
面向对象设计与构造 第一单元总结
第一单元博客作业
本单元通过三次课下作业迭代实现了一个最终支持三角函数,求和函数以及自定义函数的表达式解析化简(要求去除非必要括号)程序。
接下来我会依次对这三次作业进行分析,由于需要基于度量分析,为便于理解在开始之前我们先列举一些需要用到的评价指标:
project层次
- v(G)avg平均圈复杂度
- v(G)tot总圈复杂度
- CF整个project的耦合程度
class层次
- OCavg代表类的方法的平均循环复杂度
- WMC代表类的方法的总循环复杂度。
- LOC类的总行数。
method层次
- CogC认知复杂度,用以衡量一段程序的理解成本,即是否容易被人类认知与理解。
- ev(G)基本复杂度,是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
- Iv(G)模块设计复杂度,是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
- v(G)圈复杂度,是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
第一次作业
1. UML与基本思路
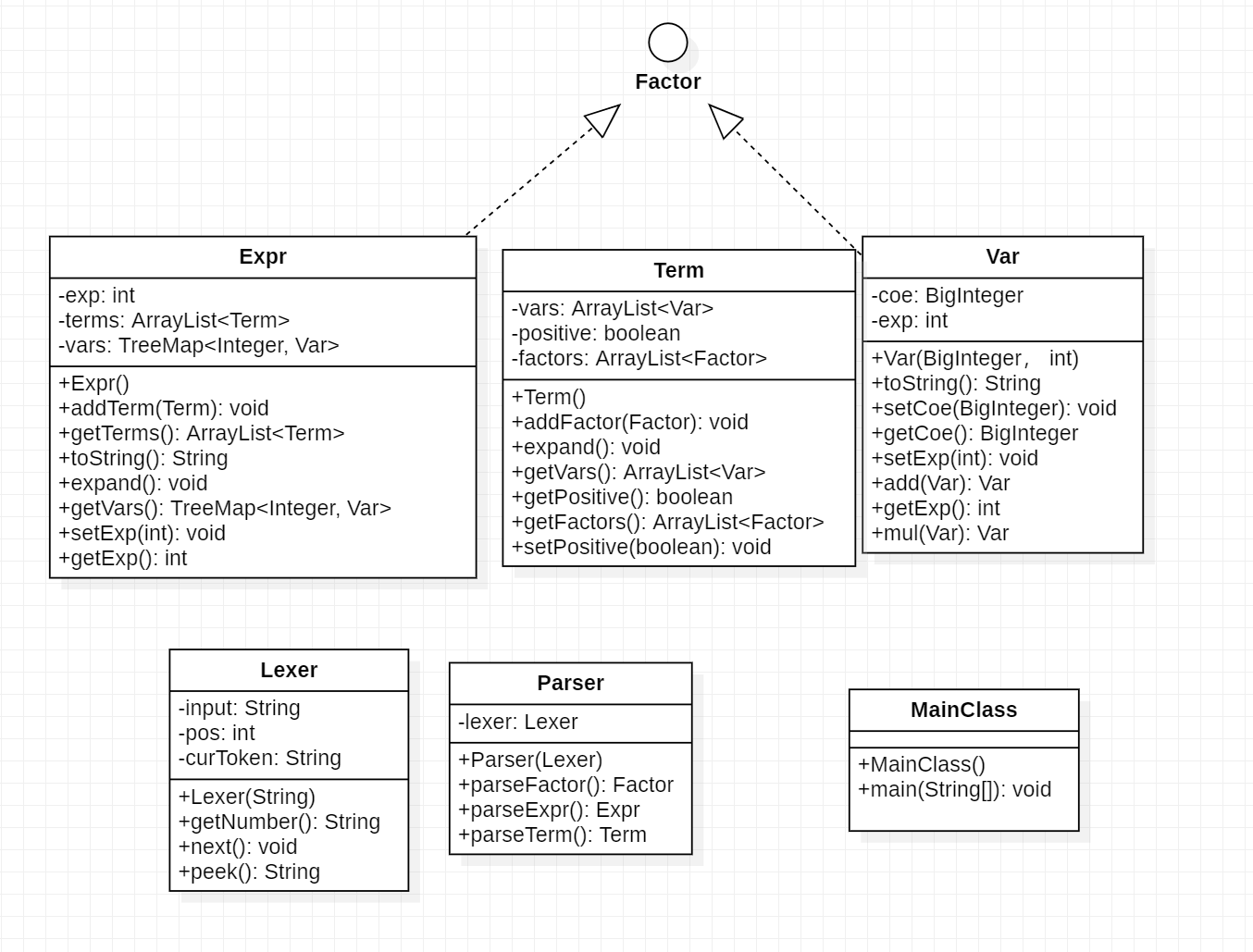
本次作业相对容易理解,非递归意义的因子种类只有幂函数和常数。数据组织上,这两种因子可用一个Var类统一表示,且化简的最终形式也可以确认为一组Var之和的形式,另外对于表达式因子,它不影响最终化简形式,但是需要一个递归的解析方法。
在递归下降法解析该表达式中,我们先使用Lexer进行词法意义上的分解(实际上伴随着Parser解析过程),并利用Parser对表达式进行Expr,Term,Factor语法层级上的解析,其中Expr代表整个表达式(或是表达式因子括号内部分)、Term代表项(表现为表达式中被加减号分割开的各部分)、Factor代表因子(表现为项中被乘号分割开的各部分,也即前述的三种因子)。注意为了处理方便以及意义鲜明,我们令Var和Expr均继承了Factor空接口,表示这些类可以被视为因子。
我的写法解析完成后只是建立了一个实际上的树状存储结构,叶子上全是Var,因此还需要递归地进行数据的综合与化简。为了简便,我先在Expr与Term类中预留了存储最简形式的容器,并分别实现expand()函数,用于将各自储存的低一层的语法元素综合并化简储存起来,这样只需要在顶层Expr类调用一次expand()函数即可得到最简形式,再重写toString()输出即可。
2. 基于度量分析
| Method | LOC |
|---|---|
| MainClass.main(String[]) | 29 |
| expression.Expr.Expr() | 5 |
| expression.Expr.addTerm(Term) | 3 |
| expression.Expr.expand() | 38 |
| expression.Expr.getExp() | 3 |
| expression.Expr.getTerms() | 3 |
| expression.Expr.getVars() | 3 |
| expression.Expr.setExp(int) | 3 |
| expression.Expr.toString() | 21 |
| expression.Term.Term() | 6 |
| expression.Term.addFactor(Factor) | 3 |
| expression.Term.expand() | 25 |
| expression.Term.getFactors() | 3 |
| expression.Term.getPositive() | 3 |
| expression.Term.getVars() | 3 |
| expression.Term.setPositive(boolean) | 3 |
| expression.Var.Var(BigInteger, int) | 4 |
