使用debezium-connector-jdbc组件完成数据同步(io.debezium.connector.jdbc.JdbcSinkConnector)
1.情景展示
在网络上几乎找不到关于debezium-connector-jdbc插件的博客文章,基本上都在吹io.confluent.connect.jdbc.JdbcSinkConnector,由于一开始对数据同步插件并不了解,导致自己走了不少弯路。
生产数据组件:debezium-connector-mysql、debezium-connector-oracle等数据库组件,通过Source Connector完成了将表数据至kafka的推送工作。
消费数据组件:confluentinc-kafka-connect-jdbc、debezium-connector-jdbc等jdbc组件,通过Sink Connector拉取kafka数据推送到数据库当中。
如果你用的是debezium的官方组件来捕获表数据的变更记录的话,千万不要使用confluentinc-kafka-connect-jdbc插件,而应该使用debezium-connector-jdbc插件。
debezium-connector-jdbc插件可以和debezium提供的debezium-connector-mysql、debezium-connector-oracle-2.5.0等数据库组件,几乎实现了数据的无缝对接。
前面我们已经实现了将表数据到kafka的推送,下面来说如何将这些数据从kafka读出来并推送到数据库当中。
2.准备工作
插件下载
这个页面会展示当前debezium的最新版本,一般情况下,我们直接采用最新版就可以了。
以2.5版本为例,进行举例说明:
我们点击“More info”按钮,会跳转到此版本详情页:https://debezium.io/releases/2.5/
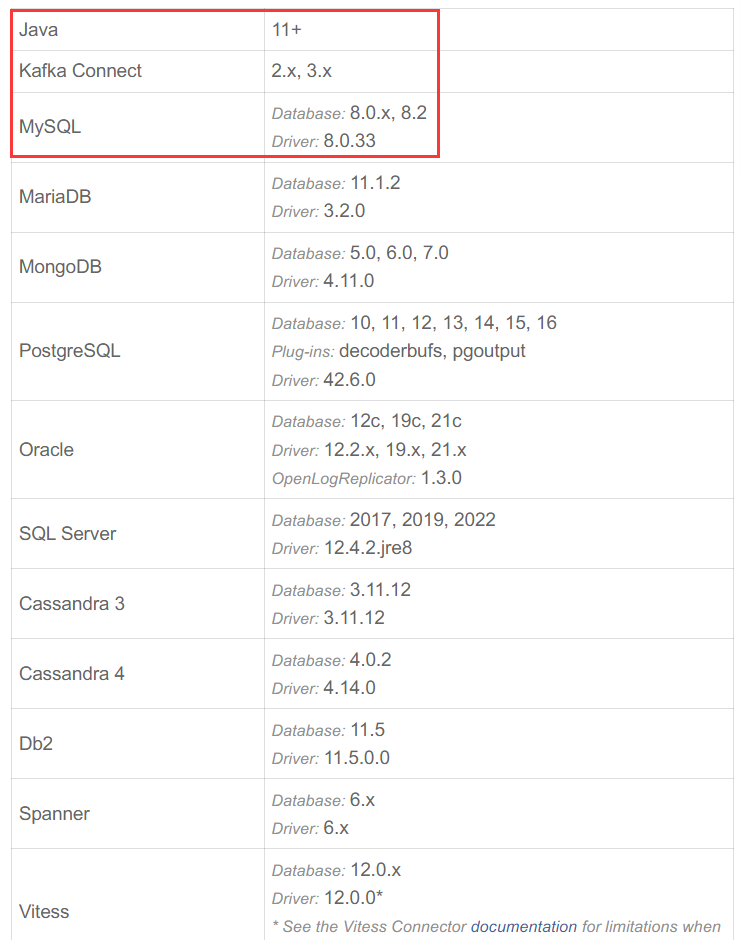
首先,映入眼帘的是:运行此插件所需的java版本,kafka版本,以及其所支持的数据库类型、版本号和驱动版本。
往下走,看到的是:Documentation
也就是说明文档,点击“Documentation”按钮,将会跳转到当前版本对应的说明文档页:https://debezium.io/documentation/reference/2.5/

然后找到:Getting Started-->点击"Installation",会跳转到插件安装界面:https://debezium.io/documentation/reference/2.5/install.html
debezium插件列表如下:
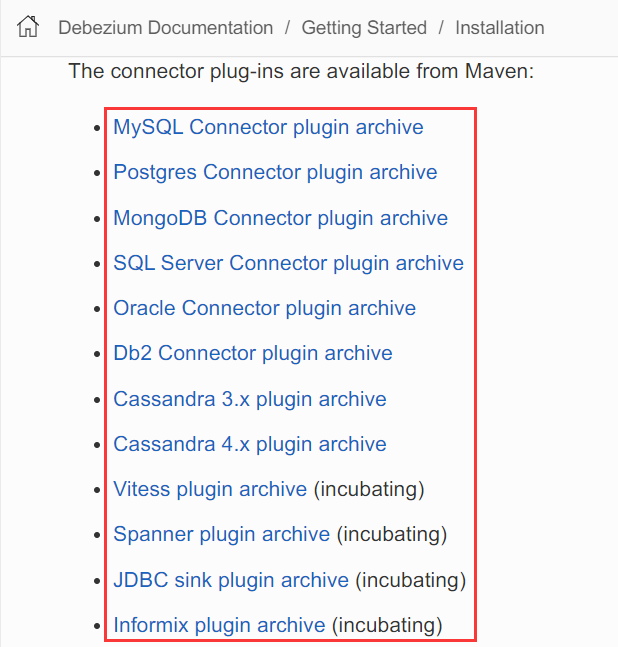
jdbc插件:https://repo1.maven.org/maven2/io/debezium/debezium-connector-jdbc/$2.5.0.Final/debezium-connector-jdbc-2.5.0.Final-plugin.tar.gz
插件下载说明:
当你发现插件下载失败的时候,需要检查下载地址当中是否存在$,如果存在将其删掉,才是正确的地址。
如上面的jdbc插件,由于多了一个$,导致下载失败,我们把它去掉再下载就可以了:https://repo1.maven.org/maven2/io/debezium/debezium-connector-jdbc/2.5.0.Final/debezium-connector-jdbc-2.5.0.Final-plugin.tar.gz
插件用法参数说明
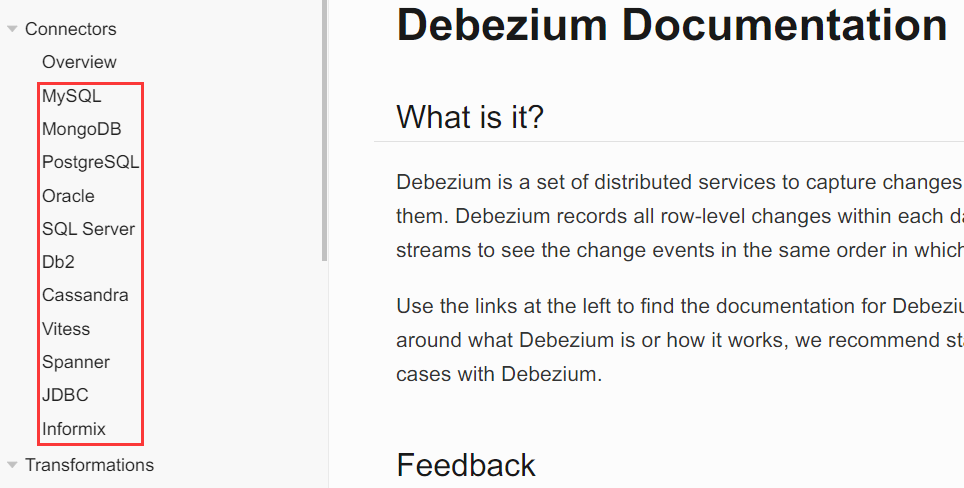
点击不同的数据库,将会跳转到对应的参数说明页。
mysql:https://debezium.io/documentation/reference/2.5/connectors/mysql.html
