
《Python 接口自动化测试》:第2章 接口基础
2 接口基础
本章讲什么:
(1)什么是接口、接口的分类,以及有哪些常用的 HTTP 接口;
(2)接口测试;
(3)基于 Python+Django+MySQL 的 HTTP 接口实例分析。
2.1 什么是接口
关于什么是接口、什么是 API,如果读者去网上查询,可以找到的解释有很多,而且绝大多数都是很标准的官方解释,例如:
API(Application Programming Interface)即应用程序接口。你可以认为 API 是一个 Web 服务与外界进行交互的接口。这里的接口可以和 API 画等号。
1.从功能层面来说
从功能层面来说,可以将接口简单理解为一个黑盒子。其上游负责输入参数,下游负责输出参数,类似于平时的黑盒测试对象,如图 2-1-1 所示。

图 2-1-1 接口理解 1
这里以一个例子来说明:
(1)在 Chrome 浏览器中输入:https://www.v2ex.com/api/nodes/show.json?name=Python,按「Enter」键之后能看到如图 2-1-2 所示的数据。
(2)下面来分析这个过程。
在输入 URL 地址并按 Enter 键后,页面实际发送了一次接口请求。具体的请求是:接口地址(https://www.v2ex.com/api/nodes/show.json?)+ 请求参数及其值(name=python)。后面这个「name=python」就是输入数据;返回的数据就是浏览器展示的一个 JSON 格式数据。至于这个数据是怎么来的,目前还是看不到的。所以这就像黑盒子一样,输入不同的数据会得到不同的返回结果。这里读者也可以试试其他的参数,看看返回的数据内容是什么样子的,比如:
https://www.v2ex.com/api/nodes/show.json?name=java
https://www.v2ex.com/api/nodes/show.json?name= 测试
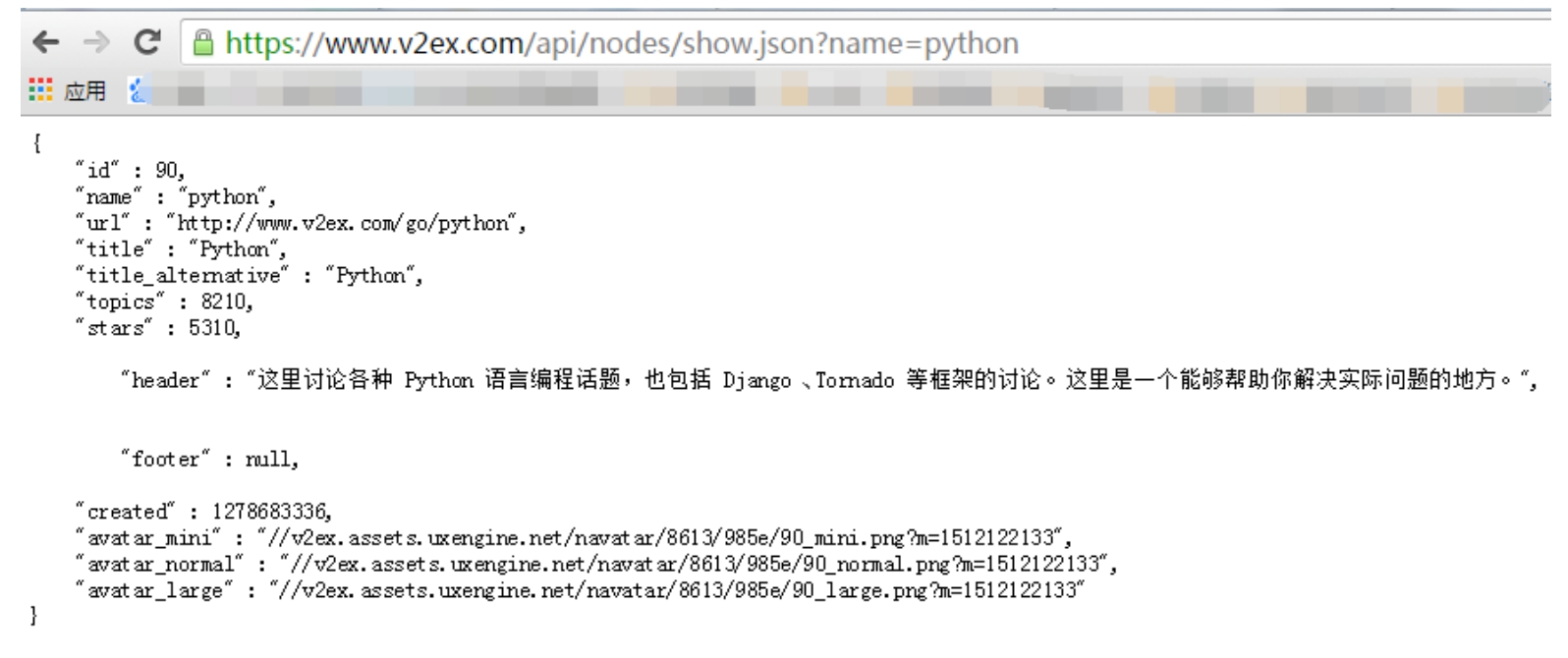
图 2-1-2 接口返回数据
名词解释
(1)JSON(JavaScript Object Notation):是一种轻量级的数据交换格式,独立于语言和平台。JSON 解释器和 JSON 库支持不同的编程语言,是以{}括起来的键值对数据。
JSON 数据格式如下:
{"name":"Michael","age":24}
在这个例子中,键是字符串形式,值可以取任意类型。name 是键名,Michael 是键对应的值。JSON 是可以嵌套的,比如{「name」:「Michael」,「birthday」:{「month」:8,「day」:26}}。
(2)JSON 格式的在线检查工具:
https://www.beJSON.com/JSONviewernew/
通过上面的在线检查工具,能检查 JSON 格式的正确性。
2.从数据流层面来说
从数据流层面来说,可以将接口理解为连接前端(Web 页面、APP 等)和数据库(Database)等后端的纽带,用于在二者之间传递数据、处理数据,如图 2-1-3 所示。

图 2-1-3 接口理解 2
在现在主流的框架结构中,后端一般都使用数据库来存储数据,而前端不能直接去数据库中操作数据,一方面不安全,另一方面效率低。要完成数据的交互,必然要有中间的纽带,那就是接口。所以,从这个层面来说,接口主要负责前端页面和后端数据库之间的数据传输和处理。
