


5.2 Selenium 八大定位 Selenium 3+Python 3 自动化测试
5.2 Selenium 八大定位
以上简要地介绍了本篇 Python 涉及的基础知识,其他一些基础知识分散在项目篇中进行讲解。Python 编程需要的技能需要在实践中得到充实和完善。
在 Selenium 中根据 HTML 页面元素的属性来定位。在 Web 测试过程中常用的操作步骤如下:
(1)定位网页上的页面元素,并获取元素对象。
(2)对元素对象实施单击、双击、拖曳或输入值等操作。
Selenium 提供了 8 种不同的定位方法,分别通过 id、name、xpath、class name、tag name、link_text、partial link text 及 css selector 进行定位。具体的使用细节会在本节中详细介绍。
5.2.1 id 定位
在正式开始讲解 Selenium 元素定位之前,需要对浏览器的驱动程序文件进行全局设置或管理。一种比较简单方便的方式是,将 Chrome 浏览器驱动文件「chromedriver.exe」放到项目目录中,这样就不需要定义驱动文件路径(例如:path=「C:\Users\lijin\AppData\Local\Google\Chrome\Application\chromedriver.exe」)。以 Chrome 浏览器为例,初始化的代码可以简化为「driver = webdriver.Chrome()」。本书之后的相关写法,也以这种方式为准。
HTML Tag 的 id 属性值是唯一的,故不存在根据 id 定位多个元素的情况。下面以在百度首页搜索框输入文本「python」为例。搜索框的 id 属性值为「kw」,如图 5.18 所示。

图 5.18
代码如下,最后一行表示通过「find_element_by_id」方法来定位搜索框。

#学习有疑问请联系作者 from selenium import webdriver #要把chromedriver.exe放到D:\Python38目录中 browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.find_element_by_id('kw').send_keys('python')
代码运行后,在百度搜索框输入「python」,如图 5.19 所示。
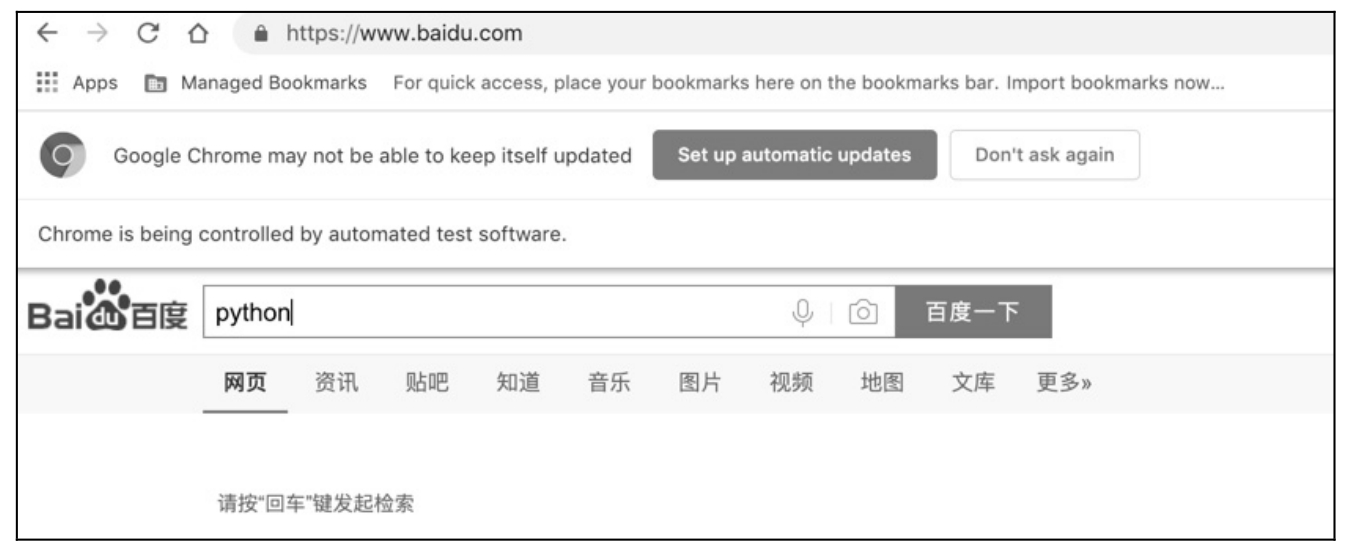
图 5.19
5.2.2 name 定位
以上百度搜索框也可以用 name 来实现,如图 5.18 所示,其 name 属性值为「wd」,方法「find_element_by_name」表示通过 name 来定位,代码如下:

from selenium import webdriver #要把chromedriver.exe放到D:\Python38目录中 browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.find_element_by_name('wd').send_keys('python')
运行后效果如图 5.20 所示。
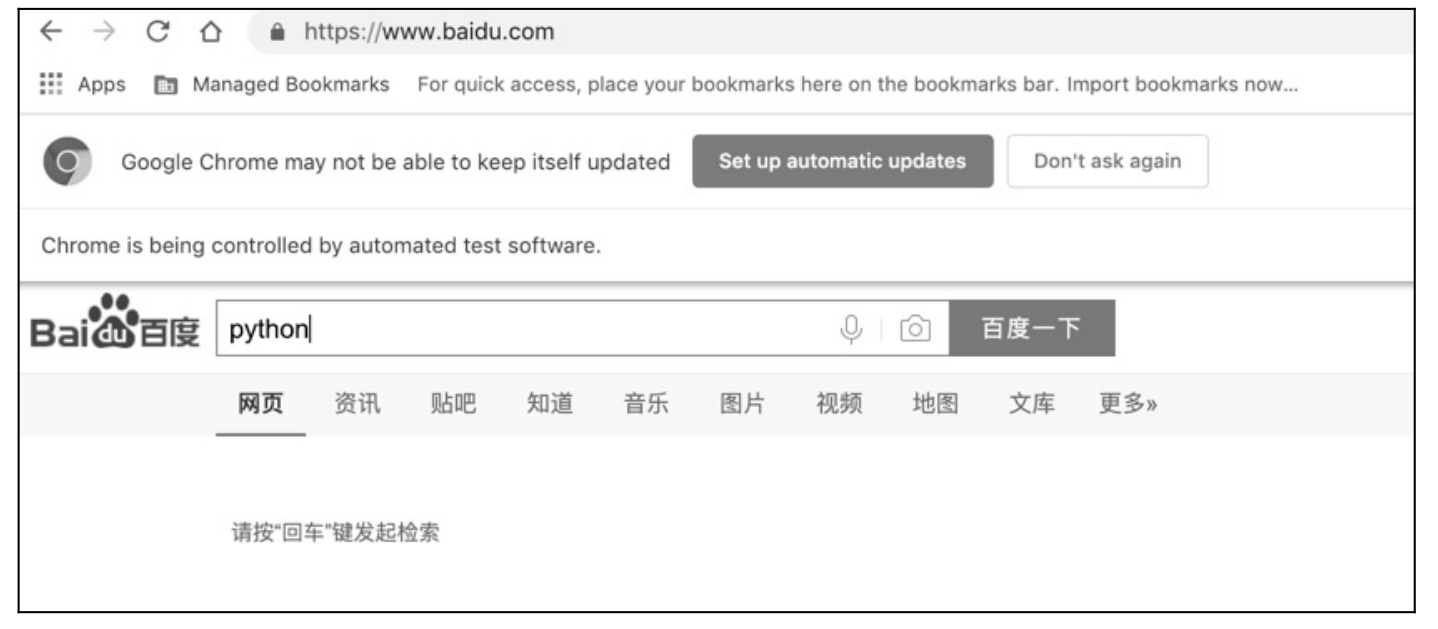
图 5.20
注意:用 name 方式定位需要保证 name 值唯一,否则定位失败。
5.2.3 class 定位
以百度首页搜索框为例,如图 5.18 所示,其 class 属性值为「s_ipt」,「find_element_by_class_name」表示通过 class_name 来定位,代码如下:

from selenium import webdriver #要把chromedriver.exe放到D:\Python38目录中 browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.find_element_by_class_name('s_ipt').send_keys('python')
运行后,在百度搜索框输入字符「python」,如图 5.21 所示。
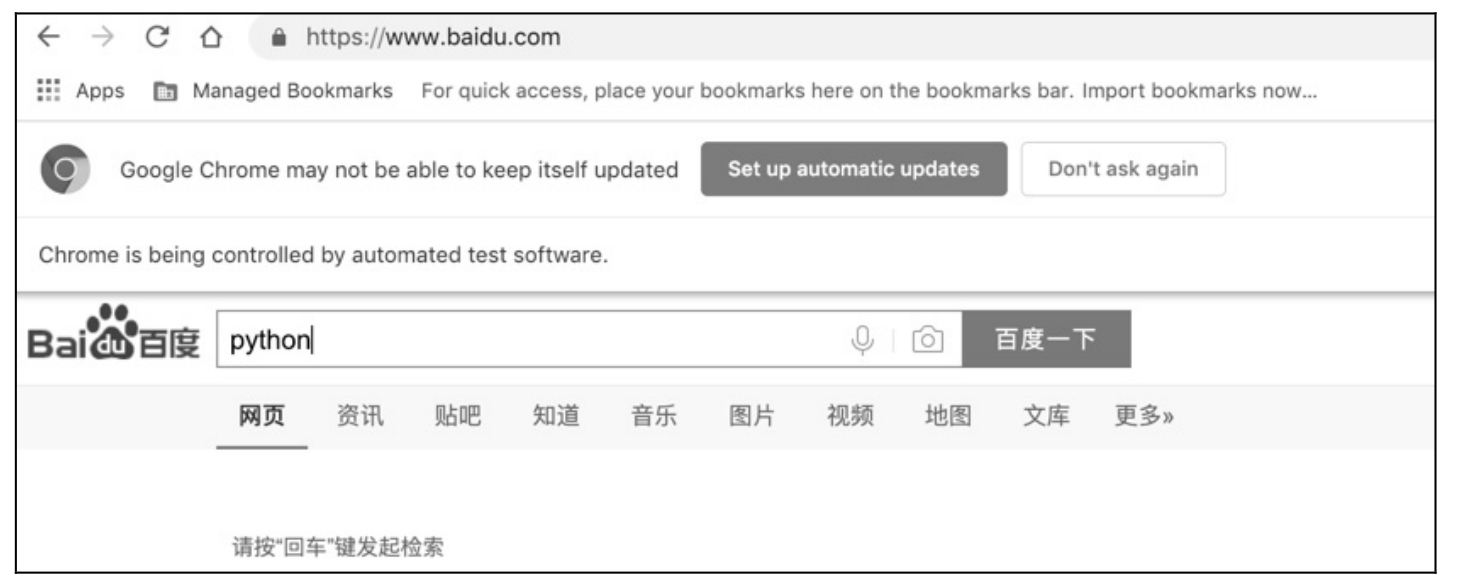
图 5.21
5.2.4 link_text 定位
link_text 是以超链接全部名字作为关键字来定位元素的。以百度首页「新闻」超链接为例,如图 5.22 所示,关键字为「新闻」。
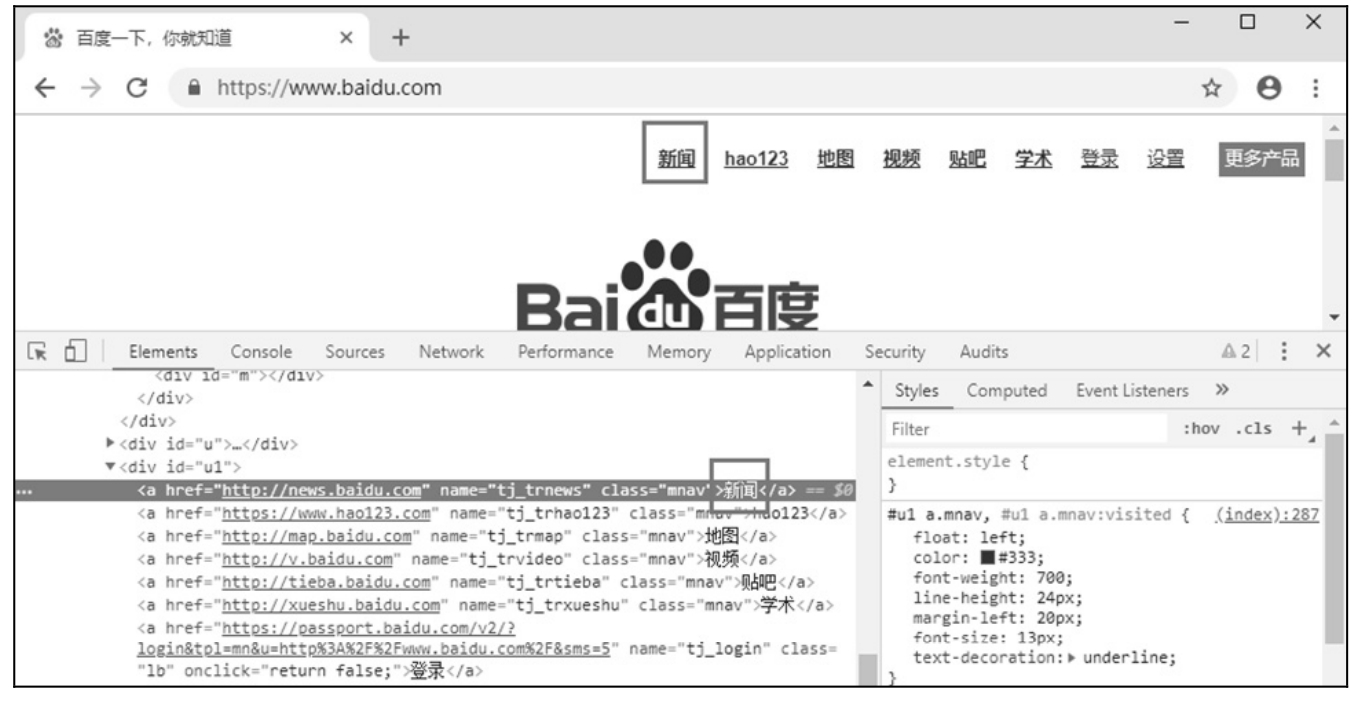
图 5.22
运行以下代码后,浏览器成功地打开了「新闻」链接,如图 5.23 所示。

