
【总结笔记】深度理解 Web Server 技术 —— 项目整体
https://huixxi.github.io/2020/06/02/小白视角:一文读懂社长的TinyWebServer/#more
1 什么是 Web Server
Web Server 是 通过 HTTP 协议 与客户端进行通信,来接收、存储、处理来自客户端的 HTTP 请求,并对请求进行响应,返回给客户端请求的内容,或返回error。
2 用户如何与Web Server 通信
【这里考察的是客户端从输入ip——TCP三次握手——HTTP请求过程的详细介绍】
3 服务器如何接收客户端发来的 HTTP 请求报文?
【考察网络编程的 4 个步骤基本原理】
该项目通过线程池(半同步半反应堆:因为同步读取客户端的请求数据不是由线程池中的线程来执行的)并发处理用户请求,主线程负责读写,工作线程(线程池中的线程)负责处理请求(例如 HTTP 请求报文的解析)。通过 epoll_wait 监听注册事件,若有事件发生,会返回一个就绪事件队列。对于可读事件,主线程将对应的 socketfd 的数据读进缓存 users[sockfd].read(),然后将该任务对象(指针)插入线程池的请求队列中 pool->append(users + sockfd),线程池的实现需要依靠 锁机制 以及 信号量机制 来实现同步,保证操作的原子性。
3.1 Web Server 监听用户请求的步骤(网络编程的 4 个步骤)
Web Server 通过 socket 监听来自用户的请求。【4 个步骤:创建 socket() —— 为 socket 绑定协议族及监听端口 bind() —— 监听 listen() —— 接收请求 accept() 】
服务器的 listen() 跟 accept() 操作是并发、同时进行的,此处用的是 Epoll I/O 复用 来对 监听 socket(listenfd) 和 连接请求 的同时监听。
3.2 线程池 + epoll I/O 多路复用 + Reactor 模式 实现并发处理就绪文件符的请求
I/O 多路复用本身是阻塞的(若遇 I/O 操作,必须等待 I/O 操作完成才能执行下一步),并且当有多个文件符就绪 sockfd 时,只能串行处理,其他未被处理的文件符就绪 sockfd 只能阻塞。为提高文件描述符 sockfd 的处理效率,使用线程池来实现并发 —— 为每个就绪的 sockfd 分配一个线程进行处理:
if (events[i] & EPOLLIN) { // 对于可读事件
if (users[sockfd].read()) { // 从该就绪事件的文件描述符读取请求数据
thread_pool->append(users + sockfd); // 将数据进行封装并插入请求队列
...
}
}
3.3 事件处理模式 —— Reator 与 Proactor 模式
服务器程序通常需要处理三类事件:
1)I/O 事件【listenfd、读就绪事件、写就绪事件】;2)信号【SIGHUP、SIGKILL】;3)定时事件【SIGALRM】。
有 2 种事件处理模式:Reactor 模式 及 Proactor 模式。
通常使用同步 I/O 模型 (如 epoll_wait 实现监听 + 线程池实现事件处理) 实现 Reactor,使用异步 I/O 模型(如 aio_read 和 aio_write 实现数据读取与写入)实现 Proactor
此项目使用同步 I/O 模拟的 Proactor 事件处理模式 。
3.3.1 Reactor 模式
笼统地说,Reactor 模式有一个服务处理器和多个请求处理器,服务处理器负责接收所有客户端的服务请求,然后根据请求类型,分发给相应的请求处理器。
针对 Web Server 项目,主线程(I/O 处理单元)只负责监听文件描述符 fd 上事件(可读、可写事件)的发生,若有,则立刻通知相应的工作线程,由工作线程处理。
通常使用同步 I/O (如epoll_wait())实现 Reactor;
同步(阻塞) I/O :在一个线程里,若遇到 I/O 操作,必须等待 I/O 操作完成才能执行下一步。
本项目采用 Reactor 模式,主线程获取一个请求,并将其放入任务请求队列,由线程池的线程获取一个任务执行。
Reactor 模式与生产消费者模式的区别是,生产消费者模型无 event- handler,消费者端拿到的数据都是同等类型的。
备注:
1)发布订阅模式与生产消费者模式的区别:发布订阅模式中,订阅者只收到自己订阅的信息,其他信息不接收,即订阅者端收到的数据类型是不同等的。
2)发布订阅模式与 Reactor 模式的区别:Reactor 模式的强调根据不同事件,调用不同的事件处理方式。
3.3.2 Proactor 模式
在 Proactor 模式下,所有的 I/O 操作都交给主线程和 内核 进行处理,工作线程仅负责处理逻辑。如主线程读完成后 users[socket].read(),选择一个工作线程来处理用户请求 thread_pool(users + sockfd)。
通常使用异步 I/O(如 aio_read() 与 ais_write())实现 Proactor
3.4 Epoll 的 2 种模式 —— 使用非阻塞 socket
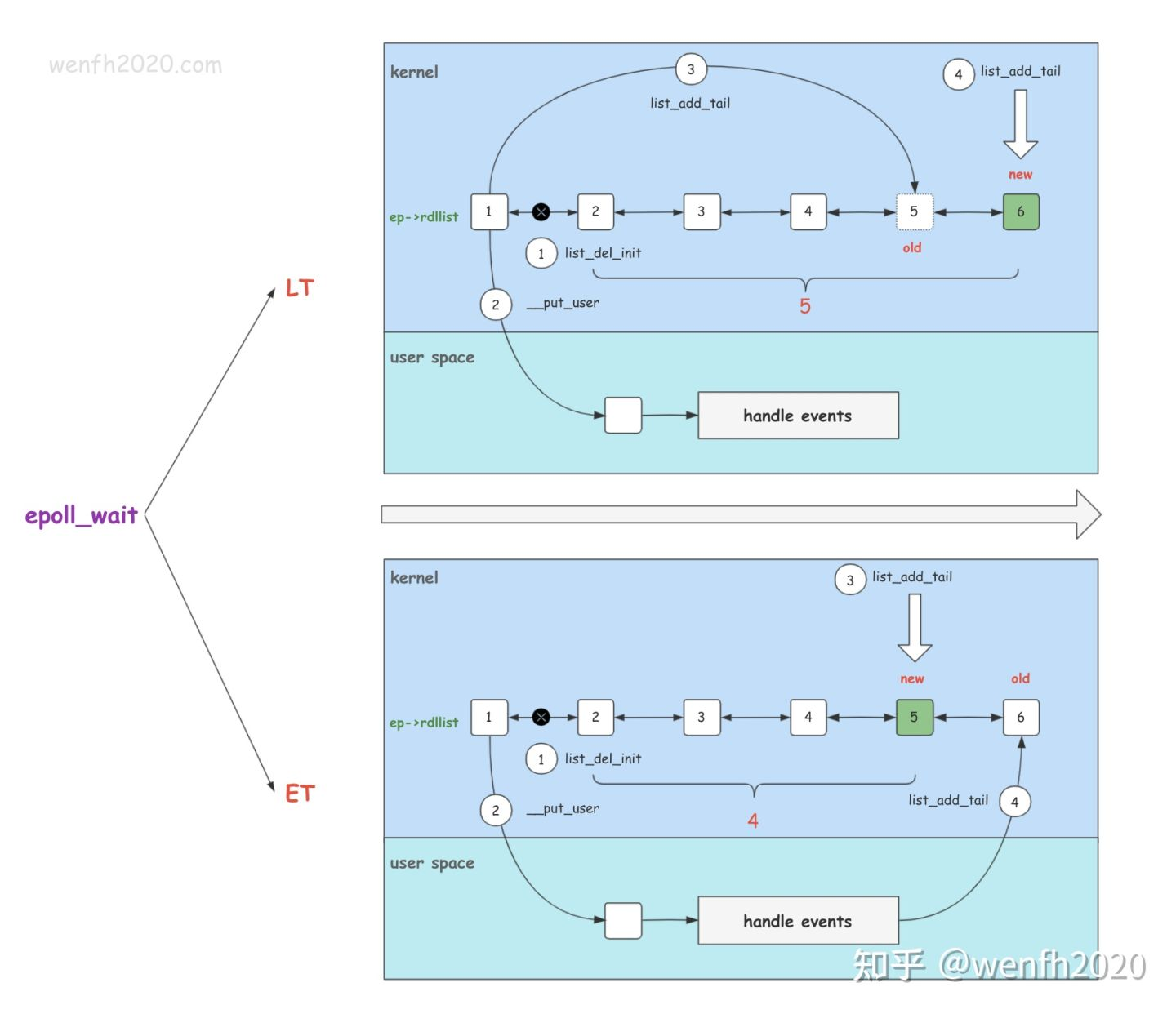
Epoll 的 LT / ET 模式实现逻辑在内核的 epoll_wait 里,epoll_wait 的关键数据结构是事件就绪队列。
LT / ET 模式区别主要有:通知方式,新事件快速处理,避免类似惊群问题。
一般情况下,epoll_ctl 系统调用,除了 Listen socket 的操作是 LT 模式,其他的 socket 处理都是 ET 模式。
Epoll_create() 默认是 LT 模式,所以才有 EPOLLET 属性,ET 模式比 LT 模式要多一次系统调用。
两种模式的区别
1)通知方式不同
LT 持续通知直到事件完毕,ET 只通知一次,不管是否处理完毕。
2)新就绪事件处理速度不同
ET 模式下新就绪事件处理速度快,LT 模式下新就绪事件处理速度慢。【ET 模式适合高并发环境,因为对于海量事件,每个事件都希望自己能够早点被处理,ET 模式在一定程度上能提高事件的处理速度】
- ET 模式:因为上一个就绪事件的数据从内核拷贝到用户空间处理结束后,用户空间根据需要重新将该事件通过 epoll_ctl 添加回就绪队列。这个过程比较漫长,新来的其他事件节点肯定排在旧节点前面。【类似一位同学去食堂排队打包了一份饭,吃完再排队打第二份饭】