oracle:https://debezium.io/documentation/reference/2.5/connectors/oracle.html
jdbc:https://debezium.io/documentation/reference/2.5/connectors/jdbc.html
如何下载历史插件版本?
在说明文档页,我们点击切换说明文档的版本号,就能看到历史版本信息。
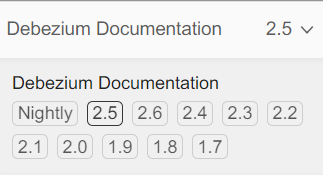
以2.0进行举例说明
如何下载2.0版的插件呢?
我们点击“2.0”,将会切换到2.0版的说明页:https://debezium.io/documentation/reference/2.0/index.html
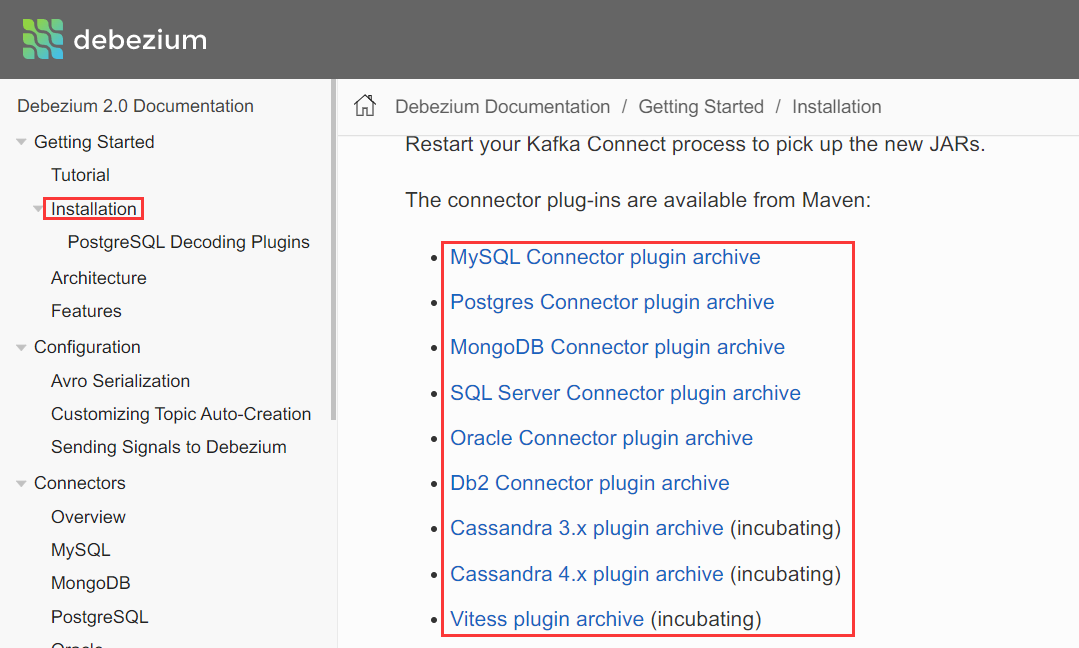
我们点击"Mysql Connector plugin archive",将会自动下载debezium-mysql-2.0.1.Final,下载地址为:https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/2.0.1.Final/debezium-connector-mysql-2.0.1.Final-plugin.tar.gz
插件安装
下载成功后,进行解压。
来到KAFKA_HOME目录下,创建一个plugins目录。
并将刚才解压的插件移到plugins目录下。
最好把版本号也加上。
另外的话,jdbc插件的版本号最好和其余数据库插件的版本号保持一致。
参数说明
说明文档:https://debezium.io/documentation/reference/2.5/connectors/jdbc.html
2.5.0版本常用参数说明
具体的数据结构,下面有。
name属性:代表的是连接器的名称,该名称具有唯一性!(名字随便起,但必须唯一)。
名字最好能让人望文生义,如:debezium-connector-sink-mysql-63-sourceTableName,这一看就知道:
创建的是Sink Connector,用的插件是:debezium-connector-jdbc,源库是mysql以及源表表名。
tasks.max属性:此连接器创建的最大任务数,默认值为1(MySQL 连接器始终使用单个任务,因此不使用此值),数据类型:int。
connector.class属性:Sink Connector的实现类,在这里我们需要填:io.debezium.connector.jdbc.JdbcSinkConnector(它是debezium-connector-jdbc的sink连接器)。
connection.url属性:数据库连接地址。
mysql形如:jdbc:mysql://192.168.0.1:3306/scott?useUnicode=true&characterEncoding=utf8&allowPublicKeyRetrieval=true&useTimezone=true&serverTimezone=Asia/Shanghai。
oceanbase形如:与上面保持一致。
oracle形如:jdbc:oracle:thin:@192.168.0.1:1521/orcl。
sqlserver形如:jdbc:sqlserver://192.168.0.1:1433;databaseName=cdc_test_20240524;encrypt=false。
说明:如果目标库是sqlserver,不声明encrypt=false的话,默认会以加密的方式进行jdbc连接。
connection.username属性:数据库用户名,如:scott。
connection.password属性:数据库密码,如:123456。
