
模拟登陆淘宝网爬取商品数据
1.因为我们要去模拟人为去登陆搜索商品,所以这里先导入webdriver,设置浏览器驱动对象。之后再获取淘宝网登陆界面的url地址。
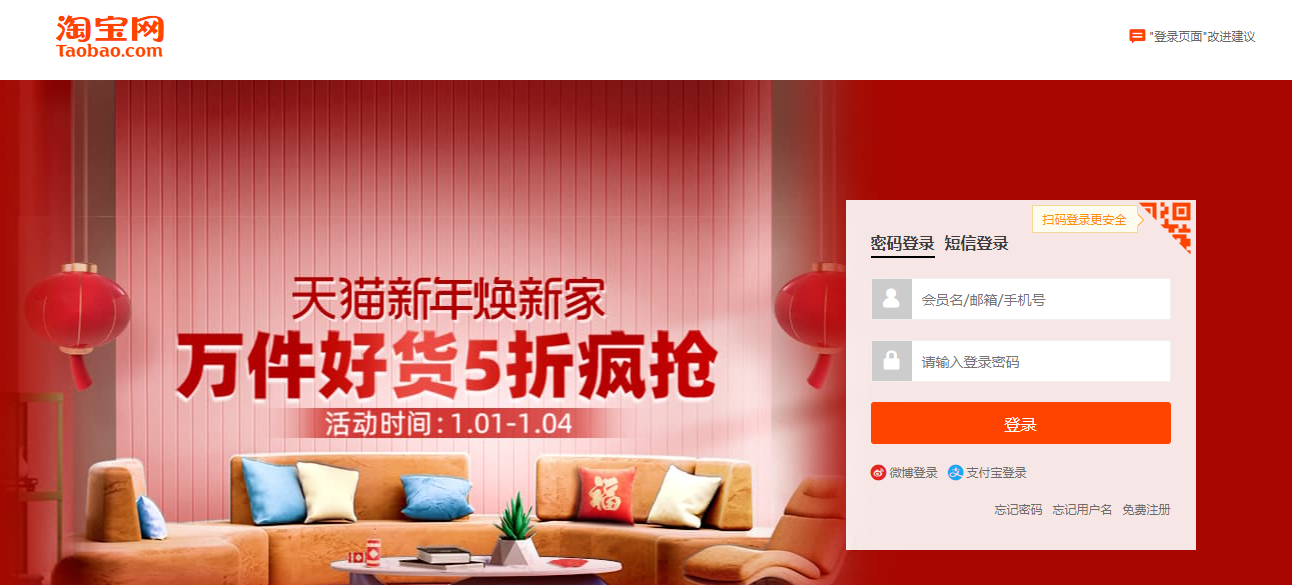

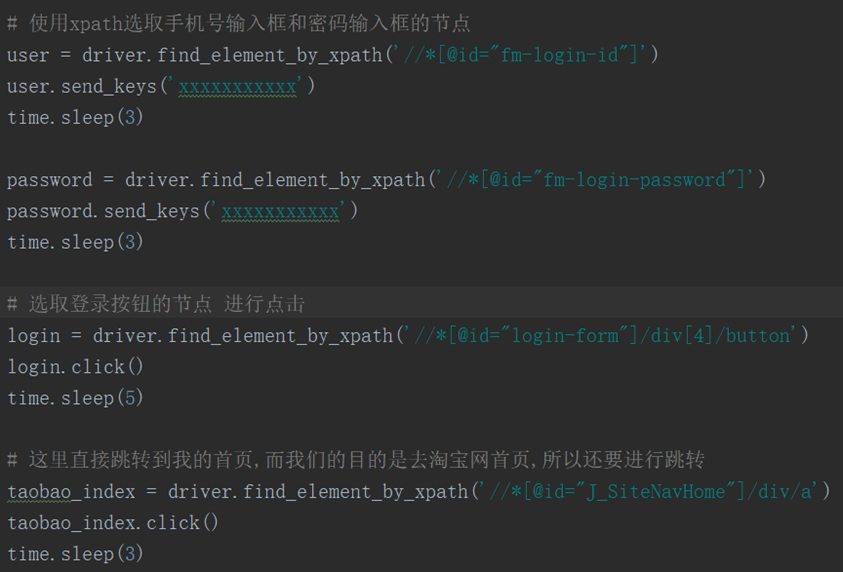
2.进入到登陆界面后,我们使用xpath定位到账号输入框和密码输入框 以及登录按钮,这里在各节点后设置时间等待,避免验证过快。登录过后显示的界面是我的首页,而首要网站淘宝网首页,所以我们再设置一个跳转,跳转到首页
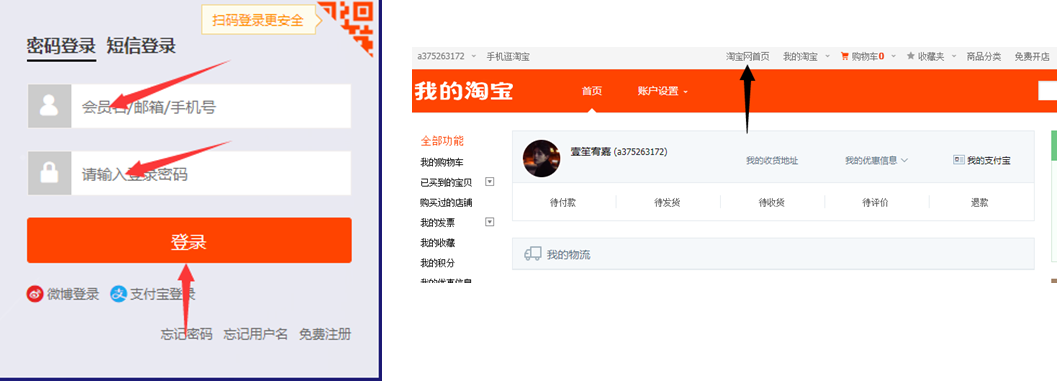
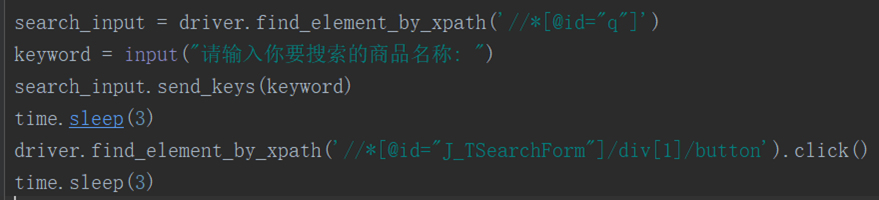
3.这样就进入到了淘宝网首页,接下来就可以开始爬取商品数据了。使用xpath定位到搜索框和搜索按钮,输入我们要搜索的商品数据,点击搜索。

4.这里举例搜索商品名称”冰箱”。搜索出来的商品有100页以上的数据,定义一个url,xpath定位到100数值处,使用正则定位匹配数值。再定义一个翻页函数,第一页搜索出来的商品数据占100页其中一页,所以页码数翻99次进行爬取。之后定义隐式等待,等待10秒时间加载页面,如果超出时间报错timeout。如果不做这项步骤的话,网页其他数据没有加载出来,爬取到的数据就会出现乱码重复格式。
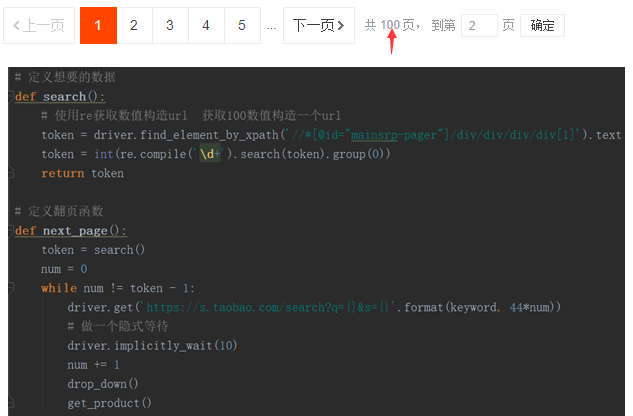
5.前面提到要模拟人为操作去爬取数据,就是说爬取的数据不能太快,即下拉滑动条的速度。所以定义下拉滑动条,设置它为每1秒钟下拉滑动一次,直至数据加载完成。再用js去执行操作。

6.接下来最后一步获取商品数据,使用xpath定位获取商品名称,价格,付款人数,商品图片地址,商店名称,最后保存到txt文本中,输出爬取成功
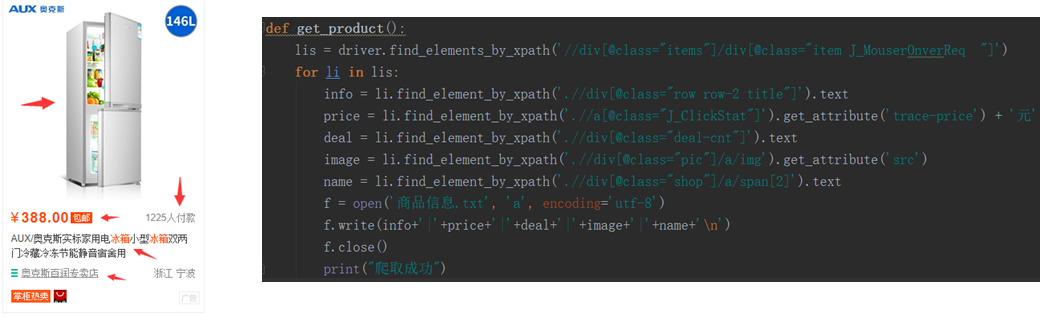
爬取数据展示:

代码如下:
from selenium import webdriver import time import re driver = webdriver.Chrome() driver.maximize_window() # 设置浏览器驱动对象 