- LT 模式:LT 模式下节点从内核拷贝到用户空间,然后又将该事件节点添加回就绪队列,这个速度很快,其他新来的结点很有可能排在已经处理过的事件后面。【类似一位同学排队打了一顿饭,又到达队尾打第二份饭】
![]()
3)能否避免类惊群问题
LT 模式不能会避免类惊群问题,ET 模式能避免类惊群问题。
考虑这样一种情况:多个进程/多个线程共享同一个 epollfd。当某个事件就绪时,多个进程/线程会同时被唤醒。假设只有 A 获取了 CPU 控制权,但没立刻处理该事件,在 LT 模式下,该事件又会放回就绪队列;等下次轮到通知该事件时,所有进程/线程又被唤醒。在 ET 模式下,无论该事件与没有被处理,该事件不会再被通知,即该事件节点被从就绪队列中删除,直到下个事件到来。
两种模式的应用场景
1)LT 模式适合并发量大,且每个连接通信量大的情况。在这种情况下,能够保证连接不会被饥饿。它的解决办法是假设每次连接有 5M 数据要传输,设置每个连接至多能传递 1M 速度,分 5 个连接进行传递。
2)ET 模式适合对用户实时性要求较高的情况,每次尽最大努力读完 5M 数据再处理其他可读事件。
备注:epoll 的数据结构
epoll 有 2 个重要数据结构:rbtree 与 ready list。epoll 是有状态的,内核维护 eventpoll 数据结构来管理所要监视的 fd。在 eventpoll 中有一棵红黑树,用来快速查找和修改要监视的 fd;还有一个 ready list 用来收集已经发生事件的 epitem。
3.4.1 LT(电平触发)
LT(电平触发)类似 select,LT 会去遍历在 epoll 事件表中的每个文件描述符,观察是否有事件发生;
LT 模式的文件描述符也必须是非阻塞,若 epoll 事件未被处理完(没有返回 EWOULDBLOCK),该事件还会被后续的 epoll_wait 触发。
int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength);
// 接着根据该连接描述符处理相关业务
// 如果这次没有处理,下次 epoll_wait 依然会返回这个 listenfd
3.4.2 ET(边缘触发)
使用 ET 模式,文件描述符必须是非阻塞,确保没有数据可读时,该文件描述符不会一直阻塞,并且每次调用 read 和 write 的时候都必须等到它们返回 EWOULDBLOCK(确保所有数据读完或写完)
while (1)
{
int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength);
if (connfd < 0)
{
LOG_ERROR("%s:errno is:%d", "accept error", errno);
break;
}
}
3.5 补充:深入理解 Epoll
3.5.1 数据结构
epoll 有 2 个重要数据结构:rbtree 与 ready list。epoll 是有状态的,内核维护 eventpoll 数据结构来管理所要监视的 fd。在 eventpoll 中有一棵红黑树,用来快速查找和修改要监视的 fd;还有一个 ready list 用来收集已经发生事件的 epitem。
3.5.2 应用场景
epoll 应用,适合海量数据,一个时间段内部分活跃的用户群体。【epoll 应用场景:海量数据、高并发、部分活跃。】
优点:与 select、poll 相比,epoll (的 ET 模式) 能够解决惊群效应。
引用:例如 app,正常用户并不是 24 小时都拿起手机玩个不停,可能玩一下,又去干别的事,回头又玩一下,断断续续地操作。即便正在使用 app 也不是连续产生读写通信事件,可能手指点击几下页面,页面产生需要的内容,用户就去浏览内容,不再操作了。换句话说,在海量用户里,同一个时间段内,很可能只有一小部分用户正在活跃,而在这一小部分活跃用户里,又只有一小撮人同时点击页面上的操作。那 epoll 管理海量用户,只需要将这一小撮人产生的事件,及时通知 appserver 处理逻辑即可。
3.5.3 接口
· epoll_create()
· epoll_ctl(epollfd, 添加/修改操作, socketfd)
· epoll_wait(epollfd, events(ready_list))
1)epoll_create:创建 epoll
epollfd = epoll_create(5);
如果要将 socket fd 写入 epoll 描述符进行监听事件,则:
addfd(epollfd, listenfd, false); // 此 api 是程序员定义的函数,里面的核心系统调用是 epoll_ctl()
2)epoll_ctl:fd 事件注册函数,用户通过这个函数关注 fd 读写事件
//将内核事件表注册读事件,ET模式,选择开启EPOLLONESHOT
void addfd(int epollfd, int fd, bool one_shot)
{
epoll_event event;
event.data.fd = fd;
#ifdef connfdET
event.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
#endif
#ifdef connfdLT
event.events = EPOLLIN | EPOLLRDHUP;
#endif
#ifdef listenfdET
event.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
#endif
#ifdef listenfdLT
event.events = EPOLLIN | EPOLLRDHUP;
#endif
if (one_shot)
event.events |= EPOLLONESHOT;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
备注:理解 EPOLLONESHOT —— 避免同一个 socketfd 被多个线程同时操作
参考链接:https://blog.csdn.net/liuxuejiang158blog/article/details/12422471
epoll 模式中,无论是 LT 还是 ET ,存在同个文件描述符所注册的事件被触发多次的情况。比如 socket 接收到数据交给一个线程处理数据,在数据未处理之前又有新数据达到触发了事件,另一个线程被激活获得该 socket,从而产生多个线程操作同一 socket。例如项目中的:
//处理客户连接上接收到的数据
