Oracle、Mysql 分页查询
1.情景展示
在实际开发过程中,分页查询是最常使用的,只要存在表格查询,就会存在分页查询;
分页的好处在于:减少查询的数据量,不会给前端、后台服务器、数据库造成压力,减少用户等待时间。
2.Oracle分页
如果仅仅是SQL,不涉及前后端交互的话,分页查询是这样子的:

显然,这种查询,对于我们来说,基本上没有意义,它往往蕴含着前后端交互:
由前端来决定要分页大小PageSize,分页的当前页PageIndex;
后台根据PageIndex和PageSize计算出开始页Start和结束页End。
前端:传当前页数和每页的大小

java:计算起始数和结束数
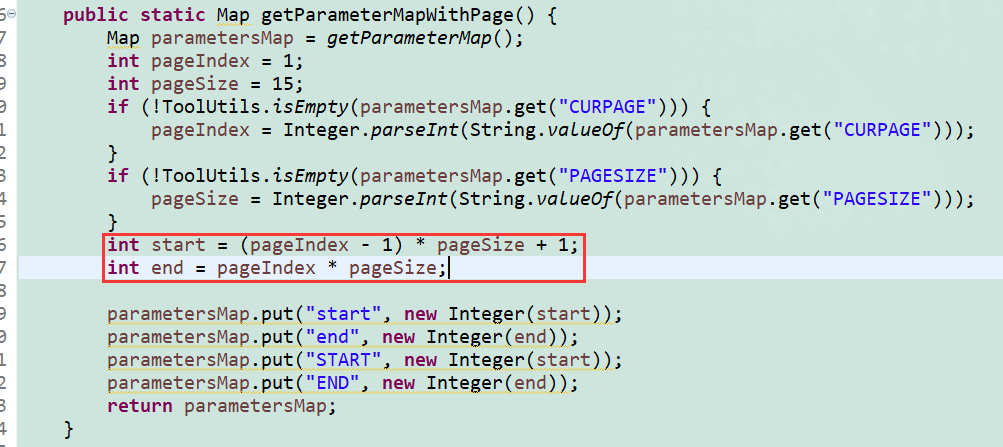
其核心点在于:
int start = (pageIndex - 1) * pageSize + 1;
int end = pageIndex * pageSize;ibatis:
<select id="getACCESS_GRANT" parameterClass="map" resultClass="java.util.HashMap" >
<isNotNull property="END">
SELECT F.* FROM (
</isNotNull>
SELECT E.*,ROWNUM ROWNO FROM (
SELECT T.GRANTJK,T.SECRETKEY,T.ACCESSID,T.ID
FROM ACCESS_GRANT T
<include refid="ACCESS_GRANT_WHERE"/>
)E ORDER BY T.ID
<isNotNull property="END">
<![CDATA[ WHERE ROWNUM <= #END# ) F WHERE F.ROWNO >= #START#]]>
</isNotNull>
</select>其核心点在于:
动态分页,即:当参数start和end有值时,才进行分页,没值时,查询的是所有数据。
3.Mysql分页
最简单查询:

前端同上;
java:只需计算起始数;
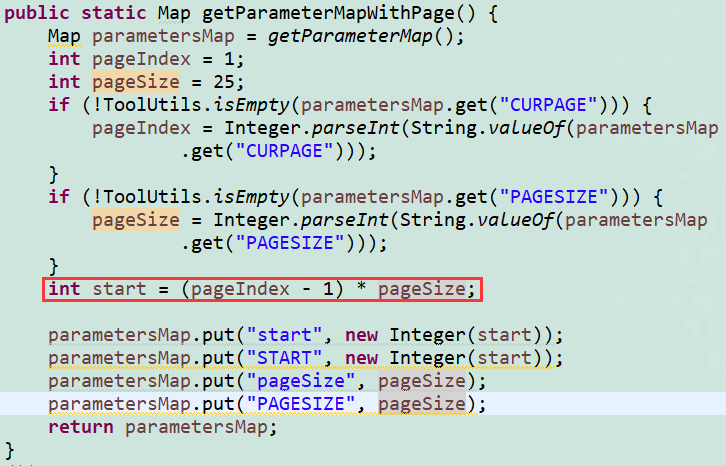
其核心点在于:
计算起始数时,pageIndex需要-1,因为limit是从0开始的,不是1!
使用mysql我们只需要知道start(起始数)和pageSize(分页大小)。
ibatis:
<select id="getMETA_THEME" parameterClass="map" resultClass="java.util.HashMap" cacheModel="cacheMETA_THEME">
<isNotNull property="START">
SELECT F.* FROM (
</isNotNull>
SELECT T.THEMEID,T.THEMENAME,T.THEMECODE,T.THEMELEVEL,T.PARENTTHEMEID,T.STATUS,T.ZJM,DATE_FORMAT(T.CREATETIME,'%Y-%m-%d') CREATETIME,T.REMARK1,T.REMARK2,T.REMARK3
FROM META_THEME T
<include refid="META_THEME_WHERE"/>
ORDER BY T.THEMEID
<isNotNull property="START">
) F
<![CDATA[ limit #START#,#PAGESIZE#]]>
</isNotNull>
</select>其核心点在于:
动态分页,即:当参数start有值时,才进行分页,没值时,查询的是所有数据。
4.小结
Mysql和Oracle分页的区别在于:
Mysql使用limit分页,Oracle使用rownum分页;
Mysql的limit 1,2 相当于:1<rownum≤3,得到的是第二行和第三行记录;要想获得前两行的记录,需要:
limit 0,2 相当于:0<rownum≤2
Oracle分页是:1≤rownum≤2,得到的是第一行和第二行的记录,也就是前两行数据。
所以,这才是造成Mysql起始数从0开始,Oracle从1开始的真正原因。
其实Oracle也可以用int start = (pageIndex - 1) * pageSize;
不过,ibatis里面不能再用≥start,而是使用>start即可。
5.分页+计数
我们知道,查询数据往往涉及分页,而分页又要牵扯到总数;
所以,这里增加oracle和mysql的示例。
2022年2月13日12:02:22
oracle分页+计数(ibatis)
分页
<select id="getBASE_DICTIONARY_INFO" parameterClass="map"
resultClass="java.util.HashMap" cacheModel="cacheBASE_DICTIONARY_INFO">
<isNotNull prepend="" property="end">
SELECT F.* FROM (
</isNotNull>
SELECT E.*,ROWNUM ROWNO FROM (
SELECT A.DICTID,A.CLASSID,A.CODE,A.NAME,A.ZJM,
A.MEMO,A.OID,A.STATUS,
(SELECT CODE FROM BASE_DICTIONARY_KIND T WHERE A.CLASSID = T.CLASSID) CLASSCODE
FROM BASE_DICTIONARY_INFO A
<include refid="BASE_DICTIONARY_INFO_WHERE" />
ORDER BY A.OID
) E
<isNotNull prepend="" property="end">
<![CDATA[ WHERE rownum<=#end#) F where ROWNO>=#start# ]]>
</isNotNull>
</select>计数
<select id="getBASE_DICTIONARY_INFO_COUNT" parameterClass="map"
resultClass="java.lang.Integer" cacheModel="cacheBASE_DICTIONARY_INFO">
SELECT COUNT(1)
FROM BASE_DICTIONARY_INFO A
<include refid="BASE_DICTIONARY_INFO_WHERE" />
</select>动态where条件
<!--表(BASE_DICTIONARY_INFO)通用查询条件-->
<sql id="BASE_DICTIONARY_INFO_WHERE">
<dynamic prepend="WHERE">
<isNotEmpty prepend="and" property="DICTID">
A.DICTID=#DICTID#
</isNotEmpty>
<isNotEmpty prepend="and" property="CLASSID">
A.CLASSID=#CLASSID#
</isNotEmpty>
</dynamic>
</sql>mysql分页+计数(mybatis)
分页
<select id="getPersonInfoByIntoAddressList" resultType="map">
<![CDATA[
SELECT
( SELECT T2.PASS FROM SC_PASS_INFO T2 WHERE T2.ID = T.INTO_ADDRESS ) kaKou,
COUNT( 1 ) jiShu
FROM
SC_PERSON_INFO T
WHERE
T.CREATETIME >= STR_TO_DATE( #{startDate}, '%Y-%m-%d' )
AND T.CREATETIME < STR_TO_DATE( #{endDate}, '%Y-%m-%d' ) + 1
AND T.INTO_ADDRESS IS NOT NULL
AND T.INTO_ADDRESS != ''
GROUP BY
T.INTO_ADDRESS
ORDER BY
T.INTO_ADDRESS
LIMIT #{start},#{pageSize}
]]>
</select>计数
<select id="getPersonInfoByIntoAddressTotal" resultType="long">
<![CDATA[
SELECT
COUNT( 1 ) totalCount
FROM
(
SELECT
1
FROM
SC_PERSON_INFO T
WHERE
T.CREATETIME >= STR_TO_DATE( #{startDate}, '%Y-%m-%d' )
AND T.CREATETIME < STR_TO_DATE( #{endDate}, '%Y-%m-%d' ) + 1
AND T.INTO_ADDRESS IS NOT NULL
AND T.INTO_ADDRESS != ''
GROUP BY
T.INTO_ADDRESS) b
]]>
</select>6.list分页
使用list进行手动分页,见文末《mysql 存储过程 示例》。
写在最后
哪位大佬如若发现文章存在纰漏之处或需要补充更多内容,欢迎留言!!!
相关推荐:
本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/15597091.html

