Kafka Connect用法(windows、linux)精讲 20251456编辑
Heaven helps those who help themselves
资深码农+深耕理财=财富自由
欢迎关注
资深码农+深耕理财=财富自由
欢迎关注
Kafka Connect用法(windows、linux)精讲
Created by Marydon on 2024-01-03 15:28
1.情景展示
传统的消息中间件,如果我们想要应用到自己的系统当中,就必须在框架里面进行集成。
也就是说,必须将连接消息中间件的代码(如:生产者和消费者)嵌入到我们的web系统中,这就是所谓的硬编码。
这种硬编码的方式,侵入性强,开发成本相对较高,它要求开发人员不仅要关注业务,还要兼顾技术实现。
这也与我们开发降低系统耦合性(解耦)的原则相悖。
那能不能使消息的生产和消费脱离系统而存在呢?
2.具体分析
我们知道:kafka是可以当作消息中间件来使用的。
而kafka connect就能很好的满足我们的需求。
我们可以根据kafka connect自定义开发组件来实现数据的同步。
3.kafka connect
说明:运行kafka connect的前提是,已经启动好了kafka。
Kafka Connect是一个高伸缩性、高可靠性的数据集成工具,用于在Apache Kafka与其他系统间进行数据搬运以及执行ETL操作。
Kafka Connect主要由source connector和sink connector组成。事实上,几乎大部分的ETL框架都是由这两大类逻辑组件组成的,如Apache Flume、Kettle等。
source connector负责把输入数据从外部系统中导入到Kafka中,而sink connector则负责把输出数据导出到其他外部系统。
配置文件说明
单独部署配置文件:KAFKA_HOME/config/connect-standalone.properties
集群部署配置文件:KAFKA_HOME/config/connect-distributed.properties
找到KAFKA_HOME/config目录下的connect-standalone.properties和connect-distributed.properties文件。
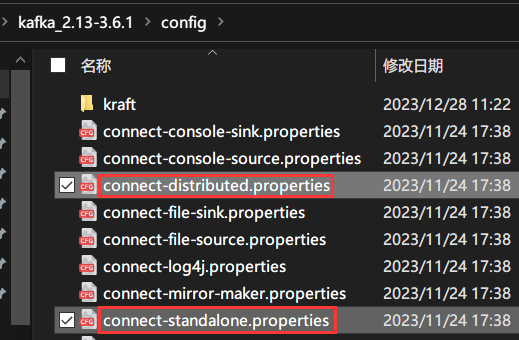
connect-standalone.properties:当只有一个kafka服务器时,我们需要使用这个配置文件。
connect-distributed.properties:当存在多个kafka服务器时(集群部署),我们需要使用这个配置文件。
以connect-standalone.properties为例:

说明:如果是connect-distributed.properties,这里可以配置多个broker地址,中间使用逗号隔开。

另外,如果用localhost:9092访问不到kafka服务器,请改成服务器对应的局域网IP,如:192.168.0.1。
bootstrap.servers属性:指定broker服务器的地址,默认值为:localhost:9092。
配置多个kafka地址的话,一个kafka connect就可以连接多个kafka。
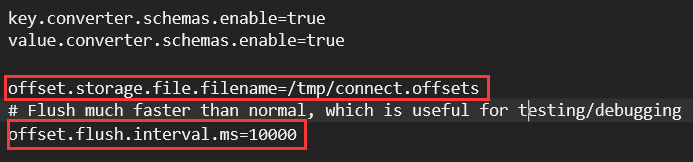
offset.storage.file.filename属性:设置偏移量文件connect.offsets的存放地址,默认路径为:/tmp。
linux:connect.offsets存储在:/tmp目录下,windows:connect.offsets存在KAFKA_HOME所在磁盘的/tmp目录下。
当目录不存在时,会自动被创建。
说明:这个属性在单独部署文件connect-standalone.properties中才存在。

在集群模式中是不需要设置连接器偏移量的存储位置的。

因为连接器偏移量被放置在了kafka的connect-offsets主题当中。
offset.flush.interval.ms属性:偏移量刷新时间间隔,单位:毫秒,默认值为:10000毫秒(10秒)。
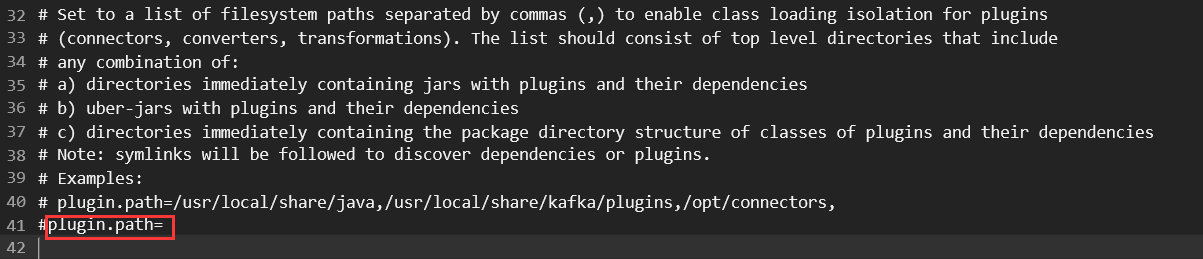
plugin.path属性:设置connect插件的存放路径,多个路径之间使用逗号隔开。
在启动kafka connect时,会自动从上面配置的路径,读取connect插件。
一般情况下,我们不在这里配置,而是将插件直接放在:KAFKA_HOME/plugins目录下。
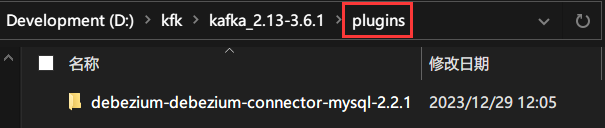
plugin.path=/kfk/kafka_2.13-3.6.1/plugins

说明:插件路径分隔符必须使用"/",不能使用反斜杠"\",否则插件将不会被kafka connect加载进去。
另外,在windows操作系统中,可以在不加盘符的情况下,将会被默认识别问当前目录所在的盘符。
这样一来,当你使用connect-standalone.bat并且指定配置文件connect-standalone.properties时,kafka connect在启动的时候,会自动读取此路径下的插件(Source Connector和Sink Connector)。

验证插件是否生效
http://localhost:8083/connector-plugins


listeners属性:设置的是kafka connect服务器的访问端口号,默认值是8083。
多个地址之间使用逗号隔开。
如何更改它的端口号呢?
listeners=HTTP://:8093
在此配置文件当中增加如上代码, 我们就把kafka connect的端口号改成8093啦。
启动kafka connect
启动前提:运行zookeeper和kafka。
kafka connect的启动方式有两种:单独部署和集群部署。
启动文件说明:
windows版
单独部署:KAFKA_HOME/bin/windows/connect-standalone.bat
集群部署:KAFKA_HOME/bin/windows/connect-distributed.bat
linux版
单独部署:KAFKA_HOME/bin/connect-standalone.sh
集群部署:KAFKA_HOME/bin/connect-distributed.sh
以只运行一个broker进行举例说明
windows操作步骤
broker的启动命令是:connect-standalone.bat
文件所在路径:KAFKA_HOME/bin/windows
所需配置文件:connect-standalone.properties
文件所在路径:KAFKA_HOME/config
切换到KAFKA_HOME/bin/windows目录下,输入cmd。

并按回车键打开黑窗口。
运行以下命令:
connect-standalone.bat ../../config/connect-standalone.properties

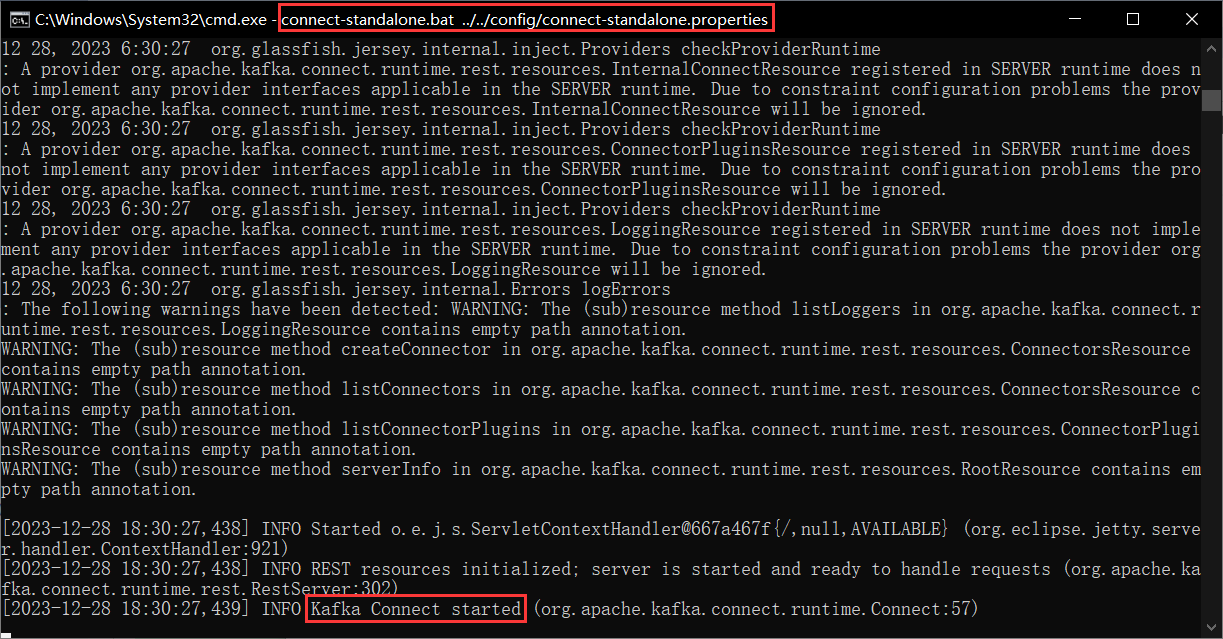
当出现如上字样时,就说明:kafka connect服务启动成功了。
访问地址:
http://localhost:8083/