| expression.Var.add(Var) | 3 |
| expression.Var.getCoe() | 3 |
| expression.Var.getExp() | 3 |
| expression.Var.mul(Var) | 3 |
| expression.Var.setCoe(BigInteger) | 3 |
| expression.Var.setExp(int) | 3 |
| expression.Var.toString() | 20 |
| parser.Lexer.Lexer(String) | 4 |
| parser.Lexer.getNumber() | 8 |
| parser.Lexer.next() | 23 |
| parser.Lexer.peek() | 3 |
| parser.Parser.Parser(Lexer) | 3 |
| parser.Parser.parseExpr() | 26 |
| parser.Parser.parseFactor() | 36 |
| parser.Parser.parseTerm() | 9 |
| Class | LOC |
|---|---|
| MainClass | 31 |
| expression.Expr | 84 |
| expression.Term | 51 |
| expression.Var | 46 |
| parser.Lexer | 43 |
| parser.Parser | 77 |
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| MainClass.main(String[]) | 1 | 1 | 2 | 2 |
| expression.Expr.Expr() | 0 | 1 | 1 | 1 |
| expression.Expr.addTerm(Term) | 0 | 1 | 1 | 1 |
| expression.Expr.expand() | 28 | 1 | 11 | 11 |
| expression.Expr.getExp() | 0 | 1 | 1 | 1 |
| expression.Expr.getTerms() | 0 | 1 | 1 | 1 |
| expression.Expr.getVars() | 0 | 1 | 1 | 1 |
| expression.Expr.setExp(int) | 0 | 1 | 1 | 1 |
| expression.Expr.toString() | 10 | 4 | 4 | 5 |
| expression.Term.Term() | 0 | 1 | 1 | 1 |
| expression.Term.addFactor(Factor) | 0 | 1 | 1 | 1 |
| expression.Term.expand() | 17 | 1 | 9 | 9 |
| expression.Term.getFactors() | 0 | 1 | 1 | 1 |
| expression.Term.getPositive() | 0 | 1 | 1 | 1 |
| expression.Term.getVars() | 0 | 1 | 1 | 1 |
| expression.Term.setPositive(boolean) | 0 | 1 | 1 | 1 |
| expression.Var.Var(BigInteger, int) | 0 | 1 | 1 | 1 |
| expression.Var.add(Var) | 0 | 1 | 1 | 1 |
| expression.Var.getCoe() | 0 | 1 | 1 | 1 |
| expression.Var.getExp() | 0 | 1 | 1 | 1 |
| expression.Var.mul(Var) | 0 | 1 | 1 | 1 |
| expression.Var.setCoe(BigInteger) | 0 | 1 | 1 | 1 |
| expression.Var.setExp(int) | 0 | 1 | 1 | 1 |
