xpath爬取喜马拉雅糗事播报音频地址
获取url地址,设置headers,使用xpath对网页进行解析:
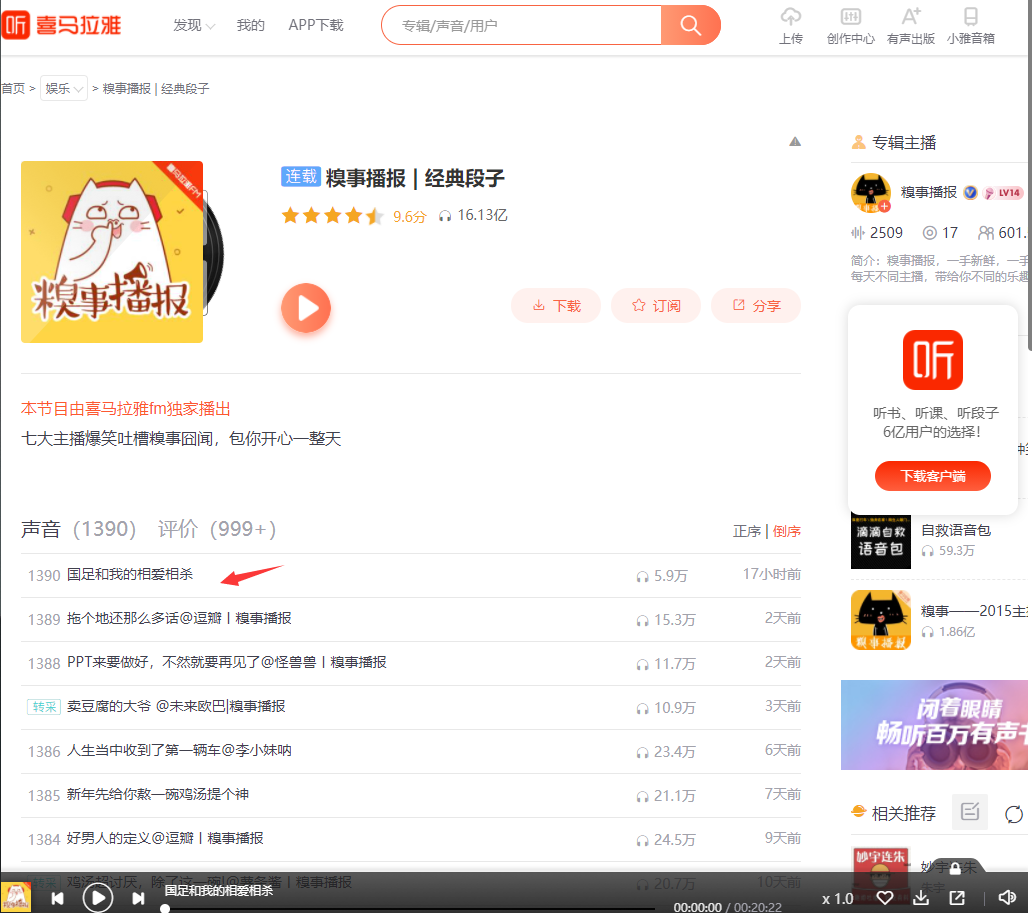


接受介绍页的url,通过xpath解析出来每一个音频的id值,标题


下载内容:
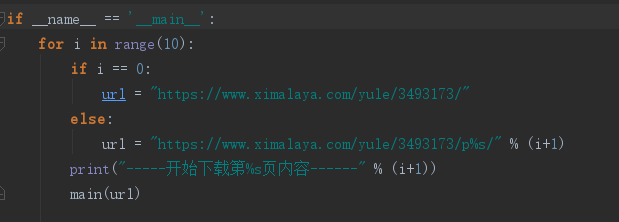
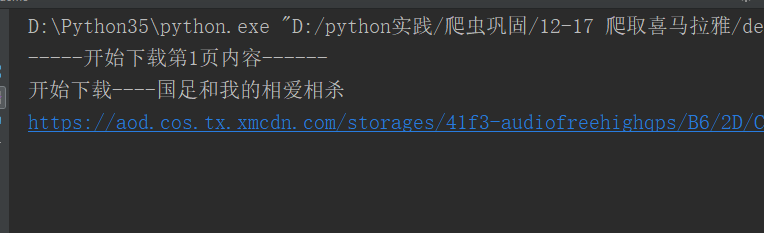
代码如下
import requests from lxml import etree import time headers = { 'authority': 'mermaid .ximalaya.com', 'cache-control': 'no-cache', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36', 'accept': '*/*', 'sec-fetch-site': 'same-site', 'sec-fetch-mode': 'cors', 'sec-fetch-user': '?1', 'sec-fetch-dest': 'empty', 'referer': 'https://www.ximalaya.com/yule/3493173/', 'accept-language': 'zh-CN,zh;q=0.9', 'cookie': '_xmLog=h5^&2e54f20f-24dc-48df-a0c0-5e4d5bc28df5^&2.1.2; x_xmly_traffic=utm_source^%^253A^%^2526utm_medium^%^253A^%^2526utm_campaign^%^253A^%^2526utm_content^%^253A^%^2526utm_term^%^253A^%^2526utm_from^%^253A; Hm_lvt_4a7d8ec50cfd6af753c4f8aee3425070=1608252623,1608253346,1608253440,1608253957; Hm_lpvt_4a7d8ec50cfd6af753c4f8aee3425070=1608253968', 'Referer': 'https://www.ximalaya.com/yule/3493173/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36', 'Origin': 'https://www.ximalaya.com', 'if-modified-since': 'Wed, 28 Nov 2018 07:43:22 GMT', 'Connection': 'keep-alive', 'Accept': '*/*', 'Sec-Fetch-Site': 'cross-site', 'Sec-Fetch-Mode': 'no-cors', 'Sec-Fetch-Dest': 'script', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8', 'xm-sign': '24393343084be486d4ce4228bc83f4a8(37)0(18)1608256264690', 'content-type': 'application/octet-stream', 'origin': 'https://www.ximalaya.com', 'If-None-Match': 'f45020c793859650e0da4f3720059922', 'pragma': 'no-cache', } def get_html(url): time.sleep(0.5) response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding return response def html_parse(text): tree = etree.HTML(text) return tree def save(url, name): print(url) response = requests.get(url) with open("./糗事播报/%s.m4a" % name, "wb") as f: f.write(response.content) def get_m4a(id, title): url = 'https://www.ximalaya.com/revision/play/v1/audio?id=%s&ptype=1' % id response = get_html(url).json() yinpin_url = response["data"]["src"] print("开始下载----%s" % title) save(yinpin_url, title) print("下载完成----%s" % title) def main(url): """ 接收介绍页的url,通过xpath解析出来每一个音频的id值、标题。 :param url: 介绍页的url :return: """ response = get_html(url) tree = html_parse(response.text) res_urls = tree.xpath('//*[@id="anchor_sound_list"]/div[2]/ul/li/div[2]/a/@href') yinpin_titles = tree.xpath('//*[@id="anchor_sound_list"]/div[2]/ul/li/div[2]/a/@title') for res, yinpin_title in zip(res_urls, yinpin_titles): get_m4a(res.split("/")[-1], yinpin_title) if __name__ == '__main__': for i in range(10): if i == 0: url = "https://www.ximalaya.com/yule/3493173/" else: url = "https://www.ximalaya.com/yule/3493173/p%s/" % (i+1) print("-----开始下载第%s页内容------" % (i+1)) main(url)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号