
【Python 总结笔记】内存管理机制
一、前导知识
1 变量与对象 —— 引用与引用计数
在 Python 中对象有类型,而变量无类型,变量只是指向对象的一个指针。
1)Python 缓存了整数类型对象和字符串类型对象(非序列对象),每个对象在内存中只存有一份,引用所指对象是相同的,即使使用赋值语句,只是创造新的引用。
a = 1
b = 1
print (a is b) # True
补充 1.1 可变对象与不可变对象
1.1.1 Python 的不可变对象(常量)
数字和字符串变量为不可变对象(常量)。当我们将新数字赋给变量x时 x=2,Python 为新数字创建对象,并将这个对象的引用传给 x。当把变量 x 赋值给变量 y 时 y = x ,y 也指向这个变量。进而,如果 y = y + 1,那么又会创建一个新对象,并把该对象赋值给 y。
1.1.2 参数传递中的不可变对象与可变对象
不可变对象(数字、字符串)使用的是值传递、可变对象(不可变对象的反面)使用的是引用传递。函数里面对可变对象参数的改变会影响外面的数值
补充 1.2 Python 的 5 种对象类型
1.2.1 int double string
int double string 都属于可变对象,此外 4 种均属于不可变对象。
1.2.2 列表 list
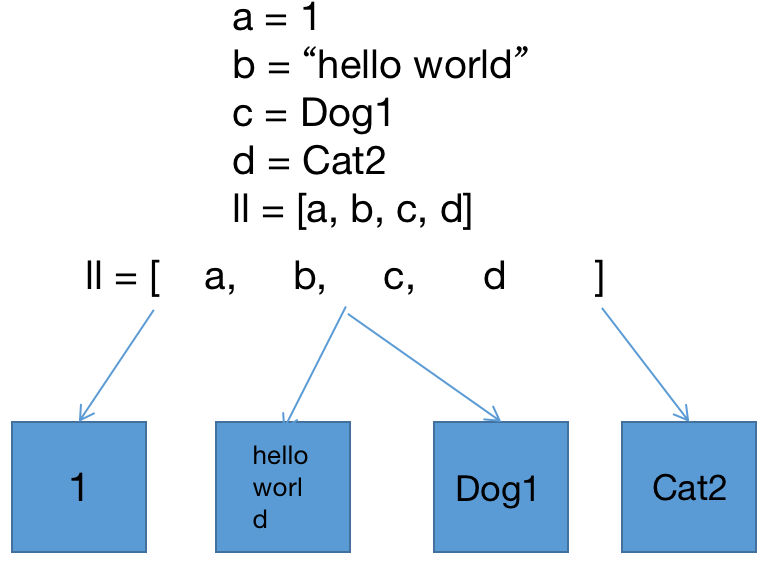
list 可以存储任意类型、任意大小的数据。它是一种序列类型。由于 Python 的变量无数据类型,因此 list 中元素的数据类型各不相同,可以包含整数、实数、字符串等基类类型的元素。
Python 采用基于值的自动内存管理模式,变量不直接存储值,而是存储值的引用或对象地址。这是 Python 中变量可以随时改变类型的原因。
注:可以将 Python 的 list 理解为底层是 deque(分段存储)