当下大部分的互联网产品都采用前/后端分离的方式,即前端的表示层负责展示数据及其样式,后端的数据层负责数据处理和存储,如图 2-1-4 所示,它们之间的业务逻辑层负责处理业务逻辑,其中最重要的就是接口。所以说,接口的健壮性、稳定性、抗压性直接决定了这个互联网产品的成败。前端页面通过调用接口传递约定的参数;接口收到请求后,会按照业务逻辑在后端进行处理,并将处理结果和需要的数据返回给前端;前端解析数据并展示在页面。这就完成了广义上的一次前/后端交互。
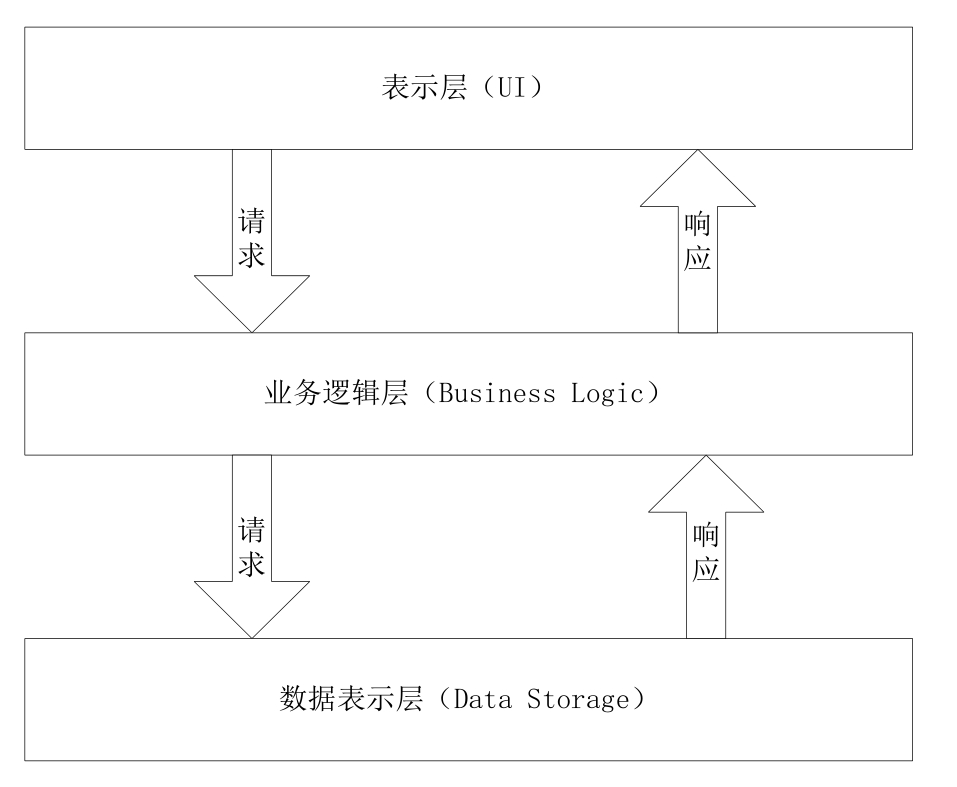
图 2-1-4 三层结构
名词解释:
(1)前端(前台):可以直观看到和使用的内容都可被归为前端。比如,Web 页面上一些可见的、可操作的界面。
(2)后端:不能被用户可见的内容。其实,后端是一个编程上的概念,具体是指业务逻辑和数据的处理。
(3)后台:通俗意义上是指管理系统,主要用来增加、删除、修改、查询数据,实际上是内部人士使用的一个 Web 系统。
3.从编程层面来说
从编程层面来说,可以将接口理解为业务逻辑处理方法的外在表现形式,如图 2-1-5 所示。它可以是一个类下面的方法,也可以是一个函数。

图 2-1-5 接口理解 3
从数据流层面来理解,接口会按照「业务逻辑」处理数据。那么业务逻辑在哪里呢?很显然,是在程序代码的函数或方法中。函数或方法按照逻辑返回不同的数据,这便是接口在不同参数下的不同返回信息。所以,从「白盒操作」角度来看,接口测试是直接对函数或方法的代码层进行测试。
以上从三个层面解释了什么是接口。读者没必要把接口想得过于复杂,认为接口和接口测试多么高深。实际上,接口和日常的页面测试没有本质的区别,只是在外在表现形式和测试方法上略微有差别。读者从以上三个层面可以窥探出接口测试的一般思路,后面还会逐步讲解,请耐心往下看。
2.2 接口的分类
根据系统调用方式可以将接口分为以下两类。
1.系统之间的接口
系统之间的接口如图 2-2-1 所示。我们用得最多的是第三方接口,比如要做一个系统来展示每天的天气,那天气数据是怎么得到的呢?不可能自己去预测天气,有免费的第三方接口可使用,只需按照接口协议调用想要的天气数据。当然,这是调用系统外部的数据。在系统内部也存在这种调用关系,道理类似。
图 2-2-1 接口分类 1
2.服务之间的接口
目前主流的系统架构如图 2-2-2 所示,即应用层、服务层和数据层。

图 2-2-2 接口分类 2
· 应用层:负责展示数据和发起数据请求。比如,12306 购票网站上显示的票数、购买操作等。
· 服务层:为应用层提供数据处理。
· 数据层:用来存储数据,有关系型数据库等。
各层之间的调用过程是怎样的呢?例如,在 12306 网站上买票,首先用户需要选择票,然后通过单击「确定」按钮下单。用户下单就是调用了应用层的接口,假设叫「购买接口」,购买接口会去数据层的数据库中进行查询、新增购买记录等操作。成功完成后,会返回一个成功标志和其他信息。最后,应用层接收到这个接口返回的数据,将买票结果展现给用户。
在这个过程中,各层之间的交互就是通过接口。应用层和服务层之间是通过 HTTP 接口,服务层和数据层主要通过 DAO(Data Access Object)访问数据。在第 5 章讲到用 Python 操作 MySQL 数据库时,使用的 PyMySQL 就是起这个作用的。
