debezium+kafka实现oracle数据同步(debezium-connector-oracle)
1.情景展示
在企业当中,往往会存在不同数据库之间的表的数据需要保持一致的情况(数据同步)。
如何将A库a表的数据同步至B库a表当中呢?(包含:新增、修改和删除)
往往不仅仅需要保持数据的一致性,还要保证数据的即时性,即:A库a表的数据发生变化后,B库a表也能立刻同步变化。
实时保持两表数据的一致性。
如何实现?
2.具体分析
要想及时知晓A库a表的数据变化,我们需要读取数据库的操作日志,从日志当中提取a表的操作日志。(至少要包含:新增、修改和删除)。
以oracle为例,就是读取oracle的article日志,而读取日志提取a表操作记录,我们可以通过组件来完成,无需自己手动解析日志。
3.解决方案
debezium-connector-oracle插件,可以很好的完成这个任务。
Debezium是一个开源的数据库事件捕捉和发布平台,旨在提供可靠的实时数据流。它基于分布式日志(如Apache Kafka)来捕获并传输数据库的变更事件,从而实现高效的数据同步和分发。通过使用Debezium的oracle连接器,可以轻松地将oracle数据库中的DML操作(包括INSERT、UPDATE、DELETE)的变更事件提取出来,并以实时的方式推送到Kafka消息队列中。
由于debezium-connector-oracle插件是结合kafka来实现的,我们自然需要用到kafka。
debezium-connector-oracle插件最终实现的效果是:监听oracle库的binlog日志,实时捕获oracle数据变更记录,并将变化的数据发布到kafka的主题当中。
Debezium的Oracle连接器捕获并记录Oracle服务器上数据库中发生的行级更改,还包括在连接器运行时添加的表。可以通过Connector配置,为指定的schema和表获取更改事件,或者忽略、屏蔽或截断特定列中的值等过滤操作。
Debezium通过使用本地LogMiner数据库包或XStream API从Oracle获取更改事件。
在开始之前,我们需要先了解一下kafka connect,通过它我们可以将其它系统与kakfa进行连接,完成主题的发布与订阅。
具体就是:通过该服务,我们可以使用REST API的方式调用kafka服务器来完成消息的发布与订阅。
更多关于kafka connect的用法,见文末推荐。
使用debezium官方提供的source connector,部署到apache kafka connect中,debezium的connector捕获到源数据库数据更新,发送到kafka集群中。
插件下载
地址:https://debezium.io/releases/
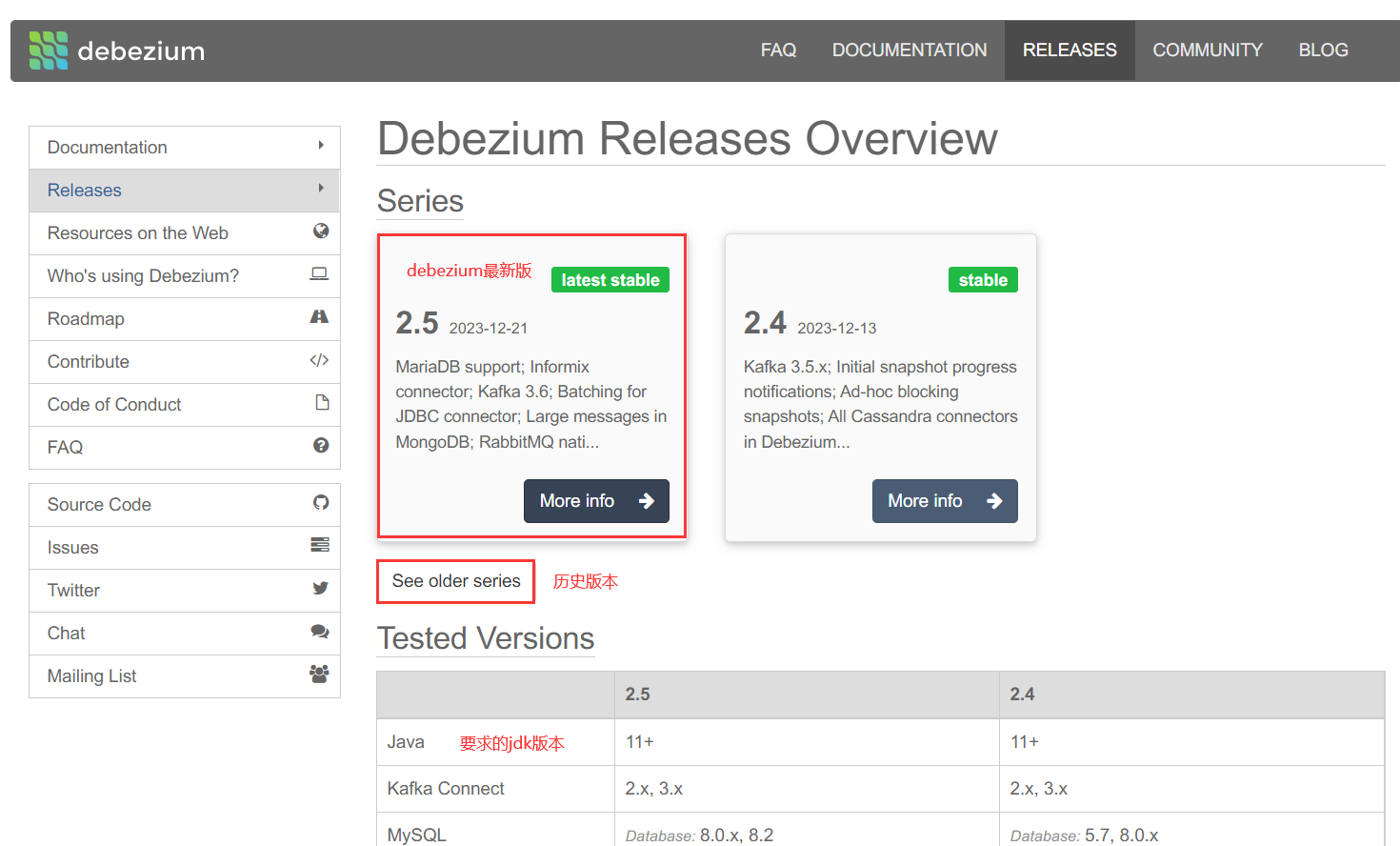
点击debezium的最新版本(More info)。
支持的版本号说明:

点击“installation guide”。
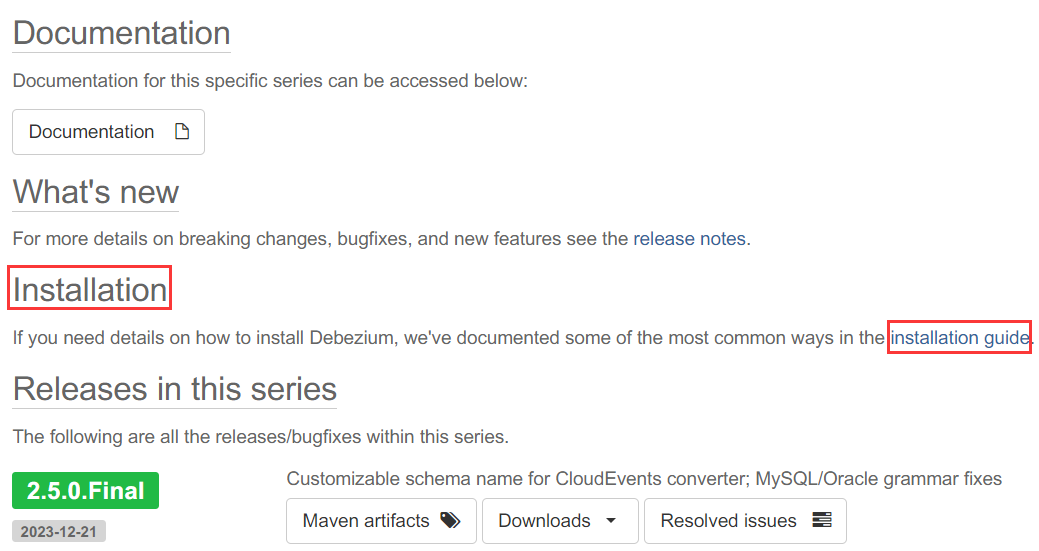
2.5.0.Final版本地址:https://debezium.io/documentation/reference/2.5/install.html
connector插件列表展示如下。
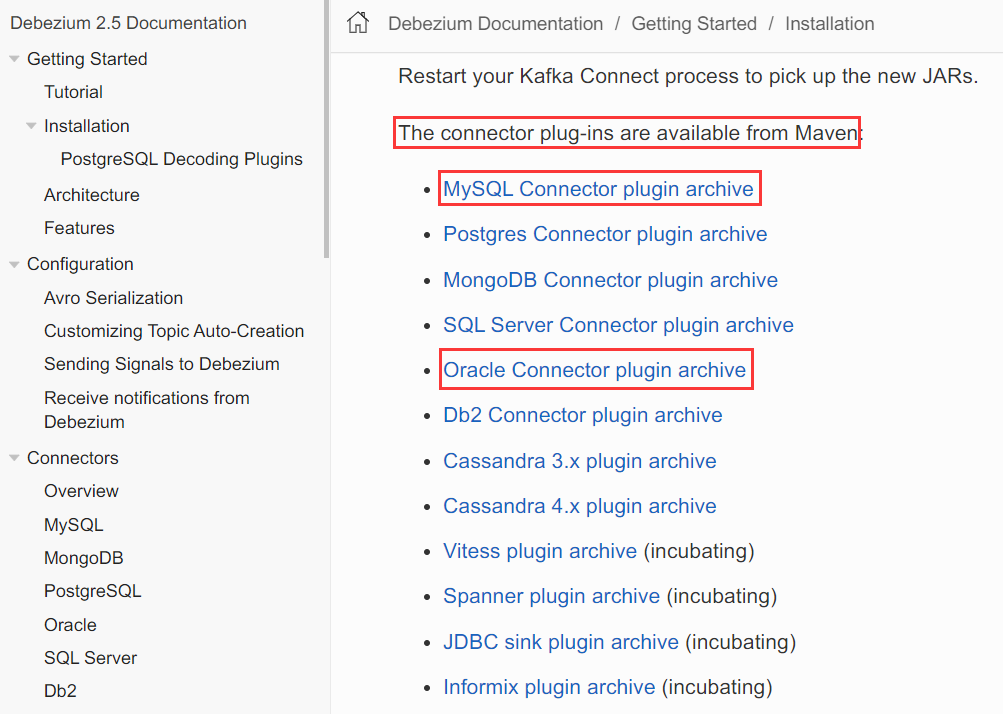
mysql connector 2.5.0版插件地址:https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/2.5.0.Final/debezium-connector-mysql-2.5.0.Final-plugin.tar.gz
oracle connector 2.5.0版插件地址:https://repo1.maven.org/maven2/io/debezium/debezium-connector-oracle/2.5.0.Final/debezium-connector-oracle-2.5.0.Final-plugin.tar.gz