3.6.1是kafka服务器的版本号。
黑窗口使用小技巧
当kafka进程正在运行时,屏幕内容会一直在变,如果我们需要查看屏幕上的内容时,可以通过点击鼠标来暂停屏幕内容输出。
如果想继续输出日志,按Enter键或者快捷键Ctrl+c。
说明:
在单独模式下,如果屏幕内容暂停输出的话,程序将暂停执行,直到按Enter键或者快捷键Ctrl+c,屏幕内容发生变化时,才会继续往下执行;
在集群模式下,屏幕内容暂停输出并不影响进程的执行。
如果是集群模式模式下,
以集群的方式启动kafka connect
connect-distributed.bat ../../config/connect-distributed.properties
linux操作步骤
broker的启动命令是:connect-standalone.sh。
文件所在路径:KAFKA_HOME/bin
所需配置文件:connect-standalone.properties。
文件所在路径:KAFKA_HOME/config
说明:
在linux操作系统下,单独部署基本上没有意义,所以,这里不讲单独部署,而是将集群部署。
即使你只运行一个connector,也推荐使用集群部署。
修改connect-standalone.properties,如果需要的话。
进入kafka根目录下

以集群的方式启动kafka connect
./bin/connect-distributed.sh -damon config/connect-distributed.properties
说明:不带./也是可以的。
-daemon:是以守护进程的方式启动kafka connect。这样一来,当我们关闭会话或者退出当前命令操作时,kafka connect会继续保持运行。
之所以可以使用参数-daemon,是因为connect-distributed.sh文件中有关于该参数的配置。

运行日志说明
kafka connect的运行日志默认存储位置为:KAFKA_HOME/logs目录下。

如上图所示,connect.log就是kafka-connect当前正在运行的日志内容。
运行日志一个小时拆分一次,connect.log会被自动拆分并且添加日期后缀名及小时。

并且确保最新运行日志内容始终存放在connect.log文件当中。
具体日志规则见:KAFKA_HOME/config/log4j.properties。
当然,如果你是以集群模式运行kafka connect的话,运行日志同样会被写入到connectDistributed.out文件中;
如果你是以单独模式运行kafka connect的话,运行日志同样会被写入到connectStandalone.out文件中。
linux环境下,如何查看kafka connect运行日志?
切换到kafka所在目录
cd /home/kafka_2.13-3.7.0
循环输出kafka connect运行日志内容
tail -f logs/connect.log
当时间来到整点时,会将现有的connect.log的内容进行拆分,当前文件会被自动加上日期,即connect.log会被重命名,形如:connect.log.2024-06-25-10-9。
同时,kafka connect会重新创建connect.log并将运行日志输出到该文件当中。
这样一来,之前的connect.log已经变成了connect.log.2024-06-25-10-9,当该文件内容被输出完毕后,屏幕内容将不会再发生变化。
要想继续查看运行日志,我们需要先退出当前命令(Ctrl+c)。
然后,再执行上述命令就可以啦。
关闭kafka connect服务
查询kafka connect对应的进程ID。
方式一:
搜索kafka-distributed.sh
ps -ef|grep connect-dist

由此可以看到:
kafka connect使用的进程ID为:12770。
方式二:
netstat -nltp|grep 8083

kafka connect使用的进程ID为:12770。
使用kill杀掉进程就可以了。
kill PID
2024-09-04 18:08:26
方式三:
jps
使用jps获取到所有正在运行的java进程。

当我使用杀掉kafka connect的服务(端口8083)后,发现:
虽然端口无法访问了,但是connect.log仍在继续输出日志,这也就证明kafka connect仍在运行。
执行jps命令后,发现:果然kafka connect仍在运行。
当我使用kill pid将该进程杀掉后,发现该进程仍在继续运行。
迫于无奈,只能使用kill -9 pid 强制杀掉进程。
4.常见接口
接口文档:
如果你的kafka版本是3.7.X,请用下面这个链接。
https://kafka.apache.org/37/generated/connect_rest.yaml
如果你的kafka版本是3.4.X,请用下面这个链接。

https://kafka.apache.org/34/generated/connect_rest.yaml
kafka不同的版本,对应的kafka connect对外提供的接口数量是不一样的。
请根据你的kafka实际版本号,按照上述链接将版本号改成对应的数字,就是你所使用的kafka的版本所对应的接口文档。
访问路径前缀:
http://localhost:8083/
GET /connectors
返回所有正在运行的 connector 名。
请求地址:
http://localhost:8083/connectors
请求方式:GET请求
响应数据示例
["debezium-connector-source-mysql-63"]
POST /connectors
新建一个 connector。
请求地址:
http://localhost:8083/connectors
请求方式:POST请求
请求数据示例
{ "name": "debezium-connector-source-mysql-63", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.user": "username", "database.server.id": 63, "schema.history.internal.kafka.bootstrap.servers": "localhost:9092", "column.include.list": "test.t_patient.CREATE_TIME,test.t_patient.ID,test.t_patient.JZ_TIME,test.t_patient.PATIENT_ID_NO,test.t_patient.PATIENT_NAME,test.t_patient.PATIENT_SEX,test.t_patient.UPDATE_TIME,test.t_patient.ZY_TIME", "database.port": "3306", "schema.history.internal.store.only.captured.tables.ddl": true, "inconsistent.schema.handling.mode": "warn", "topic.prefix": "topic-test-63", "schema.history.internal.kafka.topic": "schema-history-test-63", "database.hostname": "192.168.0.1", "database.password": "password", "table.include.list": "test.t_patient", "database.include.list": "test", "snapshot.mode": "initial" } }
响应数据示例:
{{ "name": "debezium-connector-source-mysql-63", "type": "source", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.user": "username", "database.server.id": "63", "schema.history.internal.kafka.bootstrap.servers": "localhost:9092", "column.include.list": "test.t_patient.CREATE_TIME,test.t_patient.ID,test.t_patient.JZ_TIME,test.t_patient.PATIENT_ID_NO,test.t_patient.PATIENT_NAME,test.t_patient.PATIENT_SEX,test.t_patient.UPDATE_TIME,test.t_patient.ZY_TIME", "database.port": "3306", "schema.history.internal.store.only.captured.tables.ddl": "true", "inconsistent.schema.handling.mode": "warn", "topic.prefix": "topic-test-63", "schema.history.internal.kafka.topic": "schema-history-test-63", "database.hostname": "192.168.0.1", "database.password": "password", "table.include.list": "test.t_patient", "database.include.list": "test", "snapshot.mode": "initial", "name": "debezium-connector-source-mysql-63" }, "tasks": [{ "connector": "debezium-connector-source-mysql-63", "task": 0 }] }}
GET /connectors/{name}
获取指定 connetor 的信息。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63
请求方式:GET请求
响应数据示例
{{ "name": "debezium-connector-source-mysql-63", "type": "source", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.user": "username", "database.server.id": "63", "schema.history.internal.kafka.bootstrap.servers": "localhost:9092", "column.include.list": "test.t_patient.CREATE_TIME,test.t_patient.ID,test.t_patient.JZ_TIME,test.t_patient.PATIENT_ID_NO,test.t_patient.PATIENT_NAME,test.t_patient.PATIENT_SEX,test.t_patient.UPDATE_TIME,test.t_patient.ZY_TIME", "database.port": "3306", "schema.history.internal.store.only.captured.tables.ddl": "true", "inconsistent.schema.handling.mode": "warn", "topic.prefix": "topic-test-63", "schema.history.internal.kafka.topic": "schema-history-test-63", "database.hostname": "192.168.0.1", "database.password": "password", "table.include.list": "test.t_patient", "database.include.list": "test", "snapshot.mode": "initial", "name": "debezium-connector-source-mysql-63" }, "tasks": [{ "connector": "debezium-connector-source-mysql-63", "task": 0 }] }}
DELETE /connectors/{name}
删除一个 connector,停止它的所有 task 并删除配置 。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63
请求方式:DELETE请求
响应数据:无。

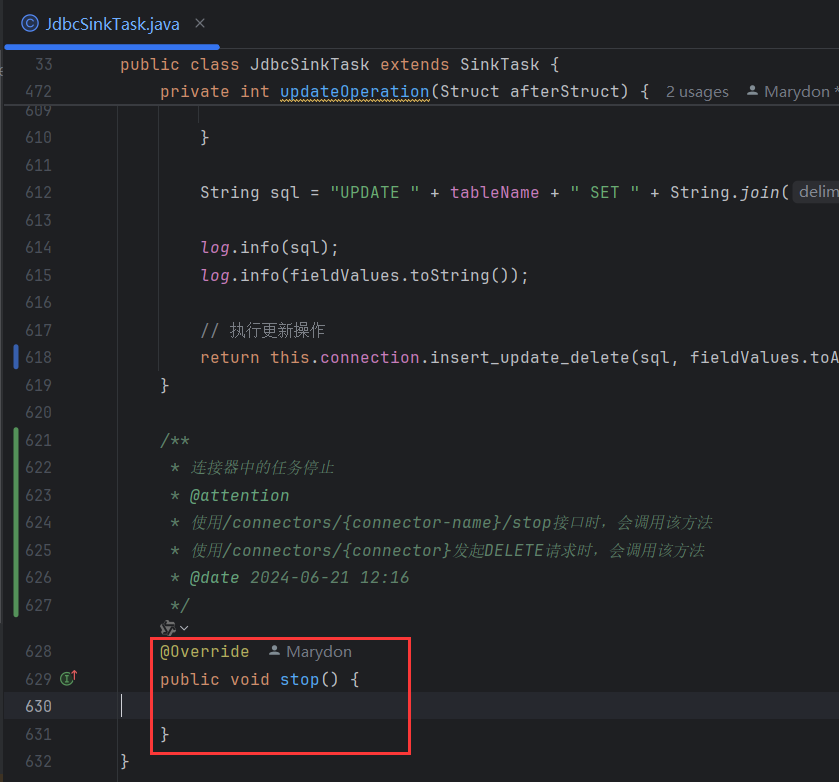
当你对Kafka Connect的/connectors/{connector}发起DELETE请求时,Kafka Connect会先调用该连接器所有任务(包括Sink Connector的任务)的stop()方法。
这个过程包括以下几个步骤:
停止任务:Kafka Connect会先停止该连接器下的所有Task,这包括调用每个Task的stop()方法。在Sink Connector的场景中,这通常意味着停止从Kafka消费数据、关闭输出到目标系统的连接(如数据库连接)、清理资源,并保存必要的状态(如偏移量)。
资源清理:stop()方法执行期间,会进行必要的资源清理工作,确保没有资源泄露。
连接器删除:在所有Task成功停止并清理完资源后,Kafka Connect会删除该连接器的配置和状态信息,最终完成连接器的删除操作。
需要注意的是,一旦执行了DELETE请求,除非重新创建并配置该连接器,否则它将不再存在于Kafka Connect服务中,且之前的状态和配置信息(如果不做额外备份)也将丢失。