// events是内核事件表,可以理解为 ready list
else if (events[i].events & EPOLLIN)
{
// 主线程读完成后【users[sockfd].read_once()】,选择一个工作线程来处理客户请求
// 如果未设置 EPOLLONESHOT,sockfd 可能会同时被多个线程所操作
if (users[sockfd].read_once())
{
pool->append(users + sockfd);
}
}
采用 EPOLLONESHOT 事件的文件描述符上的注册事件只触发一次,要想重新注册事件则需要调用 epoll_ctl 重置文件描述符上的事件,这样 socketfd 就不会出现竞态了。
备注:不能将监听描述符 listenfd 设置为 EPOLLONESHOT,否则会丢失客户端连接。
3)epoll_wait:阻塞等待 fd 事件发生
3.5.4 事件
1)EPOLLIN:有可读事件到达;
2)EPOLLOUT:有数据可写;
3)EPOLLERR:文件描述符出错;
4)EPOLLHUP:文件描述符挂断;
5)EPOLLEXCLUSIVE:唯一唤醒事件,解决 epoll_wait 惊群问题。多线程下多个 epoll_wait 同时等待,只唤醒一个 epoll_wait 执行
Linux 的 accept 惊群问题是通过这样的方式解决:当有新的连接进入 accept 队列的时候,内核仅唤醒一个进程来处理。Epoll 的 EPOLLEXCLUSIVE 是告诉内核排他性的唤醒,具体解决办法是通过竞争锁机制实现。但这种方法只能解决先创建 epollfd 再 fork 情况下的惊群效应;无法解决先 fork 再创建 epollfd,同时监听 socketfd 的情况下,导致的 epoll 惊群效应。
-
备注:惊群问题
惊群问题是指多进程(多线程)在同时阻塞等待同一个事件的时候,如果该事件发生,则所有阻塞的进程(线程)都会被唤醒,但最终只有一个进程(线程)获得 CPU 控制权,其他进程(线程又得被阻塞),这造成了严重的系统上下文切换代价。
解决办法:使用锁机制。简单来说,当一个连接来的时候,每个进程的 epoll 事件列表都含有该 fd,抢到锁的进程先释放锁,再 accept,没有抢到锁的进程把该 fd 从事件列表移除,不必再调用 accept,造成资源浪费。惊群效应就是有多个进程/线程同时等待某个事件的发生。当该事件发生时,所有进程/线程都会被唤醒,然而在一个时间段内,只有一个进程/线程获得 CPU 控制权,其他未得到控制权的进程/线程又会阻塞,这种频繁切换导致大量的不必要开销,这种现象叫做惊群效应。在 早起 Linux 中 accpet 会导致惊群问题。解决办法是设置通过锁机制,先获得锁的进程/线程才会被唤醒(这里我觉得好奇怪啊,明明阻塞了,还怎么竞争锁)。在 epoll 里,LT 模式无法避免类惊群问题,但是 ET 模式可以避免惊群问题。假设在这样的场景,多进程/多线程共用同一个 epollfd。某个事件到来,只要一个线程先获得该事件的处理,LT 模式下,如果该线程不处理该事件,内核又会将该事件放回就绪队列,每次通知事件时,所有进程/线程都会被唤醒;而 ET 模式下,可以避免类惊群问题。因为一旦事件被通知,内核都会将其从就绪队列删除。
6)EPOLLET:边缘触发模式
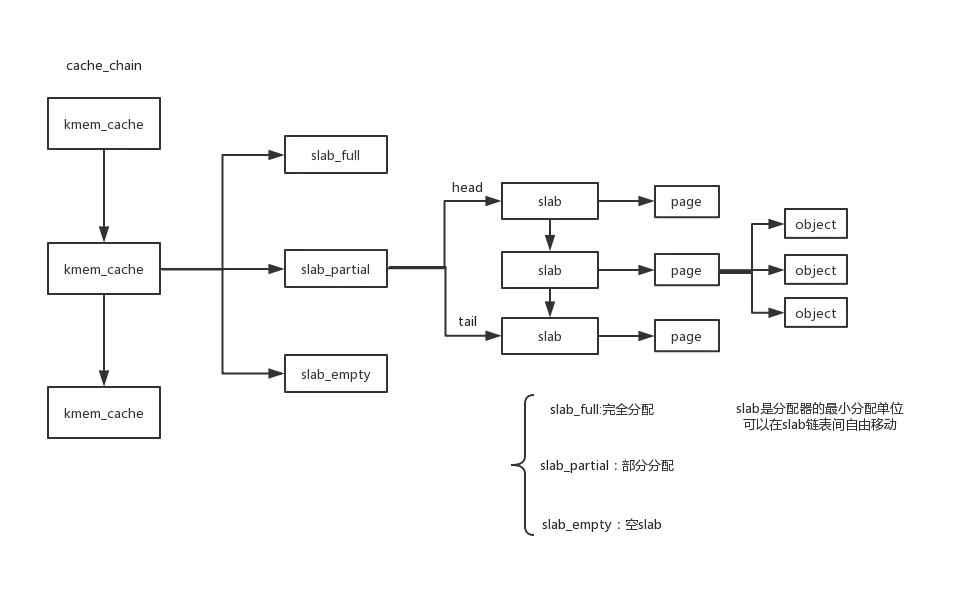
3.5.5 epoll 的初始化 —— slab 算法
这一 小节主要总结 slab 算法
epoll 初始化时,slab 算法为 epoll 分配资源。何为 slab 算法?
slab 是 Linux 的一种内存分配机制。对于一些小内存对象,如进程描述符,如果使用伙伴算法进行分配和释放,不仅会产生大量内存碎片,处理速度也缓慢。slab 分配器就是一个内存池思想。它将相同类型的对象归为一类(如进程描述符就是一类),每当要申请一个这样的对象,就从 slab 列表分配一个单元出去,释放时,又将该单元归回该对象链表中。
3.6 TCP 的阻塞 socket 与非阻塞 socket
3.6.1 阻塞 socket
【什么是阻塞?】当试图对指定的文件描述符进行读写时,若无数据可读或暂时不可写,程序会在读写函数处陷入等待状态,直到满足可读或可写条件才继续执行。当调用 socket API 时,程序阻塞在等待数据。
· 特点:开发网络程序比较简单,容易实现;
· 适用场景:对逻辑简单的客户端程序,采用阻塞 socket,这样实现简单,容易理解。
3.6.2 非阻塞 socket
什么是非阻塞?】若无数据可读或暂时不可写,读写函数会离开返回错误信息,而不会陷入等待状态。把 socket 设置为非阻塞模式,当调用 socket API 时,若当前无可读可写数据,函数会返回一个错误代码(如 EWOULDBLOCK)。
· 特点:开发网络程序比较复杂,需要对错误返回进行处理;
· 适用场景:对于逻辑比较复杂的场景,比如高性能服务器,采用非阻塞 socket,而且要配合 I/O 多路复用机制。
例如项目中的管道写端就被设置成非阻塞状态,若不设置成非阻塞状态,当管道满,缓冲区不可写,会写入阻塞态,会进一步增加信号处理函数的执行时间。
回忆:信号处理函数与管道的关系 —— 当定时器发送定时信号 SIGALRM,内核直接将信号事件(以某数值表示)写入管道写端。主线程若判断当前产生时间的 socketfd 就是管道读端的数据,就判断它是什么事件,并由此进行处理。
3.7 生产者-消费者模型
3.7.1 相关性质
· 需求原因: 因为生产者与消费者的速度往往不一致,引入缓冲区,可以平衡二者的处理能力,同时达到解耦的作用。
· 特点:生产者在缓冲区满的时候不向缓冲区放入数据,消费者在缓冲区空的时候不向缓冲区获取数据,而是陷入休眠状态,直到达到可以向缓冲区放入数据或获取数据,才被唤醒;
· 应用场景:
- Executor 任务执行框架
使用 Executor 构建 web 服务器,用于处理线程的请求:生产者将任务提交给线程池,线程池创建线程处理任务。若需要运行的任务数大于线程池的基本线程数,则把任务丢给阻塞队列。(这种方式比直接把任务丢给阻塞队列更优,因为消费者不需要每次都从阻塞队列获取数据) - 订单的并发处理
电商平台促销活动时,后台不可能同时处理很多订单。用户提交订单就是生产者,处理订单的线程就是消费者。先将用户订单放入一个队列,然后由专门的线程处理订单。 - 长时间处理任务
比如上传附件并处理,可以将用户上传和处理附件分成两个过程。用一个队列暂时存储用户上传的附件,然后立刻返回用户上传成功,然后用专门的工作线程进行处理。