In [12]: a=[1,2,3,4,5]
In [13]: b=a
In [14]: a is b
Out[14]: True
In [15]: a[0]=6
In [16]: a
Out[16]: [6, 2, 3, 4, 5]
In [17]: a is b
Out[17]: True
In [18]: b
Out[18]: [6, 2, 3, 4, 5]
1.2.3 元组 tuple
元组对象创建后就不可改变,即不可插入、删除元素。但可以对元素内部的可变对象的属性值进行修改。【可以将元组类比 int* const p 指针】
备注:列表 list 与 元组 tuple 的区别
1)相同点:二者都是序列存储,可以通过 list() 与 tuple() 相互转换;
2)不同点:
- 1)列表创建后,可以插入、删除元素;元组创建后,不可插入、删除元素。
- 2)由于列表对象的可变性,因此列表分配到的是小内存块;由于元组创建后不可插入、删除元素,因此分配到的是大块内存。
- 3)tuple 的创建速度比 list 快
1.2.4 集合 set
集合与列表类似,但集合中的元素是不重复的。集合用 {} 表示。
集合中的每个元素必须是哈希的[hashable](Python 中的每个对象都有一个哈希值。若在对象的生命周期里对象的哈希值从未改变,则称这个对象是哈希的)。
备注:列表 list 与 集合 set 的区别
1)存储方式:列表的元素是顺序存储的;集合的元素是无序存储的。
2)访问速度:可以通过 index 在 O(1) 时间内访问列表的元素,访问集合元素需要遍历;但使用 in 和 not in运算符,集合比列表的速度更快。
注:可以将 Python 的 list 理解为底层是 deque(分段存储);set 理解为底层是 unordered_map 哈希表,其 key 是对象的哈希值。