另外,当连接器被删除后,存在kafka里面的主题信息是不会被删除的。

还有就是,即使,连接器被删除,source和sink connector的偏移量信息依然存在。
这也就是说:下次新建连接器,只要保证他们的name一致(也就是还用原来的配置信息)的话,一旦新建,会接着原来的任务继续执行(而不需要从头重新开始)。

GET /connectors/{name}/config
获取指定 connector 的配置信息。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/config
请求方式:GET请求
响应数据示例:
{ "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.user": "username", "database.server.id": 63, "schema.history.internal.kafka.bootstrap.servers": "localhost:9092", "column.include.list": "test.t_patient.CREATE_TIME,test.t_patient.ID,test.t_patient.JZ_TIME,test.t_patient.PATIENT_ID_NO,test.t_patient.PATIENT_NAME,test.t_patient.PATIENT_SEX,test.t_patient.UPDATE_TIME,test.t_patient.ZY_TIME", "database.port": "3306", "schema.history.internal.store.only.captured.tables.ddl": true, "inconsistent.schema.handling.mode": "warn", "topic.prefix": "topic-test-63", "schema.history.internal.kafka.topic": "schema-history-test-63", "database.hostname": "192.168.0.1", "database.password": "password", "table.include.list": "test.t_patient", "database.include.list": "test", "snapshot.mode": "initial", "name": "debezium-connector-source-mysql-63" }
PUT /connectors/{name}/config
更新指定 connector 的配置信息。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/config
请求方式:PUT请求
GET /connectors/{name}/status
获取指定 connector 的状态,包括它是否在运行、停止、或者失败,如果发生错误,还会列出错误的具体信息。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/status
请求方式:GET请求
响应数据示例:
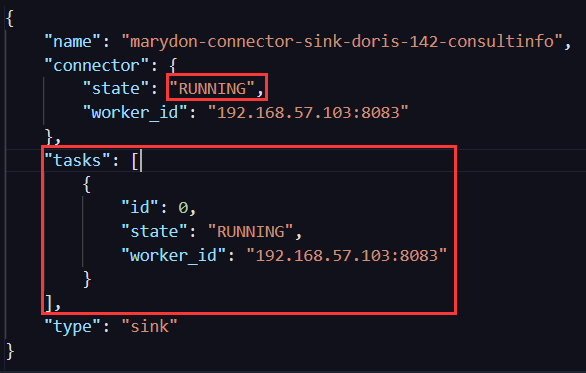
{ "name": "debezium-connector-source-mysql-63", "connector": { "state": "RUNNING", "worker_id": "192.168.0.103:8083" }, "tasks": [{ "id": 0, "state": "RUNNING", "worker_id": "192.168.0.103:8083" }], "type": "source" }
PUT /connectors/{name}/pause
暂停 connector 和它的 task的运行,可以被恢复。
说明:通过pause的connector,可通过resume请求恢复正常,调用restart接口无效。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/pause
请求方式:PUT请求
响应数据:无。


task.java和connector.java对应的stop()都会被调用。
PUT /connectors/{name}/stop
停止 connector,清空tasks,停止数据处理,直到它被恢复。
PS:网上都说被stop后,无法恢复。但是,经测试是可以恢复的。(kafka_2.13-3.7.0)
说明:通过stop停止的connector,可以通过resume请求进行恢复,通过restart无效。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/stop
请求方式:PUT请求
响应数据:无。

connector的task将被停止并清空,connector的状态也会变成停止状态。


同时,当task被stop时,会调用任务类里的stop()。

接口请求结果为404,说明你的kafka版本较低,并不支持该方法。

正常情况下,在浏览器中打开(get请求),响应结果应为:不允许的请求方法。
PUT /connectors/{name}/resume
恢复一个被pause/stop的 connector(或者,如果连接器未暂停,则不执行任何操作)。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/resume
请求方式:PUT请求
响应数据:无。
示例1
调接口:PUT /connectors/{name}/pause,connector和task变成了PAUSED状态。
调用resume后,恢复正常。
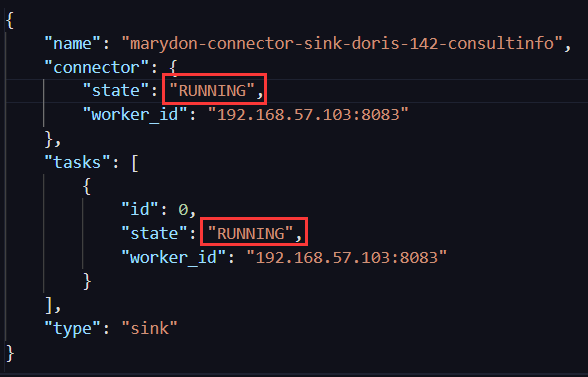
示例2
调接口:PUT /connectors/{name}/stop,connector变成了STOPPED状态、tasks被清空。
调用resume后,恢复正常。
PUT /connectors/{name}/restart
重启一个 connector,尤其是在一个 connector 运行失败的情况下比较常用。
说明:被停止(Pause和Stop)的连接器不能使用此操作,即使调用了也不会让连接器恢复运行状态。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/restart
请求方式:PUT请求
响应数据:无。
GET /connectors/{name}/tasks
获取指定 connector 正在运行的 task。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/tasks
请求方式:GET请求
响应数据示例:
[{ "id": { "connector": "debezium-connector-source-mysql-63", "task": 0 }, "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.user": "username", "database.server.id": "63", "schema.history.internal.kafka.bootstrap.servers": "localhost:9092", "column.include.list": "test.t_patient.CREATE_TIME,test.t_patient.ID,test.t_patient.JZ_TIME,test.t_patient.PATIENT_ID_NO,test.t_patient.PATIENT_NAME,test.t_patient.PATIENT_SEX,test.t_patient.UPDATE_TIME,test.t_patient.ZY_TIME", "database.port": "3306", "schema.history.internal.store.only.captured.tables.ddl": "true", "inconsistent.schema.handling.mode": "warn", "topic.prefix": "topic-test-63", "schema.history.internal.kafka.topic": "schema-history-test-63", "task.class": "io.debezium.connector.mysql.MySqlConnectorTask", "database.hostname": "192.168.0.1", "database.password": "password", "name": "debezium-connector-source-mysql-63", "table.include.list": "test.t_patient", "database.include.list": "test", "snapshot.mode": "initial" } }]
GET /connectors/{name}/tasks/{task-id}/status
获取指定 connector 的 task 的状态信息 。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/tasks/0/status
请求方式:GET请求
响应数据示例:
{"id":0,"state":"RUNNING","worker_id":"192.168.0.103:8083"}
POST /connectors/{name}/tasks/{task-id}/restart
重启一个 task,一般是因为它运行失败才这样做。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/tasks/0/restart
请求方式:POST请求
请求数据:暂无。
响应数据:暂无。
GET /connectors/{name}/tasks-config
获取指定连接器的tasks配置。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/tasks-config
请求方式:GET请求
响应数据示例:
{ "debezium-connector-source-mysql-63-0": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.user": "username", "database.server.id": 63, "schema.history.internal.kafka.bootstrap.servers": "localhost:9092", "column.include.list": "test.t_patient.CREATE_TIME,test.t_patient.ID,test.t_patient.JZ_TIME,test.t_patient.PATIENT_ID_NO,test.t_patient.PATIENT_NAME,test.t_patient.PATIENT_SEX,test.t_patient.UPDATE_TIME,test.t_patient.ZY_TIME", "database.port": "3306", "schema.history.internal.store.only.captured.tables.ddl": true, "inconsistent.schema.handling.mode": "warn", "topic.prefix": "topic-test-63", "schema.history.internal.kafka.topic": "schema-history-test-63", "database.hostname": "192.168.0.1", "database.password": "password", "table.include.list": "test.t_patient", "database.include.list": "test", "snapshot.mode": "initial" } }
GET /connector-plugins
返回安装在Kafka Connect运行中的连接器插件列表。
请求地址示例:
http://localhost:8083/connector-plugins
请求方式:GET请求
响应数据示例:
[{ "class": "org.apache.kafka.connect.file.FileStreamSinkConnector", "type": "sink", "version": "3.6.1" }, { "class": "io.debezium.connector.mysql.MySqlConnector", "type": "source", "version": "2.2.1.Final" }, { "class": "org.apache.kafka.connect.file.FileStreamSourceConnector", "type": "source", "version": "3.6.1" }, { "class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector", "type": "source", "version": "3.6.1" }, { "class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector", "type": "source", "version": "3.6.1" }, { "class": "org.apache.kafka.connect.mirror.MirrorSourceConnector", "type": "source", "version": "3.6.1" }]
除了io.debezium.connector.mysql.MySqlConnector,其余的都是kafka的默认提供的插件。
GET /connector-plugins/{plugin-class}/config
获取指定插件的配置。
请求地址示例:
http://localhost:8083/connector-plugins/io.debezium.connector.mysql.MySqlConnector/config
请求方式:GET请求
响应数据片段示例:

PUT /connector-plugins/{plugin-class}/config/validate
根据配置定义验证提供的配置值。此API执行每个配置验证,在验证期间返回建议值和错误消息。
请求地址示例:
http://localhost:8083/connector-plugins/io.debezium.connector.mysql.MySqlConnector/validate
请求方式:PUT请求
响应数据示例:暂无。
GET /connectors/{name}/topics
获取连接器所有的主题。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/topics
请求方式:GET请求
响应数据示例:
{ "debezium-connector-source-mysql-63": { "topics": ["topic-test-63.test.t_patient", "topic-test-63"] } }
PUT /connectors/{name}/topics/reset
重置连接器所有的主题。
说明:
连接器的主题信息,是在创建connector时自动生成的,所以,要想恢复此连接器下的主题信息,需要先删除此连接器,再重新创建此连接器。
所以说,既然我们无法通过REST API的方式手动为Source Connector创建主题,也无法为Sink Connector绑定主题,那么,这个接口对于我们来说,没有任何意义。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/topics/reset
请求方式:PUT请求
响应数据:无。
GET /connectors/{name}/offsets
获取指定连接器的偏移量。
既可以获取Source Connector的偏移量,也可以获取Sink Connector的偏移量。
获取Source Connector的偏移量,示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-135/offsets
请求方式:GET请求
响应数据示例:
{ "offsets": [ { "offset": { "file": "binlog.003488", "gtids": "1034a020-f4fd-11eb-aae8-fa163e7c418e:1-106594496", "pos": 449013112, "ts_sec": 1717229062 }, "partition": { "server": "topic-medi_data_cent-135" } } ] }
Sink Connector:debezium-connector-sink-sqlserver-135-t_patient
{ "offsets": [ { "offset": { "kafka_offset": 4 }, "partition": { "kafka_partition": 0, "kafka_topic": "topic-medi_data_cent-135.medi_data_cent.t_patient" } } ] }

接口请求结果为404,说明你的kafka版本较低,并不支持该方法。

DELETE /connectors/{name}/offsets
重置指定连接器的偏移量。
前提:重置指定连接器的偏移量的前提是:该连接器必须处于暂停状态(stop),否则,调该接口会报错,偏移量也不会被重置。
请求地址示例:
http://localhost:8083/connectors/debezium-connector-source-mysql-63/offsets
请求方式:DELETE请求
响应数据:无。
偏移量重置后,偏移量信息会被清空。

说明:
重置指定连接器的偏移量,既可以重置Source connector的offsets,也可以重置Sink Connector的offsets。
另外,重置偏移量,并不是说偏移量从0开始重新消费,具体从哪里开始,不确定!
如下图所示,共有46万条数据,重置偏移量后,重新消费是从第35万条开始的。

如果想要从0开始消费主题中的数据,需要调修改偏移量的接口(PATCH /connectors/{name}/offsets),将偏移量的起始位置设为0。(这个貌似也不能从0开始)
重置Sink Connector的offsets(重新拉)
重置Sink Connector的偏移量是为了让Sink Connector从订阅的主题中从某个位置开始重新拉取数据,然后同步至目标表。
重置sink connector的偏移量,可以控制topic的消费位置(从kafka订阅主题已经读过的位置),即:从某个位置开始重新消费。
一个完整的重置Sink Connector的偏移量过程,应该这样操作:
第1步:停止Sink连接器运行(STOP);
第2步:重置连接器的偏移量(连接器必须处于停止状态才能重置偏移量)(RESET);
第3步:恢复连接器运行状态(被stop的连接器必须通过resume才能恢复运行)(RESUME)。
重置Source Connector的offsets和Sink Connector的offsets(重新抽&重新拉)
一般情况下,重置Source Connector的偏移量就需要重置Sink Connector的偏移量。
重置Source Connector的偏移量的目的是为了:
让Source Connector重新读取源数据库的日志,从而重新将读取到的变更数据推送到kafka对应的主题当中。
既然主题中的数据重新生成了,但是,由于Sink Connector之前已经将订阅的主题中的数据取走了,所以,不可能再重新从0开始取数据。
这样一来的话,Source Connector重新发布到主题当中的数据,Sink Connector并不会重新拉取。
所以说,重置Source Connector的偏移量的同时,也必须重置Sink Connector的偏移量。
不然的话,Source Connector重新生成的数据,Sink Connector却不要,这将造成目标表与源表的数据不一致。
需要重置source connector偏移量的情况:源表结构发生了变化,需要重新抽数据
一个完整的重置Source Connector和Sink Connector的偏移量过程,应该这样操作:
步骤一:停止Source连接器运行,然后重置Source连接器的偏移量,然后恢复Source连接器运行;
步骤二:停止Sink连接器运行,然后重置Sink连接器的偏移量,然后恢复Sink连接器运行。
Step 1:停止Source连接器运行(STOP);
Step 2:重置连接器的偏移量(连接器必须处于停止状态才能重置偏移量)(RESET);
Step 3:恢复连接器运行状态(被stop的连接器必须通过resume才能恢复运行)(RESUME);
Step 4:停止Sink连接器运行(STOP);
Step 5:重置连接器的偏移量(连接器必须处于停止状态才能重置偏移量)(RESET);
Step 6:恢复连接器运行状态(被stop的连接器必须通过resume才能恢复运行)(RESUME)。
重置source和sink的偏移量会造成的问题:
在Source Connector运行期间,如果表中出现了新增数据,那么Source Connector将该操作视为:operation=c(这是没有问题的)。
而重置Source Connector的偏移量后,这条数据记录不仅被记成了operation=c,还被记为了operation=r。
则这条数据就被标记成了:即是READ(operation=r),又是CREATE(operation=c),那它将至少被同步至目标表两次。
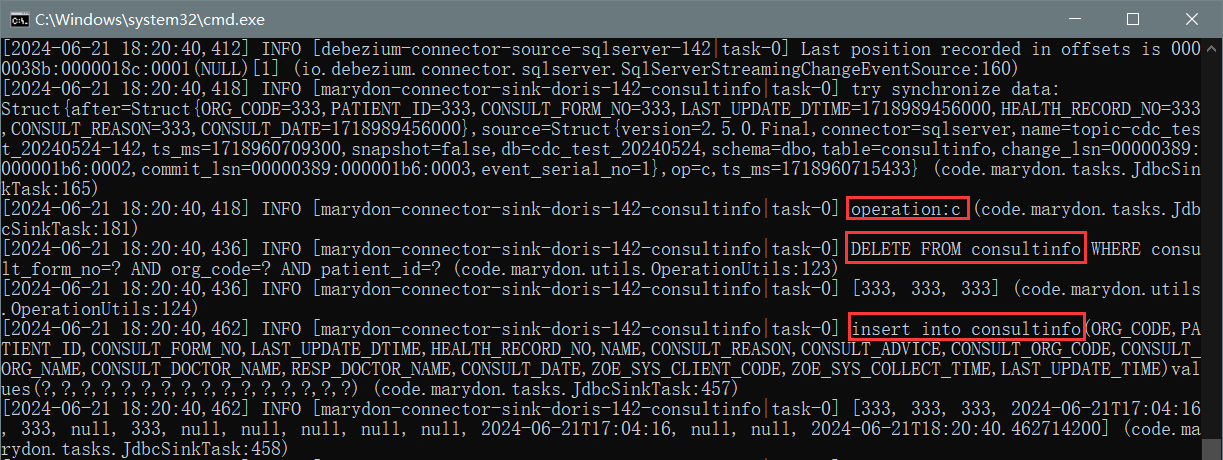
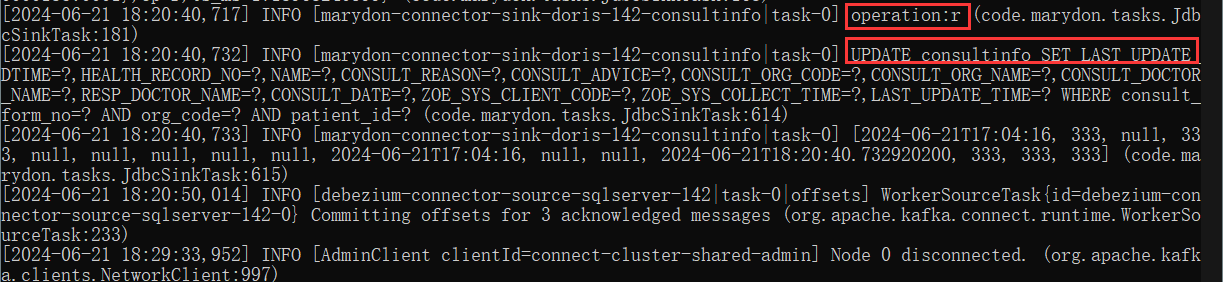
如上图所示:虽是同一条数据,却同步N次。
如果这条数据在Source Connector运行期间,又被修改,然后删除,则会更乱,虽然最终也会被删除,但中间的次数却一个都少不了。
当然,这是我的自定义开发的sink connector的实现效果。
如果用官方的JdbcSinkConnector,具体内部执行情况,需要自己去看源代码。
PATCH /connectors/{name}/offsets
修改指定连接器的偏移量,通过修改连接器的主题的偏移量来控制topic数据的产生和消费进度。
前提:修改指定连接器的偏移量的前提是:该连接器必须处于暂停状态(stop),否则,调该接口会报错,偏移量也不会被修改。
说明:
修改指定连接器的偏移量,既可以修改Source connector的offsets,也可以修改Sink Connector的offsets。
通过Source Connector产生的主题没有分区,即kafka_partition=0。
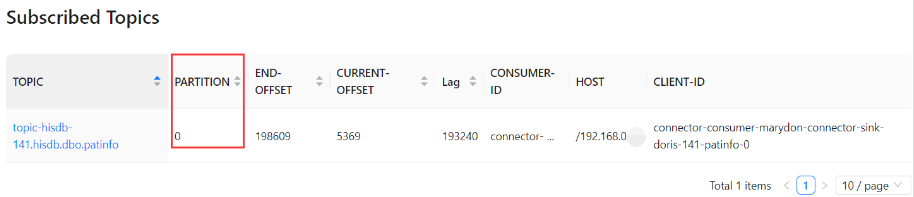
以修改sink connector的消费偏移量进行举例说明。
初始状态
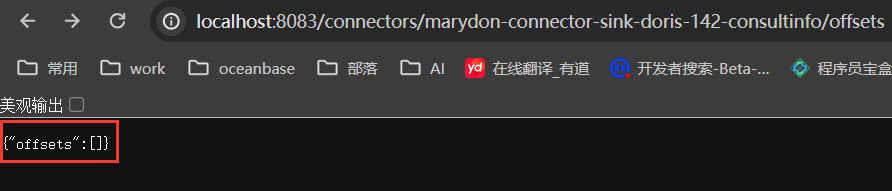
处理数据后
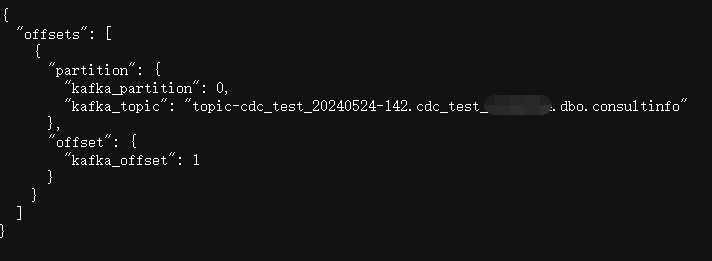
请求地址示例:
http://localhost:8083/connectors/marydon-connector-sink-doris-142-consultinfo/offsets
请求方式:PATCH请求
请求数据
{ "offsets": [ { "offset": { "kafka_offset": "0" }, "partition": { "kafka_partition": "0", "kafka_topic": "topic-cdc_test_20240524-142.cdc_test_xxxx.dbo.consultinfo" } } ] }
响应数据
{ "message": "The Connect framework-managed offsets for this connector have been altered successfully. However, if this connector manages offsets externally, they will need to be manually altered in the system that the connector uses." }
修改Sink Connector的offsets
修改Sink Connector的偏移量是为了让Sink Connector从订阅的主题中从指定位置开始重新拉取数据,然后同步至目标表。
修改sink connector的偏移量,可以控制sink connnector 消费topic的位置(从kafka订阅主题已经读过的位置),即:从指定偏移量开始消费。
一个修改的重置Sink Connector的偏移量过程,应该这样操作:
第1步:停止Sink连接器运行(STOP);
第2步:修改连接器的偏移量(连接器必须处于停止状态才能修改偏移量)(ALTER);
第3步:恢复连接器运行状态(被stop的连接器必须通过resume才能恢复运行)(RESUME)。
补充说明:
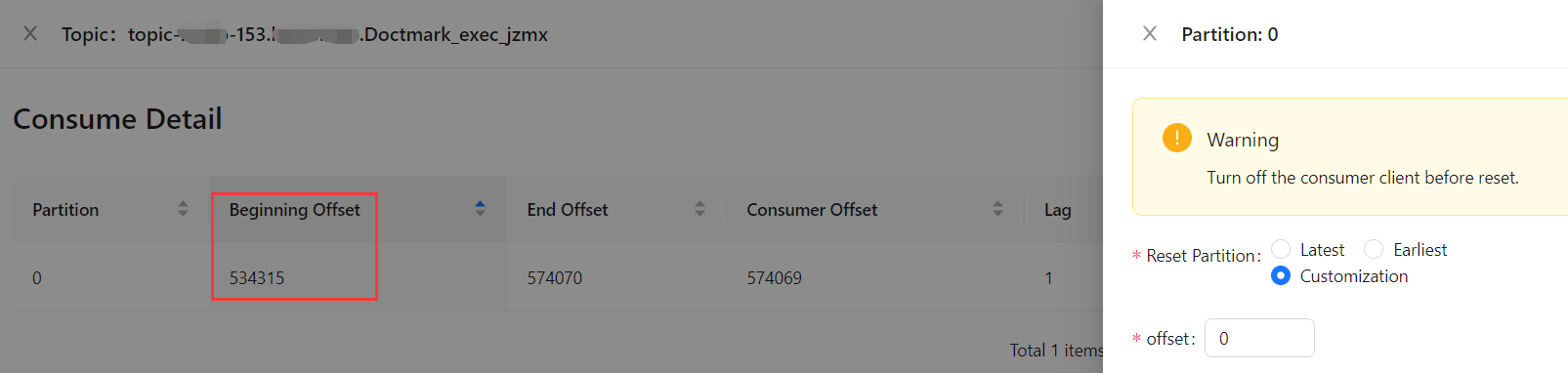
当前偏移量
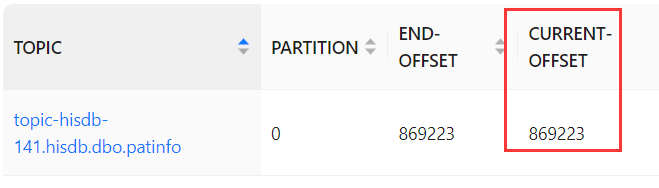
将偏移量修改成0;
偏移量修改成功。
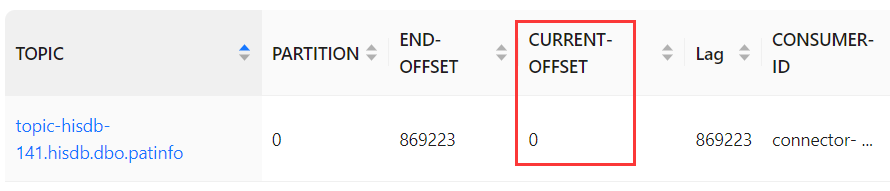
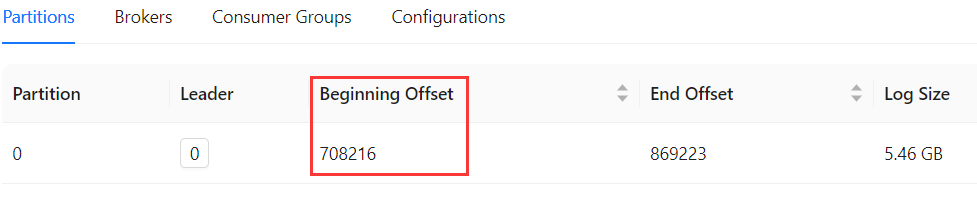
然而,它并不是从0开始消费的,
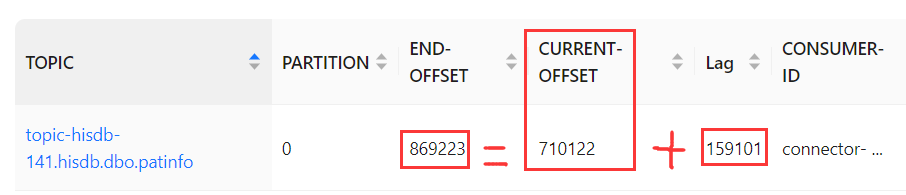
而是从上次记录的Beginning Offset开始的。
2024-11-06 17:15:59
为什么要修改偏移量,因为如果连接器所对应的任务执行失败时,任务的偏移量并一定就是连接器的偏移量。
连接器需要将偏移量回滚至534569

