PageHelper用法示例(mybatis分页查询插件) 2025760编辑
Heaven helps those who help themselves
资深码农+深耕理财=财富自由
欢迎关注
资深码农+深耕理财=财富自由
欢迎关注
PageHelper用法示例(mybatis分页查询插件)
Created by Marydon on 2023-10-08 10:54
1.情景展示
在实际开发过程中,分页查询是最常见,也是使用频率最高的数据查询。
分页查询,如果我们进行手动在xml当中写SQL的话,起码要写两个SQL。一个是分页,一个是查询数据总数。
问题在于:这样做,会提高我们的工作量,而且这些也是很繁琐的过程。
能不能让我们只关注查询业务(查询SQL),而不用管理分页,让这部分代码进行自动化呢?
2.具体分析
我们可以通过PageHelper来解决这个问题。
pagehelper是mybatis的一个插件,其作用是更加方便地进行分页查询。

3.解决方案
准备工作
如果是springboot项目,需要引入以下jar包。
<!-- 分页插件 --> <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper-spring-boot-starter</artifactId> <version>1.4.1</version> </dependency>
非springboot项目,引入下面jar包。
<dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper</artifactId> <version>5.0.0</version> </dependency>
并需:添加以下信息到xml当中
<plugins> <plugin interceptor="com.github.pagehelper.PageInterceptor"></plugin> </plugins>
说明:在实际引入的时候,可以将插件版本号改成最新的。
启用PageHelper插件
#pagehelper分页插件配置 pagehelper: #默认值:mysql #helperDialect: mysql reasonable: true supportMethodsArguments: true params: count=countSql auto-dialect: true #根据运行数据库url自动分页 autoRuntimeDialect: true
Mapper.xml(mybatis+mysql)
<resultMap id="PipelineResultMap" type="com.xyhsoft.mi.link.api.domain.FlinkDataPipeline"> <id property="pipelineid" column="PIPELINEID" jdbcType="BIGINT"/> <result property="pipelinename" column="PIPELINENAME" jdbcType="VARCHAR"/> <result property="databaseidSource" column="DATABASEID_SOURCE" jdbcType="BIGINT"/> <result property="readtype" column="READTYPE" jdbcType="VARCHAR"/> <result property="synctype" column="SYNCTYPE" jdbcType="VARCHAR"/> <result property="synctable" column="SYNCTABLE" jdbcType="VARCHAR"/> <result property="databaseidTarget" column="DATABASEID_TARGET" jdbcType="BIGINT"/> <result property="databasnameTarget" column="DATABASNAME_TARGET" jdbcType="VARCHAR"/> <result property="dataDelete" column="DATA_DELETE" jdbcType="VARCHAR"/> <result property="syncTimestamp" column="SYNC_TIMESTAMP" jdbcType="VARCHAR"/> <result property="syncTableupdate" column="SYNC_TABLEUPDATE" jdbcType="VARCHAR"/> <result property="dirtyDatanum" column="DIRTY_DATANUM" jdbcType="BIGINT"/> <result property="failTry" column="FAIL_TRY" jdbcType="VARCHAR"/> <result property="resuleNote" column="RESULE_NOTE" jdbcType="VARCHAR"/> <result property="status" column="STATUS" jdbcType="VARCHAR"/> <result property="createtime" column="CREATETIME" jdbcType="TIMESTAMP"/> <result property="databasenameSource" column="DATABASENAME" jdbcType="VARCHAR"/> </resultMap> <sql id="FlinkDataPipeline_Column_List"> t1.PIPELINEID,t1.PIPELINENAME,t1.DATABASEID_SOURCE, t1.READTYPE,t1.SYNCTYPE,t1.SYNCTABLE, t1.DATABASEID_TARGET,t1.DATABASNAME_TARGET,t1.DATA_DELETE, t1.SYNC_TIMESTAMP,t1.SYNC_TABLEUPDATE,t1.DIRTY_DATANUM, t1.FAIL_TRY,t1.RESULE_NOTE,t1.STATUS, t1.CREATETIME </sql>