topics或topics.regex属性:将要发布的主题的名称前缀,该值具有唯一性(kafka会根据此主题前缀来生成主题名称。消费者需要根据topic名称来订阅数据)。
table.name.format属性:待接收数据的表名(目标表表名,忽略大小写)。
field.include.list属性:待同步的表字段。格式:topics.regex:fieldName,多个使用逗号隔开。
说明1:可以设置只同步部分字段(指定几个字段,就同步几个字段),如果不带此参数,将默认自动同步全部字段。
说明2:目标表不存在,如果需要其自动创建的话,必须设置此属性。
说明3:表字段名称区分大小写(必须和源表字段名称一模一样)。
insert.mode属性:插入模式,默认值:insert,可选值:[insert, upsert, update],这里我们需要设为:upsert。
upsert代表的含义是:如果主键不存在,则连接器执行 INSERT 操作;如果主键存在,则连接器执行 UPDATE 操作。
当使用upsert模式时,必须指定primary.key.mode和primary.key.fields。
primary.key.mode属性:主键模式,默认值:none,可选值:[none,kafka,record_key,record_value],这里我们需要设为:record_key。
当其值设为kafka时,属性schema.evolution的值不能为basic。
delete.enabled属性:是否将null记录值视为删除,默认值:false。当为true时,primary.key.mode的值必须指定为:record_key。
这里,我们需要将其设为:true。
primary.key.fields属性:主键字段,多个字段使用逗号分割(也就是:支撑联合主键)。
说明1:主键字段名称区分大小写(必须和源表字段名称一模一样)。
说明2:源表与目标表的主键必须保持一致。
说明3:它的值依赖于属性primary.key.mode(根据源表变更记录捕获的数据存到kafka当中,所以从kafka取数据的时候,它是根据源表记录进行查找的)。
truncate.enabled属性:当出现truncate操作时,是否进行同步(清空表数据),默认值:false。
schema.evolution属性:是否同步表结构更新(当目标表不存在时,会自动创建),默认值:none,可选值:[none, basic]。
none:仅支持DML(insert、update和delete操作);basic:DML+DDL。
说明:如果需要该插件进行自动建表操作,该值必须设为:basic。
errors.log.enable属性:是否显示错误日志,默认值:false。
errors.log.include.messages属性:错误日志是否包含错误信息,默认值:false。
dialect.sqlserver.identity.insert属性:是否允许为SQLSERVER表中的标识列插入显式值,默认值:false。
3.运行
准备工作
启动服务
启动zookeeper,启动kafka,启动kafka connect。
查看所有参数配置(可忽略)
http://localhost:8083/connector-plugins/io.debezium.connector.jdbc.JdbcSinkConnector/config订阅主题
接口地址:
http://localhost:8083/connectors请求数据:(oracle订阅mysql数据)
{
"name": "debezium-connector-sink-oracle-124-tb_project",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"table.name.format": "TB_PROJECT",
"errors.log.include.messages": true,
"connection.password": "mardon456",