但实际上此时连接器的偏移量已经走到了534592

这样,我们在下次启动任务时,是从534592消费的,而不是从534569消费的,这个时候就造成数据的遗漏。
所以,我们需要更改连接器的偏移量。
修改Source Connector的offsets
至于修改Source Connector的offsets,暂时没有这种需求。
GET /admin/loggers
获取所有日志级别信息。
请求地址示例:
http://localhost:8083/admin/loggers
请求方式:GET请求
响应数据示例:
{"org.reflections":{"level":"ERROR"},"root":{"level":"INFO"}}
GET /admin/loggers/{log-name}
获取指定日志级别信息。
请求地址示例:
http://localhost:8083/admin/loggers/root
请求方式:GET请求
响应数据示例:
{"level":"INFO"}
PUT /admin/loggers/{log-name}
设置指定日志级别信息。
说明:
日志级别有:DEBUG、INFO、WARN、ERROR等。
通常情况下,我们可以通过更改root的日志级别来控制kafka connect的日志输出级别。
请求地址示例:
http://localhost:8083/admin/loggers/root
请求方式:PUT请求
请求数据示例:
{"level":"warn"}
响应数据:无。
2024-06-21 17:34:58
5.补充说明
PAUSE和STOP接口的区别
使用/pause时,连接器进入待机模式,随时可以恢复而不丢失配置或状态,适合临时性的维护或资源调配。
使用/stop时,连接器完全停止,需要重新启动,适用于长时间维护、配置变更或彻底移除连接器的场景。
共同点:
二者都能通过RESUME将connector和task恢复成RUNNING状态。
二者都会调task.java类中的stop()和connector.java的stop()方法。
不同点:
PAUSE:将连接器和任务的状态都设置成PAUSEED。
STOP:将连接器的状态改成STOPPED,停止并清空tasks。
如果想要重置连接器的偏移量,必须调用STOP接口,不能调用PAUSE接口。
来看下效果:
先调PAUSE,再重置偏移量
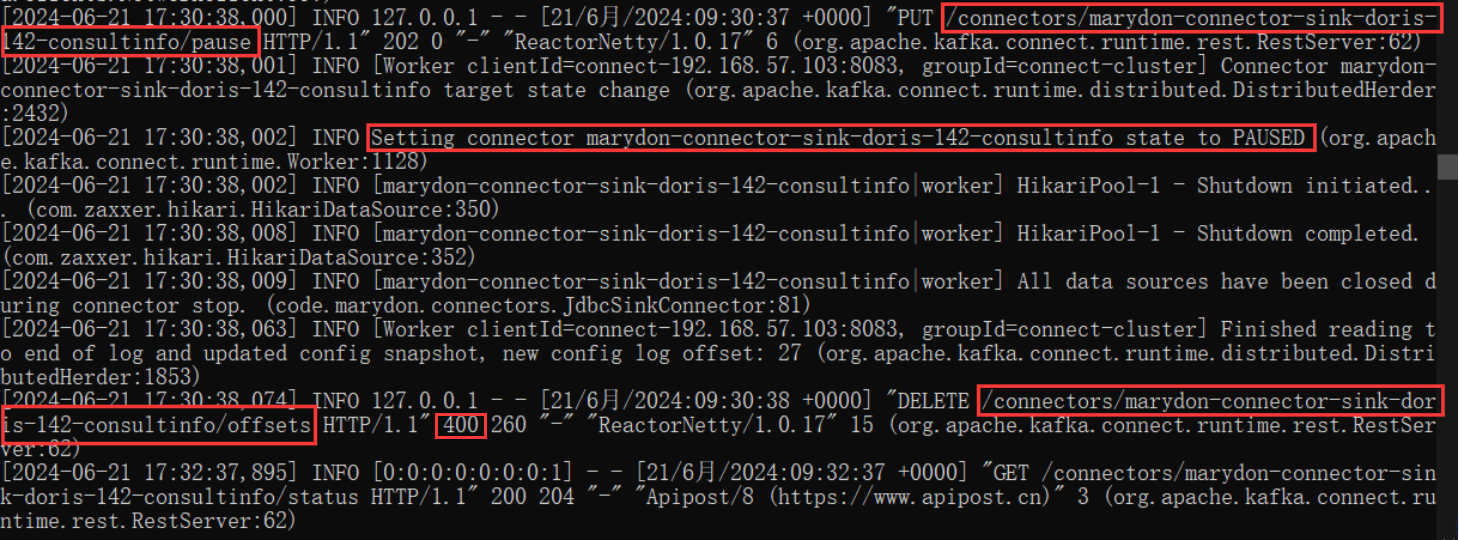
我们可以看到:
调重置偏移量接口,返回结果是:400。
先调STOP,再重置偏移量