SQLserver connector 2.5.0版插件地址:https://repo1.maven.org/maven2/io/debezium/debezium-connector-sqlserver/2.5.0.Final/debezium-connector-sqlserver-2.5.0.Final-plugin.tar.gz
插件源码地址:https://github.com/debezium/debezium
插件安装
下载成功后,进行解压。
来到KAFKA_HOME目录下,创建一个plugins目录。
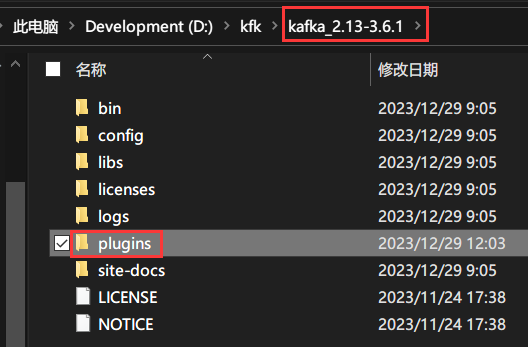
并将刚才解压的插件移到plugins目录下。
重命名在插件后面添加版本号。
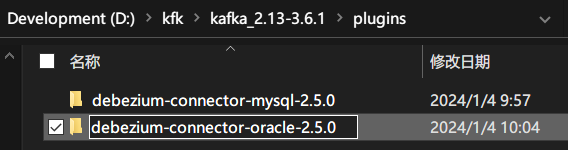
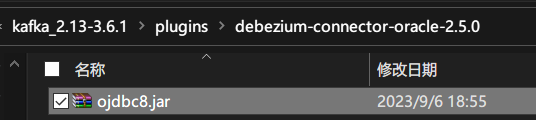
说明:
插件debezium-connector-oracle没有连接oracle的驱动,所以需要将ojdbc8.jar添加到此目录下。
参数说明
https://debezium.io/documentation/reference/2.5/connectors/oracle.html
这里我只讲自己用的的参数,其余参数说明及用法,可通过上述说明文档自行查阅。
具体的数据结构,下面有。
name属性:代表的是连接器的名称,该名称具有唯一性!(名字随便起,但必须唯一)。
名字最好能让人望文生义,如:debezium-connector-source-oracle-73,这一看就知道:创建的是Source Connector,用的插件是:debezium-connector-oracle。
connector.class属性:Source Connector的实现类,在这里我们需要填:io.debezium.connector.oracle.OracleConnector(它是debezium-connector-oracle的源连接器)。
database.hostname属性:数据库服务器所属IP,如:127.0.0.1。
database.port属性:数据库端口号,如:1521。
database.user属性:数据库用户名,如:test。
database.password属性:数据库密码,如:123456。
database.server.id属性:给数据库设置id,该值具有唯一性,默认取值范围:[5400,6400],数据类型:int。
database.dbname属性:要监控的数据库名称,如:orcl。
database.url属性:要监控的数据库连接地址,如:jdbc:oracle:thin:@192.168.0.1:1521/orcl。
tasks.max属性:要运行的任务数,默认值:1。
table.include.list属性:要捕获数据变更记录的表名称列表,可以同时监控多张表。构成:userName.tableName,多个使用逗号隔开,如:test.T_PATIENT_ZS。
schema.history.internal.store.only.captured.tables.ddl属性:默认值:false,代表的含义是:debezium会将被监控数据库下所有的表的变更记录,都进行捕获。
而实际上,我们只需捕获table.include.list里面设置的表,而不是所有的表。需将此值设为:true。
column.include.list属性:可以设置只捕获表中的部分字段变更记录,可以监控多张表的部分字段变更记录。构成:userName.tableName.columnName,多个请使用逗号隔开,如:test.T_PATIENT_ZS.CREATE_TIME,test.T_PATIENT_ZS.ID。
schema.history.internal.kafka.topic属性:连接器将在其中存储数据库模式历史记录的Kafka主题的全名,如:schema-history-test-63。