2.3 HTTP 接口
下面介绍最常用的 HTTP 接口。
(1)HTTP 接口的应用场景:Web 网站、公司的 OA 服务。
(2)HTTP 请求由三部分组成,分别是:请求地址、消息报头、请求正文。
(3)HTTP 响应也是由三个部分组成,分别是:状态码、消息报头、响应正文。
下面用具体的实例来说明 HTTP 接口。
这里使用的是 Fiddler 工具。该工具可以抓取 HTTP 数据包,辅助进行测试。通过该工具抓取特定网页的协议数据包,来分析 HTTP 的知识点。该工具的具体使用方法会在第 3 章详细讲到,目前读者只需要知道该工具可以抓取 HTTP 数据包即可。
下面抓取的是百度个人中心首页的「百度新闻」→「个性推荐」栏目中的短数据,页面如图 2-3-1 所示。
图 2-3-1 百度个人中心
使用 Fiddler 工具获取的接口数据如图 2-3-2 所示。
图 2-3-2 使用 Fiddler 工具获取的接口数据
1.HTTP 请求的三个重要数据
(1)请求地址:http://i.baidu.com/card
(2)消息报头:

名词解释
下面介绍消息报头的主要参数。
· Host:i.baidu.com
指定被请求资源的 Internet 主机和端口号,默认是 80 端口。
· Connection:keep-alive
HTTP 长连接(持久连接),客户端和服务器端建立一次连接之后,可以在这条连接上进行多次请求/响应操作。持久连接,可以设置过期时间(Keep-Alive:timeout=60),也可以不设置。
· Accept:*/*
表示浏览器能接受任何类型的文件。
· X-Requested-With:XMLHttpRequest
表明这是一次 Ajax 请求(异步),非传统请求(同步)。
· User-Agent:Mozilla/5.0(Windows NT 6.1;WOW64)
用户代理。告知服务器请求方所使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
· Accept-Encoding:gzip,deflate
设置从网站中接收的返回数据是否进行 gzip 压缩。
· Cookie:BDUSS=d0b2JQSGxBbXQ3NUhIcWpqT21xd
储存在本地的缓存数据,随 HTTP 请求一起发送,用来给服务器端验证,比如是否已经登录。
(3)请求正文:p=xinwen&c=pernews。
2.HTTP 响应的三个重要数据
(1)状态码:

(2)消息报头:
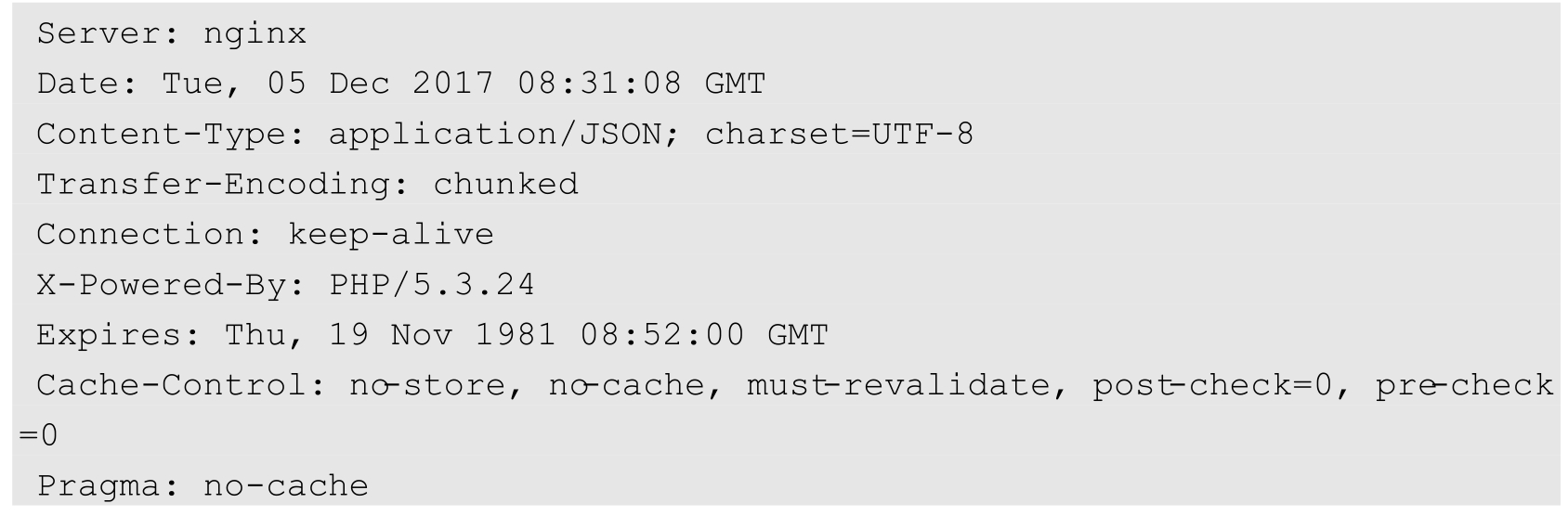
(3)响应正文:

下面介绍响应的消息报头。
「Content-Type:application/JSON;charset=UTF-8」表示服务器发送的实体数据的数据类型。
在 HTTP 请求的返回数据包中,响应状态码分为以下 5 种。
· 1xx:消息。一般是告诉客户端,请求已经收到了,正在处理,别急……
· 2xx:处理成功。一般表示请求收悉、我明白你要的、请求已受理、已经处理完成等信息。
· 3xx:重定向到其他地方。它让客户端再发起一个请求,以完成整个处理过程。
· 4xx:处理发生错误,错误来自客户端。例如,客户端请求的是一个不存在的资源、客户端未被授权、禁止访问等。