| expression.Var.toString() | 10 | 8 | 10 | 10 |
| parser.Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| parser.Lexer.getNumber() | 2 | 1 | 3 | 3 |
| parser.Lexer.next() | 10 | 2 | 6 | 10 |
| parser.Lexer.peek() | 0 | 1 | 1 | 1 |
| parser.Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| parser.Parser.parseExpr() | 8 | 1 | 6 | 6 |
| parser.Parser.parseFactor() | 9 | 5 | 7 | 7 |
| parser.Parser.parseTerm() | 1 | 1 | 2 | 2 |
| Class | OCavg | WMC |
|---|---|---|
| MainClass | 2 | 2 |
| expression.Expr | 2.75 | 22 |
| expression.Term | 2.14 | 15 |
| expression.Var | 1.88 | 15 |
| parser.Lexer | 2.75 | 11 |
| parser.Parser | 3.75 | 15 |
| Project | CF |
|---|---|
| project | 71.43% |
可以看到,各个类的规模还是比较平均的,同时各个类的平均复杂度也不算高,表明模块化做得有一定合理性。另外,我们发现主要是expand()方法相对比较复杂,不过考虑到该方法承担的功能逻辑上较为单一,规模上也还在可接受范围内,就并未进行进一步的拆解。整体上,代码的耦合度似乎有些高,这可能是由于我将解析和化简输出分开,从而导致需要parse和expand两个递归过程,这方面可通过在解析同时化简降低耦合。
3. Bug分析
本次在强测与互测中均未被测出bug。互测中用python根据形式化定义写了一个随机数据生成器,并进行了一些自动测试,发现一人的代码在输入字符串尾部存在空白符时会出现指针越界错误。
第二次作业
1. UML与基本思路
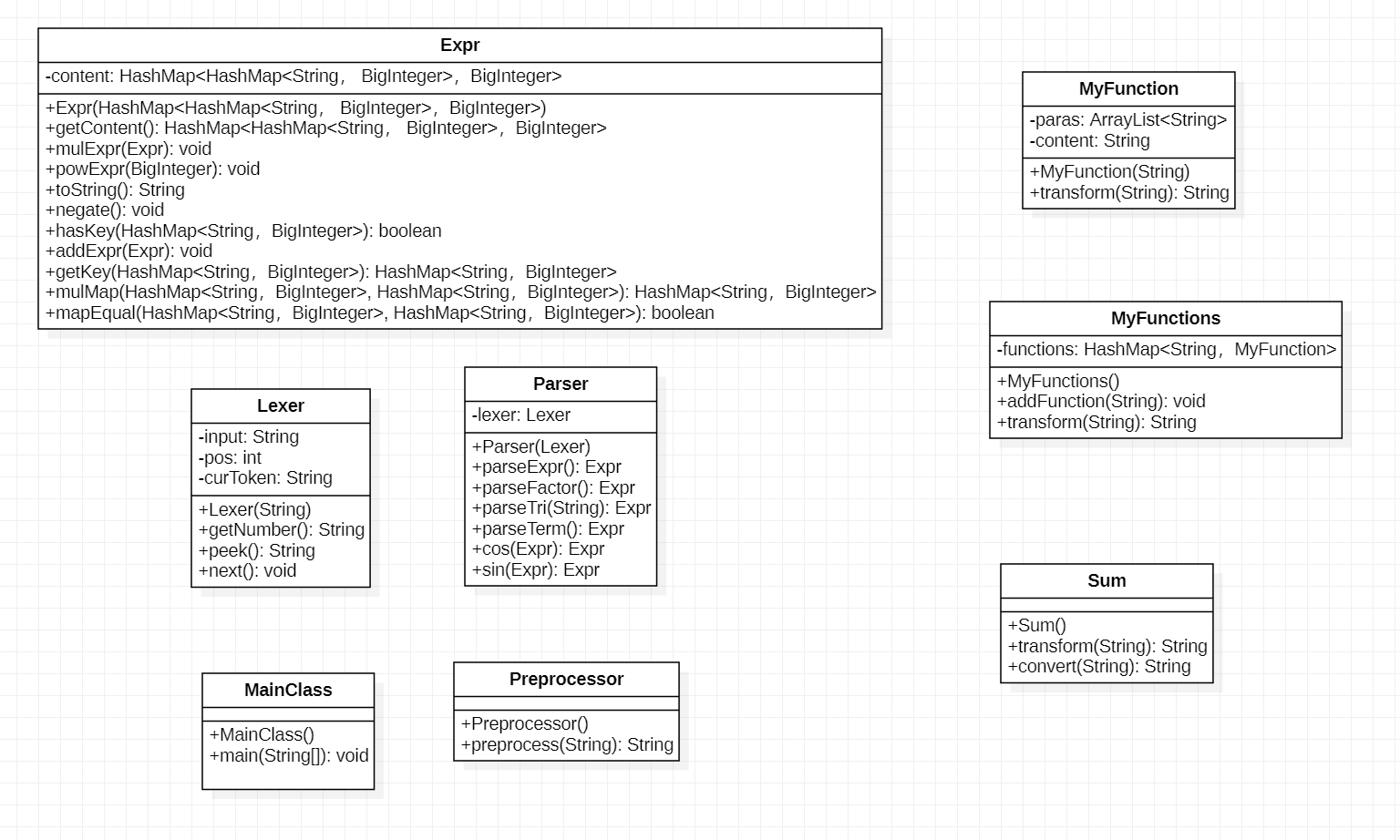
本次作业新加入了三角函数因子以及不支持嵌套的求和函数和自定义函数,在我看来算是很大的改动,便在继承上次作业部分想法的前提下进行了一些重构。
首先是确定Expr的最终形式,这方面使用嵌套的hashmap即可(实际上这一步很重要,选择了适合的数据结构能为之后的处理与化简降低很大难度);然后对于自定义函数以及求和,本次作业中我使用了暴力字符串替换进行预处理,注意这种方法需要小心处理中的许多细节,有必要单独对这部分模块进行充分的测试。
另外,可以看到本次作业中我移除了Term和Factor类,但并不代表我移除了这两个语法层级,实际上,语法上的分层在parser的各种parse方法中表现,但是我让这些方法统一返回Expr类型,因为按照形式化定义,项和因子均能被视为Expr(故也可被嵌套hashmap统一表示)。这样做的好处是可以不为Term等类编写运算和toString方法, 缺点是模块化程度较低,导致Expr类较为复杂。
2. 基于度量分析
| Method | LOC |
|---|---|
| MainClass.main(String[]) | 26 |
| expression.Expr.Expr(HashMap<HashMap<String, BigInteger>, BigInteger>) | 3 |
| expression.Expr.addExpr(Expr) | 10 |
| expression.Expr.getContent() | 3 |
| expression.Expr.getKey(HashMap<String, BigInteger>) | 8 |
