

第 7 章 unittest 扩展Parameterized - Selenium3 自动化测试
第 7 章 unittest 扩展
在第 6 章中,我们介绍了 unittest 的主要功能,但是如果只用它来写 Web 自动化测试,则仍稍显不足。例如,它不能生成 HTML 格式的报告、它不能提供参数化功能等。不过,我们可以借助第三方扩展来弥补这些不足。
7.1 HTML 测试报告
HTMLTestRunner 是 unittest 的一个扩展,它可以生成易于使用的 HTML 测试报告。HTMLTestRunner 是在 BSD 开源许可证下发布的。
下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html
因为该扩展不支持 Python 3,所以笔者做了一些修改,使它可以在 Python 3.6 下运行。
GitHub 地址:https://github.com/defnngj/HTMLTestRunner
7.1.1 下载与安装
HTMLTestRunner 的使用非常简单,它是一个独立的 HTMLTestRunner.py 文件,既可以把它当作 Python 的第三方库来使用,也可以把它当作项目的一部分来使用。
首先打开上面的 GitHub 地址,下载整个项目。然后把 HTMLTestRunner.py 单独放到 Python 的安装目录下面,如 C:\Python36\Lib\
如果把 HTMLTestRunner 当作项目的一部分来使用,就把它放到项目目录中。笔者推荐这种方式,因为可以方便地定制生成的 HTMLTestRunner 报告。

其中,test_report/用于存放测试报告,稍后将会用到。
7.1.2 生成 HTML 测试报告
如果想用 HTMLTestRunner 生成测试报告,那么请查看本书 6.1.4 节 run_tests.py 文件的实现。测试用例的执行是通过 TextTestRunner 类提供的 run()方法完成的。这里需要把 HTMLTestRunner.py 文件中的 HTMLTestRunner 类替换 TextTestRunner 类。
打开 HTMLTestRunner.py 文件,在第 877 行(如果代码更新,则行号会发生变化)可以找到 HTMLTestRunner 类。
使用Sublime打开HTMLTestRunner.py文件,查找关键字“HTMLTestRunner”。
HTMLTestRunner.py
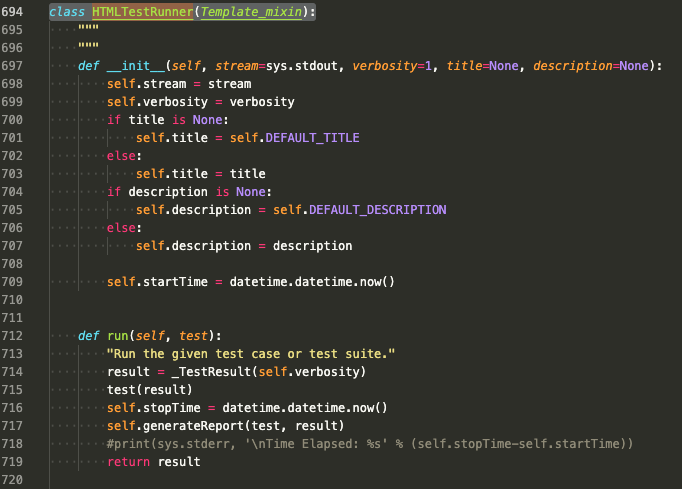
这段代码是 HTMLTestRunner 类的部分实现,主要看__init__()初始化方法的参数。
● stream:指定生成 HTML 测试报告的文件,必填。
● verbosity:指定日志的级别,默认为 1。如果想得到更详细的日志,则可以将参数修改为 2。
● title:指定测试用例的标题,默认为 None。
● description:指定测试用例的描述,默认为 None。
在 HTMLTestRunner 类中,同样由 run()方法来运行测试套件中的测试用例。修改 run_tests.py 文件如下。
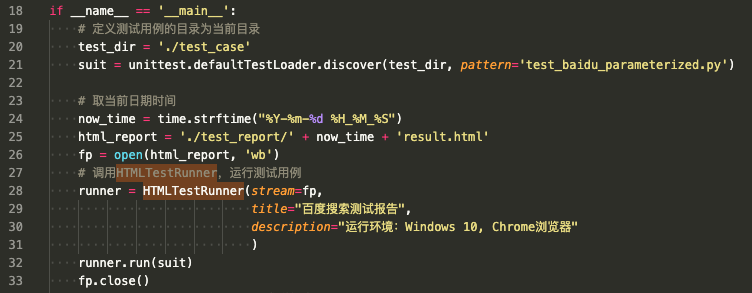


import unittest from HTMLTestRunner import HTMLTestRunner if __name__ == '__main__': # 定义测试用例的目录为当前目录 test_dir = './test_case' suit = unittest.defaultTestLoader.discover(test_dir, pattern='test*.py') fp = open('./test_report/result.html', 'wb') # 调用HTMLTestRunner,运行测试用例 runner = HTMLTestRunner(stream=fp, title="百度搜索测试报告", description="运行环境:Windows 10, Chrome浏览器" ) runner.run(suit) fp.close()
