
第 10 章 数据驱动测试(下) Selenium 3+Python 3 自动化测试
第 10 章 数据驱动测试
数据驱动测试是自动化测试领域比较主流的设计模式之一,也是高级自动化测试工程师必备的技能之一。数据驱动框架是一种自动化测试框架,其目的在于可以让相同的脚本使用不同的测试数据,测试数据和测试行为(脚本)完全分离,便于测试的维护和扩展。
例如,测试登录操作时,需要用到多种用户来登录,然后验证系统的响应是否正确。这里,我们就可以先准备好要登录的用户数据(比如用户名和密码),只需一个自动化登录脚本即可实现。
数据驱动测试的一般步骤如下:
(1)编写脚本,脚本需要有可扩展性并且支持从对象、文件或者持久化数据库中读取测试数据。
(2)准备测试数据到文件或者数据库等外部介质中。
(3)循环调用介质中的数据库来驱动脚本执行。
(4)验证自动化测试结果。
在数据驱动框架中需要掌握 Python 对文件的基本操作等,在这一章中将详细讲解有关文件的相关操作。
10.2 通过 Excel 参数,实现参数与脚本的分离
之前的章节,我们都是将测试数据写在代码中,这种在程序中直接给代码赋值的形式俗称「hardcode」。直接将数据写在源代码中,若测试数据有变,并不利于数据的修改和维护,会造成程序的质量变低。
我们可以尝试通过将测试数据放到 Excel 文档中来实现测试数据的管理,而数据驱动框架的概念正是由此而来。
10.2.1 创建 Excel 文件,维护测试数据
创建 Excel 文件「testdata.xlsx」以备测试之用,具体数据如图 10.29 所示。

图 10.29
下一步需要用 Python 实现读取 Excel 文件的函数功能以备测试之用。代码如下:

上述代码创建了命名为 read_excel 的函数,并设置了三个参数。其中,filename 是 Excel 文件名,可以指定为相对路径;Index 是 Sheet 的编号,比如 Excel 中 Sheet1 表格的 index 值为 0;column 是表格的列,比如 A 列对应的值为 0。
以上是用列表的方式来存储 Excel 中读取的数据,通过观察可以看到 A 列有 3 行数据,B 列有 4 行数据。其实这种情况下用字典的形式来存储数据比较好,每一列数据存储到一个列表中。新的读取 Excel 文件的函数代码如下:




import xlrd def read_excel(filename, sheetname): # 运用xlrd模块的open方法来打开Excel文件 xls_fh = xlrd.open_workbook(filename) # 指定要选择的表格 sheet = xls_fh.sheet_by_name(sheetname) # 打印选定表格的行数 print(sheet.nrows) # 打印选定表格的列数 print(sheet.ncols) # 声明一个空的字典dic data_dic = {} # 表明用for循环遍历Excel中的第一列数据,然后将遍历加入列表data_list中 for j in range(sheet.ncols): # 声明一个空的列表list data_list = [] for i in range(sheet.nrows): data_list.append(sheet.row_values(i)[j]) data_dic[j] = data_list print(data_dic) # 返回列表data_dic字典 return data_dic if __name__ == '__main__': read_excel("testreadexcel.xls","Sheet1")
以下代码调用为输出所有的 excel 文件中第一个 sheet 的所有数据,代码执行结果如图 10.30 所示,和 Excel 文件中的数据是一致的。从输出结果可以看到 Excel 文件有 3 行 2 列,还有数据的实际情况。

图 10.30
10.2.2 Framework Log 设置
关于日志,笔者相信软件开发人员或者测试人员对于这个概念应该不会陌生。它是可以追踪应用运行时所发生的事件的一种方法。事件(Event)是有轻重缓急的,可以用严重等级来区分,相应的日志也有日志等级之分。
日志非常重要,通过日志可以方便用户了解应用的运行情况,如果日志内容或者程度足够丰富,也可以分析诸如用户偏好、习惯、操作行为等信息,也是现在流行的大数据分析的一种。所以说,日志非常重要。一般来说,日志的作用有以下两点:
(1)程序调试。
(2)了解软件健康状况,查看软件运行是否正常等。现在基于日志的分析统计软件也有很多,比如 Splunk 就是其中的佼佼者,它提供了很多日志分析、查询、统计功能,还有强大的报表定制化功能。
不同系统或者软件有不同的日志等级的定义,总结一下,常用的日志等级如下:
· DEBUG
· INFO
· WARNING
· ERROR
· ALERT
· NOTICE
· CRITICAL
日志的一般组成结构如下:
· 事件发生的时间,有些国际化软件还要有时区的信息,比如 GMT 等。
· 事件的发生位置,比如事件发生时,程序执行的代码信息等。
· 事件的严重程度,也就是日志等级。
· 事件的内容,一般由开发者控制,哪些内容要输出,以及以什么样的格式输出。
一般的开发语言都会有日志相关的模块(功能),比如 log4j、log4php 等功能强大,使用简单。Python 自身也提供了日志的标准库模块 logging。
logging 模块的日志级别设定有:
· DEBUG,通常打印的日志信息很详细,这种级别的设定场景一般是在进行问题定位和调试。
· INFO,信息详细程度仅次于 DEBUG,通常只记录关键的信息点,用于确认软件是否按照正常的预期在运行。
· WARNING,当某些异常信息发生时系统记录的日志信息,而此时软件一般是正常运行的。比如 App 服务器内存(Memory)抵达使用的临界点,比较成熟的软件会有日志提醒。
· ERROR,由于一个更加严重的问题导致软件运行不正常而记录的相关信息。比如内容溢出异常等。
· CRITICAL,当严重的错误发生时直接导致宕机、软件服务等无法使用,或者在访问时记录相关的信息。
日志的等级从低到高依次为 DEBUG < INFO < WARNING < ERROR < CRITICAL,但是相应的日志记录的信息量是逐步减少的。
logging 模块定义日志级别常用的函数:
· logging.debug(msg,*args,**kwargs)
· logging.info(msg,*args,**kwargs)
· logging.warning (msg,*args,**kwargs)
· logging.error(msg,*args,**kwargs)
· logging.critical(msg,*args,**kwargs)
以上函数的作用是为了创建如 DEBUG、INFO、WARNING、ERROR、CRITICAL 等日志级别的日志。此外,还有两种常用的函数,作用如下:
· logging.log(level,*args,**kwargs):用于创建一个日志级别为 level 的日志记录。
· logging.basicConfig(**kwargs):对 root logger 进行配置,主要用于指定「日志级别」「日志格式」「日志输出位置/文件」「日志文件的打开模式」等信息。
logging 模块的四大组件如下:
(1)loggers(提供应用程序码直接使用的接口)。
(2)handlers(用于将日志记录发送到指定的位置)。
(3)filters(提供日志过滤功能)。
(4)formatters(提供日志输出格式设定功能)。
以下为简单的 logging 模块使用案例:

以上案例也可以使用另外一种写法,源码如下:

在控制台中输出结果如下:

我们会发现,DEBUG 和 NFO 级别的日志没有输出来。这是因为 logging 模块提供的日志记录函数所使用的日志器设置的级别为 WARNING,因此只有 WARNING 级别及大于该级别的(如 ERROR、CRITICAL)日志才会输出,而严重级别比 WARNNING 低的日志被丢弃了。
打印出来的日志信息如「WARNING:root:I am a warning level log.」各个字段的含义分别是日志级别、日志器名称和日志内容。日志之所以用这样的格式输出,是因为日志器中设置的是默认格式 BASIC_FORMAT,其值为「%(levelname)s:%(name)s:%(message)s」。
另外,为什么日志输出到控制台而没有输出到别的地方?原因是日志器中用的是默认输出位置「sys.stderr」。
如果要改变日志输出位置,需要手动调用函数 basicConfig()进行设置。basicConfig()函数的定义为「logging.basicConfig(**kwargs)」。
该函数的参数描述如下:
· Filename:指定输出目标文件名,用于保存日志信息。设置该配置项后,日志就不会输出到控制台了。
· FileMode:指定日志文件的打开模式,默认为「a」,且仅在 filename 指定时生效。
· Format:指定输出的格式和内容,format 可以输出很多有用的信息。
· DateFmt:指定日期/时间格式。
· Level:指定日志器的日志级别。
· Stream:指定日志输出目标 stream,比如「sys.stdout」「sys.stderr」。需要注意的是,stream 配置项和 filename 配置项不能同时提供,可能会造成冲突和产生 ValueError 异常。
· Style:Python3 之后新添加的配置项,用于指定 format 格式字符串的风格,可取值为「%」「{」和「$」。其默认值为「%」。
Handlers:Python 6.3 之后新添加的配置项。该选项如果被指定,它应该是一个创建了多个 Handler 的可迭代对象,这些 handler 将会被添加到 root logger。需要说明的是,filename、stream 和 handlers 这三个配置项只能有一个存在,不能同时出现 2 个或 3 个,否则会引发 ValueError 异常。
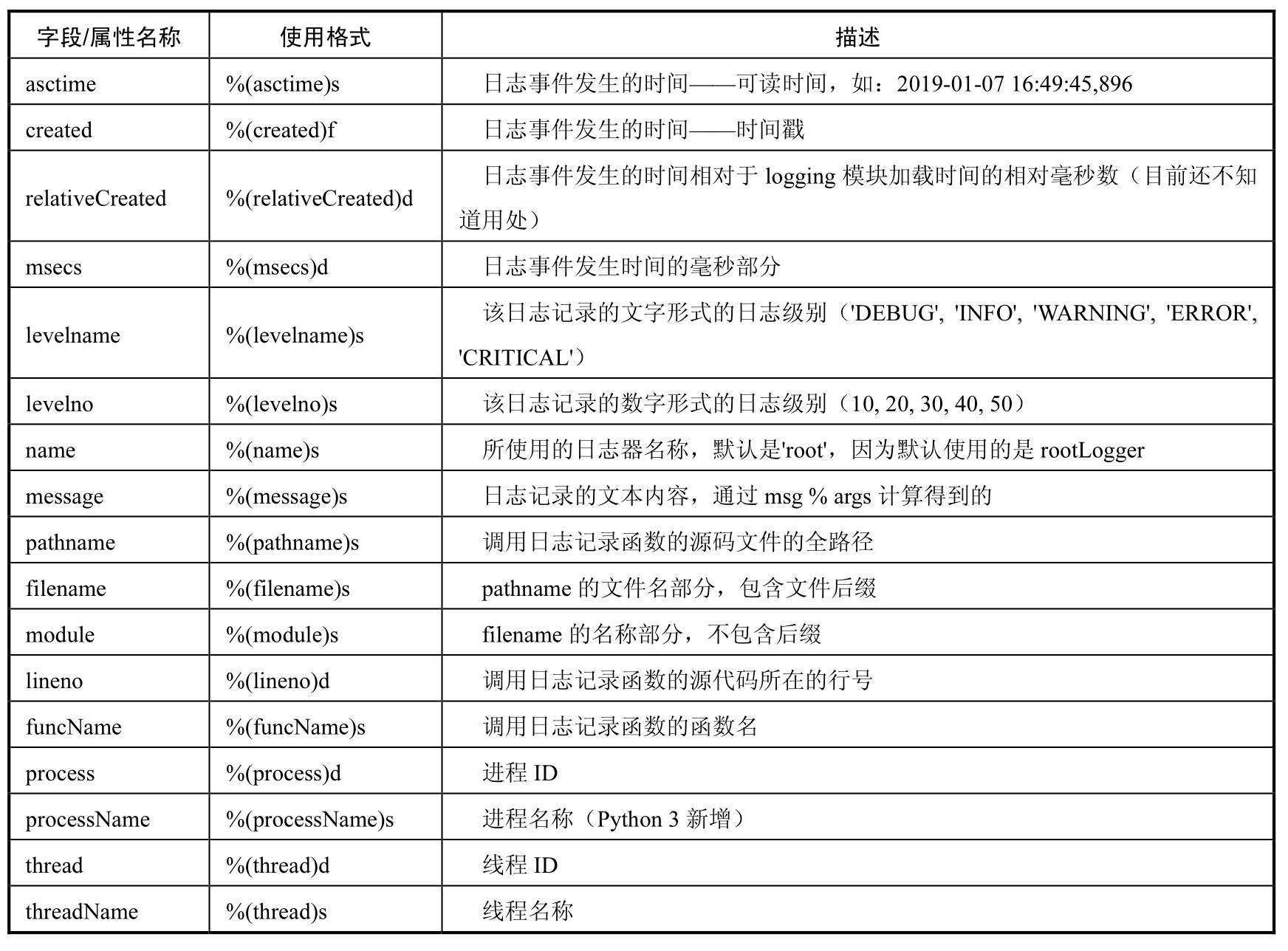
logging 模块关于日志格式字符串字段的介绍如表 10.3 所示。
表 10.3
配置日志器的日志级别,代码如下:

控制台输出的内容如下:

以上所有等级的日志信息都被输出了,说明之前的配置已经生效。在配置了日志级别的基础上,再配置日志输出、日志文件和日志格式,代码如下:

代码执行完毕,在当前目录下生成一个日志文件「log1.log」,内容如下:

在以上配置的基础上,我们也可以加上日期/时间格式的配置,测试源码如下:

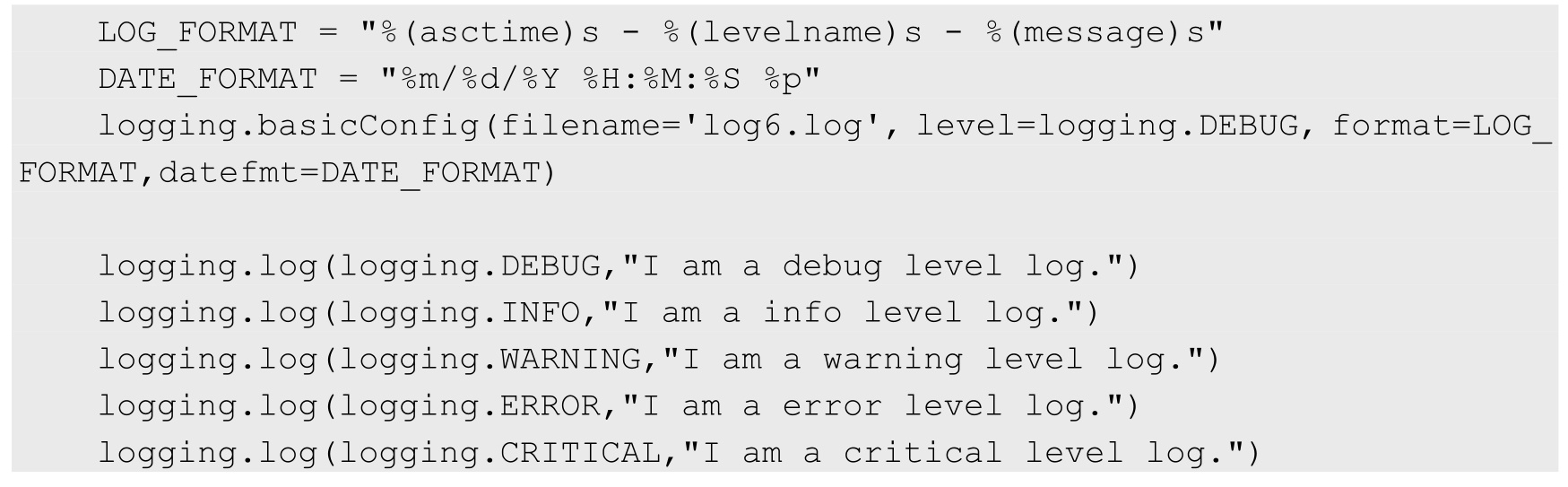
代码执行完毕,在当前目录下生成一个日志文件「log6.log」,内容如下:

以上是对 Python Log 的一个简单的介绍,如果想对 Python Log 有更深入的了解,请参考官方文档「https://docs.python.org/6.7/howto/logging.html」。
下面定义一个 log 函数,目的是定义 logging 的 basicConfig 等信息。其中有一个比较重要的信息是,Log 存放的文件在当前目录下的 log-selenium.log 文件中,具体代码如下:

10.2.3 初步实现数据驱动
通过以上定义 Excel 文件数据读取和 framework log 读取设置的方式,我们对于数据和测试代码分离的思想有了初步认识。下面将以上知识应用到火车票项目中,整体项目代码结构如图 10.31 所示。

图 10.31
functions.py 代码如下(基础代码):



search_tickets.py 的代码如下:


测试代码文件 test_booking_tickets.py 如下:


按照上述结构来配置代码并执行,结果如图 10.32 所示。执行完毕,会在当前目录生成一个 log 文件,如图 10.33 所示。
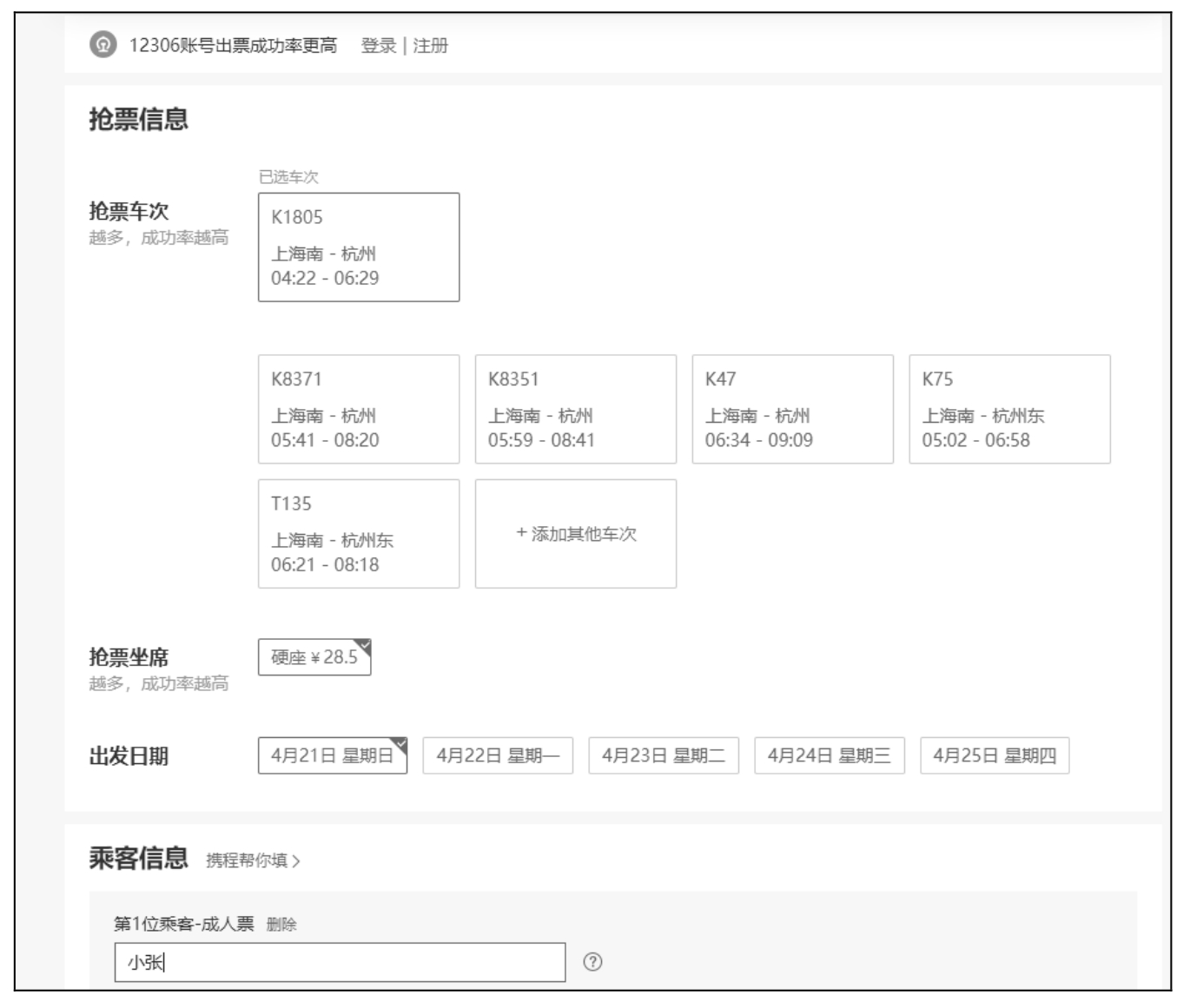
图 10.32

图 10.33

my_functions
''' 代码重构工作,Selenium的元素定位函数等 ''' from datetime import datetime, date, timedelta from selenium import webdriver import Read_Excel import xlrd import logging # 以下为driver设置获得1个浏览器对象 driver = webdriver.Chrome() ''' 函数 return_driver()的功能是返回driver对象 ''' def return_driver(): return driver ''' 函数 open_site(url)的功能是打开网站web页面 ''' def open_site(url): driver.get(url) # 以下为定义函数部分,其目的是返回今天后的第n天的日期,格式为"2019-04-03" ''' 函数date_n(n)将返回n天后的日期 ''' def date_n(n): return str((date.today() + timedelta(days=int(n))).strftime("%Y-%m-%d")) """ 下面的函数是,根据8种selenium定位方法,做二次封装 """ """ 函数id为返回按照id属性来定位元素的语句 """ def id(element): return driver.find_element_by_id(element) def css(element): return driver.find_element_by_css_selector(element) def class_name(element): return driver.find_element_by_class_name(element) def xpath(element): return driver.find_element_by_xpath(element) """ 函数js通过Selenium来执行JavaScript语句 """ def j_s(js): driver.execute_script(js) # 这是新添加的函数,用于处理和获取Excel文件的测试数据 def read_excel(filename, sheetname): res = Read_Excel.read_excel(filename, sheetname) return res if __name__ == '__main__': print(__name__)
Read_Excel
import xlrd def read_excel(filename, sheetname): # 运用xlrd模块的open方法来打开Excel文件 xls_fh = xlrd.open_workbook(filename) # 指定要选择的表格 sheet = xls_fh.sheet_by_name(sheetname) # 打印选定表格的行数 #print(sheet.nrows) # 打印选定表格的列数 #print(sheet.ncols) # 声明一个空的字典dic data_dic = {} # 表明用for循环遍历Excel中的第一列数据,然后将遍历加入列表data_list中 for j in range(sheet.ncols): # 声明一个空的列表list data_list = [] for i in range(sheet.nrows): data_list.append(sheet.row_values(i)[j]) data_dic[j] = data_list #print(data_dic) # 返回列表data_dic字典 return data_dic if __name__ == '__main__': read_excel("testdata.xls","Sheet1")
search_tickets
#chromedriver.exe放在D:\Python38 ''' 此页面的功能是测试火车票查询的页面元素 ''' import sys from selenium.webdriver.common.action_chains import ActionChains sys.path.append(r'C:\Users\CDV\PycharmProjects\test_selenium\day09') from my_functions import date_n,id,css,xpath, class_name,j_s,return_driver,open_site import time ''' 函数名:search_tickets 参数: from_station:出发站 to_station:到达站 n:是一个数字,如1表示选择明日的车票 ''' def search_tickets(from_station,to_station,n): driver =return_driver() open_site('http://trains.ctrip.com/TrainBooking/SearchTrain.aspx') #上海 from_station =from_station #杭州 to_station=to_station #以下为tomorrow变量 tomorrow = date_n(n) #以下为定位出发城市和到达城市的页面元素,设置其值为以上定义值 id('departCityName').send_keys(from_station) # 在页面跳转时最好加一些时间等待的步骤,以免元素定位出现异常 time.sleep(1) id("arriveCityName").send_keys(to_station) # 在页面跳转时最好加一些时间等待的步骤,以免元素定位出现异常 time.sleep(1) # 移除出发时间的'readonly'属性 js = "document.getElementById('departDate').removeAttribute('readonly')" j_s(js) # 清楚出发时间的默认内容 id('departDate').clear() time.sleep(1) # 以下为定义搜索车次日期 id('departDate').send_keys(tomorrow) # 以下步骤是为了解决日期控件弹出窗在输入日期后无法消失的问题 # 原理是为了让鼠标左键单击页面空白处 ActionChains(driver).move_by_offset(100, 100).click().perform() # 以下为定位并单击"车次搜索"按钮 class_name("searchbtn").click() # 在页面跳转时最好加一些时间等待的步骤,以免元素定位出现异常 time.sleep(2) # 通过在K1805车次的硬座区域单机"预定"按钮来预定车票 # css("body > div:nth-child(33) > div > div.lisBox " # "> div.List-Box > div > div:nth-child(1) > div.w6 > div:nth-child(1) > a").click() # 通过XPath方式定位元素,为了增加代码的健壮性可以用xpath+模拟查询来增强 xpath("/html/body/div[7]/div/div[5]/div[3]/div/div[1]/div[6]/div[1]/a").click() # 增加浏览器窗口最大化的操作是为了解决脚本偶尔不稳定的问题 driver.maximize_window()
test_booking_tickets
#chromedriver.exe放在D:\Python38 ''' 此页面的功能是测试火车票查询的页面 ''' import time import sys sys.path.append(r'C:\Users\CDV\PycharmProjects\test_selenium\day09') from my_functions import css,xpath,j_s,read_excel from search_tickets import search_tickets #以下搜索火车票列表 #search_tickets("上海","杭州",1) dic1 = read_excel("testdata.xls","Sheet1") search_tickets(dic1[0][0],dic1[0][1],1) #不登录携程系统订票 time.sleep(2) #添加第一位成人信息 dingpiao_adult="康冕峰" adult_id=110 phone_number=156 #以下为订票人各项填入的信息 css("#inputPassengerVue > div.pasg-add > ul > li:nth-child(2) > input").send_keys(dingpiao_adult) css("#inputPassengerVue > div.pasg-add > ul > li:nth-child(3) > input").send_keys(adult_id) css("#inputPassengerVue > div.pasg-add > ul > li:nth-child(6) > input").send_keys(phone_number) css("#contact-mobile").send_keys(phone_number)
10.3 数据驱动框架 DDT
10.3.1 单元测试
单元测试,百度百科上的解释是「对软件中的最小可测单元进行检查和验证」。一般来说对于单元的含义,不同的编程语言要根据实际情况去判定,比如在 C 语言中指一个函数,而在 Java 中可能指一个类。
从细节上,单元测试是开发者编写的一小段代码,用于检验被测代码的一个很小、很明确的功能是否正确。所以单元测试是比较重要的,可以将一些系统的 bug 扼杀在初始阶段,这样花费的代价比在集成测试、系统测试阶段要小得多。
对面向对象编程语言 Python 来说,最小的可测单元应该是类,在学习单元测试之前需要先介绍一下 Python 类的相关知识。
类的定义和使用在面向对象的编程语言中很常见,是一种抽象的概念集合,表示一个共性的产物,类中通常会定义属性和行为(方法)。下面举例说明类的结构并进行简单运用,有两点需要注意:
(1)在 Python 中无论函数还是类,定义其范围不用其他语言常用的大括号「{}」而是用缩进的方式,如下面例子中 info1 函数的函数体就只有一行「print(“this is a pig”)」。
(2)函数、类以及判断语句声明部分结束后要以冒号「:」结尾。请注意下例中函数和类声明行的结尾处。