· 5xx:处理发生错误,错误来自服务器端。例如,服务器端抛出异常、路由出错、HTTP 版本不支持等。
2.3.1 HTTP 发送请求的方式
HTTP 中有四种发送请求的方式:GET、POST、PUT 和 DELETE。
(1)GET:向特定的资源发出请求。
(2)POST:向指定资源提交「数据进行处理」请求(例如,提交表单或者上传文件),数据被包含在请求体中。POST 请求可能导致新的资源的创建,以及(也可能是「或」)已有资源的修改。
(3)PUT:向指定资源位置上传其最新内容。
(4)DELETE:请求服务器执行删除操作。
在实际应用中常用的是 GET 和 POST。其他的请求方式都可以通过这两种方式间接地实现。
2.3.2 GET 方式和 POST 方式的区别
HTTP 发送请求最主要的两个方式是 GET 和 POST,这两者有哪些区别呢?
区别一:对请求参数的处理方式不同(直观的区别)
(1)GET 请求:请求的数据会附加在 URL 之后,以「?」分隔 URL 和传输数据,如有多个参数则用「&」连接。URL 采用的是 ASCII 编码格式,而不是 Unicode 编码格式,即所有的非 ASCII 字符都要在编码之后再传输。
举例:https://www.v2ex.com/api/nodes/show.JSON?name=Python
(2)POST 请求:POST 请求会把请求的数据放置在 HTTP 请求包的 Body 数据中,数据包的形式可以是「参数名 1= 参数值 1&参数名 2= 参数值 2」,也可以是 JSON 格式(键值对)。当然,JSON 格式是一种通用的方式。
举例:http://192.168.1.171:8081/api/user_sign/
Body 数据:{「time」:「1499933825」,「sign」:「deb697c7fffcca828a7a03a218b2cda5」}
区别二:传输数据的大小不同
HTTP 没有对传输数据的大小进行限制,也没有对 URL 的长度进行限制。而在实际的程序开发中,存在以下限制。
· GET:特定浏览器和服务器对 URL 的长度有限制。例如,IE 对 URL 长度的限制是 2083Byte(2×1024Byte+35Byte)。其他浏览器(如 Netscape、FireFox 等)在理论上没有长度的限制,其限制取决于操作系统的支持。因此,在采用 GET 方式提交数据时,传输数据会受到 URL 长度的限制。
· POST:由于不是通过 URL 传值,在理论上数据的大小不受限制。但实际上,各个 Web 服务器会对采用 POST 方式提交的数据的大小进行限制,例如,Apache、IIS6 都有各自的配置。
区别三:安全性不同
POST 方式的安全性比 GET 方式的安全性高。使用 GET 方式时,在地址栏里可以直接看到请求数据,采用这种方式可能受到 Cross-site request forgery 攻击。
POST 方式需要抓包才能获取到数据,变相地提高了安全性。
2.4 接口测试
2.4.1 什么是接口测试
接口测试主要用于检测外部系统与内部系统之间,以及系统内部各个子系统之间的交互点。
2.4.2 为什么要做接口测试
1.传统的测试方法成本急剧增加,且测试效率大幅下降
如今的系统复杂度不断上升,传统的测试方法成本急剧增加,且测试效率大幅下降,所以要做接口测试。
