

数据结构复习
数据结构
数组、字符串、链表、树、栈、队列。
1.数组
数组占着一段连续的内存进行存储的数据结构。在创建数组时,需要指定数组的容量大小,先为其分配内存。即时只在数组中存放一个数字,也要为其预先分配所有的内存。
由于内存连续,可以在O(1)的时间直接进行读写,时间效率高。可以利用这个优点来创建哈希表。数组下标作为key,下标对应的内容作为value,组成了健值对的配对。
动态数组可以解决数组空间效率不高的问题,如c++的stl中的vector。先开辟较小的空间,当空间不足时,重新分配一块原来空间两倍的空间。将数据转移到新数组中,将之前的数组内存释放。但是这样也对时间性能有负面影响。所以动态数组要尽量少改变容量大小的次数
创建一个数组时,数组名其实就是一个指针,指向数组的第一个元素。同样也可以通过指针来访问数组,前提要注意确保不要超出数组的边界。
(在c/c++中,将数组作为函数参数传递时,会退化为同类型的指针。)
练习:二维数组查询
2.字符串
C/C++中每个字符串都是以‘\0’结束,要注意是否造成了字符串的越界。
为了节省内存,c/c++把常量字符串存放到一个单独的内存区域,当指针赋值给相同的字符串时,他们其实会指向同一个地址。
char str1[] = "hello";
char str2[] = "hello";
//str1和str2是两个字符串数组,分别开辟了不同的空间,所以str1和str2不同
char* str3 = "hello";
char* str4 = "hello";
//str3和str4是两个指针,无需分配内存以存储字符串内容,只要将其指向“hello”的地址即可。
String对象一旦被创建就是固定不变的了,对String对象的任何改变都不影响到原对象,相关的任何change操作都会生成新的对象。
字符串常量池:
每当我们创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就直接返回常量池中的实例引用。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中。由于String字符串的不可变性我们可以十分肯定常量池中一定不存在两个相同的字符串。
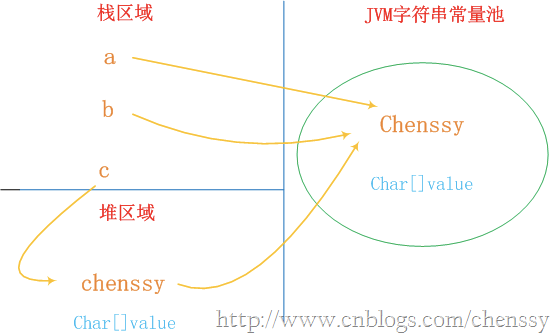
String a = "chenssy";
String b = "chenssy";
String c = new String("chenssy");
a、b和字面上的chenssy都是指向JVM字符串常量池中的"chenssy"对象,他们指向同一个对象。
new关键字一定会产生一个对象chenssy(注意这个chenssy和上面的chenssy不同),同时这个对象是存储在堆中。所以上面应该产生了两个对象:保存在栈中的c和保存堆中chenssy。但是在Java中根本就不存在两个完全一模一样的字符串对象。故堆中的chenssy应该是引用字符串常量池中chenssy。所以c、chenssy、池chenssy的关系应该是:c--->chenssy--->池chenssy。整个关系如下:
练习:替换空格(合并数组等需要多次更改大量数据位置的问题,可以考虑使用指针从后向前查找。
3.链表
链表是一种动态数据结构,在创建时不需要将全部的内存进行分配。空间效率比数组高。
练习:单链表的插入删除,链表倒序输出。
4.树
根节点没有父节点,其他都有唯一父节点。叶节点没有子节点,其他都有一个或者多个子节点。父节点和子节点之前用指针连接。
二叉树
二叉树的遍历:前序遍历,中序遍历,后序遍历(以访问根节点的顺序决定。)
二叉搜索树:根节点总比左节点大,而右节点总比根节点大。
堆:最大堆中,根节点的值最大。最小堆中根节点的值最小。
5.栈和队列
栈是一种先进后出的结构,系统为每个线程一般都会创建一个栈用来存放函数调用时候都各个函数的参数、返回地址和零时变量等等。
通常栈不考虑排序,寻找时候都需要花费O(n)的时间复杂度。
队列是一种先进先出的结构。宽度遍历树的时候,可以利用队列的结构,用来存放每一层的子节点,然后下一层依次遍历子节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号