由上图可以看到:
连接器被stop后,调用重置偏移量接口,状态值为200,说明偏移量重置成功。
2024-06-24 10:45:59
kafka connect集群模式
关于kafka connect使用集群模式部署的优势说明。
kafka connect如果被关闭,再次启动后,之前正在运行的任务会继续执行。

bin/connect-distributed.sh -daemon config/connect-distributed.properties
当连接器处于RUNNING状态时,如果我们把kafka connect手动关闭或意外关闭,当我们把kafka connect服务启动后,之前的任务会继续执行,不受影响。

kafka如果被关闭,kafka connect会暂停数据同步,当kafka服务启动后,之前的任务会继续执行。


关闭kafka,kafka connect会一直提示kafka不存在。
启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
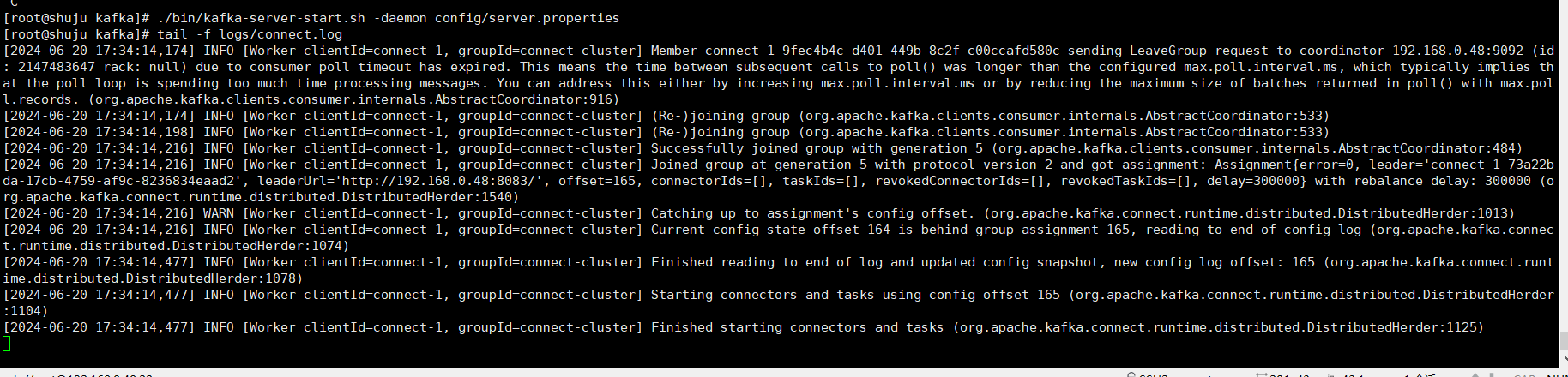
当kafka connect检测到kafka已经能访问得到后,会自动启动connectors和tasks。(上图中最后一句话)

kafka和kafka connect都被关闭,再次启动后,之前正在运行的任务会继续执行下去,不受影响。
无论是先关kafka,再关kafka connect,还是先关kafka connect,再关kafka。
然后先启动kafka,再启动kafka connect,还是先启动kafka connect,再启动kafka。
只要是在kafka connect运行期间,任务的运行状态是RUNNING的,再次启动后,任务会接着kafka/kafka connect关闭之前的进度继续执行。
kafka、kafka connect、zookeeper,这三个服务都被关闭的情况下,如果关闭之前连接器正在执行(RUNNING),待启动后,被迫中断的任务会继续执行。
也就是说:
只要是你使用集群模式启动的kafka connect,kafka、kafka connect、zookeeper这3个服务任意一个或两个被关闭,或者全部被关闭,只要是在关闭之前,我们没有手动调接口将连接器或者任务暂停、停止、删除,且没有运行异常,(也就是连接器和任务处于RUNNING状态),等服务器可以正常访问后,之前处于RUNNING状态的连接器和任务都会恢复运行,接着之前的任务进度继续执行。
之所以kafka connect能够做到如此程度,我认为是因为集群模式下,kafka connect将连接器的配置、偏移量、状态和主题等关键信息存到了kafka当中。
具体探究如下:
首先,切换到kafka所在的目录下。
查询kafka服务器中存储的所有主题信息
bin/kafka-topics.sh --list --bootstrap-server localhost:9092 bin/kafka-topics.bat --list --bootstrap-server localhost:9092
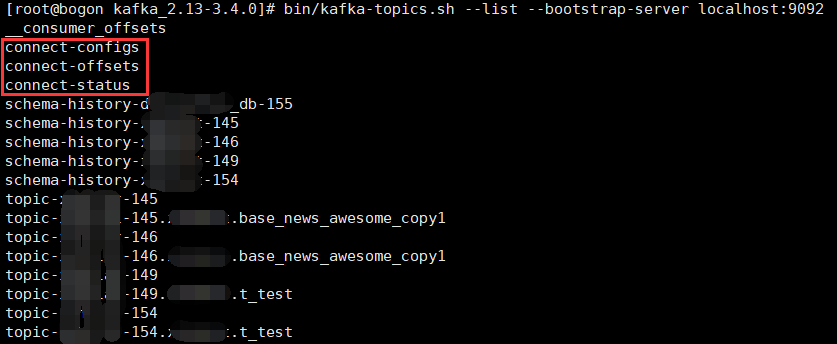
从上图当中,我们可以看到:
连接器的配置信息被存到了connect-configs。

Source连接器的偏移量信息被存到了connect-offsets(数据生产者)。

Sink连接器的偏移量信息被存到了__consumer_offsets(数据消费者)。
连接器的运行状态信息被存到了connect-status。

查看主题connect-offsets存储的内容
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-offsets --from-beginning
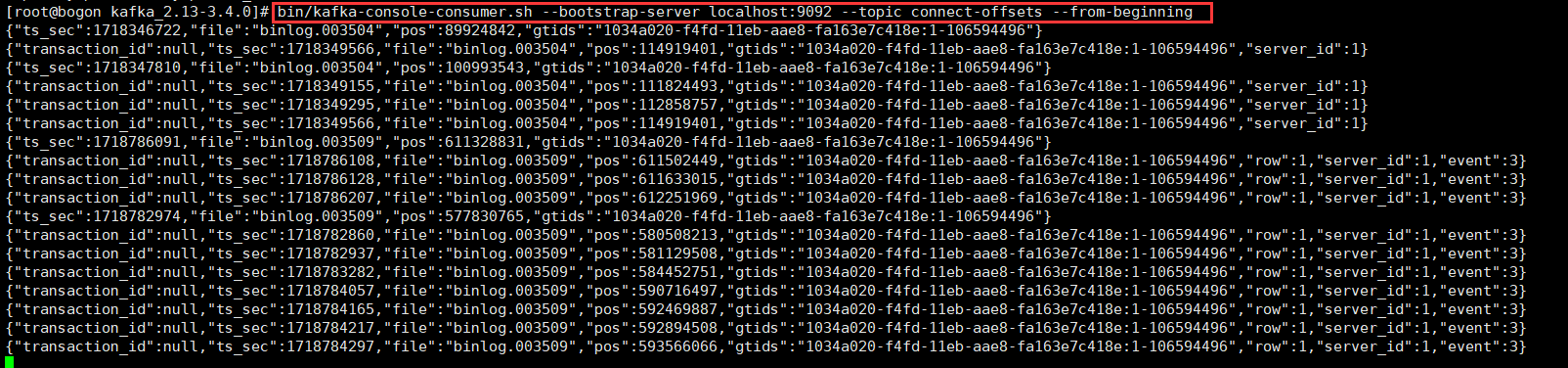
从上图我们可以看到:
连接器的偏移量信息(读取数据库日志的进度),但是不知道它是如何与连接器完成关系映射的。
查看主题connect-status存储的信息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-status --from-beginning
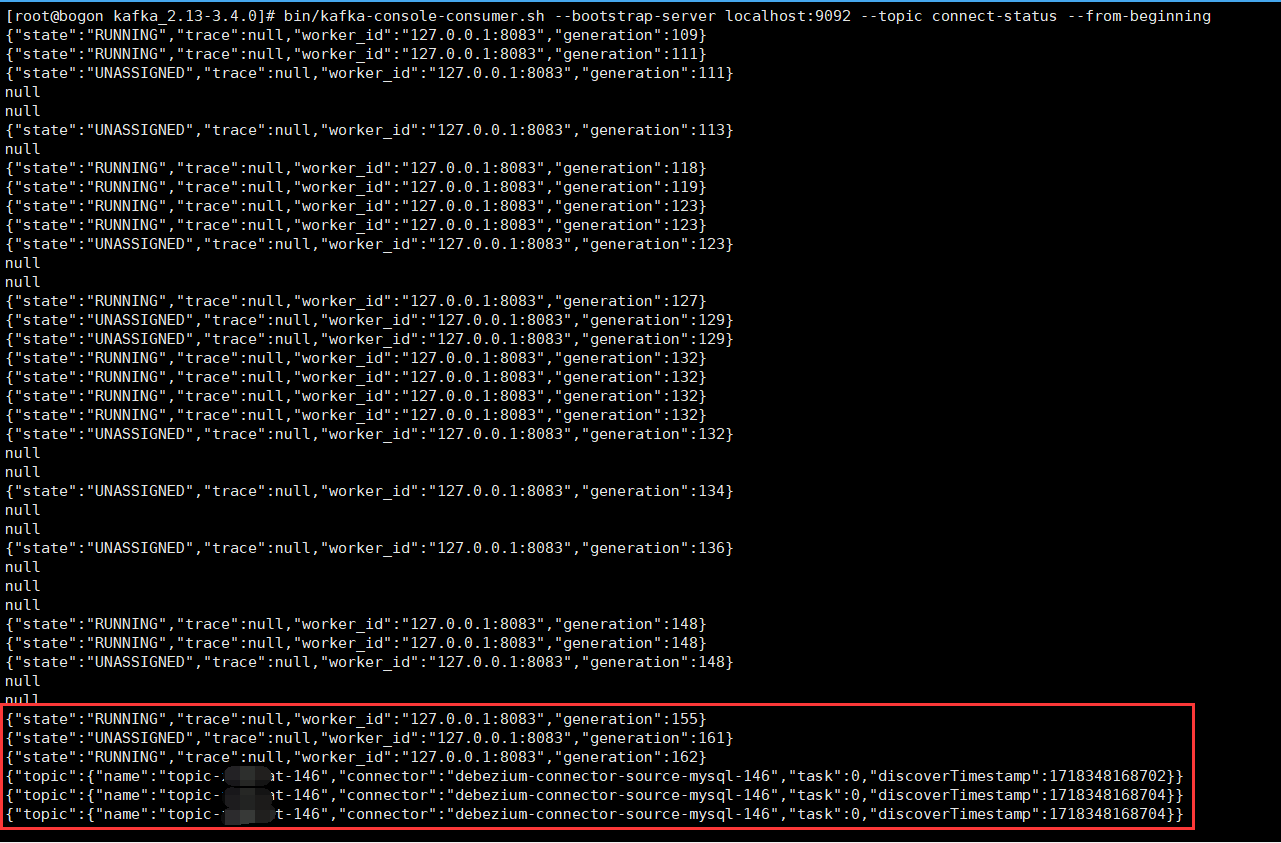
查看主题connect-config存储的信息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-configs --from-beginning
不仅存储了连接器的配置信息,还存了其它东西。