· 优点: - 解耦:将生产者类和消费者类进行解耦;
- 复用:将生产者类和消费者类进行独立开来,可以对生产者类和消费者类进行独立的复用和扩展;
- 调整并发数:由于生产者-消费者的处理速度并不匹配,可以调整并发数,给予慢的一方多的并发数,来提高任务的处理速度;
- 异步:生产者只需要关心缓冲区是否还有数据,无需等待消费者处理完数据;消费者只需要
- 支持分布式:由于生产者与消费者基于队列进行通讯,所以无需运行在同一台机器。在分布式环境中,可以通过 redis 的 list 作为队列。
- 削峰填谷。当生产者流量大的时候,消费者流量小,因为缓冲区的存在,可以填放对象;当生产者流量小,消费者流量多的时候,由于缓冲区有对象预留,所以消费者依然可以继续获取对象。
3.7.2 生产者-消费者模式的实现
实现生产者-消费者模式,需要 保证容器中数据状态的一致性 和 保证生产者和消费者之间的同步。为了实现后者,每次对缓冲区进行访问,都要先获取缓冲区的锁。具体实现是利用信号量:
·(同步信号量)定义 2 个信号量 emptyCount 和 fullCount 分别表示缓冲区满或者空的状态;
·(互斥信号量)定义二进制信号量 useQueue (锁),确保缓冲区数据的完整性。例如不会出现多个生产者向空队列添加数据,使得计数值不一致。
伪代码如下:// 注:不能先 P(useQueue); P(emptyCount) 否则可能会造成死锁
producer:
P(emptyCount);
P(useQueue);
putData();
V(useQueue);
V(emptyCount);
consumer:
P(fullCount);
P(useQueue);
putData();
V(useQueue);
V(fullCount);
3.7.3 Reactor 模式与生产者-消费者模式的区别
从结构上二者很类似,唯一不同是 Reactor 并没有缓冲队列,每当一个 Events 输入到 Reactor,该 Reactor 会主动的根据不同的 Event 类型将其分发给对应的 Request Handler 来处理。
3.8 线程池
3.8.1 为什么使用线程池
在高并发处理环境下,频繁创建和销毁线程需要消耗大量的资源,因此有必要限制程序中同时运行的线程数。
3.8.2 线程池数据结构
线程池是一个 pthread_t 类型的普通数组,程序运行时预先创建若干个 m_thread_number 线程,由这些线程去执行每个请求处理函数(HTTP 请求的 process 函数)。
备注:
1)在实现过程中,将线程设置成脱离态 pthread_detach ,当线程运行结束时,它的资源会被系统自动回收;
2)操作工作队列要加锁(缓冲队列数据一致性问题);
3)使用信号量标识请求队列中的请求数(同步问题),通过 m_queuestat.wait() 来等待一个请求队列中
// 主函数创建结构体为http_conn的线程池
threadpool<http_conn> *pool = NULL;
pool = new threadpool<http_conn>(connPool);
// 线程池的每个线程一被创建,就自动调用 worker 函数,而 woker 函数里又调用 run 函数
void *threadpool<T>::worker(void *arg)
{
threadpool *pool = (threadpool *)arg;
pool->run();
return pool;
}
void threadpool<T>::run()
{
while (!m_stop)
{
m_queuestat.wait(); // P(fullCnt)
m_queuelocker.lock(); // P(mutex)
T *request = m_workqueue.front();
m_queuelocker.unlock(); // V(mutex)
request->process();
}
}
3.8.3 线程池中的线程数量如何确定?
最直接的限制因素是 CPU 的数量 N,对于 CPU 密集型任务,线程池的数量最好等于 CPU 的数量;对于 IO 密集型任务, 线程池的数量一般大于 CPU 的数量。因为线程间竞争的是 CPU,而 IO 处理一般比较慢。
从 3 个场景角度回答。
线程池线程的个数的设置遵循这么一个原则:
1)线程等待时间所占比例越高,需要启动越多其他线程,依次继续使用 CPU,提高 CPU 的利用率;
2)线程 CPU 时间所占比例越高,需要越少的线程,以避免线程间频繁的切换。
· 场景 1:对于计算机密集型,线程的个数设置为 CPU 的个数 + 1(N+1)—— 经验值;
· 场景 2:对于 IO 密集型,线程的个数设置为两倍的 CPU 个数(2N)—— 经验值
· 场景 3:对于一个任务包含了计算操作和 IO 操作,可以通过如下思路计算:


3.9 两种请求报文
HTTP 请求报文由请求行、请求头部(报头字段)、空行和请求数据(Body)等 4 个部分组成。包括 GET 和 POST 两种请求。
3.9.1 GET
// ① 请求行
GET /route/xxx.jpg HTTP/1.1
// ② 请求头
Host: img.mukewang.com
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept:image/webp,image/*,*/*;q=0.8
Referer:http://www.imooc.com/
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
// ③ 空行
// ④ 请求数据为空
3.9.2 POST
// ① 请求行
POST / HTTP1.1
// ② 请求头
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
// ③ 空行
// ④ post 请求表单数据
name=Professional%20Ajax&publisher=Wiley
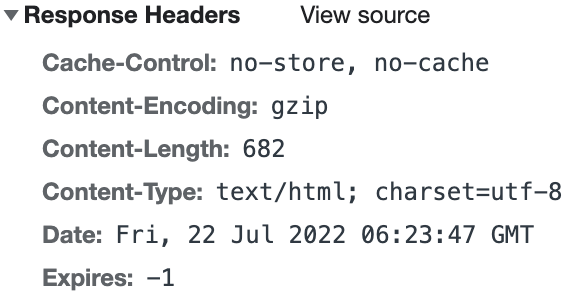
HTTP 响应头(Reponse Headers)有哪些报文段?
1)Cache-Control:缓存控制
2)Content-Encoding:报文编码方式
3)Content-Length:报文长度
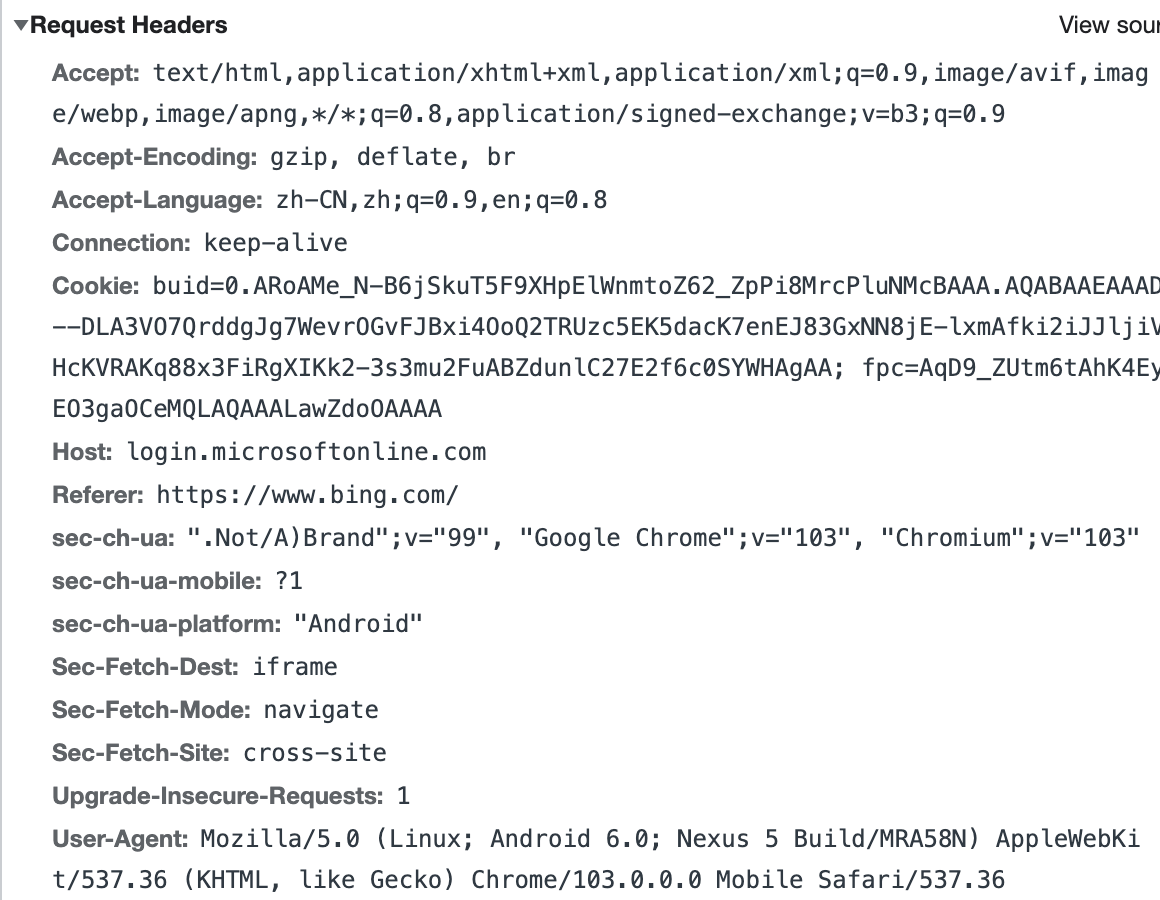
HTTP 请求头(Request Headers)有哪些报文段?
