mybatis 批量插入的两种实现方式
1.情景展示
在实际开发过程中,我们有时候会遇到前端批量提交的数据。
诚然,如果我们使用for循环一次一次插入,也是可以的。
但这会涉及到对数据库频繁操作的问题,有没有更好的办法呢?
2.具体分析
我们可以通过mybatis的批量插入功能来解决这个问题。
只需要操作一次数据库,就能完成多条数据的插入操作。
3.解决方案
第一种实现方式
XML
<!--批量插入-->
<insert id="addFlinkDataFieldBatch" parameterType="java.util.List">
insert into flink_data_field
(pipelineid, DATABASEID_SOURCE, TABLENAME_SOURCE, FIELDNAME_SOURCE, status, createtime, TABLESTATUS_TARGET)
values
<foreach collection="fieldList" separator="," item="row">
(
#{row.pipelineid},#{row.databaseidSource},#{row.tablenameSource},#{row.fieldnameSource}, #{row.status} ,now(), #{row.tablestatusTarget}
)
</foreach>
</insert>说明:
这里是mysql数据库,表主键使用的是自增属性,所以插入的时候,可以不用管主键列。
实际在执行的时候,输出的SQL结构为:
insert into flink_data_field
(pipelineid, DATABASEID_SOURCE, TABLENAME_SOURCE, FIELDNAME_SOURCE, status, createtime, TABLESTATUS_TARGET)
values
(?,?,?,?,?,当前时间,?),(?,?,?,?,?,当前时间,?),(?,?,?,?,?,当前时间,?), ...映射层(dao层、mapper层)
Boolean addFlinkDataFieldBatch(List<FlinkDataField> fieldList);说明:
插入成功,返回:true;插入失败,返回:false。
方法入参的参数名称:fileldList,与foreach标签的collection的属性值相对应。
如果不对应的话,也可以,只不过,需要我们使用注解@Param。
Boolean addFlinkDataFieldBatch(@Param("fieldList") List<FlinkDataField> list);说明:
当方法入参的参数名称与foreach标签的collection的属性值不一致时,我们有两种解决办法。
第1种:修改方法入参的参数名称,使其与foreach标签的collection的属性值保持一致。
第2种:在方法入参的变量类型前面增加@Param注解,使该注解的值与foreach标签的collection的属性值保持一致。
业务层(Bo层)
/**
* 插入管道信息及字段映射信息
* @param pipelineFieldVo
* @return
*/
@Override
public Boolean addPipelineAndField(PipelineFieldVo pipelineFieldVo) {
// 获取管道信息
FlinkDataPipeline pipeline = pipelineFieldVo.getPipeline();
if (null == pipeline) {
// 抛出运行时异常,触发提交事务进行回滚
throw new RuntimeException("管道信息不能为空");
}
// 插入flink_data_pipeline表
Boolean isSuccess = pipelineMapper.addFlinkDataPipeline(pipeline);
// 获取插入的管道主键
Long pipelineid = pipeline.getPipelineid();
if (!isSuccess || pipelineid == null) {// 插入失败
throw new RuntimeException("管道信息保存失败");
}
// 获取表信息
List<TableVo> tables = pipelineFieldVo.getTables();
if (null == tables || tables.isEmpty()) {
throw new IllegalArgumentException("保存失败:字段映射不能为空");
}
List<FlinkDataField> fieldList = new ArrayList<>();
// 遍历取出每个table里面包含的字段映射信息
tables.forEach(tableVo -> {
ColumnVo columnVo = tableVo.getTable();
if (null == columnVo) {
throw new IllegalArgumentException("保存失败:字段映射不能为空");
}
List<FlinkDataFieldVo> columns = columnVo.getColumns();
