独加锁。具体来说,就是设置多个消息队列,将外部请求分别存放在不同消息队列,这样可以达到优化的目的。
43 道多线程面试题
如果一直没有等到信号量,会等待多长时间?
考察线程池的 等待信号量超时的问题(自行设置)。
两种解决办法:
1)在取任务的时候,加上 keepAliveTime。若线程是超时时间获取,就关闭线程。
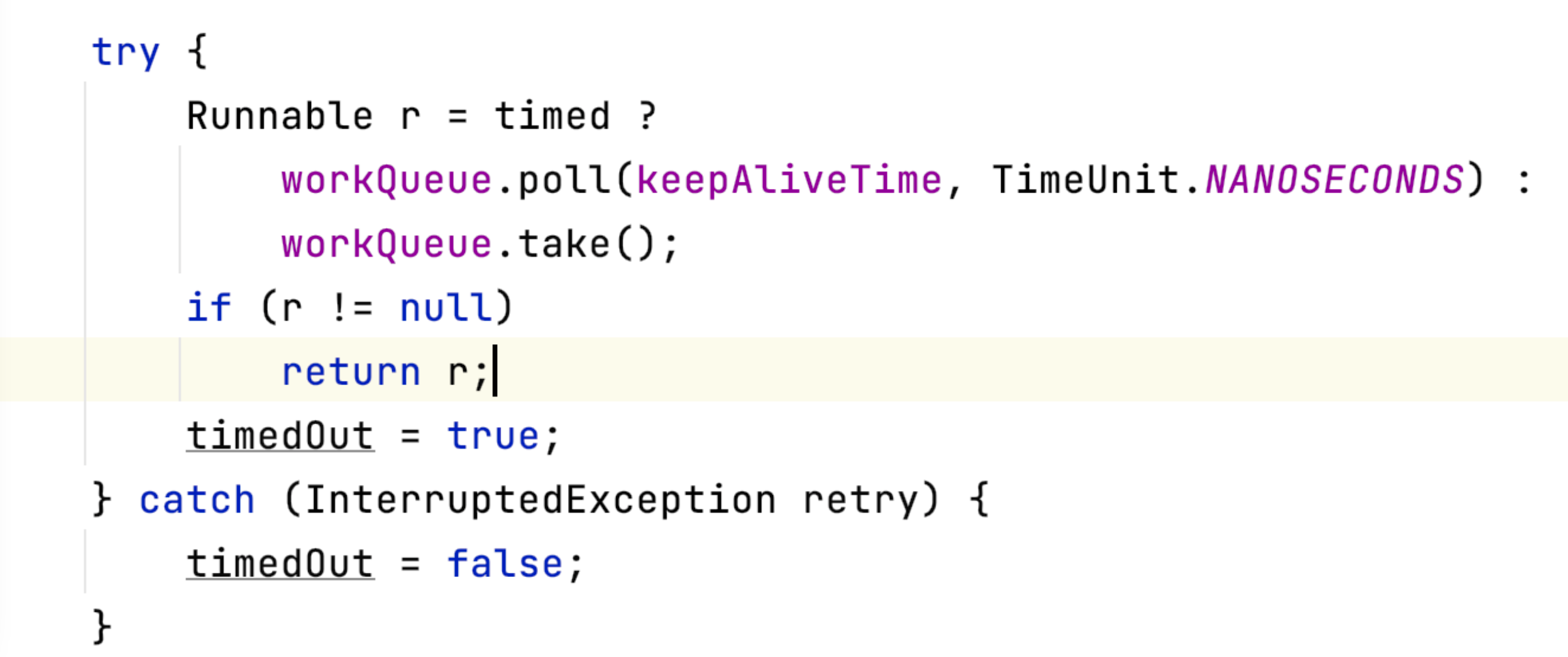
2)也可以使用 sem_waipost() ,设置线程阻塞等待信号量的时间,若超时,就执行关闭线程函数。
谈谈 WebServer 线程池的设计思想
不要单从 Reactor 回答,可以从线程池的如下优化进行回答:
1)核心线程数与非核心线程数;
2)KeepAliveTime:线程池中非核心线程空闲的存活时间;
3)线程池的拒绝策略:· 异常策略;· 丢弃策略;· 淘汰最久任务策略;
一个任务进来,先判断当前线程池中的核心线程数是否达到阈值,若小于会直接创建一个核心线程去执行任务 ,若核心线程达到限制,则任务会被放入阻塞队列中排队等待执行。进而,若阻塞队列满,开始创建非核心线程来执行阻塞队列中的业务。当非核心线程数达到阈值,且阻塞队列满,那么会采用拒绝策略处理后来的业务。
为什么要创建连接池?
若系统需要频繁访问数据库,则需要频繁创建和断开数据库连接,而创建数据库连接是一个很耗时的操作,会降低服务器的性能。所以,在程序初始化的时候,集中创建多个数据库连接,并集中管理,可以保证较快的数据库读写速度。为什么要创建连接池?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号