webdriver.Chrome(executable_path='./chromedriver.exe') driver.get('https://login.taobao.com/member/login.jhtml') # 使用xpath选取手机号输入框和密码输入框的节点 user = driver.find_element_by_xpath('//*[@id="fm-login-id"]') user.send_keys('19160765559') time.sleep(3) password = driver.find_element_by_xpath('//*[@id="fm-login-password"]') password.send_keys('ineverbealone1') time.sleep(3) # 选取登录按钮的节点 进行点击 login = driver.find_element_by_xpath('//*[@id="login-form"]/div[4]/button') login.click() time.sleep(5) # 这里直接跳转到我的首页,而我们的目的是去淘宝网首页,所以还要进行跳转 taobao_index = driver.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a') taobao_index.click() time.sleep(3) search_input = driver.find_element_by_xpath('//*[@id="q"]') keyword = input("请输入你要搜索的商品名称: ") search_input.send_keys(keyword) time.sleep(3) driver.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click() time.sleep(3) # 定义想要的数据 def search(): # 使用re获取数值构造url 获取100数值构造一个url token = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]').text token = int(re.compile('\d+').search(token).group(0)) return token # 定义翻页函数 def next_page(): token = search() num = 0 while num != token - 1: driver.get('https://s.taobao.com/search?q={}&s={}'.format(keyword, 44*num)) # 做一个隐式等待 driver.implicitly_wait(10) num += 1 drop_down() get_product() # 模拟人去滑动页面 去下载数据 # 定义下拉滑动条 # j = 滑动位置 def drop_down(): for x in range(1, 11, 2): time.sleep(1) j = x / 10 js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j driver.execute_script(js) def get_product(): lis = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]') for li in lis: info = li.find_element_by_xpath('.//div[@class="row row-2 title"]').text price = li.find_element_by_xpath('.//a[@class="J_ClickStat"]').get_attribute('trace-price') + '元' deal = li.find_element_by_xpath('.//div[@class="deal-cnt"]').text image = li.find_element_by_xpath('.//div[@class="pic"]/a/img').get_attribute('src') name = li.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text f = open('商品信息.txt', 'a', encoding='utf-8') f.write(info+'|'+price+'|'+deal+'|'+image+'|'+name+'\n') f.close() print("爬取成功") if __name__ == '__main__': next_page()

