
第 4 章 WebDriver API - 4.2 控制浏览器 - Selenium3 自动化测试
4.2 控制浏览器
WebDriver 主要提供操作页面上各种元素的方法,同时,它还提供了操作浏览器的一些方法,如控制浏览器窗口大小、操作浏览器前进或后退等。
4.2.1 控制浏览器窗口大小
有时候我们希望浏览器能在某种尺寸下运行。例如,可以将 Web 浏览器窗口设置成移动端大小(480x800),然后访问移动站点。WebDriver 提供的 set_window_size()方法可以用来设置浏览器窗口大小。
""" * set_window_size() 设置浏览器宽、高 * maximize_window() 设置浏览器全屏 """ from selenium import webdriver driver = webdriver.Chrome() driver.get("http://m.baidu.com") # 参数数字为像素点 print("设置浏览器宽480、高800显示") driver.set_window_size(480, 800) # 设置浏览器全屏 driver.maximize_window() driver.quit()
如果希望 Web 浏览器在全屏幕模式下运行,以便显示更多的元素,可以使用 maximize_window()方法实现,该方法不需要参数。
4.2.2 控制浏览器后退、前进
浏览器提供了后退和前进按钮,可以方便地在浏览过的网页之间切换,WebDriver 还提供了对应的 back()和 forward()方法来模拟后退和前进按钮。下面通过例子演示这两个方法的使用。
""" * back() 后退 * forward() 前进 * refresh() 刷新 """ from selenium import webdriver driver = webdriver.Chrome() # 访问百度首页 first_url = 'http://www.baidu.com' print("now access %s" %(first_url)) driver.get(first_url) # 访问新闻页面 second_url = 'http://news.baidu.com' print("now access %s" %(second_url)) driver.get(second_url) # 返回(后退)到百度首页 print("back to %s " %(first_url)) driver.back() # 前进到新闻页 print("forward to %s" %(second_url)) driver.forward() driver.refresh() # 刷新当前页面 driver.quit()
为了看清楚脚本的执行过程,这里每操作一步都通过 print()打印当前的 URL 地址。
4.2.3 模拟浏览器刷新
有时候需要手动刷新(按「F5」键)Web 页面,可以通过 refresh()方法实现。
4.3 WebDriver 中的常用方法
前面我们学习了定位元素的方法,但定位只是第一步,定位之后还需要对这个元素进行操作,比如,单击(按钮)或输入(输入框)。
(1)clear():清除文本。
(2)send_keys(value):模拟按键输入。
(3)click():单击元素。
(4)submit():提交表单。
例如,有些搜索框不提供搜索按钮,而是通过按键盘上的回车键完成搜索内容的提交,这时可以通过 submit()模拟。
有时候 submit()可以与 click()互换使用,但 submit()的应用范围远不及 click()广泛。click()可以单击任何可单击的元素,例如,按钮、复选框、单选框、下拉框文字链接和图片链接等。
(5)size:返回元素的尺寸。
(6)text:获取元素的文本。
(7)get_attribute(name):获得属性值。
(8)is_displayed():设置该元素是否用户可见。
""" * clear(): 清除文本。 * send_keys(*value): 模拟按键输入。 * click(): 单击元素。 * size 返回元素的尺寸。 * text 获取元素的文本。 * get_attribute(name) 获得属性值。 * is_displayed() 设置该元素是否用户可见。 """ from selenium import webdriver driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.find_element_by_id("kw").clear() driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() # submit 提交表单 search_text = driver.find_element_by_id('kw') search_text.send_keys('selenium') search_text.submit() # 获得输入框的尺寸 size = driver.find_element_by_id('kw').size print(size) # 返回百度页面底部备案信息 text = driver.find_element_by_id("cp").text print(text) # 返回元素的属性值,可以是 id、 name、 type 或其他任意属性 attribute = driver.find_element_by_id("kw").get_attribute('type') print(attribute) # 返回元素的结果是否可见,返回结果为 True 或 False result = driver.find_element_by_id("kw").is_displayed() print(result) driver.quit()
执行上面的程序并查看结果:size 方法用于获取百度输入框的宽、高;text 方法用于获得百度底部的备案信息;
get_attribute()方法用于获得百度输入的 type 属性的值;is_displayed()方法用于返回一个元素是否可见,如果可见,则返回 True,否则返回 False。
4.4 鼠标操作
在 WebDriver 中,与鼠标操作相关的方法都封装在 ActionChains 类中。
ActionChains 类提供了鼠标操作的常用方法:
● perform():执行 ActionChains 类中存储的所有行为。
● context_click():右击。
● double_click():双击。
● drag_and_drop():拖动。
● move_to_element():鼠标悬停。
鼠标悬停操作
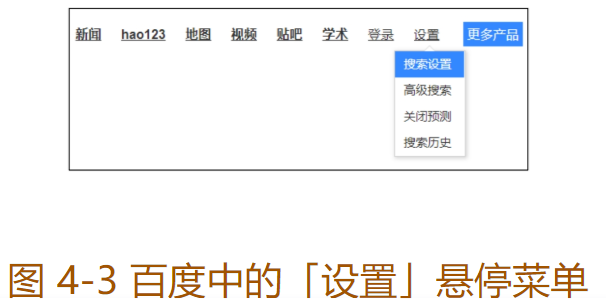
ActionChains 类提供的鼠标操作方法与 click()方法不同。
""" * perform() 执行所有 ActionChains 中存储的行为; * context_click() 右击; * double_click() 双击; * drag_and_drop() 拖动; * move_to_element() 鼠标悬停。 """ from selenium import webdriver # 引入 ActionChains 类 from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Chrome() driver.get("https://www.baidu.com") # 定位到要鼠标悬停的元素 above = driver.find_element_by_link_text("设置") # 对定位到的元素执行鼠标悬停操作 ActionChains(driver).move_to_element(above).perform() # ……
导入 ActionChains 类。