2024-06-25 11:32:08
另外,如果Source Connector没有产生数据,日志内容将会持续输出以下内容:
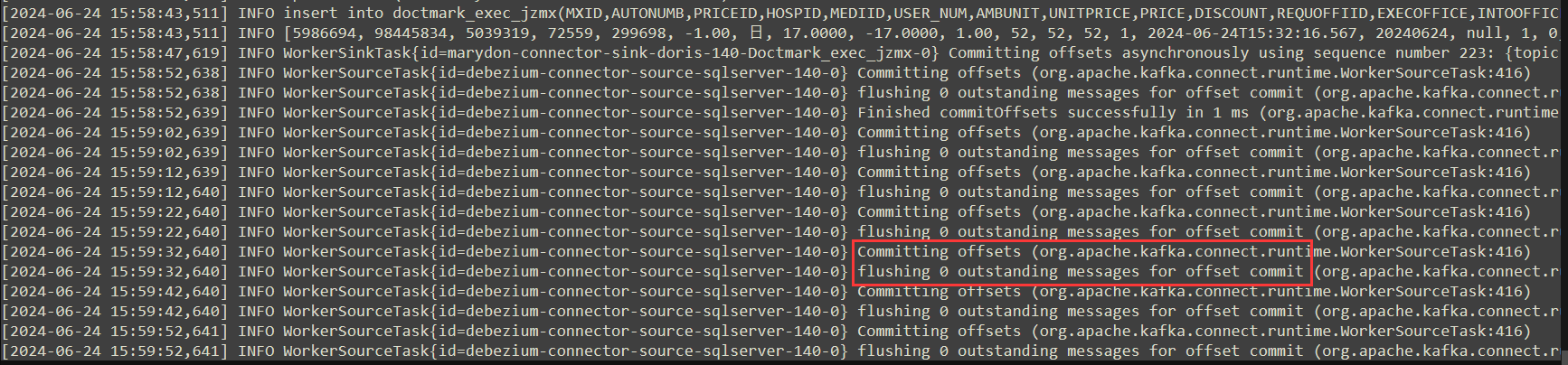
之所以这样,是因为Source Connector一直在监听数据库指定表的日志,如果源表数据有变化,就会将变化内容推送到kafka对应的主题当中,并提交Source Connector当前的偏移量;
如果没有,就会输出类似这样的内容。
2024-06-27 16:17:34
关于连接器任务的说明(connector task)
kafka connector的任务其实是定时任务,默认设置的是每10秒执行一次(不论是Source Connector还是Sink Connector都是10秒执行一次)。
对应config/connect-distributed.properties文件中的offset.flush.interval.ms。

offset.flush.interval.ms属性说明

Task.java类运行的核心是调用put()方法,也就是说:这个方法会被每10秒调用一次。
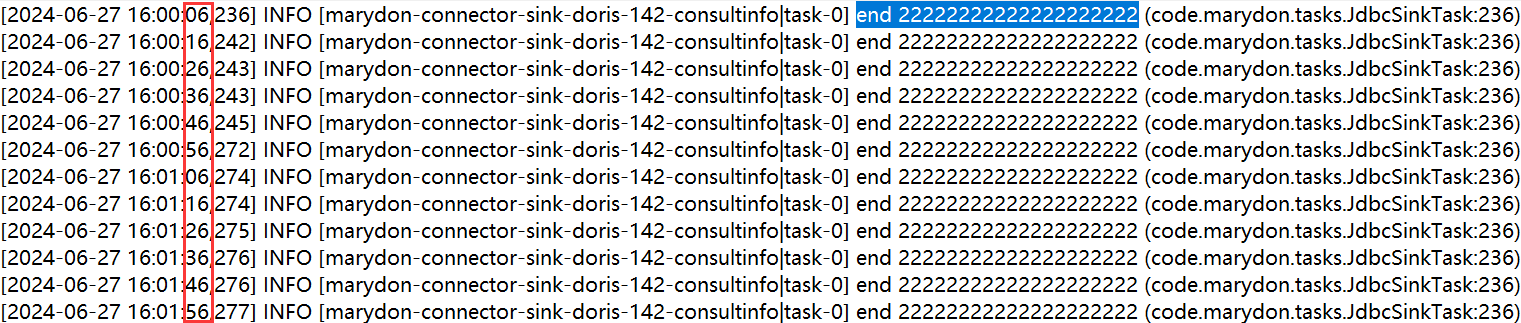
2024-07-01 18:15:26
如果连接器正在运行时,任务执行失败(报错),任务的状态会变成FAILED。

如果是由于自己封装的代码有问题,当我们关掉kafka connect后,改好代码打成并更新后,启动kafka connect,会自动变成RUNNING状态。
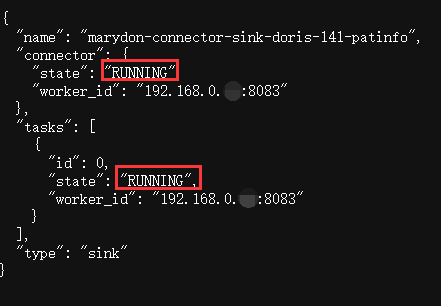
2024-07-05 17:03:37
关于Sink Connector的tasks.max参数说明
在创建Sink Connector的时候,设置tasks.max=10,以期望启动任务并行处理数据,来加快消费进度。

Sink Connector启动成功后,也确确实实启动了10个任务,如上图所示。
但是,经观测日志发现:只有一个任务在处理数据,而其它任务却不工作,这是为什么?

原来,这个参数虽然管控这支持多少个任务同时运行,但是,它还受到Sink Connector所订阅的主题分区限制。
主题有几个分区,就支持同时运行几个任务来并行处理数据,但是,每个分区最多只能有一个任务来消费数据。
实际上,使用source Connector默认产生的主题是没有分区概念的,即:kafka_partition=0。
所以说,即使Sink Connector设定了N个task,但实际上有且只有一个来消费数据。

关于connector和task的状态说明
- UNASSIGNED: The connector/task has not yet been assigned to a worker.
- RUNNING: The connector/task is running.
- PAUSED: The connector/task has been administratively paused.
- STOPPED: The connector has been stopped. Note that this state is not applicable to tasks because the tasks for a stopped connector are shut down and won't be visible in the status API.
- FAILED: The connector/task has failed (usually by raising an exception, which is reported in the status output).
- RESTARTING: The connector/task is either actively restarting or is expected to restart soon
2024-07-31 14:46:15
如果多个连接器的任务,在运行过程中,都执行失败了

如果一个个的调用任务对应的restart接口进行重启的话,会麻烦。
最简单的方法就是重启kafka connect服务。
具体操作就是:
先停掉kafka connect,然后再启动。
这样一来,所有的连接器和连接器里面对应的任务都会重新启动(不管之前处于何种状态)。
同样地,当kafka服务器意外停止后,kafka connect服务对应的连接器都变成了UNASSIGNED。