schema.history.internal.kafka.bootstrap.servers属性:kafka服务器地址,如:localhost:9092。
event.processing.failure.handling.mode属性:默认值:fail,表示的是:schema的处理模式。可选值:[fail,warn,ignore]。我们选择warn,而不是直接报错,更容易发现问题。
topic.prefix属性:将要发布的主题的名称前缀,该值具有唯一性(kafka会根据此主题前缀来生成主题名称。消费者需要根据topic名称来订阅数据)。
log.mining.strategy属性:默认值:redo_log_catalog(DDL+DML),可选值:[redo_log_catalog,online_catalog]。
redo_log_catalog:归档日志,redolog写满才会生成归档日志,导致topic接收数据慢(DDL+DML)。
online_catalog:在线日志,即时读取日志(不包含DDL,只包含DML)。
需将值设为:online_catalog,只有这样才能解决数据延迟、不能实时同步的问题。
DDL(create/alter/rename/drop/truncate)和DML(insert/update/delete)
errors.log.enable属性:默认值:false。是否输出错误日志,可将值设为true。
skipped.operations属性:默认值:t。不需要监控的操作,可选值:c(insert/create),u(update),d(delete),t(truncate),none。
snapshot.mode属性:快照模式,默认值:initial,可选值:[initial,initial_only,when_needed,never,schema_only,schema_only_recovery]。
initial(默认)(初始全量,后续增量):连接器执行数据库的初始一致性快照,快照完成后,连接器开始为后续数据库更改流式传输事件记录。
initial_only(只全量,不增量):连接器只执行数据库的初始一致性快照,不允许捕获任何后续更改的事件。
schema_only(只增量,不全量):连接器只捕获所有相关表的表结构,不捕获初始数据,但是会同步后续数据库的更改记录。
decimal.handling.mode属性:默认值:precise,可选值:[precise,double,string]
说明:
当我们使用kafka-console-consumer.bat进行消费数据的时候,数字类型的数据,会被自动转换成base64格式。
示例
当decimal.handling.mode属性值为precise时:"ZS_ID":{"scale":0,"value":"Aw=="};
当decimal.handling.mode属性值为string时:"ZS_ID":"3"。
但debezium实际产生仍然是数值类型,这一点,我已经验证过了,当使用sink connector接收时,数据并不是base64码。
当然,如果想要在使用kafka-console-consumer.bat进行消费数据的时候,数字类型的数据不被转成base64格式,可以设置decimal.handling.mode=string。
4.运行
准备工作
启动服务
启动zookeeper,启动kafka,启动kafka connect。
如果没有安装kafka或者不知道怎么启动,具体操作见文末推荐。
日志处理
第一步:开启归档日志
select name,log_mode from v$database;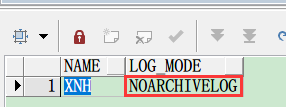
确保LOG_MODE是ARCHIVELOG,如果不是,则表示归档日志未启用。
如果未启用,需运行以下命令:
ALTER DATABASE ARCHIVELOG;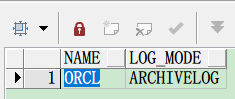
第二步:补全日志
补全日志有两种方式,一种是补全主键日志,一种是补全所有字段日志。