另外,接口测试相对容易实现自动化,且接口自动化也比较稳定,可以减少人工测试的人力成本与时间,缩短测试周期,支持后端版本的快速迭代。
2.可以发现很多页面操作中发现不了的 Bug
如果在页面中对输入框做了「必填」限制,则用户不输入内容是不能发送请求和调用接口的,这样通过页面进行测试受到的限制比较多,而直接调用接口则跳过了页面的限制。此时,如果接口没有做限制,则可以绕过前端页面去请求服务器,自然能发现很多页面操作发现不了的 Bug。
3.可以检查系统的异常处理能力
举例说明,在输入框中输入关键字进行搜索,如果前端做了限制,一旦输入的关键字达到一定长度就会被截断了。而在该情况下,调用接口是正常的,且调用接口可以传很长的参数值。此时能发现一些接口层面的 Bug。比如,接口可能会抛出和数据库表有关的日志信息,借此能看到数据库表中的一些字段数据。
4.可以检查系统的安全性、稳定性
举例说明,比如在页面的搜索框中输入特殊的 SQL 注入语句进行搜索时,发现前端会过滤这些 SQL 语句,那么从前端页面的角度来看这是没有问题的。但是,如果接口没有做类似的处理,一旦被他人获取了接口地址并实施 SQL 注入,则会带来严重的后果。所以,页面要做测试,接口更要做测试。
在前/后端分离时,只要前、后端严格按照接口协议来,一般情况下,后端完成接口测试后便可保证业务逻辑的正确性,剩下的便是前端如何展示的问题。所以,一般情况下都是后端先上线,前端再上线。
2.4.3 如何开展接口测试
做接口测试所要面对的现实情况如下:
(1)页面原型还不完整,甚至没有原型设计。
(2)有具体的页面需求文档和要实现的功能说明书。
(3)有接口文档和业务逻辑设计图等。
综上所述,接口测试人员不但需要有很强的抽象能力,而且要有丰富的联想能力。可以按照下面的步骤来实施接口测试(手工)。
(1)获取待测试接口相关数据。一般由开发人员提供接口文档,该文档中包含以下几个基本要素:接口地址、接口请求参数及其说明、请求方式、返回包数据示例、返回码解释等。
(2)充分理解接口逻辑。从产品人员的角度和开发人员的角度,理解接口所要实现的功能、数据的处理逻辑和存储逻辑。该环节尤为重要,需要考量以下几个方面:
· 每个接口所要关联的业务场景是怎样的(从产品的角度);
· 每个接口的业务处理逻辑和数据存储结构(从开发角度)。
(3)设计接口测试用例。
(4)使用工具模拟发送接口请求,检查返回包数据。
(5)对比预期结果与实际结果,判断接口测试用例的通过性。
2.4.4 前/后端交互的「契约—接口」文档
在实际的分层项目开发中,经常会看到这样的场景:
前端人员 A:「后端人员 B,你什么时候把登录接口给我,我要开始写页面了。」
后端人员 B:「等一下,我改一下接口文档就发给你,你按照这个请求就可以了。」
……
前端人员 A:「后端人员 B,登录用户不存在,你怎么给我返回了 0000 啊,害得我判断错了。」
后端人员 B:「不好意思,接口文档写错了,其实代码里面不是这个返回码,应该是 1000,稍等,我来改一下文档,你按照最新的文档做判断就可以了。」
在前/后端人员的交互中,能看到反复提到了「接口文档」,那么接口文档是什么呢?为什么它在前/后端之间如此重要?
1.什么是接口文档?
接口文档就是前/后端之间数据交互的一纸契约,有规范的格式和内容要求。后端按照接口协议接收前端传递来的合法数据并返回符合规范的数据,前端按照接口协议传递符合规范的数据并对后端返回的数据依据展示需要做处理。所以说,接口文档是对前/后端开发的强有力约束。