1)Connection:连接方式 (Keep-alive)
2)Cookie:包含 token
3)Referer:指示发起这个请求的上一个页面
4)Host:服务端地址
3.9.3 GET 和 POST 的区别
1)GET 把参数放在 URL 中,而 URL 的长度是有限制的,因此 GET 的参数长度有限制;
而 POST的参数放在 body 中,无参数长度限制;
2)GET 的请求参数会缓存在浏览器,它的请求结果也会缓存在浏览器,因此是可以回退的,并且回退不会再次发起 GET 请求;
而 POST 的请求参数并不会缓存在浏览器;
3)GET 发一次 TCP 数据包,浏览器将请求头和请求数据一起发送给服务器(空行以上的数据);
而 POST 发两次 TCP 数据包,浏览器第一次先发包含请求头的数据包给服务器,若服务器响应 100 (临时响应,需要请求者执行操作才能继续执行),第二次发包含请求数据的数据包给服务器,服务器响应 200.
4 服务器对 HTTP 连接 的 process 过程
服务器对 HTTP 连接 的 process 过程包括对请求处理读过程process_read() + 对请求处理写过程process_write()。
对请求处理读过程是对 HTTP 请求进行解析,对请求处理写过程是对 HTTP 请求返回响应码及响应文件数据。
不考虑鲁棒性的代码如下:
void http_conn::process()
{
HTTP_CODE read_ret = process_read();
bool write_ret = process_write(read_ret);
modfd(m_epollfd, m_sockfd, EPOLLOUT);
}
4.1 服务器如何对 HTTP 请求进行解析
- 服务器使用 主从状态机 的模式进行解析。从状态机负责读取报文的一行,主状态机负责对该行数据进行解析。主状态机内部调用从状态机,从状态机驱动主状态机。每解析一部分都会将整个请求的状态改变,状态机也主要是根据这个状态码来进行不同部分的解析跳转。
- 解析完毕,得到一个正确的 HTTP 请求。执行
do_request()代码部分。首先需要对 GET 请求和不同 POST 请求(登陆、注册、请求图片等)做不同的预处理,分析目标文件的属性, 然后判断目标文件是否存在,再判断是否可读,若是则使用mmap将其映射到内存地址m_file_address处,并告诉调用者获取文件成功return FILE_REQUEST。
不鲁棒的代码:
http_conn::HTTP_CODE http_conn::process_read() {
while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK))
{
switch (m_check_state)
{
case CHECK_STATE_REQUESTLINE:
ret = parse_request_line(text);
case CHECK_STATE_HEADER:
ret = parse_headers(text);
case CHECK_STATE_CONTENT:
{
{
ret = parse_content(text);
return do_request();
}
}
default:
return INTERNAL_ERROR;
}
}
}
http_conn::HTTP_CODE http_conn::do_request()
{
if (cgi == 1 && (*(p + 1) == '2' || *(p + 1) == '3'))
{
//同步线程登录校验
if (*(p + 1) == '3')
//如果是登录,直接判断
//若浏览器端输入的用户名和密码在表中可以查找到,返回1,否则返回0
else if (*(p + 1) == '2')
else if (*(p + 1) == '0')
....
}
else
strncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);
int fd = open(m_real_file, O_RDONLY);
m_file_address = (char *)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
close(fd);
return FILE_REQUEST;
}
4.2 服务器生成 HTTP 响应并返回给用户
接着根据读取结果对用户作出响应,即process_write()。若返回的是错误结果,则根据对应的错误类型,返回错误信息。若用户请求的文件存在,前面已经将其 mmap 到 m_file_address ,将响应行、响应头写到 connfd 的写缓存 m_write_buf,然后将该 connfd 修改为 EPOLLOUT 事件,使用 writev将相应信息和请求文件 聚集写 (m_iv[0].iov_base = m_write_buf; m_iv[1].iov_base = m_file_address;)到 TCP Socket 本身的发送缓冲区(缓冲区大小可以通过 setsocketopt 来修改),交由内核发送给用户。
备注:http 连接对象与连接描述符 connfd 的关联逻辑
主程序一运行就创建了 http_conn 对象数组,服务器在 accept 的时候会给每个新连接分配 1 个连接描述符 connfd,将连接描述符作为下标,取对应的 http 连接对象
// 服务器为每个分配连接描述符,服务器最多支持 MAX_FD=65535 个连接
// 将连接描述符作为下标,取对应的 http 连接对象
http_conn *users = new http_conn[MAX_FD];
// 处理新到的客户连接
int sockfd = events[i].data.fd;
if (sockfd == listenfd)
{
// 该连接分配的文件描述符
int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength);
}
不鲁棒的代码:
bool http_conn::process_write(HTTP_CODE ret)
{
switch (ret)
{
case INTERNAL_ERROR:
{
add_status_line(500, error_500_title);
add_headers(strlen(error_500_form));
break;
}
case BAD_REQUEST:
{
add_status_line(404, error_404_title);
add_headers(strlen(error_404_form));
if (!add_content(error_404_form))
return false;
break;
}
case FORBIDDEN_REQUEST:
{
add_status_line(403, error_403_title);
add_headers(strlen(error_403_form));