from selenium import webdriver #要把chromedriver.exe放到D:\Python38目录中 browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.find_element_by_link_text('贴吧').click()
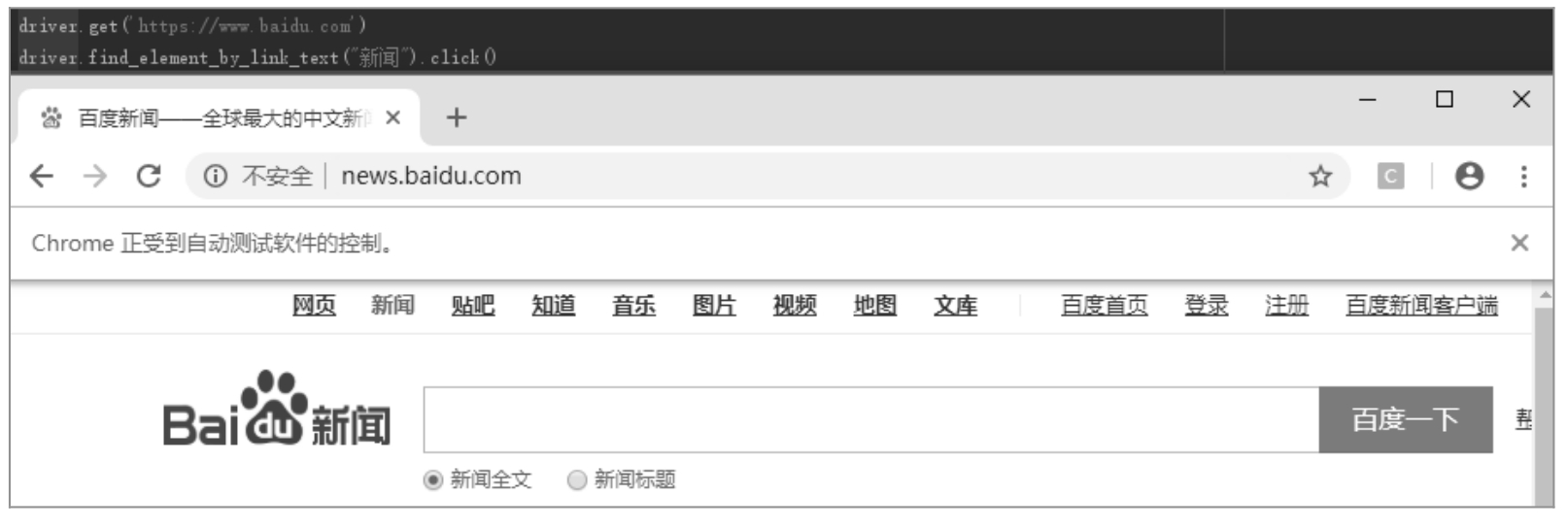
图 5.23
注意:用此方法定位元素超链接,中文字需要写全。
5.2.5 partial_link_text 定位
即用超链接文字的部分文本来定位元素,类似数据库的模糊查询。以「新闻」超链接为例,只需「新」一个字即可,即取超链接全部文本的一个子集。代码如下:

5.2.6 CSS 定位
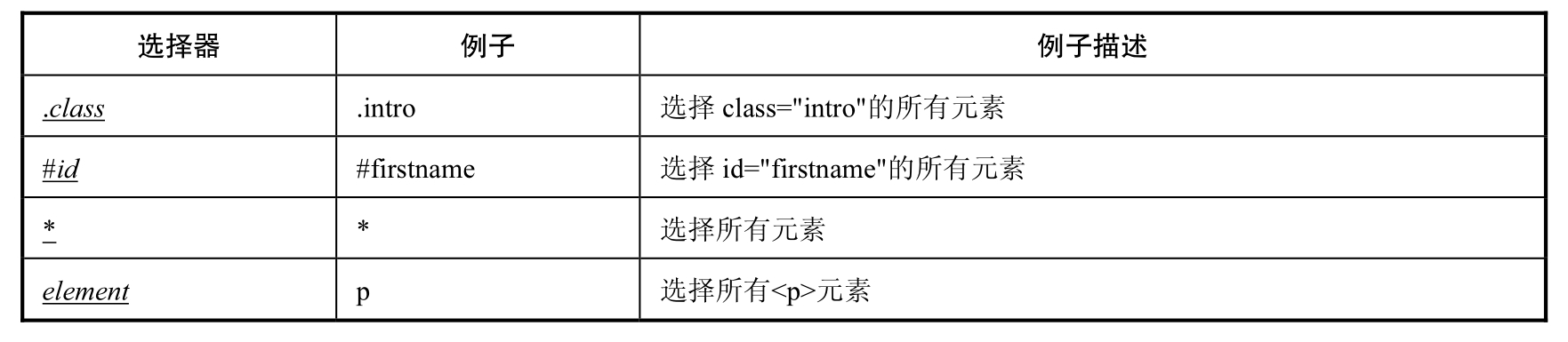
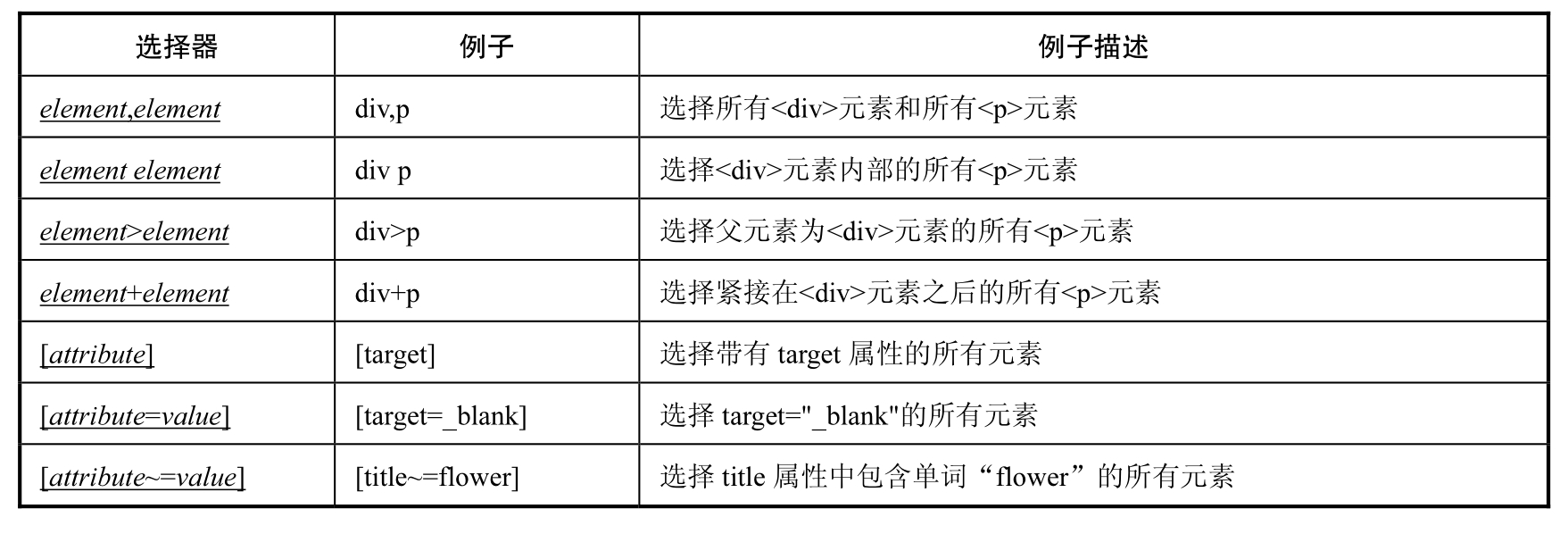
CSS 定位的优点是速度快、语法简洁。表 5.1 中的内容出自 W3School 的 CSS 参考手册。CSS 定位的选择器有十几种,在本节中主要介绍几种比较常用的选择器。
表 5.1
续表
以 class 选择器为例,实现在百度搜索框输入「python」,代码如下:

from selenium import webdriver #要把chromedriver.exe放到D:\Python38目录中 browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.find_element_by_css_selector('.s_ipt').send_keys('python')
由上可知 id 定位语法结构为:#加 id 名。实现在百度搜索框输入「python」,代码如下:

from selenium import webdriver #要把chromedriver.exe放到D:\Python38目录中 browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.find_element_by_css_selector('#kw').send_keys('python')
通过以上两个案例可以看出,CSS 定位主要利用属性 class 和 id 进行元素定位。此外,也可以利用常规的标签名称来定位,如输入框标签「input」,在标签内部又设置了属性值为「name=’wd』」,测试代码如下,代码执行结果如图 5.24 所示。

#coding=utf-8
from selenium import webdriver #要把chromedriver.exe放到D:\Python38目录中 browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.find_element_by_css_selector('input[class=s_ipt]').send_keys('python')
下面两种CSS选择器定位元素的写法也可以正常执行:
browser.find_element_by_css_selector('input#kw').send_keys('python')
browser.find_element_by_css_selector('input.s_ipt').send_keys('python')
图 5.24
CSS 定位方式可以使用元素在页面布局中的绝对路径来实现元素定位。还是以在百度输入框元素定位为例进行讲解。其元素细节如图 5.25 所示。