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;更多关于oracle日志的讲解,见文末推荐。
发布主题
接口地址:
http://localhost:8083/connectors请求数据:
{
"name": "debezium-connector-source-oracle-73",
"config": {
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"database.user": "test",
"database.dbname": "orcl",
"database.server.id": 73,
"tasks.max": 1,
"database.url": "jdbc:oracle:thin:@192.168.0.1:1521/orcl",
"schema.history.internal.kafka.bootstrap.servers": "localhost:9092",
"event.processing.failure.handling.mode": "warn",
"column.include.list": "test.T_PATIENT_ZS.CREATE_TIME,test.T_PATIENT_ZS.ID,test.T_PATIENT_ZS.JZ_TIME,test.T_PATIENT_ZS.PATIENT_ID,test.T_PATIENT_ZS.UPDATE_TIME,test.T_PATIENT_ZS.ZS_ID",
"log.mining.strategy": "online_catalog",
"database.port": "1521",
"schema.history.internal.store.only.captured.tables.ddl": true,
"topic.prefix": "topic-orcl-73",
"decimal.handling.mode": "string",
"schema.history.internal.kafka.topic": "schema-history-orcl-73",
"database.hostname": "192.168.0.1",
"database.password": "test123",
"table.include.list": "test.T_PATIENT_ZS",
"skipped.operations": "none",
"errors.log.enable": true,
"snapshot.mode": "initial"
}
}响应数据:
{
"name": "debezium-connector-source-oracle-73",
"type": "source",
"config": {
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"database.user": "test",
"database.dbname": "orcl",
"database.server.id": "73",
"tasks.max": "1",
"database.url": "jdbc:oracle:thin:@192.168.0.1:1521/orcl",
"schema.history.internal.kafka.bootstrap.servers": "localhost:9092",
"event.processing.failure.handling.mode": "warn",
"column.include.list": "test.T_PATIENT_ZS.CREATE_TIME,test.T_PATIENT_ZS.ID,test.T_PATIENT_ZS.JZ_TIME,test.T_PATIENT_ZS.PATIENT_ID,test.T_PATIENT_ZS.UPDATE_TIME,test.T_PATIENT_ZS.ZS_ID",
"log.mining.strategy": "online_catalog",