| expression.Expr.hasKey(HashMap<String, BigInteger>) | 10 |
| expression.Expr.mapEqual(HashMap<String, BigInteger>, HashMap<String, BigInteger>) | 20 |
| expression.Expr.mulExpr(Expr) | 19 |
| expression.Expr.mulMap(HashMap<String, BigInteger>, HashMap<String, BigInteger>) | 23 |
| expression.Expr.negate() | 7 |
| expression.Expr.powExpr(BigInteger) | 11 |
| expression.Expr.toString() | 34 |
| expression.MyFunction.MyFunction(String) | 11 |
| expression.MyFunction.transform(String) | 15 |
| expression.MyFunctions.MyFunctions() | 3 |
| expression.MyFunctions.addFunction(String) | 4 |
| expression.MyFunctions.transform(String) | 31 |
| expression.Sum.convert(String) | 36 |
| expression.Sum.transform(String) | 31 |
| parser.Lexer.Lexer(String) | 4 |
| parser.Lexer.getNumber() | 8 |
| parser.Lexer.next() | 35 |
| parser.Lexer.peek() | 3 |
| parser.Parser.Parser(Lexer) | 3 |
| parser.Parser.cos(Expr) | 7 |
| parser.Parser.parseExpr() | 28 |
| parser.Parser.parseFactor() | 51 |
| parser.Parser.parseTerm() | 12 |
| parser.Parser.parseTri(String) | 27 |
| parser.Parser.sin(Expr) | 7 |
| parser.Preprocessor.preprocess(String) | 10 |
| Class | LOC |
|---|---|
| MainClass | 28 |
| expression.Expr | 151 |
| expression.MyFunction | 30 |
| expression.MyFunctions | 41 |
| expression.Sum | 69 |
| parser.Lexer | 55 |
| parser.Parser | 138 |
| parser.Preprocessor | 12 |
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| MainClass.main(String[]) | 1 | 1 | 2 | 2 |
| expression.Expr.Expr(HashMap<HashMap<String, BigInteger>, BigInteger>) | 0 | 1 | 1 | 1 |
| expression.Expr.addExpr(Expr) | 4 | 1 | 3 | 3 |
| expression.Expr.getContent() | 0 | 1 | 1 | 1 |
| expression.Expr.getKey(HashMap<String, BigInteger>) | 3 | 3 | 2 | 3 |
| expression.Expr.hasKey(HashMap<String, BigInteger>) | 6 | 4 | 3 | 4 |