说明:为了保持代码的完整性,才展示了上述代码。
在此,我们只需关注下面的select标签内容即可。
<select id="getFlinkDataPipeline" parameterType="com.mysoft.mi.link.api.vo.FlinkDataPipelineVo" resultMap="PipelineResultMap"> select <include refid="FlinkDataPipeline_Column_List"></include>, t2.DATABASENAME from flink_data_pipeline t1, flink_database t2 where t2.DATABASEID = t1.DATABASEID_SOURCE <if test="pipelineid != null and pipelineid != ''"> and t1.pipelineid = #{pipelineid} </if> <if test="pipelinename != null and pipelinename != ''"> and t1.pipelinename like concat('%', #{pipelinename}, '%') </if> order by t1.CREATETIME desc </select>
这就是一个普通的两表关联查询语句。
Mapper层(Dao层)
List<FlinkDataPipeline> getFlinkDataPipeline(FlinkDataPipelineVo pipelineVo);
说明:方法名必须和select标签的id值保持一致。
业务层(Bo层)
@Override public PageList<FlinkDataPipeline> getPageList(FlinkDataPipelineVo pipelineVo) { // 进行分页 // PageHelper.startPage(null == pipelineVo.getPageIndex() ? 1 : pipelineVo.getPageIndex(), null == pipelineVo.getPageSize() ? 15 : pipelineVo.getPageSize()); PageHelper.startPage(pipelineVo.getPageIndex(), pipelineVo.getPageSize()); // 注意:只有紧跟着PageHelper.startPage(pageNum,pageSize)的sql语句才被pagehelper起作用 List<FlinkDataPipeline> metaDatabaseList = pipelineMapper.getFlinkDataPipeline(pipelineVo); PageInfo<FlinkDataPipeline> pageInfo = new PageInfo<>(metaDatabaseList); return new PageList<>(pageInfo.getTotal(), pageInfo.getList()); }
说明:这一块是核心代码。
第一步:确定分页内容(第几页,每页大小)。
PageHelper.startPage(null == pipelineVo.getPageIndex() ? 1 : pipelineVo.getPageIndex(), null == pipelineVo.getPageSize() ? 15 : pipelineVo.getPageSize());
第二步:通过Mapper接口调用查询语句。
List<FlinkDataPipeline> metaDatabaseList = pipelineMapper.getFlinkDataPipeline(pipelineVo);
注意:需要分页的查询语句必须紧跟第一步的分页代码,另外,第一步和第二步顺序不能颠倒。
否则,该查询语句将不会进行分页,查询的将是所有数据。
第三步:将返回的List塞到PageInfo对象当中。
PageInfo<FlinkDataPipeline> pageInfo = new PageInfo<>(metaDatabaseList);
第四步:拿到分页后的数据或者塞到PageList对象当中。
pageInfo.getList();
或者
return new PageList<>(pageInfo.getTotal(), pageInfo.getList());
控制层(Controller层)