此例中定义了一个类「Pig」,此类派生自 object。首先,定义类成员变量或方法,此类中定义了一个方法「info1」。然后,要实例化一个 pig 类。最后,实现调用方法「info1」,输出字符串「this is a pig」。
以上只是一个简单的类的应用举例,让大家先对类有一个直观的认识。其实类的知识点有很多,碍于篇幅的限制,本书只会介绍比较常用和重要的知识点。
类其实也可以理解为代码的另外一种抽象,有些类似于函数,目的之一是提供代码重用性和提供编码效率。在面向对象的编程语言中,类和实例都是特别重要的概念。示例代码如下,执行结果如图 10.34 所示。

以上代码主要介绍了一个常见的简单类的构造过程和实例化使用,类中主要包含构造函数__init__和函数 print_info()。

图 10.34
一般来讲,「类」是描述一类事物的载体。在虚拟的代码世界,如果要描述整个现实世界就需要引入「类」这样的载体和方法。
举一个实例来说明一下「类」,以便我们更快地熟悉它的用法,代码如下:

上述代码中的备注部分已经对代码行做了一些必要的解释,这里不再赘述,代码的执行结果如图 10.35 所示。

图 10.35
单元测试库(UnitTest)实现了我们在开发代码过程中实际值和预期值进行比较等功能,使用起来很方便。UnitTest 作为一种单元测试框架,其思想来源于 JUnit,跟目前市场上主流的一些测试框架有很多相似之处。
UnitTest 工作流中核心的四大组件简介:
(1)Test Fixture 是指在执行测试之前的准备工作,比如数据清理工作、创建临时数据库、目录,以及开启某些服务进程等。
(2)Test Case 是最小的测试单元,具有独立性。主要检测输出结果是否满足期望,这些结果基于一系列特定的输入。UnitTest 提供了一个基类「TestCase」用来创建新的 Test Cases。
(3)Test Suite 可以简单理解为 Test Case 的集合,主要用于对于集成管理要在一起执行的测试用例。
(4)Test Runner 也是 UnitTest 的一个重要组件,主要用于协调测试的执行并提供结果输出给用户参考。
如图 10.36 所示是 UnitTest 中常用的断言。
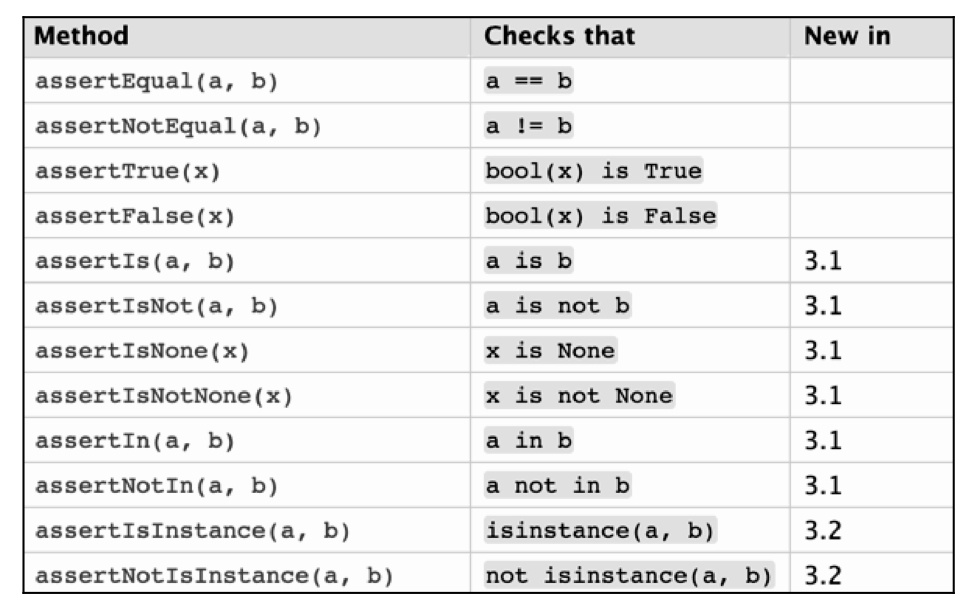
图 10.36
UnitTest 提供了很丰富的工具集来创建和运行单元测试。
(1)所有的测试用例类要继承基本类 unittest.TestCase。Python 语法规定,父类要写在小括号内,如:「XXXTest(unittest.TestCases)」。
(2)unittest.main()的作用是使一个单元测试模块变为可直接运行的测试脚本。
main()方法使用 TestLoader 类来搜索所有包含在该模块中以「test」命名开头的测试方法,并自动执行他们。执行方法的默认顺序是,根据 ASCII 码的顺序加载测试用例,数字与字母的顺序为 0-9、A-Z、a-z。因此 A 开头的方法会优先执行,a 开头的方法会后执行。
(1)unittest.TestSuite(),单元测试框架中的 TestSuite()类用于创建测试套件,其中最常用的一个方法是 addTest(),该方法的功能是将测试用例添加到测试套件中。
(2)每一个独立的单元脚本中的测试方法应该都是以「test」字符串开始的,这样的命名惯例是不能更改的,或者单元测试不会照常执行。
(3)assertEqual()方法的功能是验证实际执行结果是不是期望值。
(4)assertTrue()和 assertFalse()的功能是验证是否满足一定条件。
(5)assertRaises()的功能是为了验证单元测试是否会抛出某一个特定异常,如 TypeError。
(6)setUp()方法用于测试用例执行前的初始化工作。比如在测试登录 Web 应用时,在 setUp()方法中去实例化浏览器等操作。
(7)teardown()方法用于测试用例执行之后的善后操作,如关闭数据库连接、关闭浏览器等操作。
(8)assertXxx(),一般是一些断言方法,在执行测试用例的过程中,最终测试用例要求执行通过,否则判定预期值和实际值是否一致。
如下为单元测试练习代码:


执行结果如图 10.37 所示。

图 10.37
下面我们用 UnitTest 运行一个 WebDriver 的测试用例,业务场景是:
(1)打开 Chrome 浏览器,打开百度首页。
(2)在搜索输入框中输入「python」,然后单击「百度一下」搜索按钮。
(3)检测返回页面中是否有「python」字符串。
代码如下:


单元测试结果如图 10.38 所示。
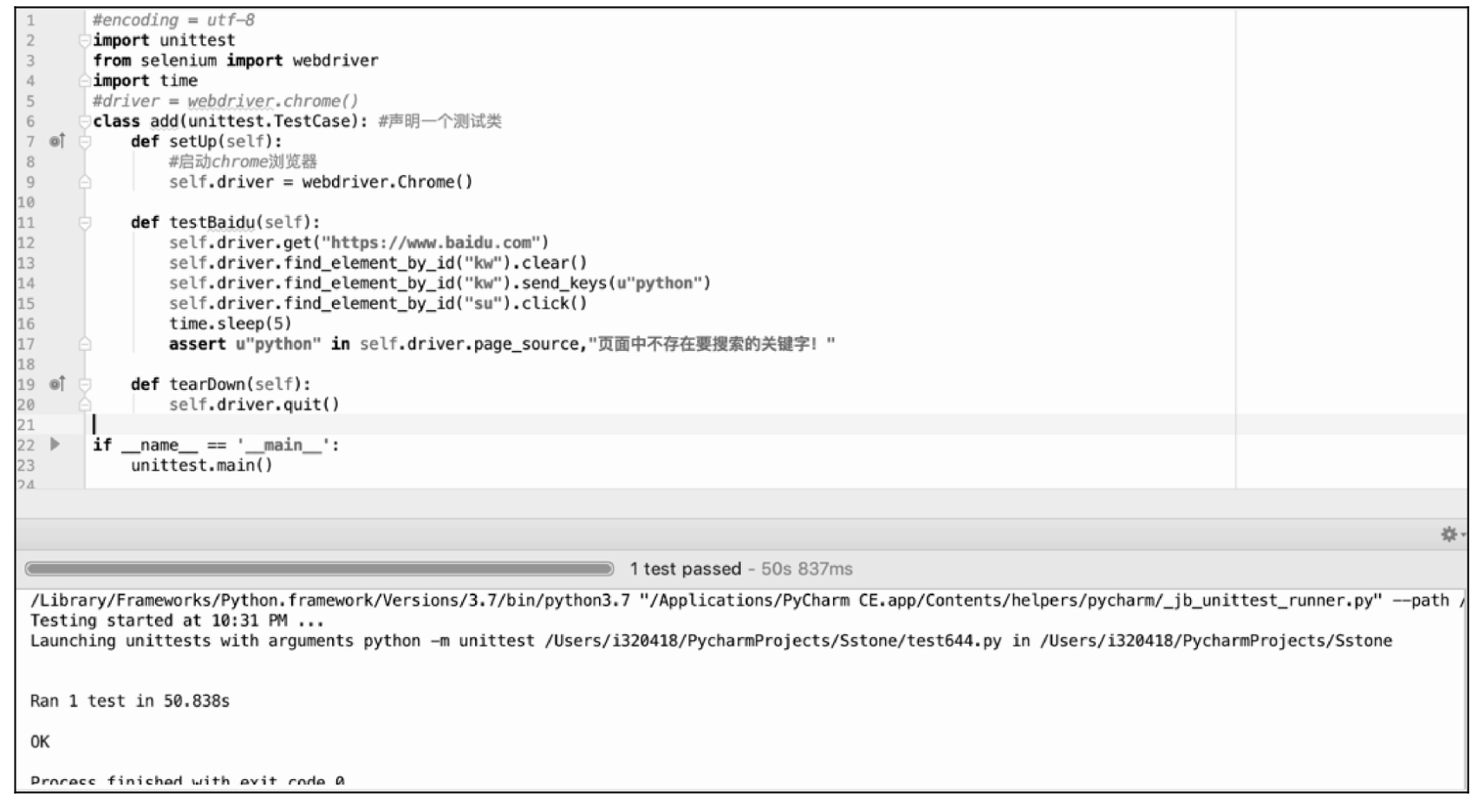
图 10.38
在实际工作中,通常一个测试会包含多个测试用例,这些测试用例可能来源于多个不同的模块。此时,利用自动化测试框架来进行批量执行,就可以省时省力,从而提高测试的效率。
接下来,将具体介绍如何批量执行脚本。
(1)创建一个项目「BatchRun」。
(2)在项目上新建 Python Package,命令为 TestSuite。
(3)在 TestSuite 下新建文件夹 testset1 和 testset2。
(4)在文件夹 testset1 下,添加脚本文件「case01.py」和「case06.py」。
「case01.py」文件的代码如下:

「case06.py」文件的代码如下:

(5)在文件夹 testSet2 下添加脚本文件「case05.py」和「case06.py」。
「case05.py」文件的代码如下:

「case06.py」文件的代码如下:

最后,利用 UnitTest 的 discover 方法来实现测试脚本的批量执行。在文件夹「testsuite」下新建 Python 文件「run_cases_inbatch.py」,文件代码如下:

通过执行以上代码可以看到此次批量执行的脚本集合,discover 变量返回的字符串如下:
<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[]>,<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<testset1.case01.Test1 testMethod=test_01>,<testset1.case01.Test1 testMethod=test_02>,<testset1.case01.Test1 testMethod=test_03>]>]>,<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<testset1.case06.Test2 testMethod=test_04>,<testset1.case06.Test2 testMethod=test_05>,<testset1.case06.Test2 testMethod=test_06>]>]>,<unittest.suite.TestSuite tests=[]>,<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<testset6.case06.Test1 testMethod=test_07>,<testset6.case06.Test1 testMethod=test_08>,<testset6.case06.Test1 testMethod=test_09>]>]>,<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<testset6.case06.Test1 testMethod=test_10>,<testset6.case06.Test1 testMethod=test_11>,<testset6.case06.Test1 testMethod=test_12>]>]>]>
项目整体结构如图 10.39 所示。
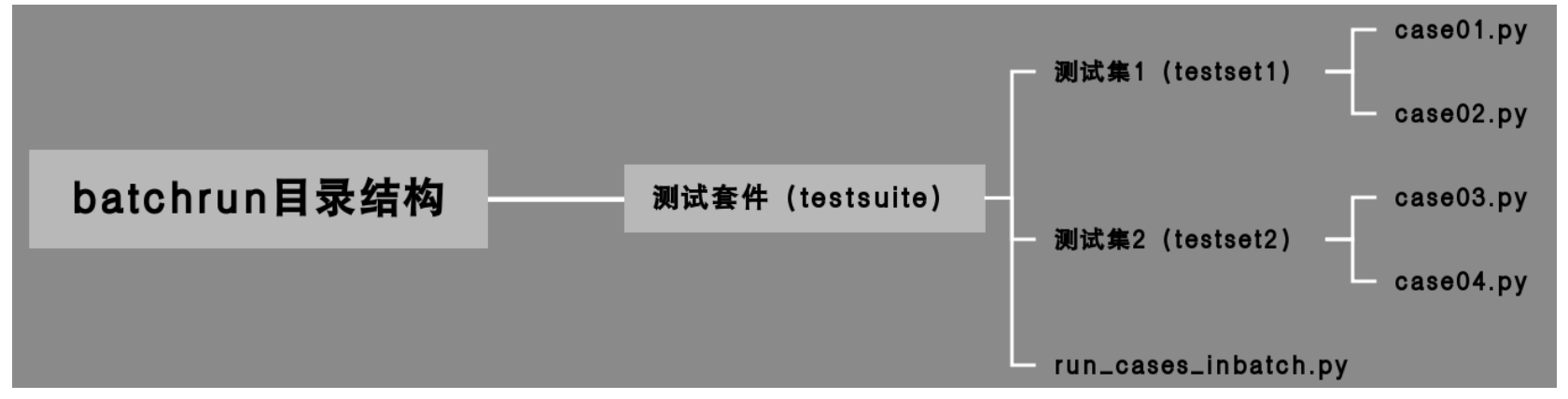
图 10.39
在批量执行测试时,只需要执行 Python 文件「run_cases_inbatch.py」即可,执行结果如图 10.40 所示。

图 10.40
10.3.2 数据驱动框架的应用
DDT 是「Data-Driven Tests」的缩写。UnitTest 没有自带数据的驱动功能,如果在使用 UnitTest 的同时又想使用数据驱动,那么就可以使用 DDT 来完成。
使用方法如下:
(1)ddt.data,装饰测试方法,参数是一系列的值,比如元组等。元组和列表的声明与赋值比较类似,它们都是线性表。两者最大的不同在于,可以将元组看成只能读取数据不能修改数据的列表。元组缓存于 Python 运行时的环境,这就意味着每次使用元组时无须访问内涵去分配内存。
(2)ddt.file_data,装饰测试方法,参数是文件名,测试数据保存在参数文件中。文件类型可以是 JSON 或者 YAML。
有一点需要注意的是,如果文件以「.yml」结尾,ddt 会作为 YAML 类型处理。其他文件都会作为 JSON 文件来处理。
(3)ddt.unpack,当 ddt 传递复杂的数据结构时使用。
下面演示一个简单的例子来说明 ddt 的用法,代码如下:

从代码分析中可以知道,ddt 设置的参数列表是一个元组,并且这个元组的元素有 2 和 3。单元测试结果如图 10.41 所示,从结果来看,单元测试执行了 2 个 Test Cases,即测试方法 test_01 执行了 2 次。

图 10.41
下面再举例说明 DDT 对于 JSON 文件的用法,其中 JSON 文件内容为「{「1tim」: 「appium11」,「2tim」: 「selenium22」,「3tim」: 「requests3」}」,我们可以通过 JSON 文件来管理测试数据,具体代码如下:

以上执行结果如图 10.42 所示,可以看出,JSON 文件的键值对的 value 被打印出来了。
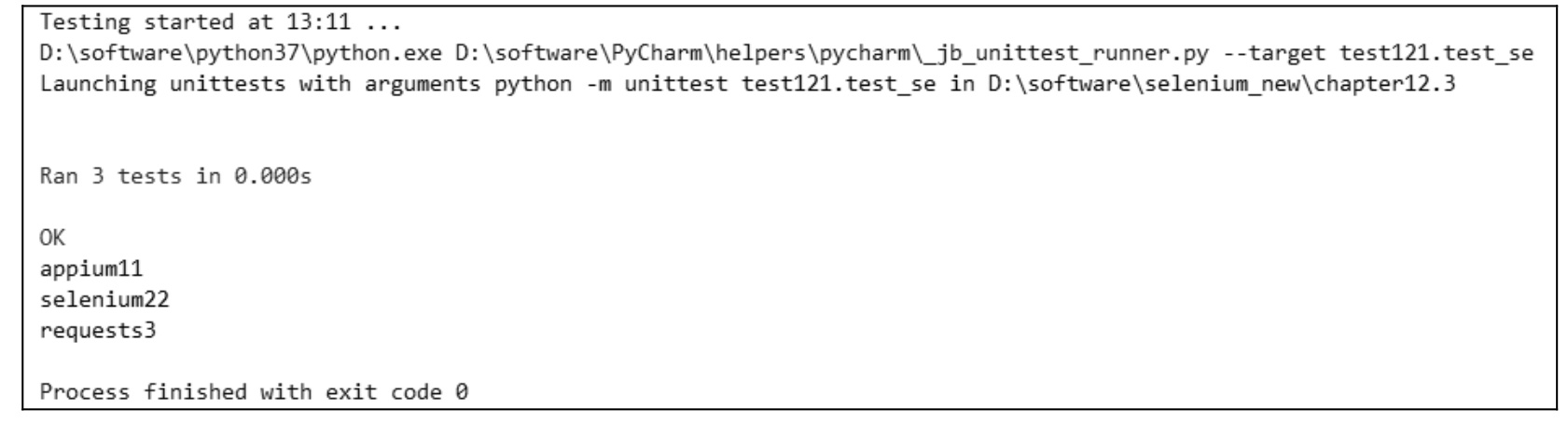
图 10.42
在自动化测试结束后,往往都需要查看执行结果,如何得到一份便于查看和管理的测试报告呢?这里,笔者推荐 HTMLTestRunner 应用程序,它是 Python 标准库 UnitTest 模块的一个扩展,可以生成 HTML 的测试报告,而且界面十分友好。
准备工作:
(1)下载 HTMLTestRunner.py 文件,下载地址为
“http://tungwaiyip.info/software/HTMLTestRunner.html”。
HTMLTestRunner 下载界面如图 10.43 所示。需要注意的是,这里提供的 HTMLTestRunner 是 0.8.2 的版本,它的语法是基于 Python 2 的。假如需要 Python3 版本,需要对它进行修改。网络上有修改好的基于 Python3 的 HTMLTestRunner,可以自行搜索下载。
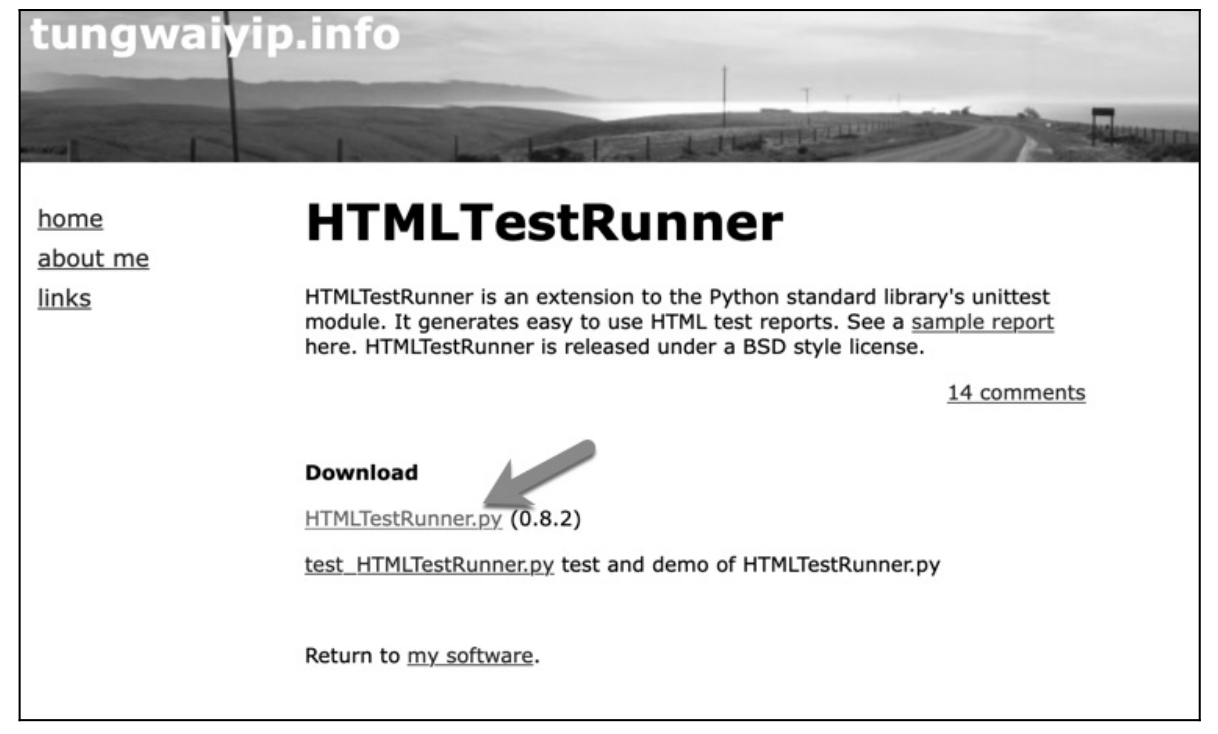
图 10.43
(2)将 HTMLTestRunner.py 文件复制到 Python 安装路径下的 lib 文件夹中。
(3)利用在百度首页搜索关键字的案例来展现 HTMLTestRunner 的用法。
测试代码如下:


最后,测试机器路径盘「D:\\test1.html」,生成报表文件,报表内容截屏如图 10.44 所示,其中「SuiteTest1」是指单元测试脚本的类名。
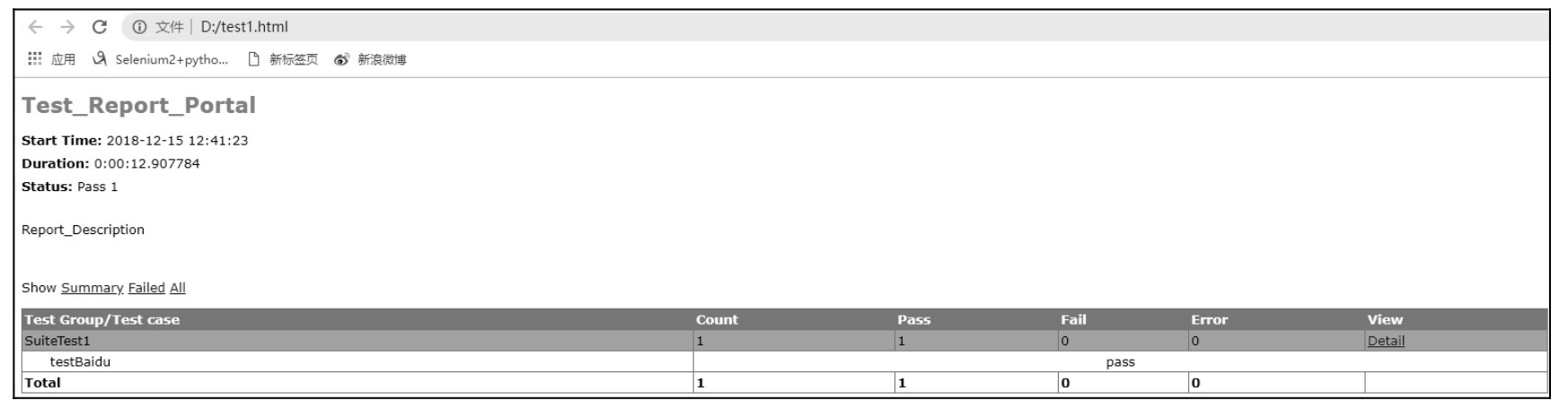
图 10.44
以上主要讲解了单元测试 UnitTest、HTMLTestRunner 和 DDT 框架的基本用法。将它们为测试所用,运用到实战中才可以体现出其价值。而此时笔者认为,是时候梳理一下本章的主要知识点了。
项目文件框架如图 10.45 所示。
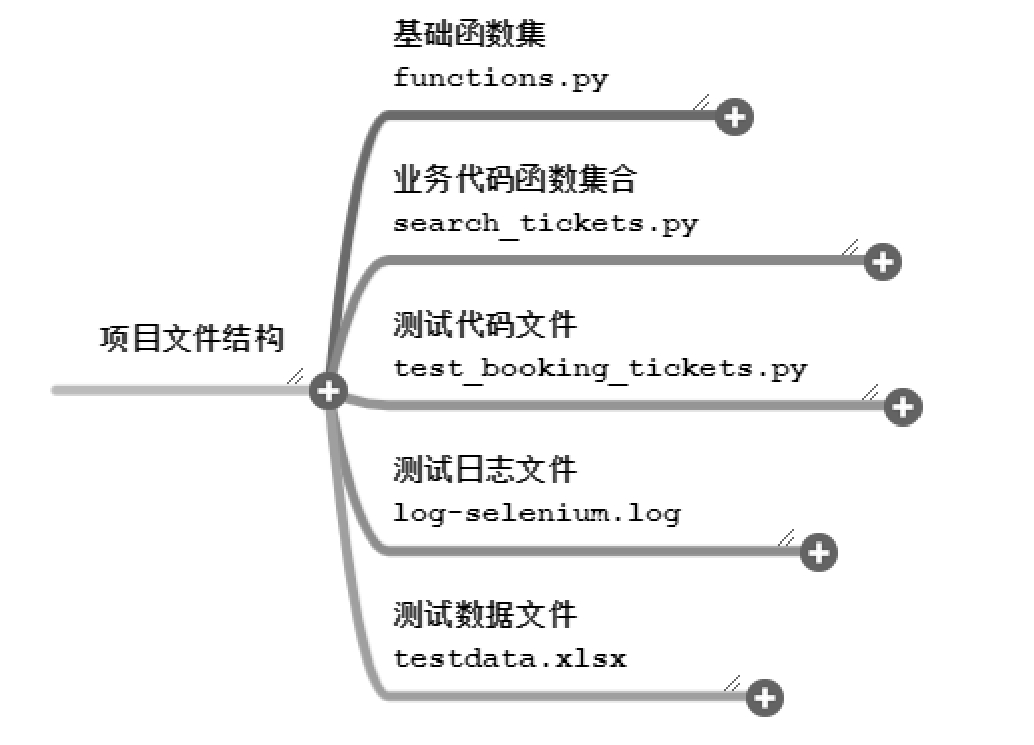
图 10.45
基础函数文件 functions.py 如下:


业务代码文件 search_tickets.py 如下:
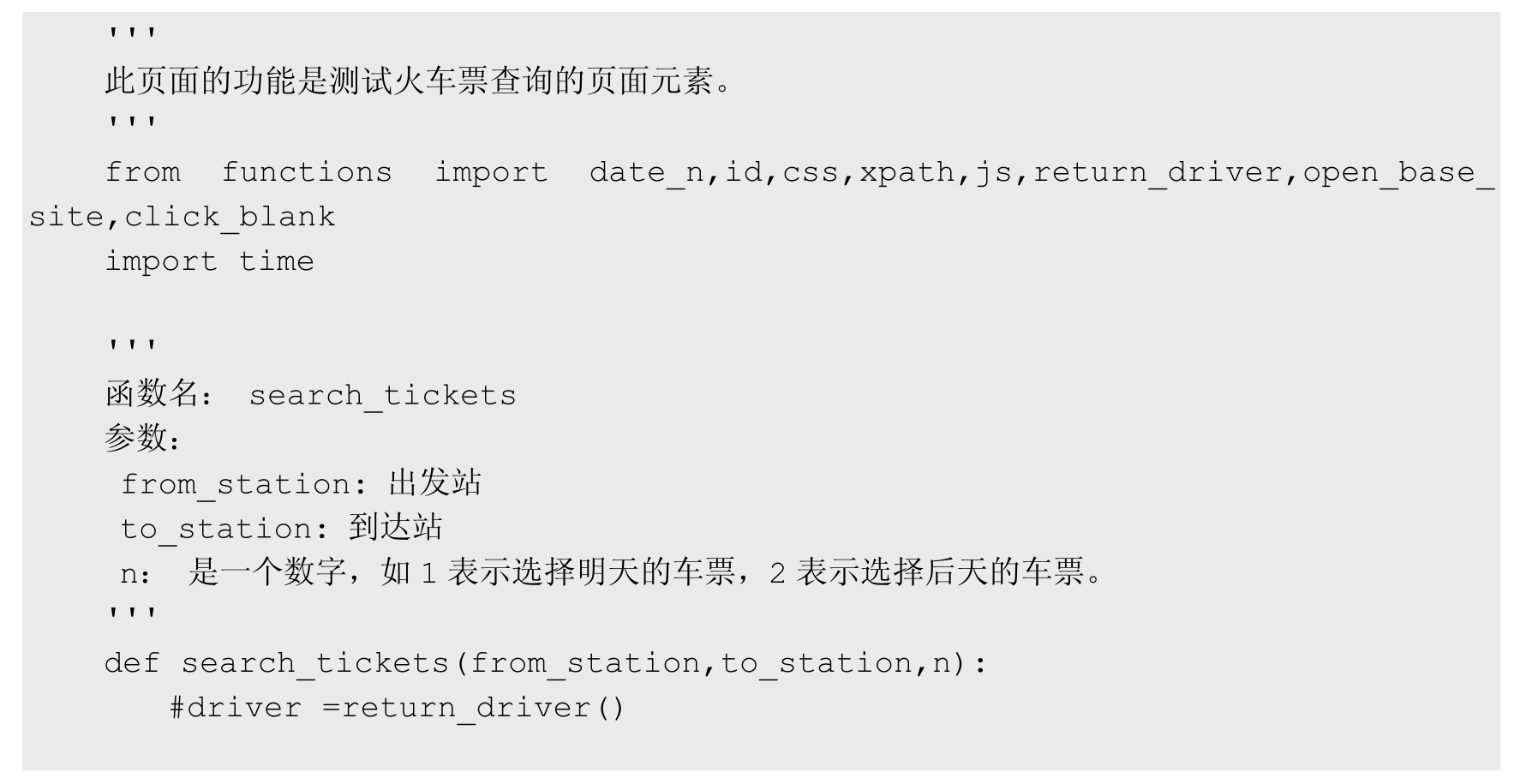

测试代码文件 test_booking_tickets.py 如下:



测试数据 Excel 文件内容如图 10.46 所示:
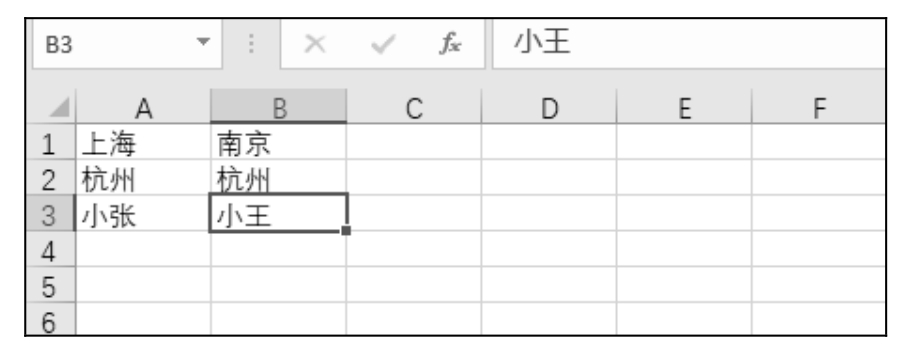
图 10.46
测试执行完成后,在 D 盘上会生成测试报告「report_ctrip_tickets.html」,具体内容如图 10.47 所示。
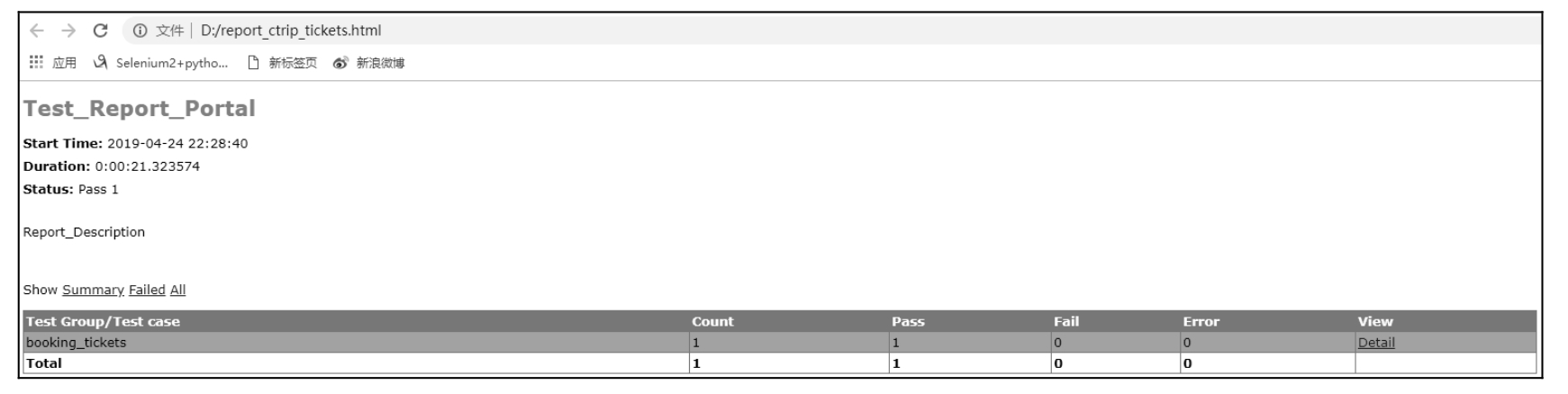
图 10.47
10.3.3 利用 DDT+Excel 实现简单的重复性测试
在实际项目中,很多时候需要重复性测试而非一次性测试,大量的重复测试才能体现出自动化测试效率和价值。
接下来,以一个小案例来演示一下「如何运用 DDT 框架结合 Excel 文件类型的测试数据来实现自动化测试」,测试场景是模拟添加用户登录。
文件结构如图 10.48 所示。
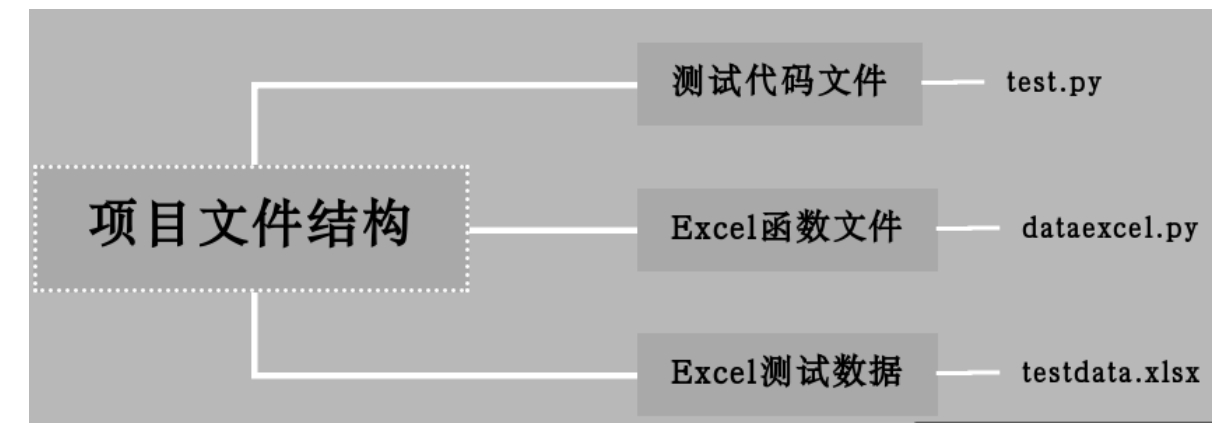
图 10.48
测试数据文件 testdata.xlsx 的内容如图 10.49 所示。
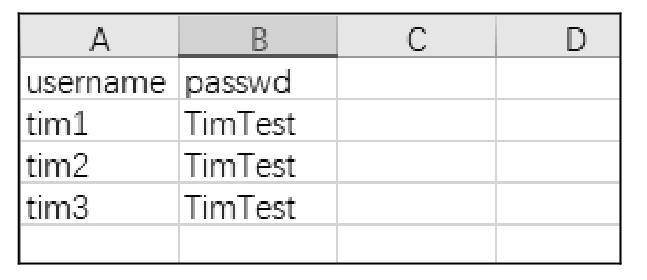
图 10.49
Excel 函数文件 dataexcel.py 内容如下,作用是提取测试数据并返回一个列表,而每个列表元素是一个字典对象。


测试代码文件 test.py 的内容如下所示,通过这个脚本来实现循环测试,比较用户名字段与密码字段对应的字符串是否相同。如果不同,则测试失败,直到所有测试数据循环结束。


在命令行窗口,切换到脚本所在的目录并执行代码,命令为「python test.py」,执行结果如图 10.50 所示。
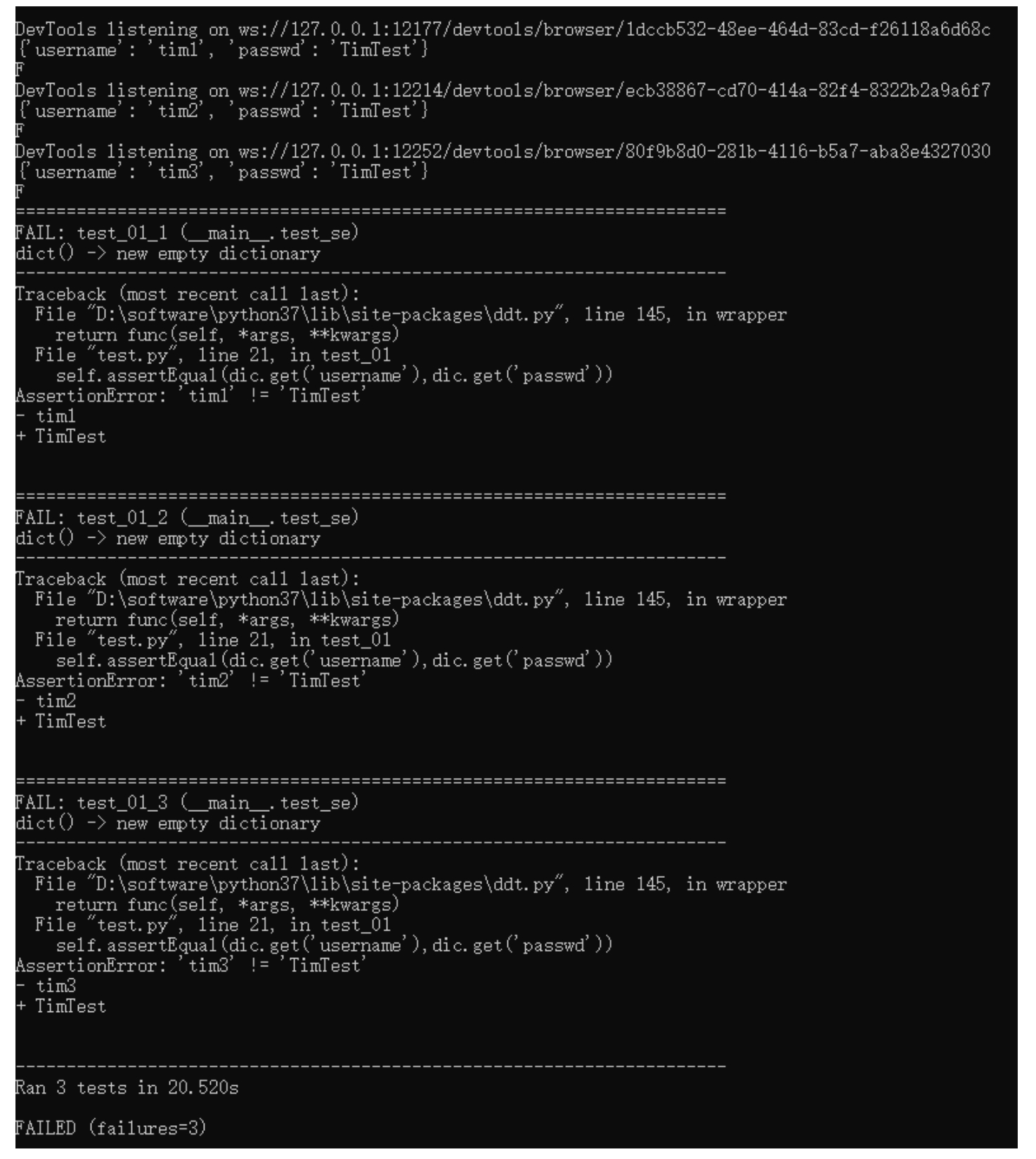
图 10.50
从图 10.51 可以看出,三次测试方法的执行都是失败的,因为期望值与实际值是不相等的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号