首先,使用 open()方法打开 result.html 文件,用于写入测试结果。如果没有 result.html 文件,则会自动创建该文件,并将该文件对象传给 HTMLTestRunner 类的初始化参数 stream。然后,调用 HTMLTestRunner 类中的 run()方法来运行测试套件。最后,关闭 result.html 文件。
打开/test_report/result.html 文件,将会得到一张HTML格式的报告。HTMLTestRunner 测试报告如图。
7.1.3 更易读的测试报告
现在生成的测试报告并不易读,因为它仅显示测试类名和测试方法名。如果随意命名为「test_case1」「test_case2」等,那么将很难明白这些测试用例所测试的功能。
在编写功能测试用例时,每条测试用例都有标题或说明,那么能否为自动化测试用例加上中文的标题或说明呢?答案是肯定的。在此之前,我们先来补充一个知识点:Python 的注释。
Python 的注释有两种,一种叫作 comment,另一种叫作 doc string。前者为普通注释,后者用于描述函数、类和方法。
在类或方法的下方,可以通过三引号(「」「」「」或『』『』『』)添加 doc string 类型的注释。这类注释在平时调用时不会显示,只有通过 help()方法查看时才会被显示出来。
因为 HTMLTestRunner 可以读取 doc string 类型的注释,所以,我们只需给测试类或方法添加这种类型的注释即可。
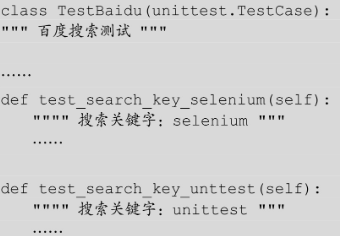
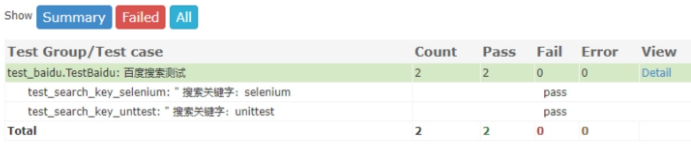
再次运行测试用例,查看测试报告,加了注释的测试报告如图 7-2 所示。
7.1.4 测试报告文件名
因为测试报告的名称是固定的,所以每次新的测试报告都会覆盖上一次的。如果不想被覆盖,那么只能每次在运行前都手动修改报告的名称。这样显然非常麻烦,我们最好能为测试报告自动取不同的名称,并且还要有一定的含义。时间是个不错的选择,因为它可以标识每个报告的运行时间,更主要的是时间不会重复标识。
在 Python 的 time 模块中提供了各种关于时间操作的方法,利用这些方法可以完成这个需求。
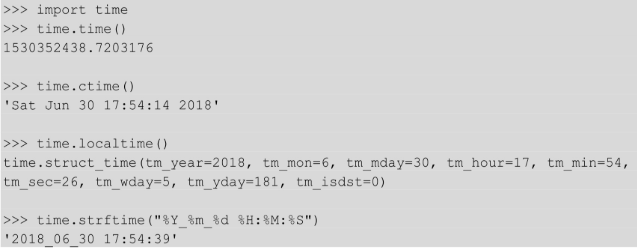
说明如下。
● time.time():获取当前时间戳。
● time.ctime():当前时间的字符串形式。
● time.localtime():当前时间的 struct_time 形式。
● time.strftime():用来获取当前时间,可以将时间格式化为字符串。
打开 run_tests.py 文件,做如下修改。

通过 strftime()方法以指定的格式获取当前日期时间,并赋值给 now_time 变量。将 now_time 通过加号(+)拼接到生成的测试报告的文件名中。
7.2 数据驱动应用
数据驱动是自动化测试的一个重要功能,在第 5 章中,介绍了数据文件的使用。虽然不使用单元测试框架一样可以写测试代码和使用数据文件,但是这就意味着放弃了单元测试框架提供给我们的所有功能,如测试用例的断言、灵活的运行机制、结果统计及测试报告等。这些都需要自己去实现,显然非常麻烦。所以,抛开单元测试框架谈数据驱动的使用是没有意义的。
下面探讨数据驱动的使用,以及 unittest 关于参数化的库。
7.2.1 数据驱动
大多数文章和资料都把「读取数据文件」看作数据驱动的标志。
在 unittest 中,使用读取数据文件来实现参数化可以吗?当然可以。这里以读取 CSV 文件为例。创建一个 baidu_data.csv 文件,如图 7-4 所示。
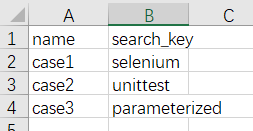
文件第一列为测试用例名称,第二例为搜索的关键字。接下来创建 test_baidu_data.py 文件。