"primary.key.mode": "record_key",
"tasks.max": 1,
"truncate.enabled": true,
"connection.username": "marydon",
"topics.regex": "topic-test-124.test.tb_project",
"delete.enabled": true,
"primary.key.fields": "id",
"connection.url": "jdbc:oracle:thin:@192.168.0.1:1521/orcl",
"insert.mode": "upsert",
"errors.log.enable": true
}
}响应数据:
{
"name": "debezium-connector-sink-oracle-124-tb_project",
"type": "sink",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"table.name.format": "TB_PROJECT",
"errors.log.include.messages": "true",
"connection.password": "mardon456",
"primary.key.mode": "record_key",
"tasks.max": "1",
"truncate.enabled": "true",
"connection.username": "marydon",
"topics.regex": "topic-test-124.test.tb_project",
"delete.enabled": "true",
"primary.key.fields": "id",
"connection.url": "jdbc:oracle:thin:@192.168.0.1:1521/orcl",
"insert.mode": "upsert",
"errors.log.enable": "true",
"name": "debezium-connector-sink-oracle-124-tb_project"
},
"tasks": [{
"connector": "debezium-connector-sink-oracle-124-tb_project",
"task": 0
}]
}由于在创建Source Connector时,我们设置的是存量+全量更新,所以,在Sink Connector成功创建后,为了测试数据是否可以正常同步。
我们需要:对源表进行操作(增、删、改)都可以。
初次同步耗时较长,需要我们耐心等待。
新增操作
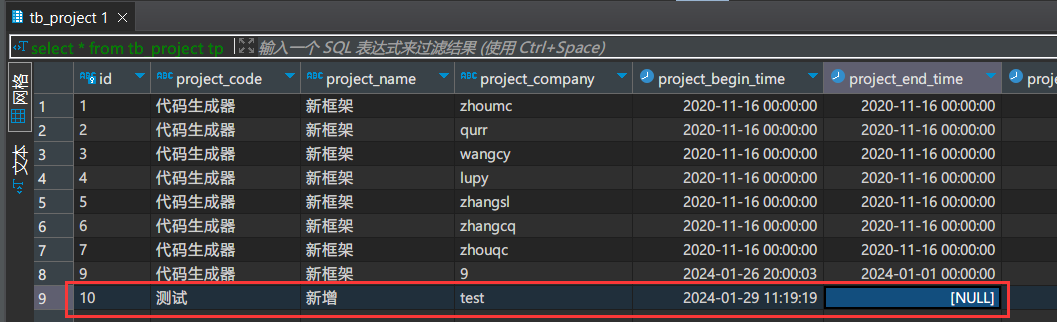
当我们对源表进行新增操作后,会发现Kafka Connect窗口输出了:Committing offsets for 1 acknowledged messages。

这就表示Source Connector已经将此表的这个新增数据推送到了kafka的topic-test-124.test.tb_project主题中。
当Kafka Connect窗口出现如下字样时,就表示Sink Connector已经从kafka的topic-test-124.test.tb_project主题中拿到最新数据并且同步到了目标表的目标表中。


修改操作
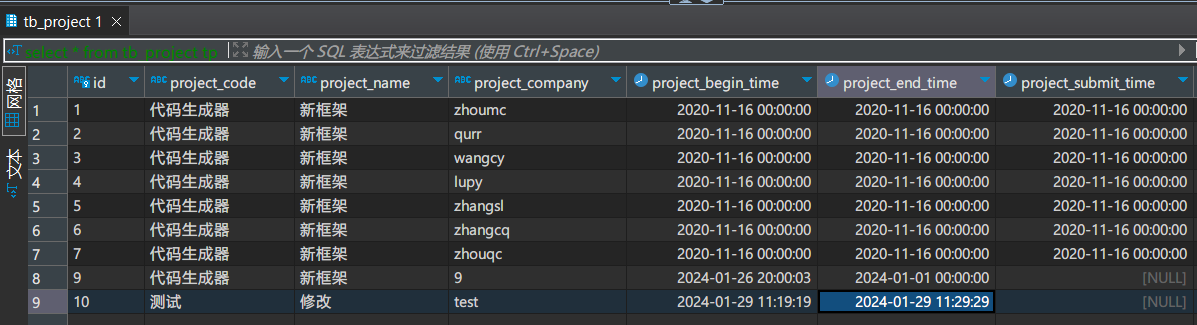

删除操作
6.拓展
关于主题的补充说明
关于主题的生成条件,我在前两篇文章已经说过了。
也就是说:在Source Connector创建之后,鉴于其参数snapshot.mode的设置以及表数据的变化,还有启动所需时间的长短问题,经常会造成:
主题没有创建的情况。

这个时候,Sink Connector的主题该怎么确定呢?