| expression.Expr.mapEqual(HashMap<String, BigInteger>, HashMap<String, BigInteger>) | 14 | 6 | 5 | 6 |
| expression.Expr.mulExpr(Expr) | 7 | 1 | 4 | 4 |
| expression.Expr.mulMap(HashMap<String, BigInteger>, HashMap<String, BigInteger>) | 14 | 1 | 7 | 7 |
| expression.Expr.negate() | 3 | 1 | 3 | 3 |
| expression.Expr.powExpr(BigInteger) | 1 | 1 | 2 | 2 |
| expression.Expr.toString() | 23 | 3 | 8 | 10 |
| expression.MyFunction.MyFunction(String) | 3 | 1 | 3 | 3 |
| expression.MyFunction.transform(String) | 4 | 1 | 4 | 4 |
| expression.MyFunctions.MyFunctions() | 0 | 1 | 1 | 1 |
| expression.MyFunctions.addFunction(String) | 0 | 1 | 1 | 1 |
| expression.MyFunctions.transform(String) | 18 | 6 | 11 | 11 |
| expression.Sum.convert(String) | 7 | 2 | 6 | 6 |
| expression.Sum.transform(String) | 18 | 6 | 11 | 11 |
| parser.Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| parser.Lexer.getNumber() | 2 | 1 | 3 | 3 |
| parser.Lexer.next() | 15 | 2 | 8 | 14 |
| parser.Lexer.peek() | 0 | 1 | 1 | 1 |
| parser.Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| parser.Parser.cos(Expr) | 0 | 1 | 1 | 1 |
| parser.Parser.parseExpr() | 8 | 1 | 6 | 6 |
| parser.Parser.parseFactor() | 11 | 6 | 9 | 9 |
| parser.Parser.parseTerm() | 1 | 1 | 2 | 2 |
| parser.Parser.parseTri(String) | 7 | 3 | 5 | 5 |
| parser.Parser.sin(Expr) | 0 | 1 | 1 | 1 |
| parser.Preprocessor.preprocess(String) | 0 | 1 | 1 | 1 |
| Class | OCavg | WMC |
|---|---|---|
| MainClass | 2 | 2 |
| expression.Expr | 4 | 44 |
| expression.MyFunction | 3 | 6 |
| expression.MyFunctions | 3.33 | 10 |
| expression.Sum | 7 | 14 |
| parser.Lexer | 3.75 | 15 |
| parser.Parser | 3.29 | 23 |
| parser.Preprocessor | 1 | 1 |
| Project | CF |
|---|---|
| project | 32.14% |