"database.port": "1521",
"schema.history.internal.store.only.captured.tables.ddl": "true",
"topic.prefix": "topic-orcl-73",
"decimal.handling.mode": "string",
"schema.history.internal.kafka.topic": "schema-history-orcl-73",
"database.hostname": "192.168.0.1",
"database.password": "test123",
"table.include.list": "test.T_PATIENT_ZS",
"skipped.operations": "none",
"errors.log.enable": "true",
"snapshot.mode": "initial",
"name": "debezium-connector-source-oracle-73"
},
"tasks": [{
"connector": "debezium-connector-source-oracle-73",
"task": 0
}]
}主题发布成功后,debezium将会自动捕获oracle数据变更日志,并将数据推送到kafka当中。
查询主题
主题的生成条件说明:
debezium source connector启动之后,当指定监控的表数据发生变更时,它才会创建主题(也就是往kafka当中推送数据)。

如果处于监控中的表一直没有数据变更,那这个主题就一直不会产生。
具体就是:
当snapshot.mode=schema_only时,source connector启动后,不会立马创建主题,而是直到源表数据发生变化时,才会创建主题(也就是:debezium-oracle插件通过读取日志,监控到该表发生了变化,会自动将变化的数据推送到kafka上,这时,主题自然就生成了)。
当snapshot.mode=initial时,source connector启动后,如果源表已经有数据,它会立马创建主题;
反之,如果源表一条数据都没有,不会立马创建主题,直到源表有新增数据时,才会创建主题。
主题生成规则:
一张表对应一个主题。
oracle主题构成:topic.prefix.userName.tableName(oracle的用户名统一会变成大写)
这里t_patient表对应的主题是:topic-orcl-73.TEST.T_PATIENT_ZS。
查看已发布的主题
请求地址:
http://localhost:8083/connectors/debezium-connector-source-oracle-73/topics响应数据:
{"debezium-connector-source-oracle-73":{"topics":["topic-orcl-73.TEST.T_PATIENT_ZS","topic-orcl-73"]}}消费数据
通过产生的主题消费数据。
切换到KAFKA_HOME\bin\windows目录下,输入cmd,按Enter键打开cmd窗口。
输入以下命令并执行
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic topic-orcl-73.TEST.T_PATIENT_ZS --from-beginning
执行结果如下:
{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"string","optional":true,"field":"PATIENT_ID"},{"type":"string","optional":true,"field":"ZS_ID"},{"type":"int64","optional":true,"name":"io.debezium.time.Timestamp","version":1,"field":"CREATE_TIME"},{"type":"int64","optional":true,"name":"io.debezium.time.Timestamp","version":1,"field":"UPDATE_TIME"},{"type":"int64","optional":true,"name":"io.debezium.time.MicroTimestamp","version":1,"field":"JZ_TIME"},{"type":"string","optional":false,"field":"ID"}],"optional":true,"name":"topic-orcl-73.TEST.T_PATIENT_ZS.Value","field":"before"},{"type":"struct","fields":[{"type":"string","optional":true,"field":"PATIENT_ID"},{"type":"string","optional":true,"field":"ZS_ID"},{"type":"int64","optional":true,"name":"io.debezium.time.Timestamp","version":1,"field":"CREATE_TIME"},{"type":"int64","optional":true,"name":"io.debezium.time.Timestamp","version":1,"field":"UPDATE_TIME"},{"type":"int64","optional":true,"name":"io.debezium.time.MicroTimestamp","version":1,"field":"JZ_TIME"},{"type":"string","optional":false,"field":"ID"}],"optional":true,"name":"topic-orcl-73.TEST.T_PATIENT_ZS.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false,incremental"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":false,"field":"schema"},{"type":"string","optional":false,"field":"table"},{"type":"string","optional":true,"field":"txId"},{"type":"string","optional":true,"field":"scn"},{"type":"string","optional":true,"field":"commit_scn"},{"type":"string","optional":true,"field":"lcr_position"},{"type":"string","optional":true,"field":"rs_id"},{"type":"int64","optional":true,"field":"ssn"},{"type":"int32","optional":true,"field":"redo_thread"},{"type":"string","optional":true,"field":"user_name"}],"optional":false,"name":"io.debezium.connector.oracle.