if (null == columns || columns.isEmpty()) {
throw new IllegalArgumentException("保存失败:字段映射不能为空");
}
columns.forEach(flinkDataFieldVo -> {
FlinkDataField flinkDataField = FlinkDataField.builder().build();
flinkDataField.setPipelineid(pipelineid)// 管道主键
.setDatabaseidSource(columnVo.getDatabaseidSource())
.setDatabaseidTarget(columnVo.getDatabaseidTarget())
.setTablenameSource(columnVo.getTablenameSource())
.setTablenameTarget(columnVo.getTablenameTarget())
.setTablestatusTarget(columnVo.getTablestatusTarget())
;
flinkDataField.setFieldnameSource(flinkDataFieldVo.getFieldnameSource())
.setFieldtypeSource(flinkDataFieldVo.getFieldtypeSource())
.setFieldisnullSource(flinkDataFieldVo.getFieldisnullSource())
.setFieldiskeySource(flinkDataFieldVo.getFieldiskeySource())
.setFieldnameTarget(flinkDataFieldVo.getFieldnameTarget())
.setFieldtypeTarget(flinkDataFieldVo.getFieldtypeTarget())
.setFieldisnullTarget(flinkDataFieldVo.getFieldisnullTarget())
.setFieldiskeyTarget(flinkDataFieldVo.getFieldiskeyTarget())
.setStatus(flinkDataFieldVo.getStatus())
;
// 将表的字段映射关系放到List当中
fieldList.add(flinkDataField);
});
});
return flinkDataFieldMapper.addFlinkDataFieldBatch(fieldList);
}控制层(Controller层)
@ApiOperation(value = "添加管道信息", notes = "添加管道信息", httpMethod = "POST")
@PostMapping(value = "/add", produces = {"application/json;charset=UTF-8"})
public Boolean addPipelineAndField(@RequestBody @Valid PipelineFieldVo pipelineFieldVo){
return pipelineService.addPipelineAndField(pipelineFieldVo);
}4.补充说明
第一种方式的弊端:
当表的列数较多(20+),以及一次性插入的行数较多(5000+)时,整个插入的耗时十分漫长。
从资料中可知,默认执行器类型为Simple,会为每个语句创建一个新的预处理语句,也就是创建一个PreparedStatement对象。在我们的项目中,会不停地使用批量插入这个方法,而因为MyBatis对于含有<foreach>的语句,无法采用缓存,那么在每次调用方法时,都会重新解析sql语句。
耗时就耗在,由于我foreach后有5000+个values,所以这个PreparedStatement特别长,包含了很多占位符,对于占位符和参数的映射尤其耗时。并且,查阅相关资料可知,values的增长与所需的解析时间,是呈指数型增长的。
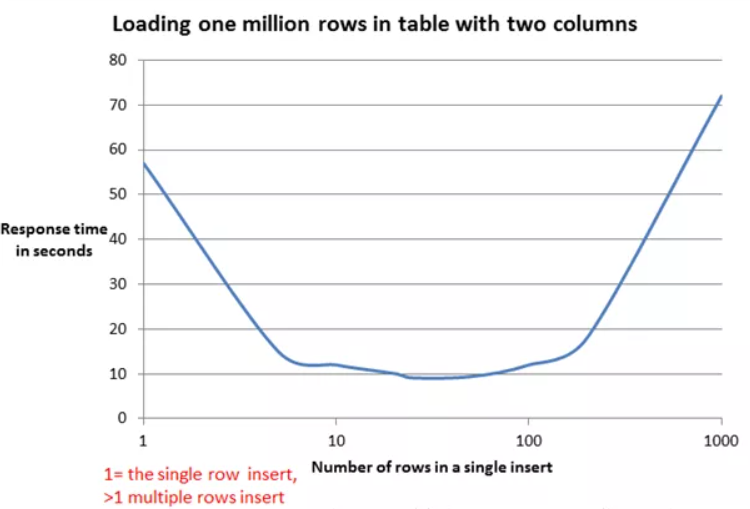
所以,如果非要使用 foreach 的方式来进行批量插入的话,可以考虑减少一条 insert 语句中 values 的个数,最好能达到上面曲线的最底部的值,使速度最快。
一般按经验来说,一次性插20~50行数量是比较合适的,时间消耗也能接受。
另一种折中的办法是:
如果要插入的总行数在100行以内的话,使用这种方式是没有问题的。
实在不行,我们还可以按100行进行拆分成N次,进行批量插入。
2024年4月25日10:41:50
第二种实现方式(推荐使用)
实际上,mybatis官方推荐的是:使用了 ExecutorType.BATCH 的插入方式。
以springboot项目为例
#配置 MyBatis 批处理
mybatis:
configuration:
default-executor-type: batch其余的,与第一种实现方式一致。
说明:这种方式的执行结果(返回的影响行数)有可能是负数。
本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/17747109.html

