


python爬取腾讯课堂优质编程课程
基本开发环境
·Python 3.6
·Pycharm
相关模块使用
import requests import jieba import time import wordcloud
目标网页分析
爬取青灯教育免费公开课的课程评价
网站地址
https://ke.qq.com/course/384363?taid=10654594091048299&tuin=8aa5eb27

如何获取课程评价?
打开开发者工具(F12或者鼠标右键检查),复制评价,在开发者工具当中进行搜索。
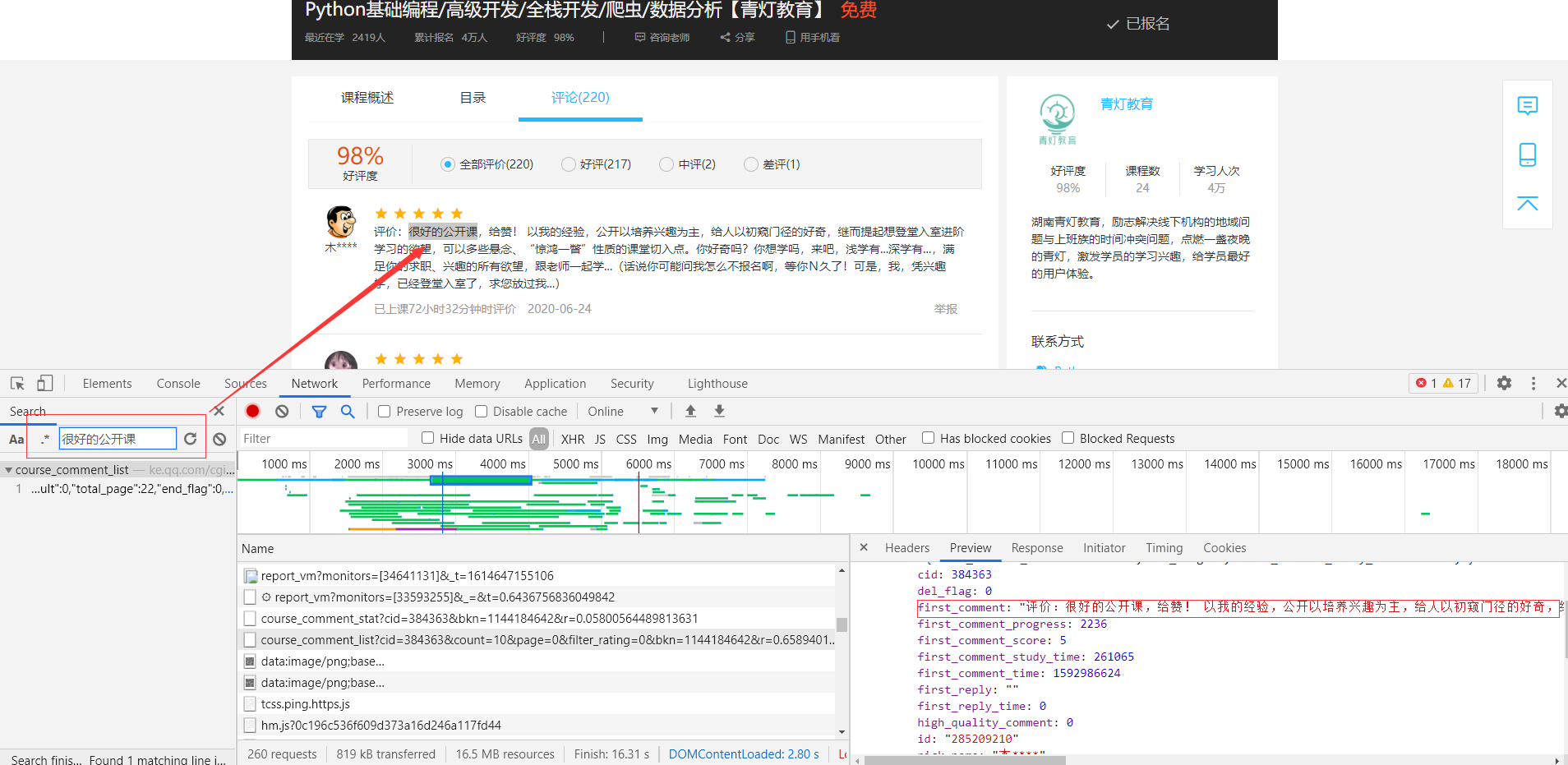
这条数据有十条评价,一页评价也是10条评论,所以只需要请求这个链接,再通过json数据,字典取值的方式提取评价内容即可
·如何实现多页爬取
第一页数据接口参数:

第二页数据接口参数:
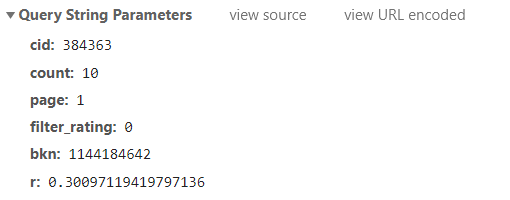
通过对比可得:page参数的变化,对应的是页码数。构建for循环即可实现多页爬取效果
爬虫实现代码
注意点:
headers参数需要添加referer防盗链,不然获取不到数据
import time import requests for page in range(0, 23): time.sleep(1) url = 'https://ke.qq.com/cgi-bin/comment_new/course_comment_list' headers = { 'referer': 'https://ke.qq.com/course/384363?taid=10654585501113707&tuin=8aa5eb27', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } params = { 'cid': '384363', 'count': '10', 'page': page, 'filter_rating': '0', 'bkn': '1905043087', 'r': '0.30477140651006174', } response = requests.get(url=url, params=params, headers=headers) html_data = response.json() result = html_data['result']['items'] for i in result: comment = i['first_comment'] with open('评价.txt', mode='a', encoding='utf-8') as f: f.write(comment) f.write('\n') print(comment)
词云实现代码:
import jieba import wordcloud # 读取文件内容 f = open(r'D:\python\demo\腾讯课堂评价\评价.txt', encoding='utf-8') txt = f.read() # jieba 分词 分割词汇 txt_list = jieba.lcut(txt) string = ' '.join(txt_list) # 词云图设置 wc = wordcloud.WordCloud( width=1000, # 图片的宽 height=700, # 图片的高 background_color='white', # 图片背景颜色 font_path='msyh.ttc', # 词云字体 # mask=py, # 所使用的词云图片 scale=15, stopwords={'老师'}, # 停用词 # contour_width=5, # contour_color='red' # 轮廓颜色 ) # 给词云输入文字 wc.generate(string) # 词云图保存图片地址 wc.to_file(r'D:\python\demo\腾讯课堂评价\out.png')