break;
}
case FILE_REQUEST:
{
add_status_line(200, ok_200_title);
if (m_file_stat.st_size != 0)
{
add_headers(m_file_stat.st_size);
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv[1].iov_base = m_file_address;
m_iv[1].iov_len = m_file_stat.st_size;
m_iv_count = 2;
bytes_to_send = m_write_idx + m_file_stat.st_size;
return true;
}
else
{
const char *ok_string = "<html><body></body></html>";
add_headers(strlen(ok_string));
if (!add_content(ok_string))
return false;
}
}
}
}
在主程序的 EPOLLOUT 事件处理部分处,调用write()函数。不鲁棒性代码如下:
bool http_conn::write()
{
int temp = 0;
while (1)
{
temp = writev(m_sockfd, m_iv, m_iv_count);
bytes_have_send += temp;
bytes_to_send -= temp;
if (bytes_have_send >= m_iv[0].iov_len)
{
m_iv[0].iov_len = 0;
m_iv[1].iov_base = m_file_address + (bytes_have_send - m_write_idx);
m_iv[1].iov_len = bytes_to_send;
}
else
{
m_iv[0].iov_base = m_write_buf + bytes_have_send;
m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;
if (bytes_to_send <= 0)
{
unmap();
modfd(m_epollfd, m_sockfd, EPOLLIN);
}
}
}
4 数据库连接池
如果每次用户请求我们都需要创建、销毁一个数据库连接,在请求量大的时候,严重影响服务器性能,使用数据库连接池,预先生成一些数据库连接,供用户请求使用。与线程池一样,数据库池需要使用锁机制保证互斥,使用信号量最大连接数 MAX_CONN 、 当前可用连接数 FREE_CONN 、当前已用连接数 CUR_CONN 保证同步。
4.1 数据库连接生成步骤:
1)使用 mysql_init() 初始化连接
con = mysql_init(con);
2)使用 mysql_real_connect() 建立一个到mysql数据库的连接
con = mysql_real_connect(con, url.c_str(), User.c_str(), PassWord.c_str(), DBName.c_str(), Port, NULL, 0);
3)使用 mysql_query() 执行查询语句
mysql_query(mysql, "SELECT username,passwd FROM user")
4)使用 result = mysql_store_result(mysql) 获取结果集
MYSQL_RES *result = mysql_store_result(mysql);
5)使用 mysql_num_fields(result) 获取查询的列数,mysql_num_rows(result) 获取结果集的行数
//返回结果集中的列数
int num_fields = mysql_num_fields(result);
6)通过mysql_fetch_row(result)不断获取下一行,然后循环输出
//从结果集中获取下一行,将对应的用户名和密码,存入map中
while (MYSQL_ROW row = mysql_fetch_row(result))
{
string temp1(row[0]);
string temp2(row[1]);
users[temp1] = temp2;
}
4.2 RAII 机制在数据库连接池上的使用
4.2.1 什么是 RAII 机制
RAII (Resource Acquisition is Initialization)资源获取即初始化。采用的是使用局部对象来管理资源。局部对象是指存储在栈的对象,它的生命周期由操作系统管理。由于 C++ 保证已构造的对象最终会销毁,即它的析构函数最终会被调用。因此 RAII 机制在获取资源时,构造一个临时对象。在临时对象生命周期内保持对资源访问的有效性,在临时对象析构的时候释放资源,避免资源泄漏。使用 RAII 机制,必须在构造函数中初始化 connectionRAII(MYSQL **con, connection_pool *connPool);
4.2.2 RAII 机制如何在数据库连接池上使用
项目在定义 class connection_pool 并没有为其定义构造函数跟析构函数,也就是说 connection_pool 仅仅是个结构体。
定义封装类 class connectionRAII ,在构造函数中获取连接池的一条连接 connPool->GetConnection(); ,在析构函数中释放获取的这条连接。
如果不使用 connectionRAII mysqlcon(&mysql, connPool); 而是直接调用 connPool->GetConnection(); 程序员可能在 http_conn::initmysql_result() 后面忘记释放这条连接。
class connectionRAII{
public:
connectionRAII(MYSQL **con, connection_pool *connPool);
~connectionRAII();
private:
MYSQL *conRAII;
connection_pool *poolRAII;
};
connectionRAII::connectionRAII(MYSQL **SQL, connection_pool *connPool){
//当有请求时,从数据库连接池中返回一个可用连接,更新使用和空闲连接数
*SQL = connPool->GetConnection();
conRAII = *SQL;
poolRAII = connPool;
}
connectionRAII::~connectionRAII(){
poolRAII->ReleaseConnection(conRAII);
}
//释放当前使用的连接
bool connection_pool::ReleaseConnection(MYSQL *con)
{
if (NULL == con)
return false;
lock.lock();