import csv import codecs import unittest from time import sleep from itertools import islice from selenium import webdriver class TestBaidu(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Chrome() cls.base_url = "https://www.baidu.com" @classmethod def tearDownClass(cls): cls.driver.quit() def baidu_search(self, search_key): self.driver.get(self.base_url) self.driver.find_element_by_id("kw").send_keys(search_key) self.driver.find_element_by_id("su").click() sleep(3) def test_search(self): with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f: data = csv.reader(f) for line in islice(data, 1, None): search_key = line[1] self.baidu_search(search_key) if __name__ == '__main__': unittest.main(verbosity=2)
这样做似乎没有问题,确实可以读取 baidu_data.csv 文件中的三条数据并进行测试,测试结果如下。
所有测试数据被当作一条测试用例执行了。我们知道,unittest 是以「test」开头的测试方法来划分测试用例的,而此处是在一个测试方法下面通过 for 循环来读取测试数据并执行的,因而会被当作一条测试用例。
这样划分并不合理,比如,有 10 条数据,只要有 1 条数据执行失败,那么整个测试用例就执行失败了。所以,10 条数据对应 10 条测试用例更为合适,就算其中 1 条数据的测试用例执行失败了,也不会影响其他 9 条数据的测试用例的执行,并且在定位测试用例失败的原因时会更加简单。
import csv import codecs import unittest from time import sleep from itertools import islice from selenium import webdriver class TestBaidu(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Chrome() cls.base_url = "https://www.baidu.com" cls.test_data = [] with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f: data = csv.reader(f) for line in islice(data, 1, None): cls.test_data.append(line) @classmethod def tearDownClass(cls): cls.driver.quit() def baidu_search(self, search_key): self.driver.get(self.base_url) self.driver.find_element_by_id("kw").send_keys(search_key) self.driver.find_element_by_id("su").click() sleep(3) def test_search_selenium(self): self.baidu_search(self.test_data[0][1]) def test_search_unittest(self): self.baidu_search(self.test_data[1][1]) def test_search_parameterized(self): self.baidu_search(self.test_data[2][1]) if __name__ == '__main__': unittest.main(verbosity=2)
这一次,用 setUpClass() 方法读取 baidu_data.csv 文件,并将文件中的数据存储到 test_data 数组中。分别创建不同的测试方法使用 test_data 中的数据,测试结果如下。
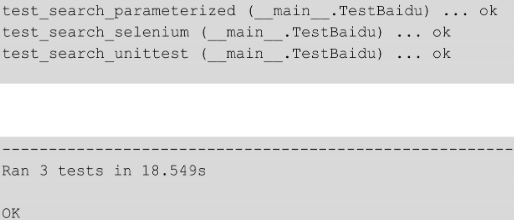
从测试结果可以看到,3 条数据被当作 3 条测试用例执行了。那么是不是就完美解决了前面的问题呢?接下来,需要思考一下,读取数据文件带来了哪些问题?