如果连接器很多的话,最便捷的方式就是重启kafka connect。
2024-08-26 10:29:17
关于偏移量的说明
以消费者为例。
2024-08-28 16:22:25
关于日志的说明
kafka日志使用的是org.slf4j.Logger。
如果是自定义开发的Source或者Sink connector组件,想要将出现的异常信息输出到指定文件,这是可以实现的。
具体操作步骤如下:
第一步:定义一个日志类。
import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * 错误日志输出 * @author Marydon * @version 1.0 * @description * @date 2024-08-01 * @email marydon20170307@163.com */ public class LogWriterUtils { // private final Logger log = LoggerFactory.getLogger(this.getClass()); private static final Logger LOG = LoggerFactory.getLogger(LogWriterUtils.class); /** * 错误信息输出 * @attention * @date 2024-08-07 15:49 * @param errorMessage 错误信息 */ public static void error(String errorMessage) { LOG.error(errorMessage); } /** * 异常输出 * @attention * @date 2024-08-08 14:48 * @param errorMessage 异常信息 * @param throwable 异常对象 */ public static void errorWithException(String errorMessage, Throwable throwable) { LOG.error(errorMessage, throwable); } }
第二步:修改KAFKA_HOME/config/connect-log4j.properties文件。
kafka connect服务的运行日志被配置在了connect-log4j.properties文件当中。
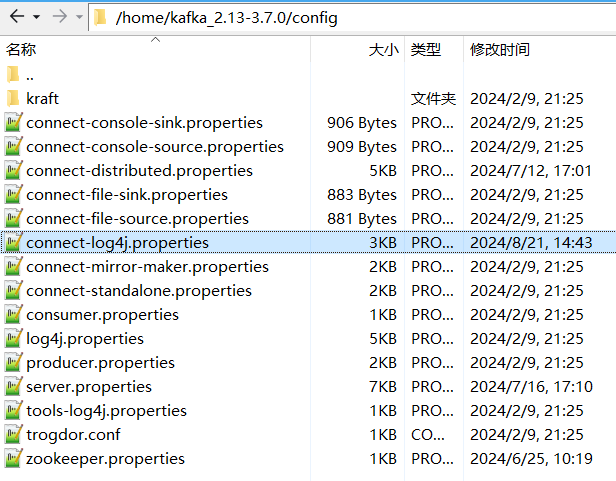
connect-log4j.properties文件内容为:
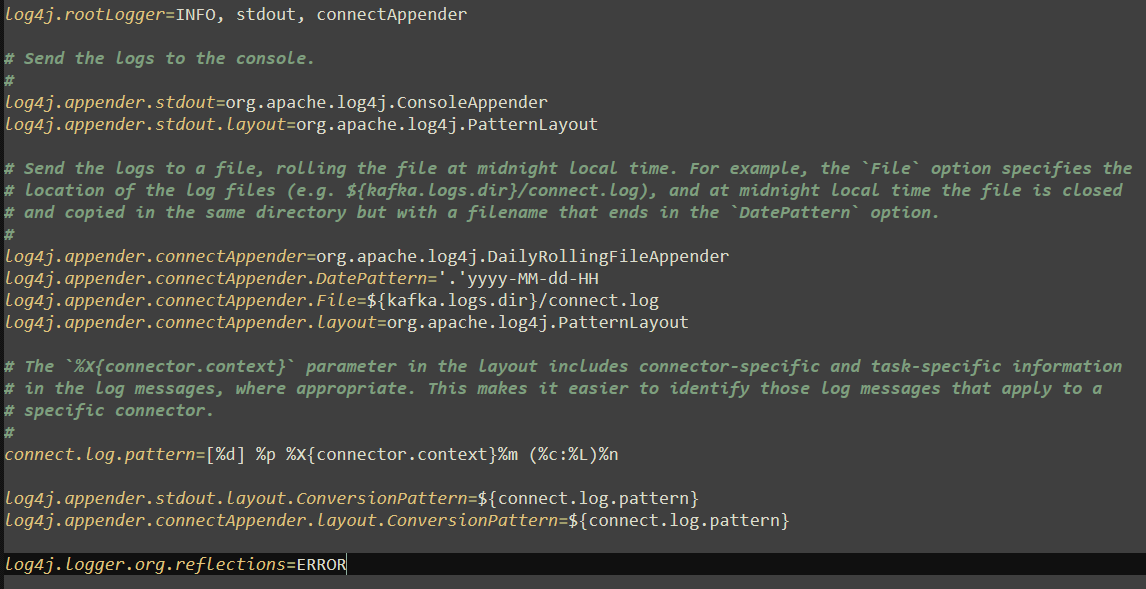
往文件底部添加以下内容:
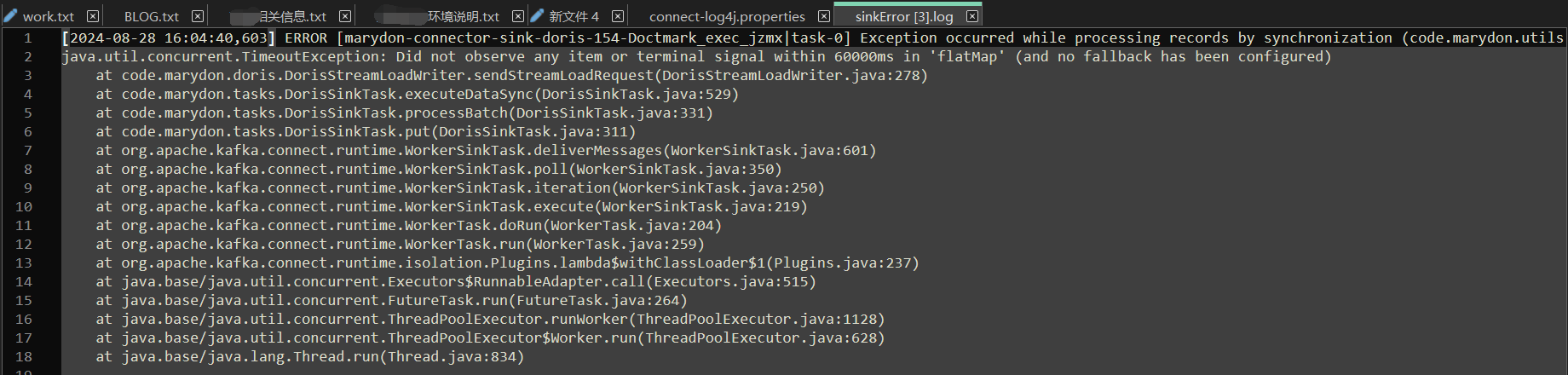
#2024-08-02 09:19:09 #LogWriterUtils.java产生的ERROR级别日志将分别输出在sinkError.log和connect.log中 log4j.logger.code.marydon.utils.LogWriterUtils=ERROR, sinkErrorAppender, connectAppender #防止日志信息被父logger继承并再次记录,这有助于避免日志信息的重复 log4j.additivity.code.marydon.utils.LogWriterUtils=false log4j.appender.sinkErrorAppender=org.apache.log4j.DailyRollingFileAppender log4j.appender.sinkErrorAppender.DatePattern='.'yyyy-MM-dd #后续查看日志文件logs/sinkError.log,就能知道数据写入失败的原因 log4j.appender.sinkErrorAppender.File=${kafka.logs.dir}/sinkError.log log4j.appender.sinkErrorAppender.layout=org.apache.log4j.PatternLayout log4j.appender.sinkErrorAppender.layout.ConversionPattern=${connect.log.pattern}
在需要调用的地方调用,然后,错误日志将会输出到指定文件中。
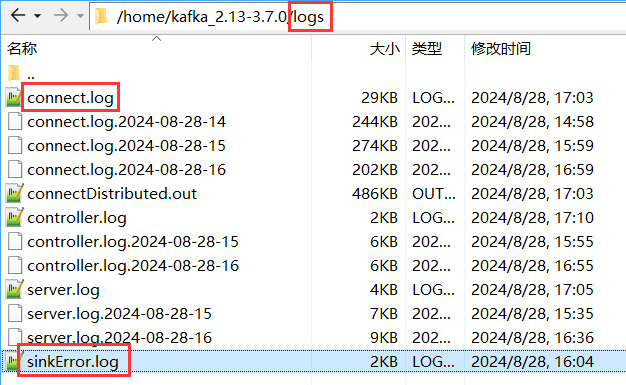
connect.log
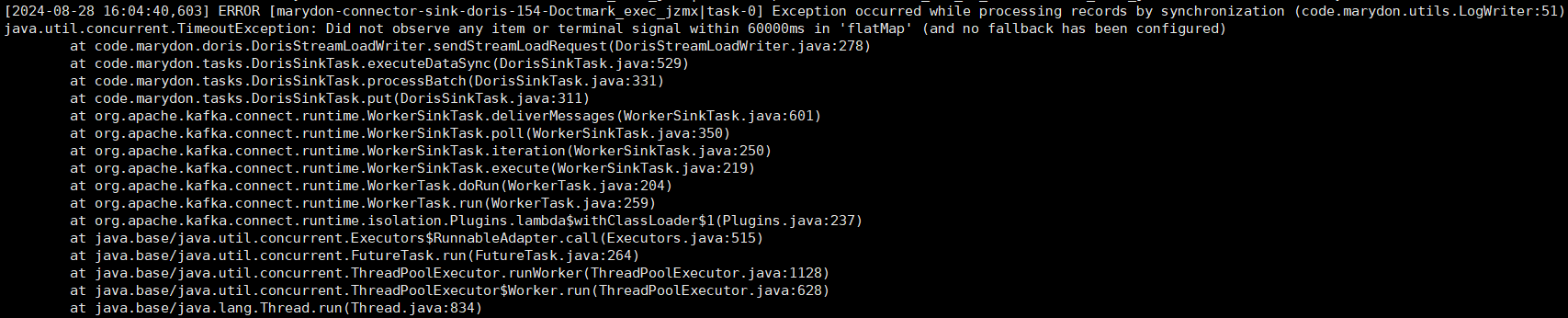
sinkError.log
如果不想日志输出到connect.log中,使用下面这行代码即可。
#LogWriterUtils.java产生的ERROR级别日志将分别输出在sinkError.log log4j.logger.code.marydon.utils.LogWriterUtils=ERROR, sinkErrorAppender
与君共勉:最实用的自律是攒钱,最养眼的自律是健身,最健康的自律是早睡,最改变气质的自律是看书,最好的自律是经济独立 。
您的一个点赞,一句留言,一次打赏,就是博主创作的动力源泉!
↓↓↓↓↓↓写的不错,对你有帮助?赏博主一口饭吧↓↓↓↓↓↓
本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/17943289



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· 地球OL攻略 —— 某应届生求职总结
2018-01-03 potplayer 网页调用potplayer播放本地视频