@ApiOperation(value = "分页查询管道列表", notes = "分页查询管道列表", httpMethod = "GET") @GetMapping(value = "/getPipelineList", produces = {"application/json;charset=UTF-8"}) public PageList<FlinkDataPipeline> getPipelineList(@ApiParam(value = "管道名称", required = false, example = "管道1") @RequestParam(required = false) String pipelinename, @ApiParam(value = "第几页", required = false, example = "1") @Pattern(regexp = "^$|^[1-9]\\d*$", message = "pageIndex可为空或正整数") @RequestParam(required = false) String pageIndex, @Pattern(regexp = "^$|^[1-9]\\d*$", message = "pageIndex可为空或正整数") @ApiParam(value = "每页展示几条", required = false, example = "15") @RequestParam(required = false) String pageSize){ FlinkDataPipelineVo pipelineVo = FlinkDataPipelineVo.builder().build() .setPipelinename(pipelinename) .setPageIndex(null == pageIndex ? 1 : Integer.parseInt(pageIndex)) //默认1 .setPageSize(null == pageSize ? 15 : Integer.parseInt(pageSize)) //默认15 ; return pipelineService.getPageList(pipelineVo); }
效果展示
mysql分页展示
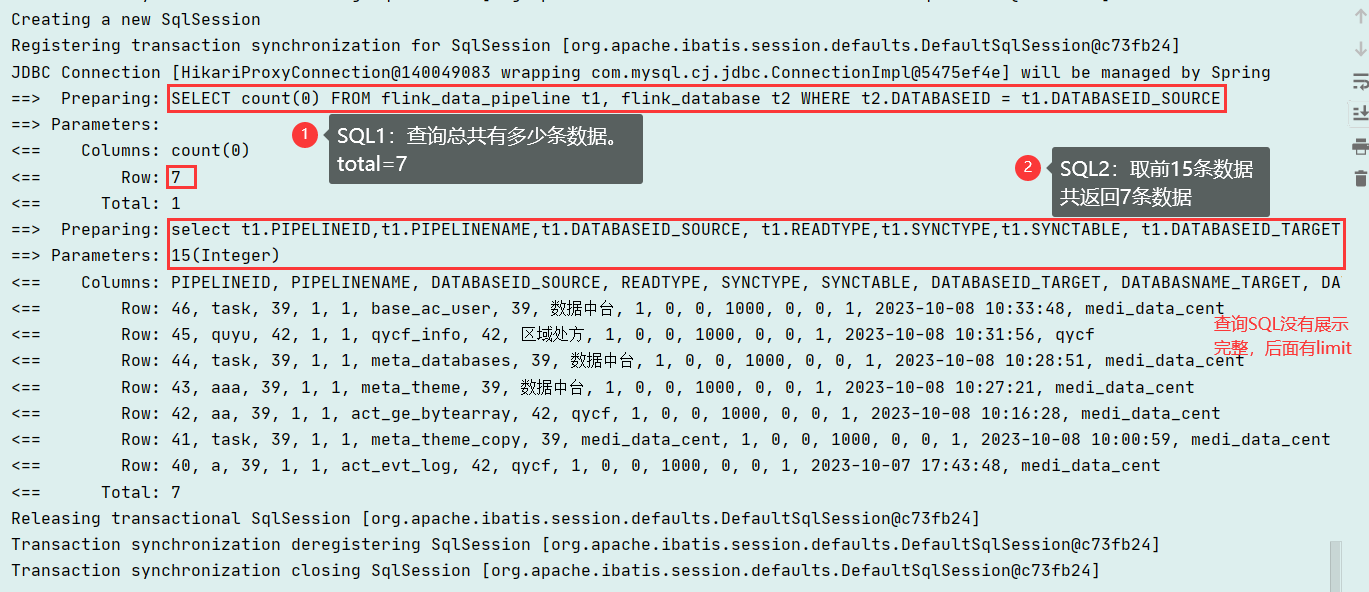
控制台输出
查看代码
Creating a new SqlSession Registering transaction synchronization for SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@c73fb24] JDBC Connection [HikariProxyConnection@140049083 wrapping com.mysql.cj.jdbc.ConnectionImpl@5475ef4e] will be managed by Spring ==> Preparing: SELECT count(0) FROM flink_data_pipeline t1, flink_database t2 WHERE t2.DATABASEID = t1.DATABASEID_SOURCE ==> Parameters: <== Columns: count(0) <== Row: 7 <== Total: 1 ==> Preparing: select t1.PIPELINEID,t1.PIPELINENAME,t1.DATABASEID_SOURCE, t1.READTYPE,t1.SYNCTYPE,t1.SYNCTABLE, t1.DATABASEID_TARGET,t1.DATABASNAME_TARGET,t1.DATA_DELETE, t1.SYNC_TIMESTAMP,t1.SYNC_TABLEUPDATE,t1.DIRTY_DATANUM, t1.FAIL_TRY,t1.RESULE_NOTE,t1.STATUS, t1.CREATETIME , t2.DATABASENAME from flink_data_pipeline t1, flink_database t2 where t2.DATABASEID = t1.DATABASEID_SOURCE order by t1.CREATETIME desc LIMIT ? ==> Parameters: 15(Integer) <== Columns: PIPELINEID, PIPELINENAME, DATABASEID_SOURCE, READTYPE, SYNCTYPE, SYNCTABLE, DATABASEID_TARGET, DATABASNAME_TARGET, DATA_DELETE, SYNC_TIMESTAMP, SYNC_TABLEUPDATE, DIRTY_DATANUM, FAIL_TRY, RESULE_NOTE, STATUS, CREATETIME, DATABASENAME <== Row: 46, task, 39, 1, 1, base_ac_user, 39, 数据中台, 1, 0, 0, 1000, 0, 0, 1, 2023-10-08 10:33:48, medi_data_cent <== Row: 45, quyu, 42, 1, 1, qycf_info, 42, 区域处方, 1, 0, 0, 1000, 0, 0, 1, 2023-10-08 10:31:56, qycf <== Row: 44, task, 39, 1, 1, meta_databases, 39, 数据中台, 1, 0, 0, 1000, 0, 0, 1, 2023-10-08 10:28:51, medi_data_cent <== Row: 43, aaa, 39, 1, 1, meta_theme, 39, 数据中台, 1, 0, 0, 1000, 0, 0, 1, 2023-10-08 10:27:21, medi_data_cent <== Row: 42, aa, 39, 1, 1, act_ge_bytearray, 42, qycf, 1, 0, 0, 1000, 0, 0, 1, 2023-10-08 10:16:28, medi_data_cent <== Row: 41, task, 39, 1, 1, meta_theme_copy, 39, medi_data_cent, 1, 0, 0, 1000, 0, 0, 1, 2023-10-08 10:00:59, medi_data_cent <== Row: 40, a, 39, 1, 1, act_evt_log, 42, qycf, 1, 0, 0, 1000, 0, 0, 1, 2023-10-07 17:43:48, medi_data_cent <== Total: 7 Releasing transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@c73fb24] Transaction synchronization deregistering SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@c73fb24] Transaction synchronization closing SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@c73fb24]