不出所料,复杂度集中在Expr和Parser类中,这确实是我这种架构的代价;同时也可以看到负责字符串替换的几个类拥有较大的认知复杂度与非结构化程度,在编写的过程中我也发现这是bug的重灾区,说明这种trick是大型项目需要避免的;可喜的是,CF相比上次作业有大幅降低,说明该架构整体的耦合度不是很高,逻辑线路比较清晰。
3. Bug分析
得益于较为充分的测试,本次在强测与互测中均未被测出bug,同时也未成功hack他人代码。
第三次作业
1. UML与基本思路
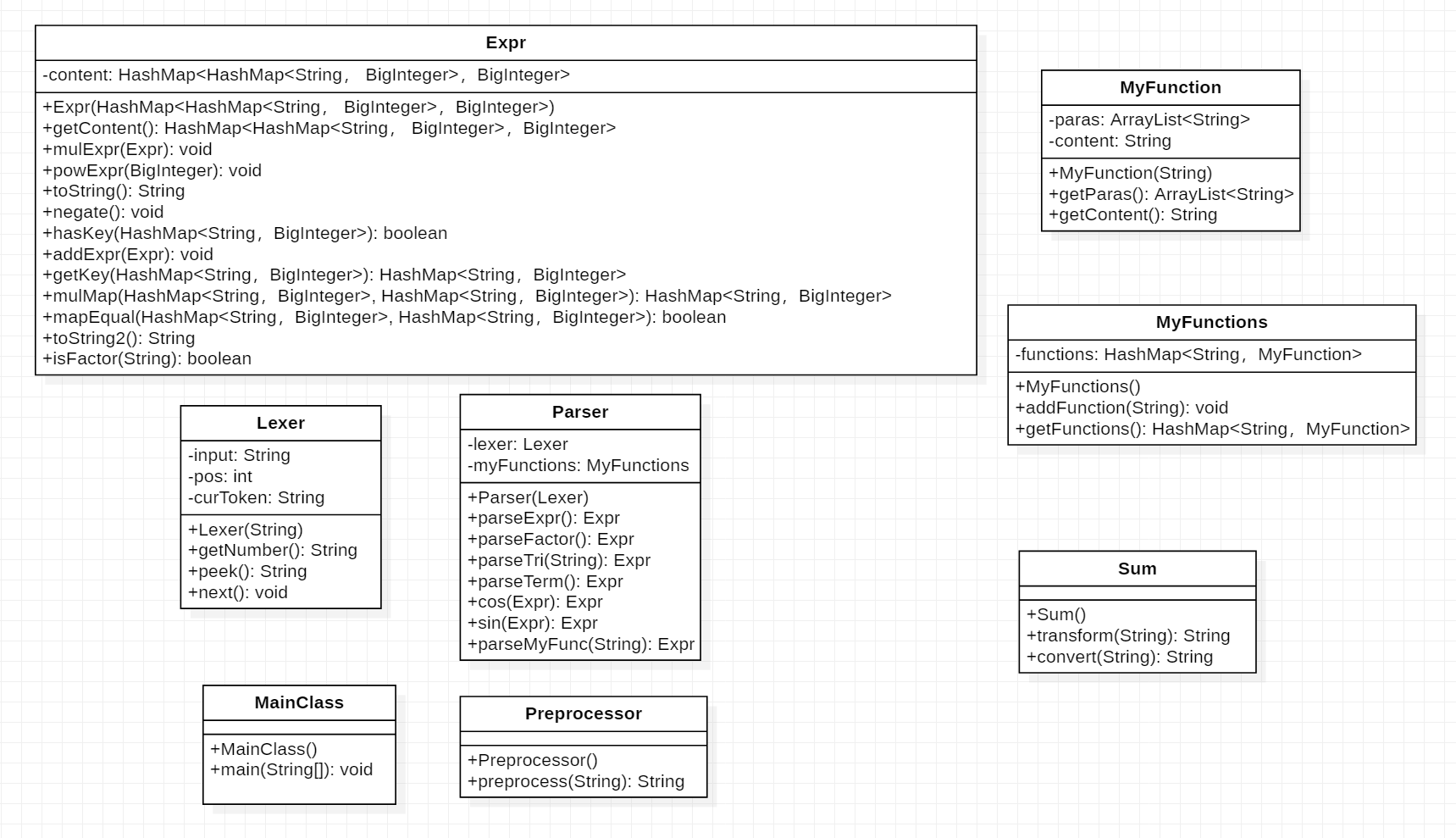
本次作业要求三角函数以及自定义函数支持嵌套,总体需要改动的地方不多。由于自定义函数可以嵌套,不能沿用字符串预处理模式,便在Parser中新增parseMyFunc()方法,用于解析自定义函数;三角函数其实在上次作业中已经实现嵌套表达式,但本次作业要求三角函数内部只能是因子,输出时需要添加必要的括号,否则会格式错误(我的bug便是出现在这一方面)。
2. 基于度量分析
| Method | LOC |
|---|---|
| MainClass.main(String[]) | 26 |
| expression.Expr.Expr(HashMap<HashMap<String, BigInteger>, BigInteger>) | 3 |
| expression.Expr.addExpr(Expr) | 10 |
| expression.Expr.getContent() | 3 |
| expression.Expr.getKey(HashMap<String, BigInteger>) | 8 |
| expression.Expr.hasKey(HashMap<String, BigInteger>) | 10 |
| expression.Expr.isFactor(String) | 12 |
| expression.Expr.mapEqual(HashMap<String, BigInteger>, HashMap<String, BigInteger>) | 20 |
| expression.Expr.mulExpr(Expr) | 19 |
| expression.Expr.mulMap(HashMap<String, BigInteger>, HashMap<String, BigInteger>) | 23 |
| expression.Expr.negate() | 7 |
| expression.Expr.powExpr(BigInteger) | 11 |
| expression.Expr.toString() | 34 |
| expression.Expr.toString2() | 38 |
| expression.MyFunction.MyFunction(String) | 11 |
| expression.MyFunction.getContent() | 3 |
| expression.MyFunction.getParas() | 3 |
| expression.MyFunctions.MyFunctions() | 3 |
| expression.MyFunctions.addFunction(String) | 4 |
| expression.MyFunctions.getFunctions() | 3 |
| expression.Sum.convert(String) | 36 |
| expression.Sum.transform(String) | 31 |
| parser.Lexer.Lexer(String) | 4 |
| parser.Lexer.getNumber() | 8 |
| parser.Lexer.next() | 41 |
| parser.Lexer.peek() | 3 |
| parser.Parser.Parser(Lexer, MyFunctions) | 4 |
| parser.Parser.cos(Expr) | 7 |
| parser.Parser.parseExpr() | 28 |