由前面两篇文章,我们已经知道了mysql和Oracle主题的生成规则,分别是:
mysql:topic.prefix.databaseName.tableName;
Oracle:topic.prefix.userName.tableName。
由于往往拿不到主题(主题尚未被创建),所以我们在创建Sink Connector时,需要提前指定要订阅的topic。
那么问题来了,主题先被订阅后被创建,能不能Sink Connector能不能从Kafka中读取数据呢?
只要你创建的Source Connector和Sink Connector没有报错,在运行过程中也没有报错,并且保证订阅的主题名称和Source Connector生成的主题名称完全一致,
事实上是可以正常接收数据的。
只不过,首次订阅数据完成同步的过程比较慢(通常需要10-30分钟),耐心等待就可以了。
当目标库目标表不存在时,自动建表
前提条件:
需要指定参数schema.evolution,并将其值设为basic;
需要指定参数field.include.list,格式为:topicName:fieldName。
源库:mysql&目标库:mysql
(mysql-->mysql自动建表)
{
"name": "debezium-connector-sink-mysql-122-tb_project",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"table.name.format": "TB_PROJECT",
"connection.password": "marydon123",
"primary.key.mode": "record_key",
"tasks.max": 1,
"truncate.enabled": true,
"connection.username": "marydon",
"topics.regex": "topic-test-122.test.tb_project",
"delete.enabled": true,
"field.include.list": "topic-test-122.test.tb_project:create_by,topic-test-122.test.tb_project:create_time,topic-test-122.test.tb_project:id,topic-test-122.test.tb_project:project_begin_time,topic-test-122.test.tb_project:project_code,topic-test-122.test.tb_project:project_company,topic-test-122.test.tb_project:project_end_time,topic-test-122.test.tb_project:project_manager,topic-test-122.test.tb_project:project_name,topic-test-122.test.tb_project:project_submit_time,topic-test-122.test.tb_project:update_by,topic-test-122.test.tb_project:update_time",
"schema.evolution": "basic",
"primary.key.fields": "id",
"connection.url": "jdbc:mysql://192.168.0.1:3306/test2?useUnicode=true&characterEncoding=utf8&allowPublicKeyRetrieval=true&useTimezone=true&serverTimezone=Asia/Shanghai",
"insert.mode": "upsert"
}
}由于Source Connector设置的同步类型为存量+增量,所以,在Source Connector和Sink Connector创建成功后,主题并不会立即生成。
我们还需要在源表当中插入一条数据,来触发Source Connector捕获数据并创建主题。
说明:如果是全量+增量的同步类型的话,只要确保源表存在数据,后续耐心等待就可以了,大概需要半个小时的时间。
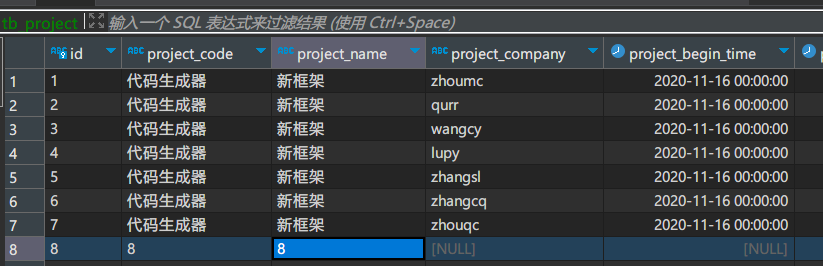
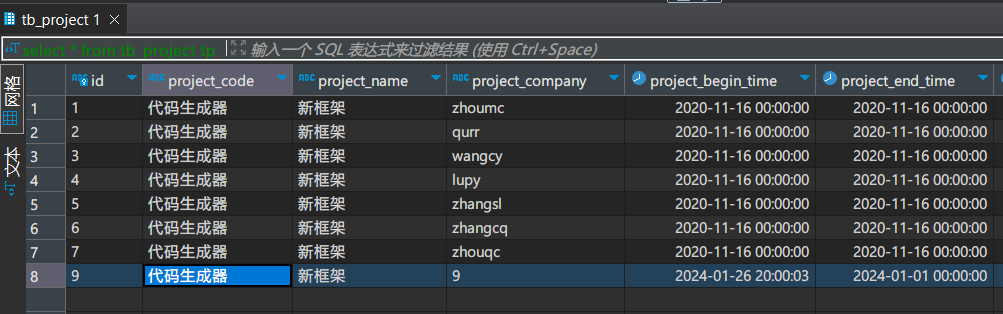