(1)增加了读取的成本。不管什么样的数据文件,在运行自动化测试用例前都需要将文件中的数据读取到程序中,这一步是不能少的。
(2)不方便维护。读取数据文件是为了方便维护,但事实上恰恰相反。在 CSV 数据文件中,并不能直观体现出每一条数据对应的测试用例。而在测试用例中通过 test_data[0][1]方式获取数据也存在很多问题,如果在 CSV 文件中间插入了一条数据,那么测试用例获取到的测试数据很可能就是错的。
如果在测试过程中需要用很多数据怎么办?我们知道测试脚本并不是用来存放数据的地方,如果待测试的数据很多,那么全部放到测试脚本中显然并不合适。
在回答这个问题之前,先思考一下什么是 UI 自动化测试?UI 自动化测试是站在用户的角度模拟用户的操作。那么用户在什么场景下会输入大量的数据呢?其实输入大量数据的功能很少,如果整个系统都需要用户重复或大量地输入数据,那么很可能是用户体验做得不好!大多数时候,系统只允许用户输入用户名、密码和个人信息,或搜索一些关键字等。
假设我们要测试用户发文章的功能,这时确实会用到大量的数据。
那么读取数据文件是不是就完全没必要了呢?当然不是,比如一些自动化测试的配置就可以放到数据文件中,如运行环境、运行的浏览器等,放到配置文件中会更方便管理。
7.2.2 Parameterized
Parameterized 是 Python 的一个参数化库,同时支持 unittest、Nose 和 pytest 单元测试框架。
GitHub 地址:https://github.com/wolever/parameterized
Parameterized 支持 pip 安装。
pip3 install parameterized==0.8.1
离线安装命令:python setup.py install
Installed d:\python38\lib\site-packages\parameterized-0.7.4-py3.8.egg Processing dependencies for parameterized==0.7.4 Finished processing dependencies for parameterized==0.7.4
在第 6.3 节实现了百度搜索的测试,这里将通过 Parameterized 实现参数化。
test_baidu_parameterized.py
import unittest from time import sleep from selenium import webdriver from parameterized import parameterized class TestBaidu(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Chrome() cls.base_url = "https://www.baidu.com" def baidu_search(self, search_key): self.driver.get(self.base_url) self.driver.find_element_by_id("kw").send_keys(search_key) self.driver.find_element_by_id("su").click() sleep(2) # parameterized参数化 @parameterized.expand([ ("case1", "selenium"), ("case2", "unittest"), ("case3", "parameterized"), ]) def test_search(self, name, search_key): self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") @classmethod def tearDownClass(cls): cls.driver.quit() if __name__ == '__main__': unittest.main(verbosity=2)
这里的主要改动在测试用例部分。
首先,导入 Parameterized 库下面的 parameterized 类。
其次,通过@parameterized.expand()来装饰测试用例 test_search()。
在@parameterized.expand()中,每个元组都可以被认为是一条测试用例。元组中的数据为该条测试用例变化的值。在测试用例中,通过参数来取每个元组中的数据。
在 test_search()中,name 参数对应元组中第一列数据,即「case1」「case2」「case3」,用来定义测试用例的名称;search_key 参数对应元组中第二列数据,即「selenium」「unittest」「parameterized」,用来定义搜索的关键字。
最后,使用 unittest 的 main()方法,设置 verbosity 参数为 2,输出更详细的执行日志。运行上面的测试用例,结果如下。
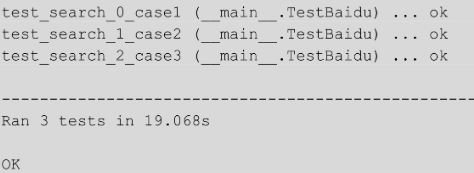
通过测试结果可以看到,因为是根据@parameterized.expand()中元组的个数来统计测试用例数的,所以产生了 3 条测试用例。test_search 为定义的测试用例的名称。参数化会自动加上「0」、「1」和「2」来区分每条测试用例,在元组中定义的「case1」「case2」「case3」也会作为每条测试用例名称的后缀出现。
7.2.3 DDT
DDT(Data-Driven Tests)是针对 unittest 单元测试框架设计的扩展库。允许使用不同的测试数据来运行一个测试用例,并将其展示为多个测试用例。
GitHub 地址:https://github.com/datadriventests/ddt
DDT 支持 pip 安装。