connList.push_back(con);
++FreeConn;
--CurConn;
lock.unlock();
reserve.post();
return true;
}
主程序运行时,调用 initmysql_result() 初始化数据库读取表,在 initmysql_result() 中初始化局部变量 RAII 连接池对象 ,当函数结束时,局部变量调用对象的析构函数
/*主程序*/
//初始化数据库读取表
users->initmysql_result(connPool);
/*http 类程序*/
void http_conn::initmysql_result(connection_pool *connPool)
{
...
connectionRAII mysqlcon(&mysql, connPool);
...
}
5 服务器优化:定时器处理非活动连接
项目中,主程序一运行就分配了 MAX_FD = 65535 个 HTTP 连接对象:
// 创建连接资源数组
client_data *users_timer = new client_data[MAX_FD];
若某连接对象与服务器建立连接后,长时间不交换数据,一直占用这个连接描述符,可能导致其它连接无法建立。所以要利用定时器,释放掉超时的非活动连接的连接描述符。(例如登陆网站长时间不操作,再次访问时需要重新登陆)。
项目中使用的是 SIGALRM信号 来实现定时器,利用 alarm 函数周期性的出发 SIGALRM信号,信号处理函数利用 管道 通知主循环线程,主循环收到该信号后,对时间轮上的所有定时器进行处理。
// 处理异常事件
else if (events[i].events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR))
{
//服务器端关闭连接,移除对应的定时器
time_wheel_timer *timer = users_timer[sockfd].timer;
timer->cb_func(&users_timer[sockfd]);
if (timer)
{
// timer_lst.del_timer(timer);
timeWheel.del_timer(timer);
}
}
5.1 高性能定时器之时间轮定时器
定时器一般有 3 种实现方式:升序链表,时间轮、时间堆。其中时间轮定时器、时间堆定时器是高性能定时器。
相比升序链表定时器,时间轮能提高性能的原因是:时间轮用数组存储多条定时器链表,对每一条定时器链表的插入操作明显提升。
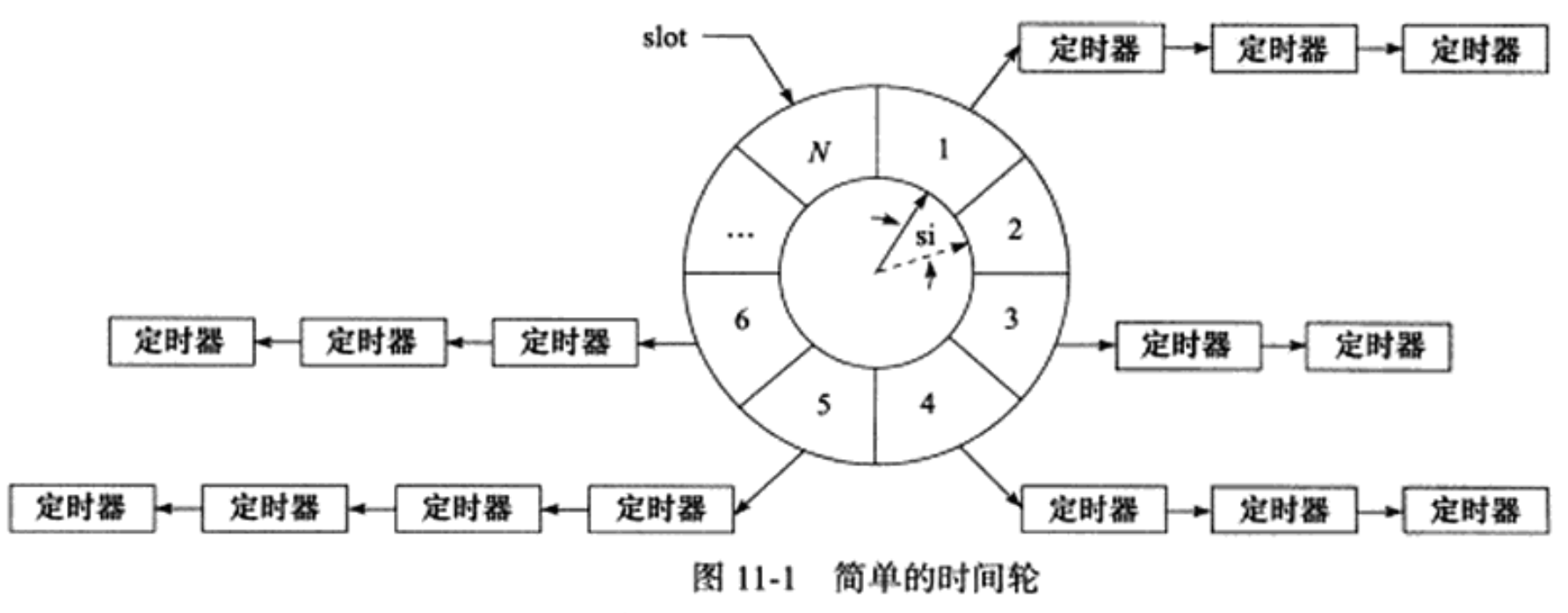
5.1.1 时间轮数据结构
主要数据结构: 存储多条升序链表的数组
class time_wheel
{
private:
static const int N = 60; // 时间轮上的槽的数目
static const int SI = 1; // 每1s时间轮轮动一次,槽间隔为1s
time_wheel_timer *slots[N]; // 时间轮的槽,其中每个元素指向一个定时器链表,链表无序
int cur_slot; // 时间轮的当前槽
public:
// 根据定时值 timeout 创建一个定时器,并把它插入合适槽中
time_wheel_timer *add_timer(int timeout);
// 删除定时器
void del_timer(time_wheel_timer *timer);
// SI时间到后,调用该函数,时间轮向前滚动一个槽的间隔
void tick();
}
5.1.1 定时器数据结构
记录该定时器所属槽、失效圈数(也就是说定时器记录的是倒计时)、前后定时器指针、定时回调函数。
class time_wheel_timer
{
public:
int rotation; // 记录定时器在时间轮转多少圈后失效
int time_slot; // 记录定时器属于时间轮上的哪个槽
void (*cb_func)(client_data*); // 定时器回调函数
client_data *user_data; //客户数据
time_wheel_timer *next;
time_wheel_timer *prev;
public:
time_wheel_timer(int rot, int ts) : next(NULL), prev(NULL), rotation(rot), time_slot(ts) {}
};
tick 的逻辑是每到达一个槽,就遍历该槽的所有定时器对象,将该对象的剩余失效圈数减 1,如果已经减至 1,则将其从链表删除。
// SI时间到后,调用该函数,时间轮向前滚动一个槽的间隔
void time_wheel::tick() {
time_wheel_timer *tmp = slots[cur_slot]; // 取得当前槽上头结点
while (tmp)
{
// 如果定时器的rotation值大于0,则在这一轮不起作用
if (tmp->rotation > 0) {
tmp->rotation--;
tmp = tmp->next;
}
//否则说明定时器已经到期,于是执行定时任务,然后删除该定时器
else {
tmp->cb_func(tmp->user_data);
if (tmp == slots[cur_slot]) {
slots[cur_slot] = tmp->next;
delete tmp;
if (slots[cur_slot]) {
slots[cur_slot]->prev = NULL;
}
tmp = slots[cur_slot];
}
else {
tmp->prev->next = tmp->next;
if (tmp->next) {
tmp->next->prev = tmp->prev;
}
time_wheel_timer *tmp2 = tmp->next;
delete tmp;
tmp = tmp2;
}
}
cur_slot = ++cur_slot % N;
}
}
5.2 高性能定时器之时间堆定时器
时间堆与时间轮的区别是,时间轮采用固定值为心搏间隔(触发一次 tick),而时间堆是将所有定时时间最小的一个定时器的超时值作为心搏间隔。具体实现:每个定时器记录的是到期的绝对时间,tick() 函数创建计数时间变量,不断最小堆顶定时器是否到期,若到期则删除堆顶元素,并调整最小堆。
5.3 3 种主流定时器优缺点对比
1)升序链表使用绝对到期时间,的插入时间为 O(n) 【插入排序时间复杂度】,删除时间为 O(1)【删除链表头结点时间复杂度】;
- 优点:实现简单;缺点:插入时间复杂度过高;
2) 时间堆的插入时间为 O(lgn)【调整小顶堆的时间复杂度】,删除时间为 O(1)【删除堆顶】;
- 优点:节省内存消耗,适合任务量小、并发量小的场景;缺点:插入时间比时间轮慢,不适用任务量大、并发量大的场景
3) 时间轮的插入时间为 O(1)【有N多个升序链表,可看成插入时间复杂度为 O(1)】,删除时间为 O(1)【删除堆顶时间复杂度】