如上图所示,我在源表当中增加了一条数据。
大概过了半个小时后,目标表被创建了出来,并且插入了一条数据。

双方表结构对比
源表表结构:tb_project
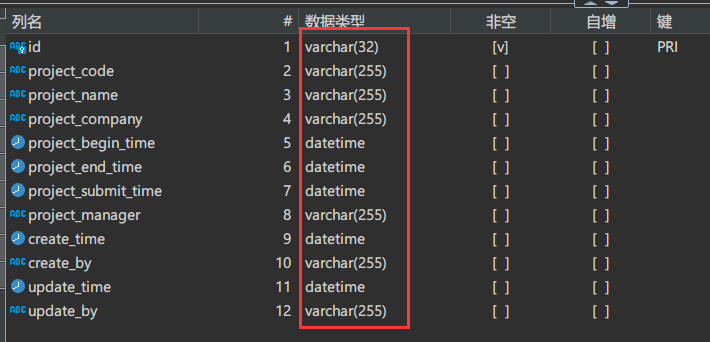
被自动创建的表结构:tb_project
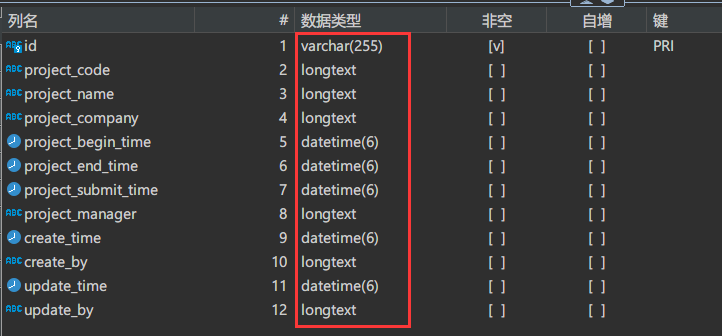
我们会发现自动创建的目标表与源表的字段类型会发生变化。
这一点是我们需要注意的。
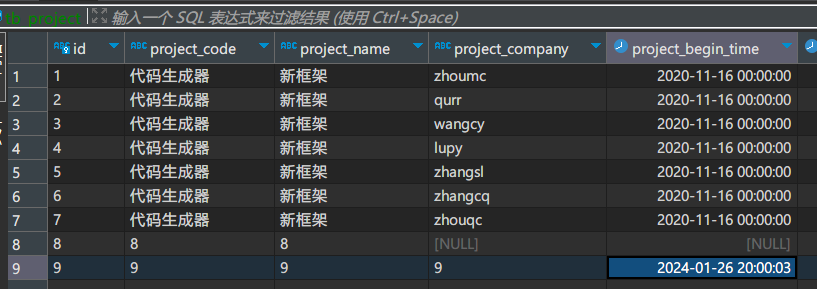
新增示例
新增id=9那列

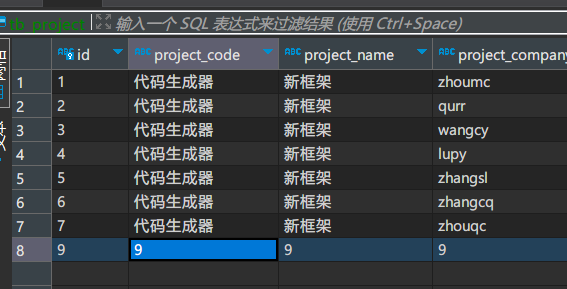
删除示例
把id=8的那列删掉
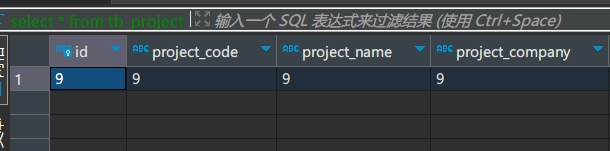
修改示例
把id=9那列数据进行修改
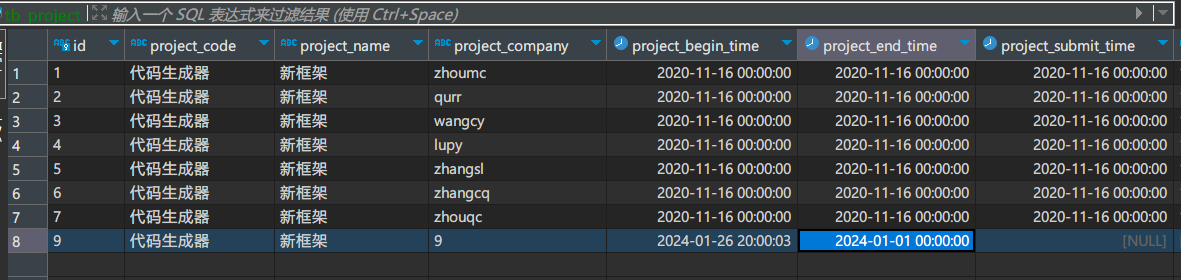

另外,我们可以发现:
在被自动创建的TB_PROJECT表名被mysql数据库被转换成了小写。

源库:oracle&目标库:oracle
(oracle-->oracle自动建表)
源表:T_PATIENT_ZS
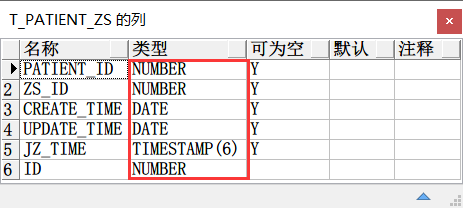
被自动创建的表:T_PATIENT_TEST
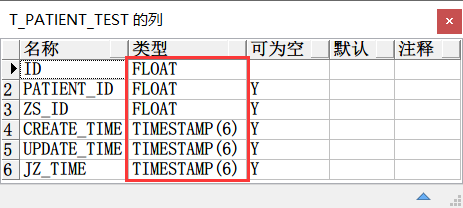
目标表字段的数据类型同样无法和源表保持一致。
源库:mysql&目标库:oracle
(mysql-->oracle自动建表)
源表:oauth2_access_token
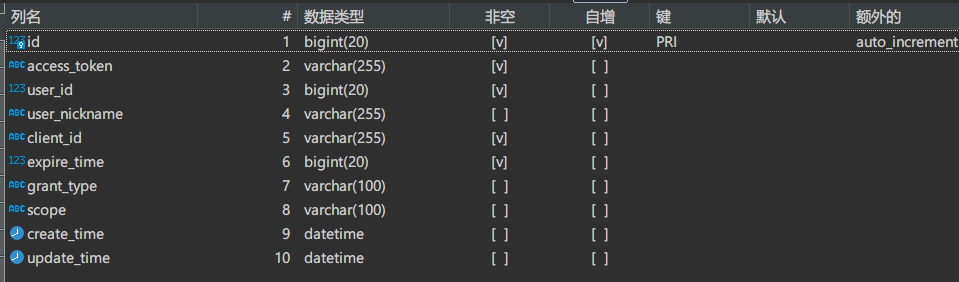
查看代码
{
"name": "debezium-connector-source-mysql-123",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"errors.log.include.messages": true,
"database.user": "marydon",
"database.server.id": 123,
"schema.history.internal.kafka.bootstrap.servers": "localhost:9092",
"event.processing.failure.handling.mode": "warn",
"column.include.list": "test.oauth2_access_token.access_token,test.oauth2_access_token.client_id,test.oauth2_access_token.create_time,test.oauth2_access_token.expire_time,test.oauth2_access_token.grant_type,test.oauth2_access_token.id,test.oauth2_access_token.scope,test.oauth2_access_token.update_time,test.oauth2_access_token.user_id,test.oauth2_access_token.user_nickname",
"database.port": "3306",
"schema.history.internal.store.only.captured.tables.ddl": true,
"schema.history.internal.store.only.captured.databases.ddl": true,
"topic.prefix": "topic-test-123",
"schema.history.internal.kafka.topic": "schema-history-test-123",
"database.hostname": "192.168.0.1",
"database.connectionTimeZone": "GMT+8",
"database.password": "marydon@db",
"table.include.list": "test.oauth2_access_token",
"skipped.operations": "none",
"errors.log.enable": true,
"database.include.list": "test",