图 5.25
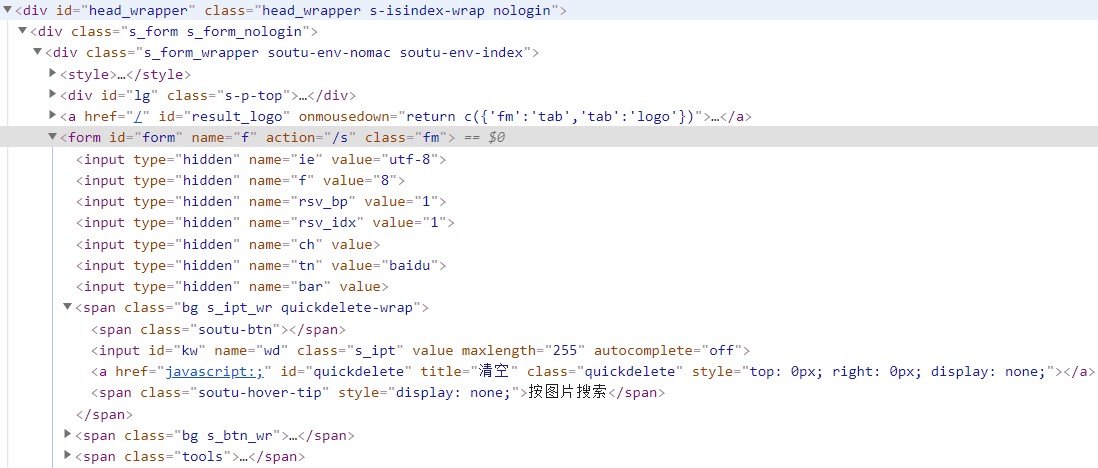
通过 Chrome 浏览器开发者工具可以很方便地看到百度首页搜索输入框元素的绝对路径为「html>body>div>div>div>div>div>form>span>input[name=「wd」]」。测试代码如下:


CSS 定位也可以使用元素在页面布局中的相对路径来实现元素定位。下面以相同的案例来说明相对路径如何使用,测试代码如下:
#coding=utf-8 from selenium import webdriver #要把chromedriver.exe放到D:\Python38目录中 browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.find_element_by_css_selector('form#form>span>input.s_ipt').send_keys('python')
其实通过分析对比可以发现,最终相对路径的写法和直接利用标签名称来定位,两者的代码实现的功能是一致的。
5.2.7 XPath 定位
通过 XPath 来定位元素的方式,对比较难以定位的元素来说很有效,几乎都可以解决,特别是对于有些元素没有 id、name 等属性的情况。
1.XPath 简介
XPath 是 XML Path 语言的缩写,是一种用来确定 XML 文档中某部分位置的语言。它在 XML 文档中通过元素名和属性进行搜索,主要用途是在 XML 文档中寻找节点。XPath 定位比 CSS 定位有更大的灵活性。XPath 可以向前搜索也可以向后搜索,而 CSS 定位只能向前搜索,但是 XPath 定位的速度比 CSS 慢一些。
XPath 语言包含根节点、元素、属性、文本、处理指令、命名空间等。以下文本为 XML 实例文档,用于演示 XML 的各种节点类型,便于理解 XPath。

其中 <animalList> 为文档节点,也是根节点;<name> 为元素节点;type=「mammal」为属性节点。
节点之间的关系:
· 父节点。每个元素都有一个父节点,如上面的 XML 示例中,animal 元素是 name、size,以及 action 元素的父节点。
· 子节点。与父节点相反,这里不再赘述。
· 兄弟节点,有些也叫同胞节点。它表示拥有相同父节点的节点。如上代码所示,name、size 和 action 元素都是同胞节点。
· 先辈节点。它是指某节点的父节点,或者父节点的父节点,以此类推。如上代码所示,name 元素节点的先辈节点有 animal 和 animalList。
· 后代节点。它表示某节点的子节点、子节点的子节点,以此类推。如上代码所示,animalList 元素节点的后代节点有 animal、name 等。
2.XPath 语法
XPath 来自于 XML,又由于 HTML 语言的语法和 XML 比较接近,故 XPath 也支持定位 HTML 页面元素。下面以美团登录为例,采用绝对路径与相对路径演示。网页元素如图 5.26 所示。