2.为什么接口文档很重要?
(1)接口文档是纽带。当接口文档确定之后,前/后端人员就可以各自开发自己的代码,在开发完成后就可以联调了,而联调的过程就是对接口是否能使用进行测试。这样可以节省前/后端等待的时间。
(2)接口文档是对业务逻辑的传承。在标准的研发流程中,接口文档始终是最新的,所有的前/后端人员修改方案都要先设计接口并更新接口文档,然后再修改代码。这样间接地节省了后期维护的成本和新入职员工的学习成本。
3.接口文档是什么样子的?
接口文档主要包含以下内容。
(1)接口功能:对接口作用的大概描述,使人一眼就知道该接口的作用。
(2)接口 URL:即接口的请求地址。一般都是相对地址,便于在不同环境之间切换。
(3)请求方法:一般的 HTTP 的请求方法是 POST 或 GET。
(4)请求参数:包含参数类型及其限制条件。
(5)返回包数据的实例。
(6)返回码的解释。

图 2-4-1 所示是一个简洁版的接口文档。
2.5 接口实例
本节主要分析一个接口实例,目的是让读者直观地理解接口、接口的表现方式、接口的数据处理逻辑。
该实例是基于 Python+Django+MySQL 开发的,目前暂不提供外网访问功能,只能在本地演示,其涵盖了前端、后端、数据库及其交互功能,是一个浓缩版的小系统。
2.5.1 前端页面
图 2-5-1 所示的是一个简单的前端页面,它分为两部分:上方是名称输入框和「搜索」按钮,可以按照名称来搜索数据;下方是搜索结果展示列表。
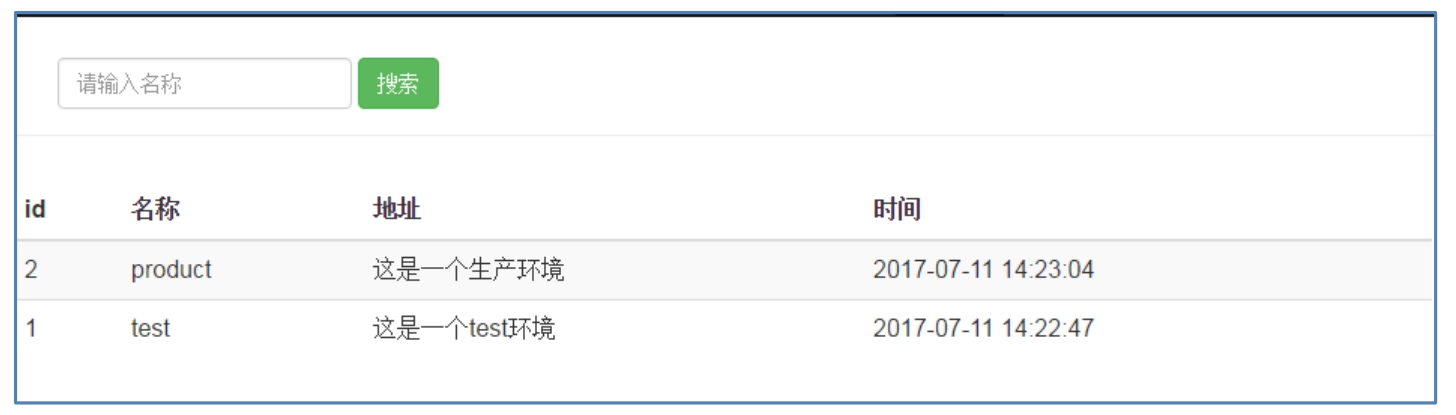
图 2-5-1 演示版页面
大家应该比较熟悉这个场景,无论是 Web 页面还是 APP 应用程序,都有类似的搜索功能及其结果展示列表。
用户在这个页面中输入关键字「test」并单击「搜索」按钮,然后在搜索结果展示列表中会显示出搜索到的内容,如图 2-5-2 所示。

图 2-5-2 搜索到的内容
2.5.2 节会以一张流程图来展示这个页面和底层数据的交互过程。
2.5.2 数据流图
图 2-5-3 是按照 2.5.1 小节介绍的业务流程绘制的简单数据流图。
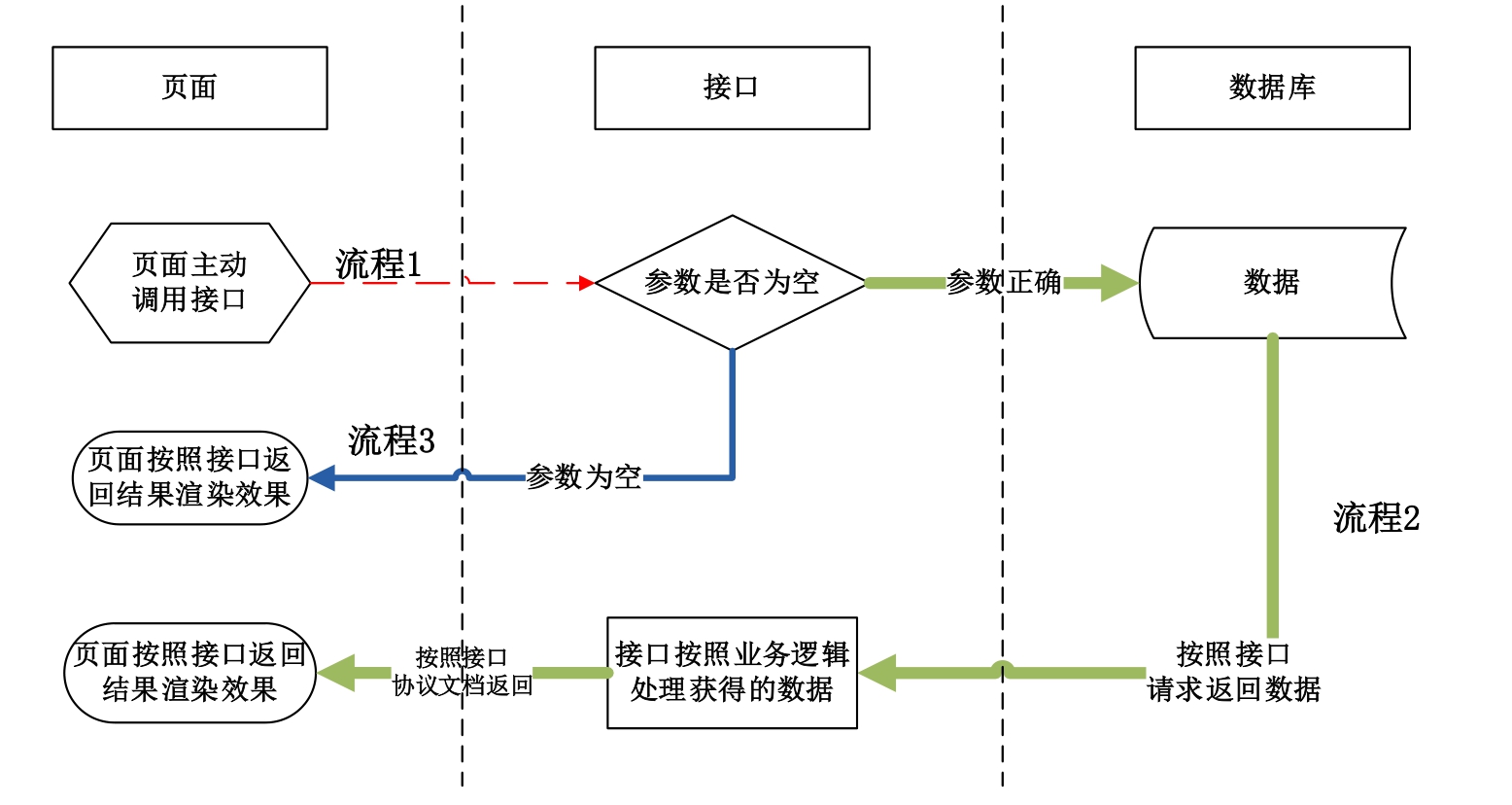
图 2-5-3 数据流图
按照前面对接口的理解,这里将这个数据流划分为页面、接口、数据库 3 部分。下面分别介绍图中的 3 个流程。
1.流程 1
首先,用户在页面主动发起搜索功能,即输入关键字后单击「搜索」按钮,此时页面调用接口,传入接口需要的参数(content)和值(搜索关键字),等待接口返回数据。
这种等待过程很常见,比如在百度中搜一个关键字,然后页面一直在「转圈」,这可能就是页面在等待接口返回数据。出现这种情况,可能是接口返回数据慢导致页面一直在等待,也可能是网络传输延迟等。
2.流程 2
如果接口接收到的请求数据是正确且合法的,则会按照接口中的逻辑到数据库中获取数据,在获取到数据后会对数据进行处理,再将处理结果和返回码按照接口协议中的格式返回给页面。
页面接收到返回数据后,会按照接口协议和实际需要来渲染效果,比如,页面列表会展示接口返回的数据,即用户看到的检索结果。
3.流程 3
接口接收到请求后,先判断必要的参数是否存在(比如,按照接口文档约定的参数名称应该是 content,然而传来的参数名称是 name,显然这不是需要的)。如果参数不存在,则接口直接返回空数据和对应的返回码。