"snapshot.mode": "initial"
}
}被自动创建的表:OAUTH2_ACCESS_TOKEN

查看代码
{
"name": "debezium-connector-sink-oracle-123-oauth2_access_token",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"table.name.format": "OAUTH2_ACCESS_TOKEN",
"errors.log.include.messages": true,
"connection.password": "marydon456",
"primary.key.mode": "record_key",
"tasks.max": 1,
"truncate.enabled": true,
"connection.username": "mardon",
"topics.regex": "topic-test-123.test.oauth2_access_token",
"delete.enabled": true,
"field.include.list": "topic-test-123.test.oauth2_access_token:access_token,topic-test-123.test.oauth2_access_token:client_id,topic-test-123.test.oauth2_access_token:create_time,topic-test-123.test.oauth2_access_token:expire_time,topic-test-123.test.oauth2_access_token:grant_type,topic-test-123.test.oauth2_access_token:id,topic-test-123.test.oauth2_access_token:scope,topic-test-123.test.oauth2_access_token:update_time,topic-test-123.test.oauth2_access_token:user_id,topic-test-123.test.oauth2_access_token:user_nickname",
"schema.evolution": "basic",
"primary.key.fields": "id",
"connection.url": "jdbc:oracle:thin:@192.168.0.1:1521/orcl",
"insert.mode": "upsert",
"errors.log.enable": true
}
}源库:oracle&目标库:mysql
(oracle-->mysql自动建表)
源表:BASE_JOB_FRCODE
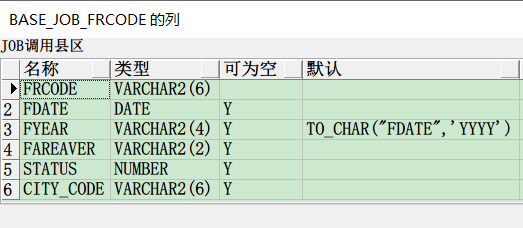
查看代码
{
"name": "debezium-connector-source-oracle-125",
"config": {
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"errors.log.include.messages": true,
"database.user": "marydon",
"database.dbname": "orcl",
"database.server.id": 125,
"tasks.max": 1,
"database.url": "jdbc:oracle:thin:@192.168.57.111:1521/orcl",
"schema.history.internal.kafka.bootstrap.servers": "localhost:9092",
"event.processing.failure.handling.mode": "warn",
"column.include.list": "MARYDON.BASE_JOB_FRCODE.CITY_CODE,MARYDON.BASE_JOB_FRCODE.FAREAVER,MARYDON.BASE_JOB_FRCODE.FDATE,MARYDON.BASE_JOB_FRCODE.FRCODE,MARYDON.BASE_JOB_FRCODE.FYEAR,MARYDON.BASE_JOB_FRCODE.STATUS",