| parser.Parser.parseFactor() | 54 |
| parser.Parser.parseMyFunc(String) | 22 |
| parser.Parser.parseTerm() | 12 |
| parser.Parser.parseTri(String) | 27 |
| parser.Parser.sin(Expr) | 7 |
| parser.Preprocessor.preprocess(String) | 10 |
| Class | LOC |
|---|---|
| MainClass | 28 |
| expression.Expr | 201 |
| expression.MyFunction | 21 |
| expression.MyFunctions | 13 |
| expression.Sum | 69 |
| parser.Lexer | 61 |
| parser.Parser | 165 |
| parser.Preprocessor | 12 |
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| MainClass.main(String[]) | 1 | 1 | 2 | 2 |
| expression.Expr.Expr(HashMap<HashMap<String, BigInteger>, BigInteger>) | 0 | 1 | 1 | 1 |
| expression.Expr.addExpr(Expr) | 4 | 1 | 3 | 3 |
| expression.Expr.getContent() | 0 | 1 | 1 | 1 |
| expression.Expr.getKey(HashMap<String, BigInteger>) | 3 | 3 | 2 | 3 |
| expression.Expr.hasKey(HashMap<String, BigInteger>) | 6 | 4 | 3 | 4 |
| expression.Expr.isFactor(String) | 3 | 2 | 2 | 2 |
| expression.Expr.mapEqual(HashMap<String, BigInteger>, HashMap<String, BigInteger>) | 14 | 6 | 5 | 6 |
| expression.Expr.mulExpr(Expr) | 7 | 1 | 4 | 4 |
| expression.Expr.mulMap(HashMap<String, BigInteger>, HashMap<String, BigInteger>) | 14 | 1 | 7 | 7 |
| expression.Expr.negate() | 3 | 1 | 3 | 3 |
| expression.Expr.powExpr(BigInteger) | 1 | 1 | 2 | 2 |
| expression.Expr.toString() | 23 | 3 | 8 | 10 |
| expression.Expr.toString2() | 25 | 4 | 8 | 11 |
| expression.MyFunction.MyFunction(String) | 3 | 1 | 3 | 3 |
| expression.MyFunction.getContent() | 0 | 1 | 1 | 1 |
| expression.MyFunction.getParas() | 0 | 1 | 1 | 1 |
| expression.MyFunctions.MyFunctions() | 0 | 1 | 1 | 1 |
| expression.MyFunctions.addFunction(String) | 0 | 1 | 1 | 1 |
| expression.MyFunctions.getFunctions() | 0 | 1 | 1 | 1 |
| expression.Sum.convert(String) | 7 | 2 | 6 | 6 |