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"name":"event.block","version":1,"field":"transaction"}],"optional":false,"name":"topic-orcl-73.TEST.T_PATIENT_ZS.Envelope","version":1},"payload":{"before":null,"after":{"PATIENT_ID":"1","ZS_ID":"1","CREATE_TIME":1704326400000,"UPDATE_TIME":1704326400000,"JZ_TIME":1702826697000000,"ID":"1"},"source":{"version":"2.5.0.Final","connector":"oracle","name":"topic-orcl-73","ts_ms":1704339457000,"snapshot":"false","db":"ORCL","sequence":null,"schema":"TEST","table":"T_PATIENT_ZS","txId":"0b001c0067ad8900","scn":"17183616021516","commit_scn":"17183616021532","lcr_position":null,"rs_id":"0x00852f.000cb4f2.0010","ssn":0,"redo_thread":1,"user_name":"TEST"},"op":"c","ts_ms":1704339461968,"transaction":null}}说明:
消费的数据,如果含有中文,中文会出现乱码,不用理会;(因为windows中文版,cmd的编码集默认为:GBK,而数据库一般采用的是UTF-8)。
消费的数据,如果含有数值类型,会被自动编码成base64格式,这个也不用管。(这是使用kafka-consume-consumer.bat造成的,它本身还是数值类型)
源库源表数据

5.同步数据
这样一来,我们就实现了数据同步的前半部分:抽取数据 push。
示例:
至于将kafka中存储的数据更新到别的数据库(同步数据 pull),有三种实现方式:
第一种:使用插件io.confluent.connect.jdbc.JdbcSinkConnector;
第二种:使用插件io.debezium.connector.jdbc.JdbcSinkConnector(推荐使用)。
说明:
网上看到的几乎都是使用第一种方式来完成数据同步,这其实是不对的,也有使用第3种方式来完成数据同步的。
但,最好的还是使用第2种方式,因为它可以和io.debezium.connector.mysql.OracleConnector插件无缝对接,不需要进行额外的数据转换操作。
当我们使用主键字段进行数据同步时(通常情况下),目标表字段的主键的名称需要与源表的主键名称完全一致(大小写也必须保持一致),否则,使用JdbcSinkConnector会报错:
主键字段不存在。
第三种:自定义开发消费组件;
当然,官方的jdbc插件也不是万能的,例如:
源表表名与目标表表名不一致;
目标表字段B需要对应源表表字段A,而不是A-->A;
在进行数据同步时,目标表需要增加时间戳字段或者实现假删除等等个性化需求,官方插件就不能用了。
我们只能自己开发kafka connect组件了。
写在最后
哪位大佬如若发现文章存在纰漏之处或需要补充更多内容,欢迎留言!!!
相关推荐:
- 个人主页
- kafka下载、安装与部署保姆级教程(windows、linux)
- kafka 自定义开发Sink Connector组件(兼容oracle和oracle)
- Kafka Connect用法
- https://www.modb.pro/db/159580
- http://wed.xjx100.cn/news/226411.html?action=onClick
- oracle补全日志详解
- 使用debezium-connector-jdbc组件完成数据同步(io.debezium.connector.jdbc.JdbcSinkConnector)
- kafka 自定义开发Sink Connector组件
- Kafka Connect 自定义Sink Connector实现在数据同步时增加时间戳字段和假删除功能
本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/17944940