"log.mining.strategy": "online_catalog",
"database.port": "1521",
"schema.history.internal.store.only.captured.tables.ddl": true,
"schema.history.internal.store.only.captured.databases.ddl": true,
"topic.prefix": "topic-orcl-125",
"schema.history.internal.kafka.topic": "schema-history-orcl-125",
"database.hostname": "192.168.0.1",
"database.password": "marydon456",
"table.include.list": "MARYDON.BASE_JOB_FRCODE",
"skipped.operations": "none",
"errors.log.enable": true,
"snapshot.mode": "initial"
}
}被自动创建的表:base_job_frcode
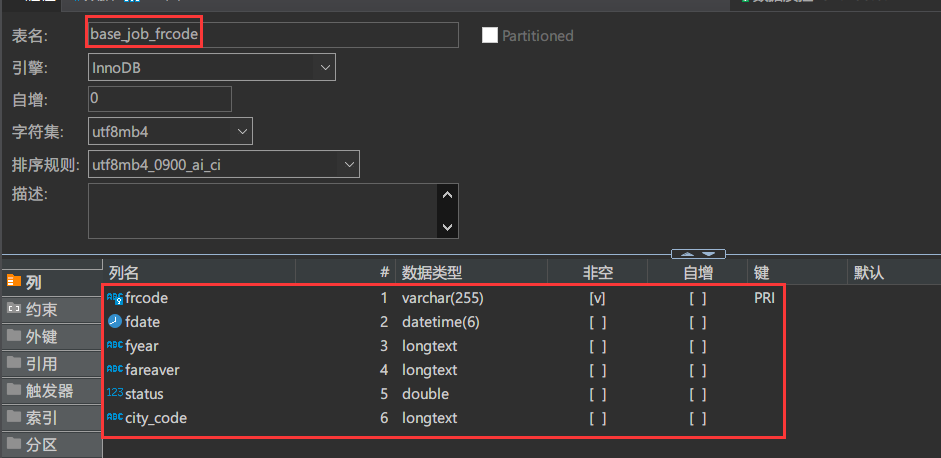
查看代码
{
"name": "debezium-connector-sink-mysql-125-BASE_JOB_FRCODE",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"table.name.format": "BASE_JOB_FRCODE",
"errors.log.include.messages": true,
"connection.password": "marydon@db",
"primary.key.mode": "record_key",
"tasks.max": 1,
"truncate.enabled": true,
"connection.username": "marydon",
"topics.regex": "topic-orcl-125.MARYDON.BASE_JOB_FRCODE",
"delete.enabled": true,
"field.include.list": "topic-orcl-125.MARYDON.BASE_JOB_FRCODE:CITY_CODE,topic-orcl-125.MARYDON.BASE_JOB_FRCODE:FAREAVER,topic-orcl-125.MARYDON.BASE_JOB_FRCODE:FDATE,topic-orcl-125.MARYDON.BASE_JOB_FRCODE:FRCODE,topic-orcl-125.MARYDON.BASE_JOB_FRCODE:FYEAR,topic-orcl-125.MARYDON.BASE_JOB_FRCODE:STATUS",
"schema.evolution": "basic",
"primary.key.fields": "FRCODE",
"connection.url": "jdbc:mysql://192.168.0.1:3306/test?useUnicode=true&characterEncoding=utf8&allowPublicKeyRetrieval=true&useTimezone=true&serverTimezone=Asia/Shanghai",
"insert.mode": "upsert",
"errors.log.enable": true
}
}其它补充说明
源表表名和目标表的表名必须保持一致(忽略大小写),否则无法完成数据同步。
源表表字段名称和目标表字段名称必须保持一致(忽略大小写),否则无法完成数据同步。
源表的主键名称和目标表的主键名称必须完全保持一致(大小写也必须保持一致),否则会报错:xx字段不存在(通常指的就是目标表的主键名称和源表的主键名称不一致)。
JdbcSinkConnector支持同步的数据类型有:
当然,官方的jdbc插件也不是万能的,例如:
源表表名与目标表表名不一致;
目标表字段B需要对应源表表字段A,而不是A-->A;
在进行数据同步时,目标表需要增加时间戳字段或者实现假删除等等个性化需求,官方插件就不能用了。
我们只能自己开发kafka connect组件了,具体见文末推荐。
本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/17990522