pip3 install ddt==1.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
同样以百度搜索为例,来看看 DDT 的用法。创建 test_baidu_ddt.py 文件。
import unittest from selenium import webdriver from time import sleep from ddt import ddt, data, file_data, unpack @ddt class TestBaidu(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Chrome() cls.base_url = "https://www.baidu.com" def baidu_search(self, search_key): self.driver.get(self.base_url) self.driver.find_element_by_id("kw").send_keys(search_key) self.driver.find_element_by_id("su").click() sleep(3) # 参数化使用方式一 @data(["case1", "selenium"], ["case2", "ddt"], ["case3", "python"]) @unpack def test_search1(self, case, search_key): print("第一组测试用例:", case) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化使用方式二 @data(("case1", "selenium"), ("case2", "ddt"), ("case3", "python")) @unpack def test_search2(self, case, search_key): print("第二组测试用例:", case) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化使用方式三 @data({"search_key": "selenium"}, {"search_key": "ddt"}, {"search_key": "python"}) @unpack def test_search3(self, search_key): print("第三组测试用例:", search_key) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化读取JSON文件 @file_data('ddt_data_file.json') def test_search4(self, search_key): print("第四组测试用例:", search_key) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化读取yaml文件 @file_data('ddt_data_file.yaml') def test_search5(self, case): search_key = case[0]["search_key"] print("第五组测试用例:", search_key) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") @classmethod def tearDownClass(cls): cls.driver.quit() if __name__ == '__main__': unittest.main(verbosity=2)
使用 DDT 需要注意以下几点。
首先,测试类需要通过@ddt 装饰器进行装饰。
其次,DDT 提供了不同形式的参数化。这里列举了三组参数化,第一组为列表,第二组为元组,第三组为字典。需要注意的是,字典的 key 与测试方法的参数要保持一致。
执行结果如下。
DDT 同样支持数据文件的参数化。它封装了数据文件的读取,让我们更专注于数据文件中的内容,以及在测试用例中的使用,而不需要关心数据文件是如何被读取进来的。
首先,创建 ddt_data_file.json 文件。
{ "case1": {"search_key": "python"}, "case2": {"search_key": "ddt"}, "case3": {"search_key": "Selenium"} }
在测试用例中使用 test_data_file.json 文件参数化测试用例,在 test_baidu_ddt.py 文件中增加测试用例数据。

注意,ddt_data_file.json 文件需要与 test_baidu_ddt.py 放在同一目录下面,否则需要指定 ddt_data_file.json 文件的路径。
除此之外,DDT 还支持 yaml 格式的数据文件。创建 ddt_data_file.yaml 文件。
case1: - search_key: "python" case2: - search_key: "ddt" case3: - search_key: "unittest"
在 test_baidu_ddt.py 文件中增加测试用例。

这里的取值与上面的 JSON 文件有所不同,因为每一条用例都被解析为[{『search_key』:『python』}],所以要想取到搜索关键字,则需要通过 case[0][「search_key」]的方式获取。