最终返回的PageList的数据格式,示例:
{ "total": 7, "list": [ { "pipelineid": 46, "pipelinename": "task", "databaseidSource": 39, "readtype": "1", "synctype": "1", "synctable": "base_ac_user", "databaseidTarget": 39, "databasnameTarget": "数据中台", "dataDelete": "1", "syncTimestamp": "0", "syncTableupdate": "0", "dirtyDatanum": 1000, "failTry": "0", "resuleNote": "0", "status": "1", "createtime": 1696732428000, "databasenameSource": "medi_data_cent" }, { "pipelineid": 45, "pipelinename": "quyu", "databaseidSource": 42, "readtype": "1", "synctype": "1", "synctable": "qycf_info", "databaseidTarget": 42, "databasnameTarget": "区域处方", "dataDelete": "1", "syncTimestamp": "0", "syncTableupdate": "0", "dirtyDatanum": 1000, "failTry": "0", "resuleNote": "0", "status": "1", "createtime": 1696732316000, "databasenameSource": "qycf" } ] }
2024-08-15 15:25:10
oracle分页展示

pagehelper插件所生成的分页sql示例:
SELECT * FROM (SELECT TMP_PAGE.*, ROWNUM PAGEHELPER_ROW_ID FROM (SELECT TYPE_CODE, TYPE_NAME, TYPE_VALUE, TYPE_CONTENT, TYPE, TYPE_REC, TYPE_BM, TYPE_COMING FROM BASEDICT T1 ORDER BY T1.TYPE_CODE, T1.TYPE_VALUE) TMP_PAGE) WHERE PAGEHELPER_ROW_ID <= ? AND PAGEHELPER_ROW_ID > ?
2024-08-30 09:14:23
4.补充说明
经过上面,我们知道pageHelper插件针对需要分页的地方会根据不同的数据库采取不同的分页方式。
mysql:会给要执行的sql后面添加limit进行分页。
mysql sql limit ? ,?
需要注意的是:
在MySQL中,在xml文件的<select>标签中的使用的是union all,如果使用pagehelper插件进行分页查询的话,需要在最外层包裹一层select才行。
原先的sql
select name from table1 order by id union all select name from table2 order by id
在最外层包裹一层select,执行的分页将为:
select t.* from ( select name from table1 order by id union all select name from table2 order by id ) t limit ?, ?
如果没有在最外层包裹一层select,执行的分页将为:
select name from table1 order by id union all select name from table2 order by id limit ?, ?
这个显然不是我们想要的效果。
oracle:在执行的sql外面增加两层select。
SELECT * FROM (SELECT TMP_PAGE.*, ROWNUM PAGEHELPER_ROW_ID FROM (OARCLE SQL) TMP_PAGE) WHERE PAGEHELPER_ROW_ID <= ? AND PAGEHELPER_ROW_ID > ?
与君共勉:最实用的自律是攒钱,最养眼的自律是健身,最健康的自律是早睡,最改变气质的自律是看书,最好的自律是经济独立 。
您的一个点赞,一句留言,一次打赏,就是博主创作的动力源泉!
↓↓↓↓↓↓写的不错,对你有帮助?赏博主一口饭吧↓↓↓↓↓↓
本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/17748387.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
2019-10-08 win10 将任意文件固定到开始屏幕(最佳办法)