- 优点:插入和删除操作都很快,适合任务量大、并发量大的场景;- 缺点:需要维护很大的数组,开销大。
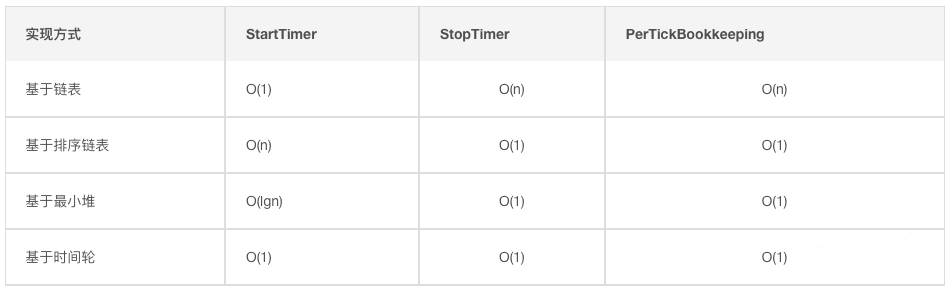
升序链表根据到点绝对时间,升序插入,时间复杂度为O(n),删除的时候删除链表头,时间复杂度为O(1);
时间堆插入需要调整对顶,时间复杂度为O(logn),删除时删除堆顶,为O(1);
时间轮由于有哈希映射,找到槽的时间段复杂度为O(1),每个槽的链表很短,可看成插入删除操作为O(1)
5.4 时间轮定时器处理非活动连接
服务器主循环为每一个连接创建一个定时器,并对每个连接进行定时。具体的:利用 alarm 函数周期性地触发 SIGALRM 信号,信号处理函数利用管道通知主循环。主循环接收到信号或,对时间堆上的定时器进行处理。【定时方法与信号通知流程;定时器及其容器设计与定时任务的处理】
5.4.1 信号通知流程
Linux 下的信号采用异步处理机制。信号处理函数和当前线程是两条不同的执行路线。具体的,当线程收到信号时,操作系统会中断线程当前的正常流程,转而进入信号处理函数执行操作,完成后再返回中断的地方继续执行。
问题:由于要避免信号竞态现象发生,信号处理期间系统不会再次触发它。但是,如果信号处理函数执行时间过长,会导致信号屏蔽太久。
解决方案:信号处理函数仅仅发送信号通知主循环,将信号对应的处理逻辑放在程序主循环中,由主循环执行信号对应的逻辑代码。
【信号竞态现象:指由于系统不恰当的执行顺序,导致本该到达并响应的信号没有被响应】
5.4.2 统一事件源
即将信号事件与其他事件一样被处理。
解决办法:使用管道传信号值
具体:信号处理函数使用管道将信号传递给主循环,信号处理函数往管道的写端写入信号值,主循环则从管道的读端读出信号值。使用 I/O 复用系统调用来监听管道读端的可读事件,这样信号事件与其他文件描述符可通过 epoll 来监测,从而是实现统一处理。
5.4.3 信号处理机制
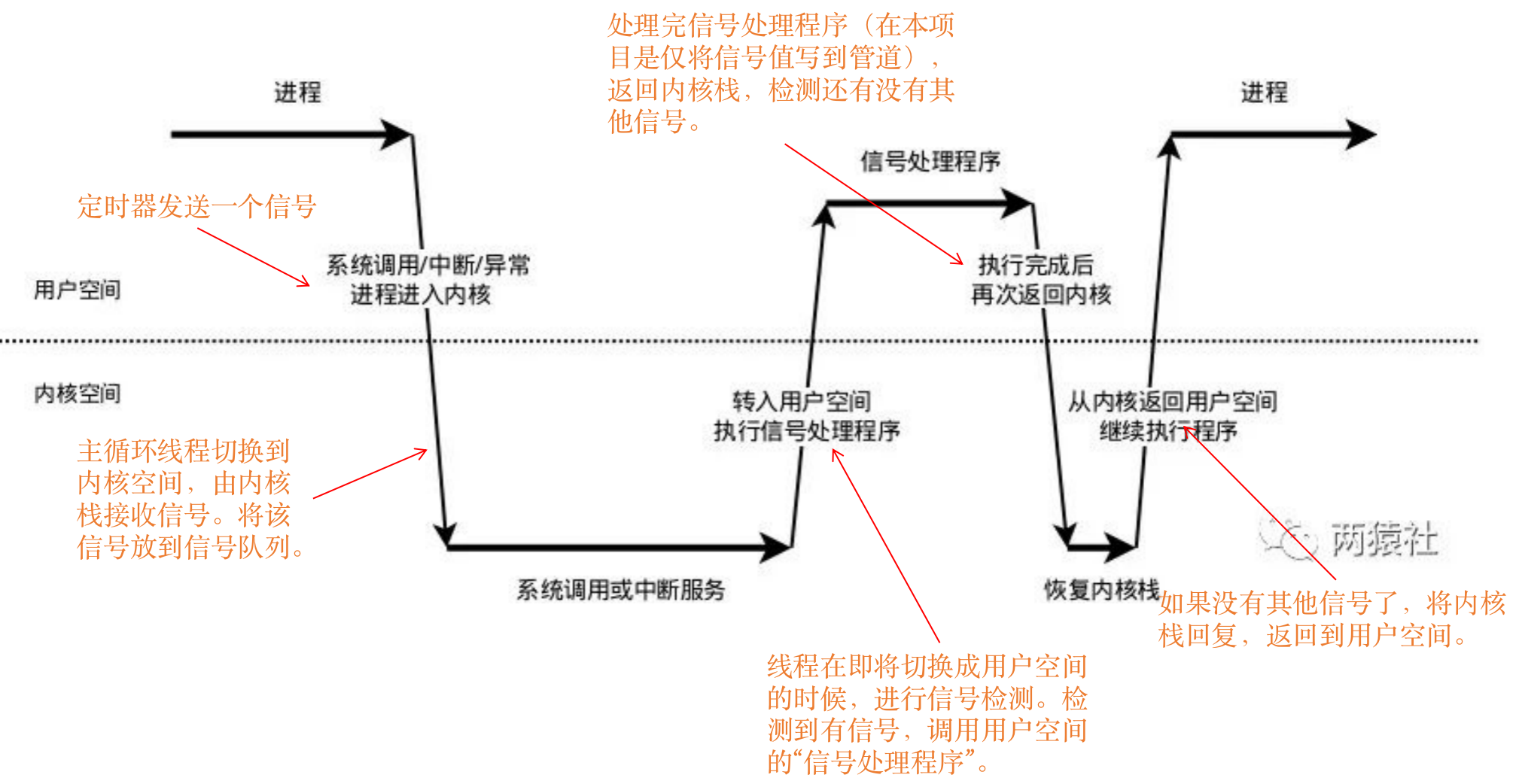
5.4.4 信号通知逻辑
1)创建管道,其中管道写端写入信号值,管道读端通过 I/O 复用系统检测读事件;
//创建管道
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd);
assert(ret != -1);
// 设置写端非阻塞:若不设置非阻塞,则若缓冲区满导致阻塞,会进一步增加信号处理函数的执行时间
setnonblocking(pipefd[1]);
// 设置读端为 ET 非阻塞
addfd(epollfd, pipefd[0], false);
2)设置信号处理函数 SIGALRM(时间到会触发)和 SIGTERM(kill 会出发,ctrl+c);
addsig(SIGALRM, sig_handler, false);
// 设置 SIGTERM,kill 会触发
addsig(SIGTERM, sig_handler, false);
//设置信号函数
void addsig(int sig, void(handler)(int), bool restart = true)
{
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = handler;
if (restart)
sa.sa_flags |= SA_RESTART;
sigfillset(&sa.sa_mask);
// 设置信号捕捉函数
assert(sigaction(sig, &sa, NULL) != -1);
}
//信号处理函数:仅通过管道发送信号值,不处理信号对应的逻辑,缩短异步执行时间,减少对主程序的影响
void sig_handler(int sig)
{
//为保证函数的可重入性,保留原来的errno
int save_errno = errno;
int msg = sig;
// 将信号值从管道写端写入,传输字符类型,而非整型
send(pipefd[1], (char *)&msg, 1, 0);
errno = save_errno;
}
3)利用 I/O 复用系统监听管道读端文件描述符的可读事件;
while (!stop_server)
{
//监测发生事件的文件描述符
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
...
}
4)信号值传递给主循环,主循环再根据接收到的信号值执行目标信号对应的逻辑代码。
5.4.5 为什么管道写端要非阻塞?
信号处理函数是将信号值 send() 给 socket 缓冲区。若缓冲区满,则会阻塞,这会增加信号处理函数的执行时间。由前述可知,为了避免信号竞态现象,需要尽量减少信号执行函数的执行时间。
备注:由于管道写端设置为非阻塞,所以这次信号会失效。但定时事件是非必须立即处理的事件,可以允许这样的情况发生。
备注:QPS(Query Per Second) 与 TPS(Transaction Per Second) 的区别
1)Tps 即每秒处理事务数,一个事务包括了
用户请求服务器
服务器自己的内部处理
服务器返回给用户
2)QPS 即每秒查询数,它是对一个特定的查询服务器在规定时间内所处理流量的衡量标准。
二者差异:
一个页面的一次请求,形成一个TPS;
但一个页面的请求,可能产生多次对服务器的请求,这些请求计入 QPS。
所以,QPS 大于等于 TPS.
6 内存池压力测试
CLOCKS_PER_SEC = 1000000
BenchmarkConcurrentMalloc:
10000 个线程并发执行 10 轮次,每轮次malloc 100次: 花费 2.278 s
10000 个线程并发执 10 轮次,每轮次free 100 次: 花费 1.191 s
10000 个线程并发 malloc&free 10,000,000次,总计花费 3.470 s
BenchmarkMalloc:
10000 个线程并发执行 10 轮次,每轮次malloc 100次: 花费 4 ms
10000 个线程并发执 10 轮次,每轮次free 100 次: 花费 3 ms
10000 个线程并发 malloc&free 10,000,000次,总计花费 6ms
结论:使用 TLS 内存池,申请内存与释放内存都远远大于直接调用系统 malloc 和 free。原因:估计是 Ubuntu 系统的 malloc 做了池化优化。
7 未使用内存池的服务器的压力测试
1)仅考虑 Reactor + LT(Listenfd)+ ET(connfd):
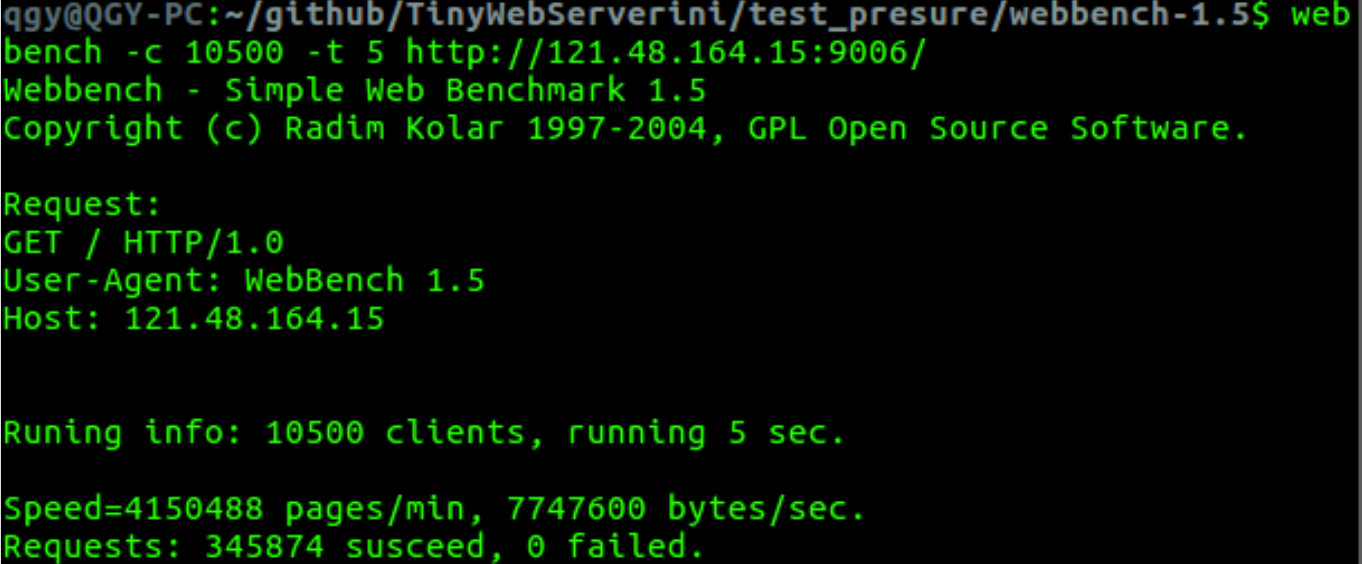
并发连接总数:10500
访问服务器时间:5s
每秒钟响应请求数:415,0488 pages/min 【QPS】
每秒钟传输数据量:7747600 bytes/sec
所有访问均成功
2)在1)的基础上使用压测
并发连接数仅有四五千,QPS 1w多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号