页面在接收到返回数据后,会按照约定的情况来处理数据。比如,请求接口时传入的参数值为空,则接口依据逻辑返回必填参数为空,页面在接受到该返回信息时会提示用户输入必填值。这些都是依托接口文档的约束。
那实际情况是不是这样的呢?下面在通过页面发送请求时,使用 Fiddler 工具抓取接口数据,来了解实际请求情况。
图 2-5-4 所示的是获取的页面请求接口情况(即用户在输入搜索关键字后单击「搜索」按钮时产生的数据),其中包含页面请求接口的地址、请求的参数及其值、接口返回的数据。
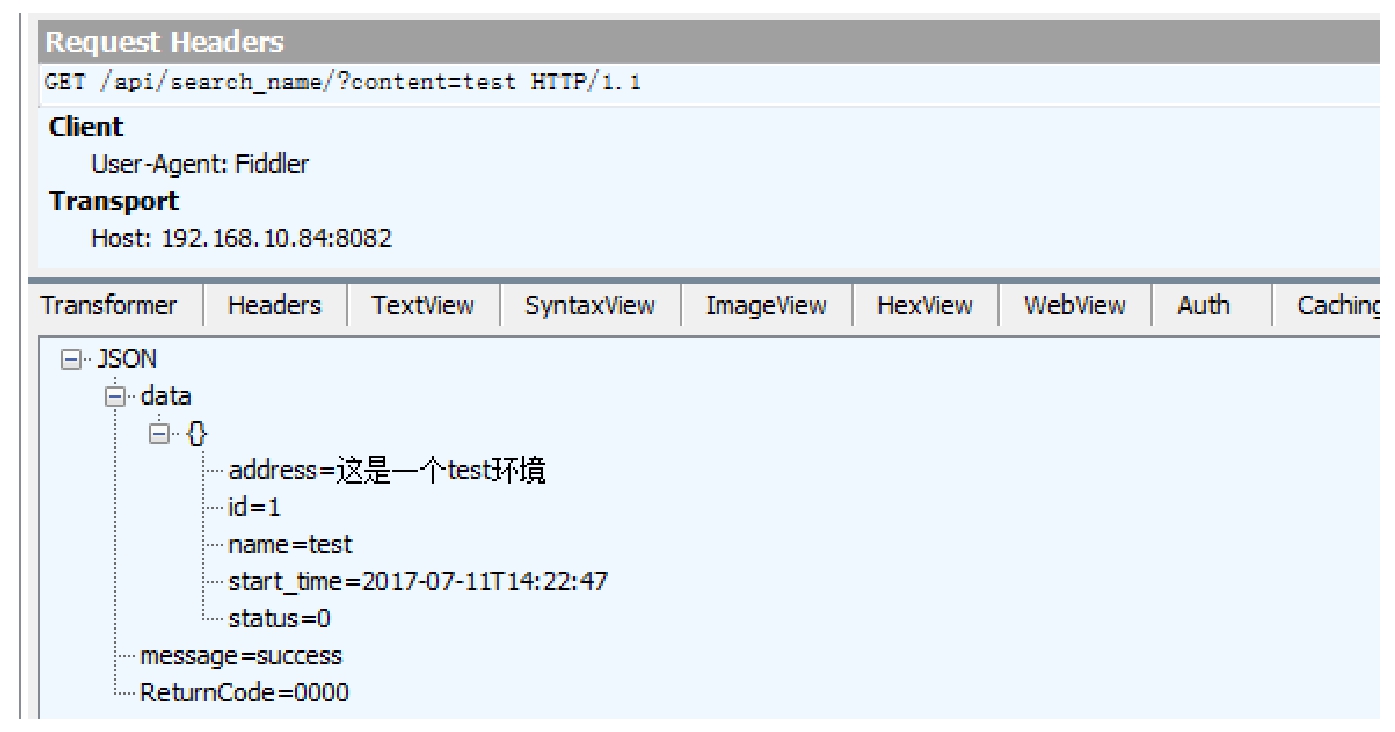
图 2-5-4 Fiddler 工具获取的页面请求接口情况
通过这个页面,能看到以下信息:
(1)接口的地址是 api/search_name。
(2)接口请求参数及其值是 content=test。
(3)接口请求方式是 GET。
(4)接口返回数据是 JSON 形式,包括返回码 ReturnCode、返回信息 message,以及返回数据 data。data 中是一个个 JSON 格式的列表数据。这里涉及 Python 的一些语法,会在后面章的语法部分讲到。
大家注意观察,这个 data 中的数据和在页面中看到的搜索结果非常类似,这说明页面的数据确实是这个接口返回的。有时页面在渲染数据时做了取舍,并不是将接口返回的所有数据都展示在页面上,比如这里的 status 参数值没有做展示。
底层的数据结构又是什么样子的呢?请看图 2-5-5。
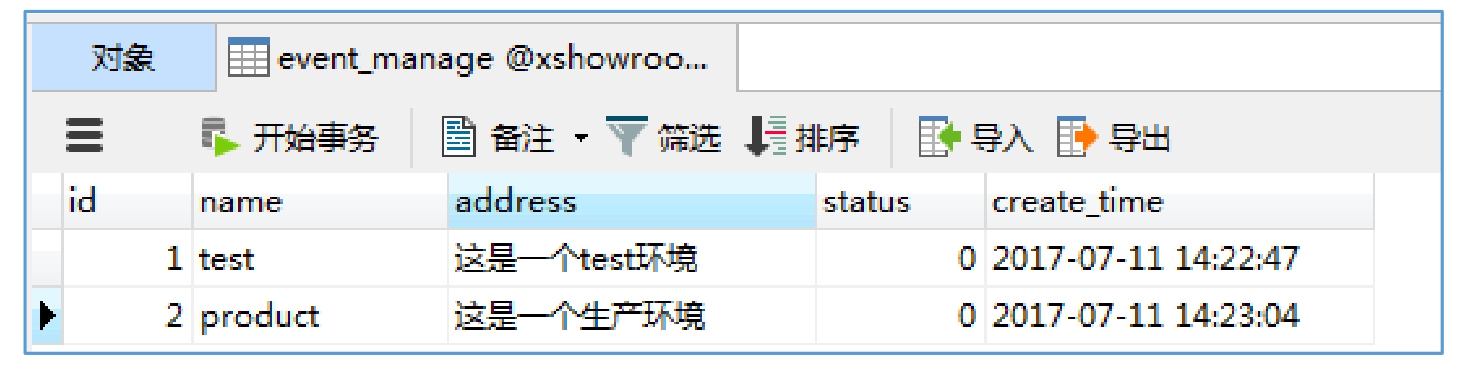
图 2-5-5 数据库表结构
图 2-5-5 展示的是底层数据在数据库的存储情况。这里简单地用一张表来存储所有的数据,在实际项目中会有N张表,每张表之间又会有一些关联字段来建立关系。可以看到,数据库中有两条数据,而接口只返回了其中第一条。原因是,页面搜索的关键字是 test,所以接口的业务逻辑只取了第一条数据。
到这里已经通过接口把前端页面和数据库有机地结合起来了,大家也能比较清楚地理解接口在这两者之间起到的作用。
关于 MySQL 数据库的相关知识,会在第 5 章中讲解。此处读者只需知道有这么一个地方用来存储原始数据即可。
2.5.3 逻辑代码
前几节分别介绍了 Web 页面的样式及功能、页面调用的接口、接口请求和返回数据、数据库数据存储,那是不是就结束了呢?细心的读者可能会发现,现在还不知道接口的代码是怎么处理数据的,即,为什么数据库中有两条数据,而接口只返回了 1 条呢。下面就来介绍这个接口对应的代码是怎么获取数据、处理数据和返回数据的。
这里用的是 Django 框架中的映射关系,将接口请求地址与 views.py 中的处理函数关联起来。其大概的意思是:在调用接口 api/search_name 时,Django 框架会去找 search_name_in 函数。urls.py 文件中的具体配置映射关系如下。
代码:urls.py

具体的业务处理逻辑在 search_name_in 函数中,见下面的代码:
代码:views.py

下面介绍一下上方代码的逻辑:
(1)代码第 1 行是定义一个函数,函数名为 search_name_in。后面括号中是请求参数,参数 request 是特别针对 HTTP 请求的,里面存储的是 HTTP 请求的所有数据。很显然,这个函数的功能是对 HTTP 请求包中的数据做处理。