import unittest from selenium import webdriver from time import sleep from ddt import ddt, data, file_data, unpack @ddt class TestBaidu(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Chrome() cls.base_url = "https://www.baidu.com" def baidu_search(self, search_key): self.driver.get(self.base_url) self.driver.find_element_by_id("kw").send_keys(search_key) self.driver.find_element_by_id("su").click() sleep(3) # 参数化使用方式一 @data(["case1", "selenium"], ["case2", "ddt"], ["case3", "python"]) @unpack def test_search1(self, case, search_key): print("第一组测试用例:", case) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化使用方式二 @data(("case1", "selenium"), ("case2", "ddt"), ("case3", "python")) @unpack def test_search2(self, case, search_key): print("第二组测试用例:", case) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化使用方式三 @data({"search_key": "selenium"}, {"search_key": "ddt"}, {"search_key": "python"}) @unpack def test_search3(self, search_key): print("第三组测试用例:", search_key) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化读取JSON文件 @file_data('ddt_data_file.json') def test_search4(self, search_key): print("第四组测试用例:", search_key) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化读取yaml文件 @file_data('ddt_data_file.yaml') def test_search5(self, case): search_key = case[0]["search_key"] print("第五组测试用例:", search_key) self.baidu_search(search_key) self.assertEqual(self.driver.title, search_key + "_百度搜索") @classmethod def tearDownClass(cls): cls.driver.quit() if __name__ == '__main__': unittest.main(verbosity=2)
7.3 自动发送邮件功能
自动发送邮件功能是自动化测试项目的重要需求之一,当自动化测试用例运行完成之后,可自动向相关人员的邮箱发送测试报告。
SMTP(Simple Mail Transfer Protocol)是简单邮件传输协议,是一组由源地址到目的地址传送邮件的规则,可以控制信件的中转方式。Python 的 smtplib 模块提供了简单的 API 用来实现发送邮件功能,它对 SMTP 进行了简单的封装。
在给其他人发送邮件之前,首先需要通过浏览器打开邮箱网址(如 www.126.com),或打开邮箱客户端(如 Foxmail),登录自己的邮箱账号。如果是邮箱客户端,则还需要配置邮箱服务器地址(如 smtp.126.com)。然后填写收件人地址、邮件的主题和正文,以及添加附件等。即便通过 Python 实现发送邮件功能,也需要设置这些信息。
7.3.1 Python 自带的发送邮件功能
在发送邮件时,除填写主题和正文外,还可以添加抄送人、添加附件等。这里我们分别把测试报告作为正文和附件进行发送。
1.发送邮件正文
send_mail_text.py
import smtplib from email.mime.text import MIMEText from email.header import Header # 发送邮件标题 subject = 'Python email test' # 编写HTML类型的邮件正文 msg = MIMEText('<html><h1>你好!</h1></html>', 'html', 'utf-8') msg['Subject'] = Header(subject, 'utf-8') # 连接发送邮件 smtp = smtplib.SMTP() smtp.connect("smtp.126.com") smtp.login("sender@126.com", "a123456") smtp.sendmail("sender@126.com", "receiver@126.com", msg.as_string()) smtp.quit()
首先,调用 email 模块下面的 MIMEText 类,定义发送邮件的正文、格式,以及编码。
然后,调用 email 模块下面的 Header 类,定义邮件的主题和编码类型。
smtplib 模块用于发送邮件。connect()方法指定连接的邮箱服务;login()方法指定登录邮箱的账号和密码;sendmail()方法指定发件人、收件人,以及邮件的正文;quit()方法用于关闭邮件服务器的连接。
2.发送带附件的邮件
send_mail_att.py