1.2.5 字典 dict
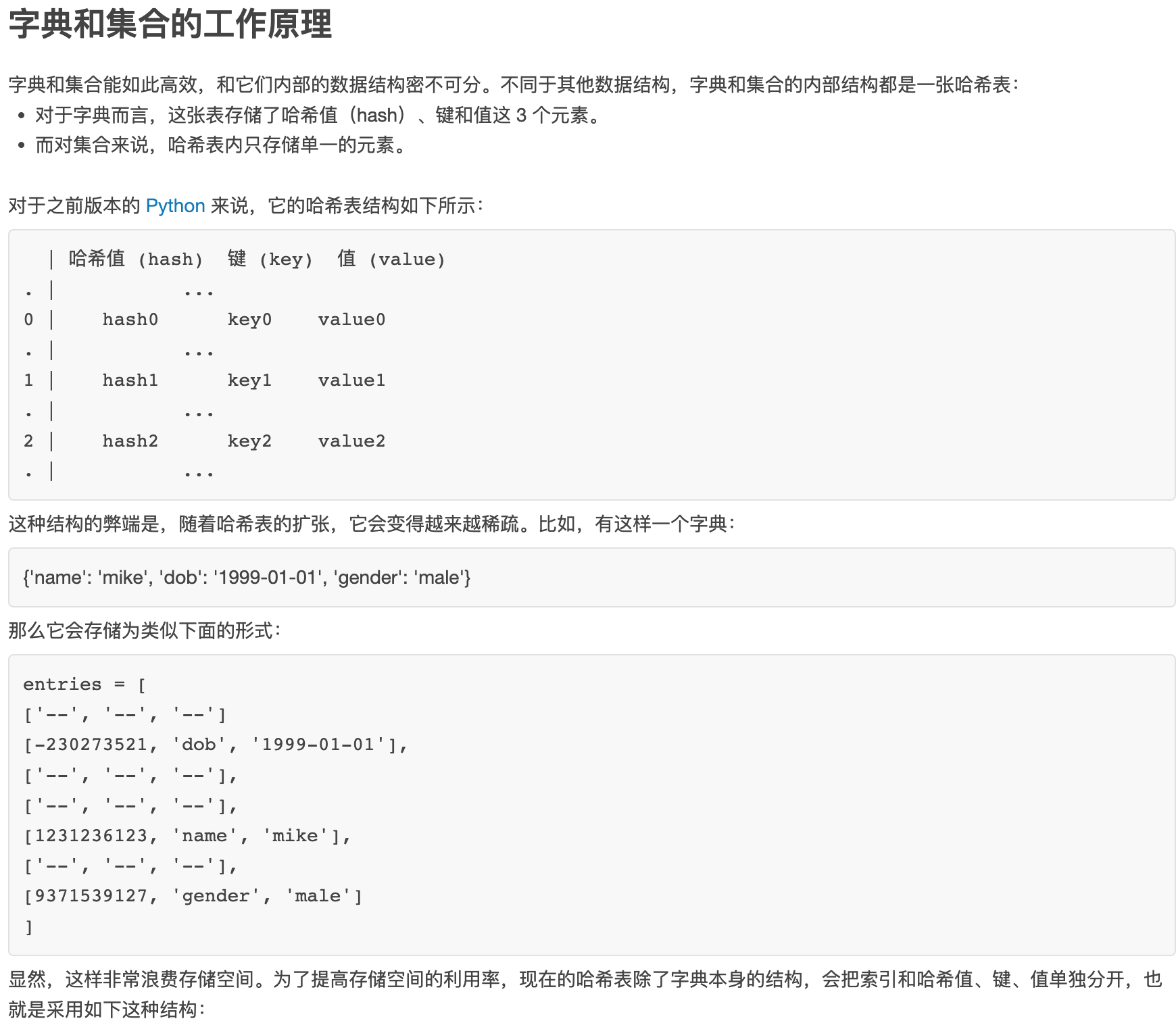
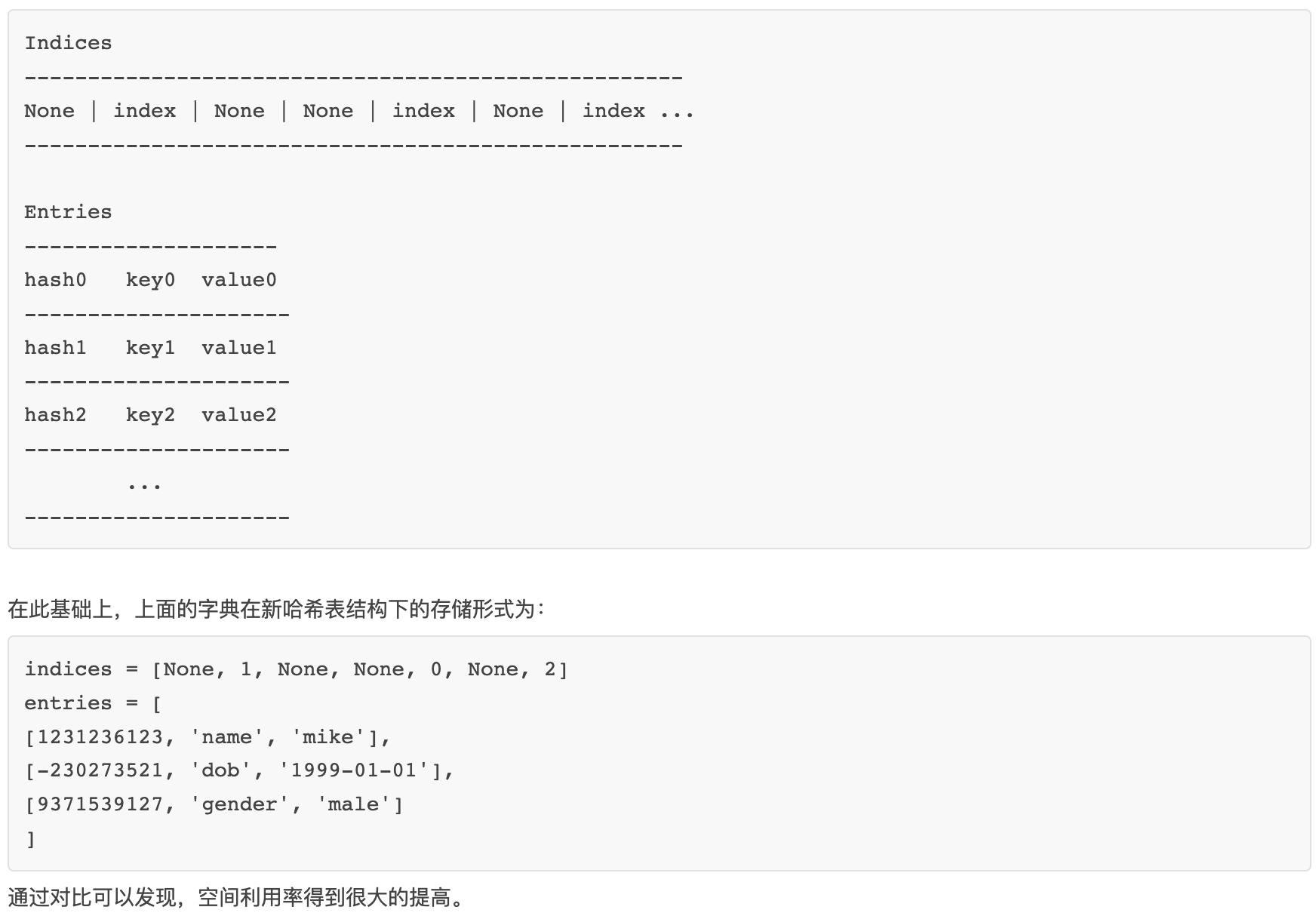
字典是一个存储键值对集合的容器对象,其底层也是一个哈希表。字典 dict 与 集合 set 的区别是它的键不是对象的哈希值,而是 key 的哈希值,并且存储的是 key-value 键值对。
二、内存管理器
Python 内存管理器采用内存池的管理方式。目的:减少内存碎片、提高内存分配效率。
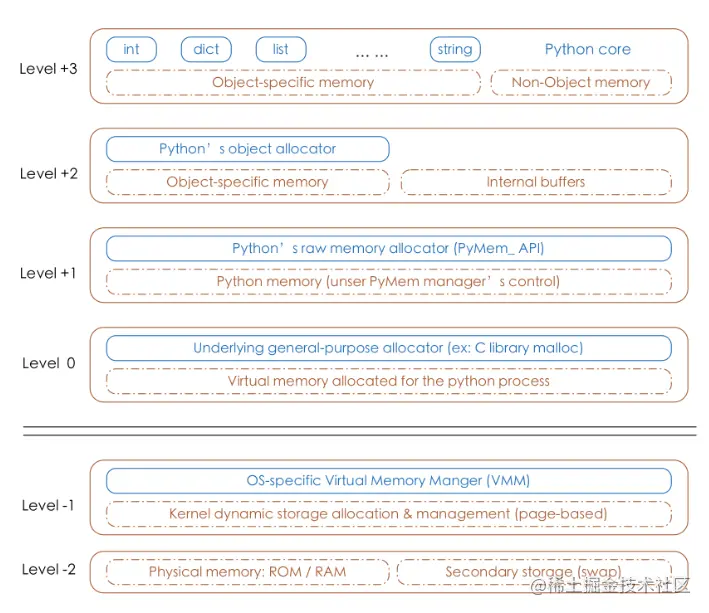
Python 的对象管理主要位于 Level+1 ~ Level+3 层。
1)Level+3 层:通过 FreeList 机制,为每一个 Python 内置对象维护一个空闲内存块链表;
2)Level+2 层:当申请的内存大小小于 256 KB 时,内存分配主要由 Python 对象分配器管理;
3)Level+1 层:当申请的内存大小大于 256 KB 时,由 Python 原生的内存分配器进行分配,即调用maclloc 函数。
三、垃圾回收机制
Python 的垃圾回收机制是以引用计数机制为主,标记-清除和分代收集两种机制为辅的策略。当对象的引用计数为 0 时,该对象就要被回收成垃圾。
a = [1,2]
del a # 对 a 进行解引用,对象[1,2] 的引用计数减1
备注:
垃圾回收与 Redis 的缓存回收策略有相近的思路。频繁的垃圾回收,使得 CPU 被不重要的事情处理,无法处理紧急事情,降低效率。因此,Python 只会在特定条件下,自动启动垃圾回收机制。具体:当 Python 运行时,会记录其中分配对象和取消分配对象的次数。当二者差值高于某个阈值时,垃圾回收才会启动。