(2)代码第 3 行是获取接口请求参数 content 的值,并将其值赋给了 search_name 参数。当这个参数值不存在时,则默认是空字符串。
(3)代码第 5 行是按照业务逻辑获取所有的数据。这里使用 SQL 语句查询数据,并将结果赋给了 event_tuple 参数。
(4)代码第 8、9 行是对获取到的数据进行 for 循环,并将数据组装成一个字典加入 event_list 中,然后返回一个 JSON 数据包。
2.6 补充知识点
2.6.1 名词解释
1.Django 框架
Django 是一个开源的 Web 应用框架,由 Python 写成。它采用了 MVC 的框架模式,即模型(M)、视图(V)和控制器(C)。相比其他 Web 框架,Django 的优势是:大而全,集成了 ORM、模型绑定、模板引擎、缓存和 Session 等诸多功能。
2.HTTP
HTTP 即超文本传输协议(Hypertext Transfer Protocol),是基于请求/响应范式的(相当于客户机/服务器)。一台客户机与服务器建立连接后,发送一个请求给服务器;服务器接到请求后,给予相应的响应信息。HTTP 的默认端口是 80,可以不写。
3.MySQL 数据库
MySQL 是一种关系型数据库。它将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样增加了运行速度并提高了灵活性。MySQL 有以下特点:
(1)使用标准的 SQL 数据语言形式。
(2)相对于 Oracle 和 SQL Server,MySQL 更小,更轻量级,当然更适合测试。
2.6.2 答疑
(1)前端页面已经做了「非必填」判断,为什么接口还要做非必填参数的校验?是不是多此一举?
这并不是多此一举,而是双重保护。通常,对于必填参数的校验,前/后端都要做。前端做校验,一方面是给用户友好的提示;另一方面是最直接的系统保护,减少了对后端的请求。而后端做校验,一方面,如果前端没有做保护,则后端不至于出错;另一方面(也是最重要的),如果用户绕过前端的请求直接调用接口则不至于出错。
(2)前端开发、后端开发是什么意思?
· 前端开发。
前端开发一般指的是 Web 前端开发,即网站前端页面(即网页的页面)的开发。简单地说,网站前端工程师负责网站中用户可见的内容开发,如网页上的特效、网页的布局、图片和视频等。网站前端工程师的工作内容是,将美工设计的效果图设计成浏览器可以运行的网页,并和后端开发工程师配合,做网页的数据显示和交互。
· 后端开发。
后端开发一般负责网站后台逻辑的设计和实现,以及用户及网站的数据的保存和读取。比如,在前端实现了登录页面,那么当用户输入账号和密码并单击「登录」按钮时,其实前端已经完成了自己的事件,然后就是等待后端返回账号和密码校验结果,前端根据这个校验结果来显示登录成功、账号或密码错误等提示信息。
(3)前/后端开发的顺序是什么?
在实际的项目开发中,前/后端开发是并行开展的,它们之间能并行的关键是接口文档,前/后端开发都要依据接口文档来做各自对应的事情,如图 2-6-1 所示。

图 2-6-1 前/后端并行开发机制

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步