| expression.Sum.transform(String) | 18 | 6 | 11 | 11 |
| parser.Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| parser.Lexer.getNumber() | 2 | 1 | 3 | 3 |
| parser.Lexer.next() | 18 | 2 | 11 | 18 |
| parser.Lexer.peek() | 0 | 1 | 1 | 1 |
| parser.Parser.Parser(Lexer, MyFunctions) | 0 | 1 | 1 | 1 |
| parser.Parser.cos(Expr) | 0 | 1 | 1 | 1 |
| parser.Parser.parseExpr() | 8 | 1 | 6 | 6 |
| parser.Parser.parseFactor() | 13 | 7 | 12 | 12 |
| parser.Parser.parseMyFunc(String) | 2 | 1 | 3 | 3 |
| parser.Parser.parseTerm() | 1 | 1 | 2 | 2 |
| parser.Parser.parseTri(String) | 7 | 3 | 5 | 5 |
| parser.Parser.sin(Expr) | 0 | 1 | 1 | 1 |
| parser.Preprocessor.preprocess(String) | 0 | 1 | 1 | 1 |
| Class | OCavg | WMC |
|---|---|---|
| MainClass | 2 | 2 |
| expression.Expr | 4.38 | 57 |
| expression.MyFunction | 1.67 | 5 |
| expression.MyFunctions | 1 | 3 |
| expression.Sum | 7 | 14 |
| parser.Lexer | 4.25 | 17 |
| parser.Parser | 3.38 | 27 |
| parser.Preprocessor | 1 | 1 |
| Project | CF |
|---|---|
| project | 39.29% |
由于整体改动并不是很大,代码规模与复杂度与上次相近,便不再赘述。
3. Bug分析
本次在强测中未被测出bug,但在互测中出现一个bug。该bug出现在isFactor()方法中,该方法中我试图直接利用一次正则匹配判断三角函数内部是否满足因子形式以确定是否有必要在两侧添加括号,但是我当时设计的一次正则匹配实际上无法确定字符串是否为因子,这个问题我后来通过递归调用isFactor()进行递归的正则匹配才得以解决。
hack中发现两人各一个bug,其中一人的bug与我类似,另一人由于使用了Integer而出现了溢出错误。
总结:
总的来说,第一次单元的三次作业通过递进的难度让我初识了面向对象的设计方法,也意识到了充分掌握这种思想方法的重要性。
一旦代码规模增大,使用一般的面向过程的编程方法往往会导致逻辑过于复杂致于不可读、难以扩展,而通过将问题分解,模块化,并设计适当的对象进行组织和管理,能够使得不仅在编程过程中保持思路清晰,而且代码具备高可理解性。另外,善用编程语言的面向对象的特性,比如继承与多态,能够大大减少工程量,同时也使得迭代更为容易。在这一点上,我承认目前做得还不够好,可以看到我在后两次作业中甚至并没有建立继承关系,不过我还是注意了对各种功能的抽象与封装,使得程序的整体逻辑还是较为清晰的。
最后,即使对自己的编程能力极为自信,也不能忽视测试的重要性。测试有很多技巧,目前我也只能初窥门径:对于黑盒测试,可以使用脚本语言快速搭建随机数据生成器以及评测器;白盒测试中,可以通过对工程不同模块的分别测试来验证整体的正确性,当然还有各显神通的边界数据编写等等方法,在此也不再赘述了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号