图 5.26
(1)相对路径示例代码如下:

(2)绝对路径示例代码如下:

以上示例采用 input 标签的 id 属性进行定位,也可以用 name 属性进行定位,代码如下:

5.2.8 tag_name 定位
tag_name 定位即通过标签名称定位,如图 5.27 所示,定位标签「form」并打印标签属性值「name」。
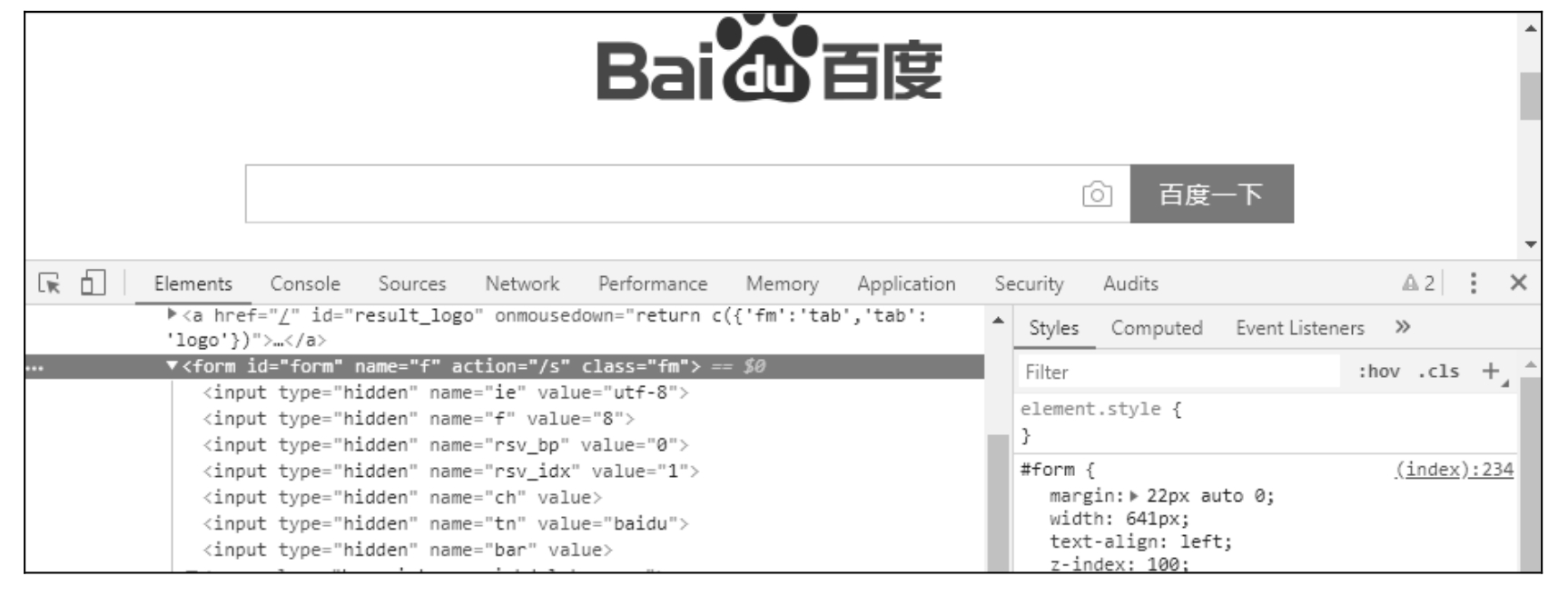
图 5.27
代码如下:


成功后控制台输出「f」,如图 5.28 所示。

图 5.28
本章主要介绍了 Selenium 元素的八大定位,每一种定位方式都有其特殊的用法,读者只要掌握其特殊性即可。需要在项目中多用多想、总结经验,时间久了会对这些定位方式有更深的理解。