1 分代回收
Python 将所有的对象分为 0 1 2 代。创建对象为 0 代对象,当某一代对象经历过垃圾回收,依然存活,就被归入下一代对象,生代越老,回收频率越低。分代回收建立在标记-清除的基础上,不同代数对应一个链表,以空间换时间的方法提高回收效率。
1.1 触发分代回收的例子
(700, 10, 10)
1)700:当分配对象的个数达到 700 时,进行一次 0 代回收;
2)10:当进行 10 次 0 代回收以后触发一次 1 代回收;
3)10:当进行 10 次 1 代回收以后触发一次 2 代回收;
2 标记清除
标记清除算法是一种基于追踪回收技术实现的垃圾回收算法。它分为两个阶段:1)第一阶段是标记阶段,GC 会把所有的”活动对象“打上标记;2)第二阶段把那些没有标记的对象,即非活动对象,进行回收。
具体原理:以对象为有向图的节点,以对象之间的引用关系为有向图的边,构成一个有向图。从根对象(root object)出发,沿着有向边遍历对象,可达的对象标记为活动对象,不可达的对象即为要被清除的非活动对象。【根对象是全局变量、调用栈、寄存器等】
步骤总结:
1)系统每新增 701 个对象,Python 执行一次 GC 操作;
2)一个对象创建后,随着时间推移将被逐步移入老生代,回收频率逐渐降低;
3)每执行 11 次新生代 GC,触发一次中生代 GC;
4)每执行 11 次中生代 GC,触发一次老生代 GC;
5)某个生代需要执行 GC,在它前面的所有年轻生代也同时执行 GC;
6)对多个生代执行 GC,Python 将它们的对象链表拼接在一起,一次性处理;
7)GC 执行完毕后,count 清理,而后一个生代 count 加 1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号