import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart # 邮件主题 subject = 'Python send email test' # 发送的附件 with open('log.txt', 'rb') as f: send_att = f.read() att = MIMEText(send_att, 'text', 'utf-8') att["Content-Type"] = 'application/octet-stream' att["Content-Disposition"] = 'attachment; filename="log.txt"' msg = MIMEMultipart() msg['Subject'] = subject msg.attach(att) smtp = smtplib.SMTP() smtp.connect("smtp.126.com") smtp.login("sender@126.com", "a123456") smtp.sendmail("sender@126.com", "receiver@126.com", msg.as_string()) smtp.quit()
首先,读取附件的内容。通过 MIMEText 类,定义发送邮件的正文、格式,以及编码;Content-Type 指定附件内容类型;application/octet-stream 表示二进制流;Content-Disposition 指定显示附件的文件;attachment;filename=「log.txt」指定附件的文件名。
然后,使用 MIMEMultipart 类定义邮件的主题,attach()指定附件信息。
最后,通过 smtplib 模块发送邮件,发送过程与第一个例子相同。
7.3.2 用 yagmail 发送邮件
yagmail 是 Python 的一个第三方库,可以让我们以非常简单的方法实现自动发送邮件功能。
GitHub 项目地址:https://github.com/kootenpv/yagmail
通过 pip 命令安装。
pip install yagmail
项目文档提供了的简单发送邮件的例子。
yagmail_demo.py
import yagmail #连接邮箱服务器 yag = yagmail.SMTP(user="sender@126.com", password="a123456", host='smtp.126.com') # 邮箱正文 contents = ['This is the body, and here is just text http://somedomain/image.png', 'You can find an audio file attached.'] # 发送邮件 yag.send('receiver@126.com', 'send email subject', contents)
总共四行代码,是不是比上面的例子简单太多了。有了前面的基础,这里的代码就不需要做过多解释了。
如果想给多个用户发送邮件,那么只需把收件人放到一个 list 中即可。

如果想发送带附件的邮件,那么只需指定本地附件的路径即可。

另外,还可以通过 list 指定多个附件。yagmail 库极大地简化了发送邮件的代码。
7.3.3 整合自动发送邮件功能
在学习了如何用 Python 实现发送邮件之后,现在只需将功能集成到自动化测试项目中即可。打开 run_tests.py 文件,修改代码如下。

run_tests.py
import time import unittest import yagmail from HTMLTestRunner import HTMLTestRunner # 把测试报告作为附件发送到指定邮箱。 def send_mail(report): yag = yagmail.SMTP(user="testingwtb@126.com", password="a123456", host='smtp.126.com') subject = "标题,自动化测试报告" contents = "正文,请查看附件。" yag.send('testingwtb@126.com', subject, contents, report) print('email has send out !') if __name__ == '__main__': # 定义测试用例的目录为当前目录 test_dir = './test_case' suit = unittest.defaultTestLoader.discover(test_dir, pattern='test_baidu_parameterized.py') # 取当前日期时间 now_time = time.strftime("%Y-%m-%d %H_%M_%S") html_report = './test_report/' + now_time + 'result.html' fp = open(html_report, 'wb') # 调用HTMLTestRunner,运行测试用例 runner = HTMLTestRunner(stream=fp, title="百度搜索测试报告", description="运行环境:Windows 10, Chrome浏览器" ) runner.run(suit) fp.close() send_mail(html_report) # 发送报告
整个程序的执行过程可以分为两部分:
(1)定义测试报告文件,并赋值给变量 html_report,通过 HTMLTestRunner 运行测试用例,将结果写入文件后关闭。
(2)调用 send_mail()函数,并传入 html_report 文件。在 send_mail()函数中,把测试报告作为邮件的附件发送到指定邮箱。
为什么不把测试报告的内容读取出来作为邮件正文发送呢?因为 HTMLTestRunner 报告在展示时引用了 Bootstrap 样式库,当作为邮件正文「写死」在邮件中时,会导致样式丢失,所以作为附件发送更为合适。