调用 ActionChains 类,把浏览器驱动 driver 作为参数传入。
move_to_element()方法用于模拟鼠标移动到元素上,在调用时需要指定元素。

提交所有 ActionChains 类中存储的行为。
4.5 键盘操作
前面介绍过,send_keys()方法可以用来模拟键盘输入,我们还可以用它来输入键盘上的按键,甚至是组合键等。


from selenium import webdriver # 引入Keys模块 from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome() driver.get("http://www.baidu.com") # 输入框输入内容 driver.find_element_by_id("kw").send_keys("seleniumm") # 删除多输入的一个m driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE) # 输入空格键+“教程” driver.find_element_by_id("kw").send_keys(Keys.SPACE) driver.find_element_by_id("kw").send_keys("教程") # ctrl+a 全选输入框内容 driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'a') # ctrl+x 剪切输入框内容 driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'x') # ctrl+v 粘贴内容到输入框 driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'v') # 通过回车键来代替单击操作 driver.find_element_by_id("su").send_keys(Keys.ENTER) driver.quit()
上面的脚本没有什么实际意义,仅向我们展示模拟键盘各种按键与组合键的用法。
在使用键盘按键方法前需要先导入 Keys 类。
# 引入Keys模块 from selenium.webdriver.common.keys import Keys
以下为常用的键盘操作。
● send_keys(Keys.BACK_SPACE):删除键(BackSpace)
● send_keys(Keys.SPACE):空格键(Space)
● send_keys(Keys.TAB):制表键(Tab)
● send_keys(Keys.ESCAPE):回退键(Esc)
● send_keys(Keys.ENTER):回车键(Enter)
● send_keys(Keys.CONTROL,'a'):全选(Ctrl+a)
● send_keys(Keys.CONTROL,'c'):复制(Ctrl+c)
● send_keys(Keys.CONTROL,'x'):剪切(Ctrl+x)
● send_keys(Keys.CONTROL,'v'):粘贴(Ctrl+v)
● send_keys(Keys.F1):键盘 F1
……
● send_keys(Keys.F12):键盘 F12
4.6 获得验证信息
在进行 Web 自动化测试中,用得最多的几种验证信息是 title、current_url 和 text。
● title:用于获取当前页面的标题。
● current_url:用于获取当前页面的 URL。
● text:用于获取当前页面的文本信息。
下面仍以百度搜索为例,对比搜索前后的信息。
""" * title 获取当前页面title * current_url 获取当前页面URL * text 获得文本信息 """ from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get("https://www.baidu.com") print('Before search================') # 打印当前页面title title = driver.title print("title:"+ title) # 打印当前页面URL now_url = driver.current_url print("URL:"+now_url) driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() sleep(2) print('After search================') # 再次打印当前页面title title = driver.title print("title:"+title) # 打印当前页面URL now_url = driver.current_url print("URL:"+now_url) # 获取搜索结果条数 num = driver.find_element_by_class_name('nums').text print("result:"+num) driver.quit()
运行结果如下。
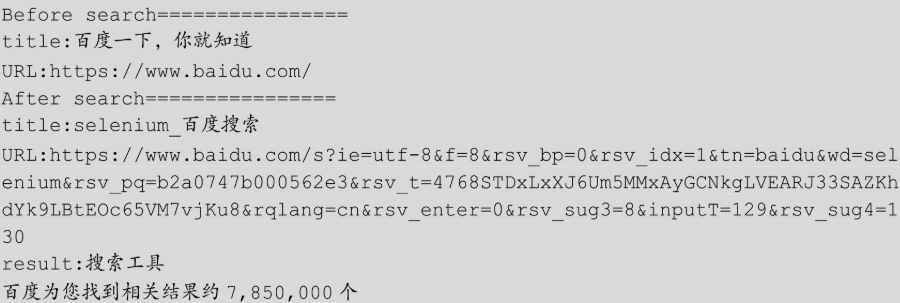
通过上面的打印信息可以看出搜索前后的差异,这些差异信息可以拿来作为自动化测试的断言点。
4.7 设置元素等待
WebDriver 提供了两种类型的元素等待:显式等待和隐式等待。
4.7.1 显式等待
显式等待是 WebDriver 等待某个条件成立则继续执行,否则在达到最大时长时抛出 TimeoutException
7_element_wait01.py
""" * presence_of_element_located() 方法判断元素是否存在 """ from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() driver.get("http://www.baidu.com") element = WebDriverWait(driver, 5, 0.5).until( EC.visibility_of_element_located((By.ID, "kw")) ) element.send_keys('selenium') driver.quit()
WebDriverWait 类是 WebDriver 提供的等待方法。在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间仍检测不到,则抛出异常。具体格式如下。

● driver:浏览器驱动。
● timeout:最长超时时间,默认以秒为单位。
● poll_frequency:检测的间隔(步长)时间,默认为 0.5s。
● ignored_exceptions:超时后的异常信息,默认情况下抛出 NoSuchElementException 异常。
WebDriverWait()一般与 until()或 until_not()方法配合使用,下面是 until()和 until_not()方法的说明。
 调用该方法提供的驱动程序作为一个参数,直到返回值为 True。
调用该方法提供的驱动程序作为一个参数,直到返回值为 True。
 调用该方法提供的驱动程序作为一个参数,直到返回值为 False。
调用该方法提供的驱动程序作为一个参数,直到返回值为 False。
在本例中,通过 as 关键字将 expected_conditions 重命名为 EC,并调用 presence_of_element_located()方法判断元素是否存在。
expected_conditions 类提供的预期条件判断方法如下表所示。
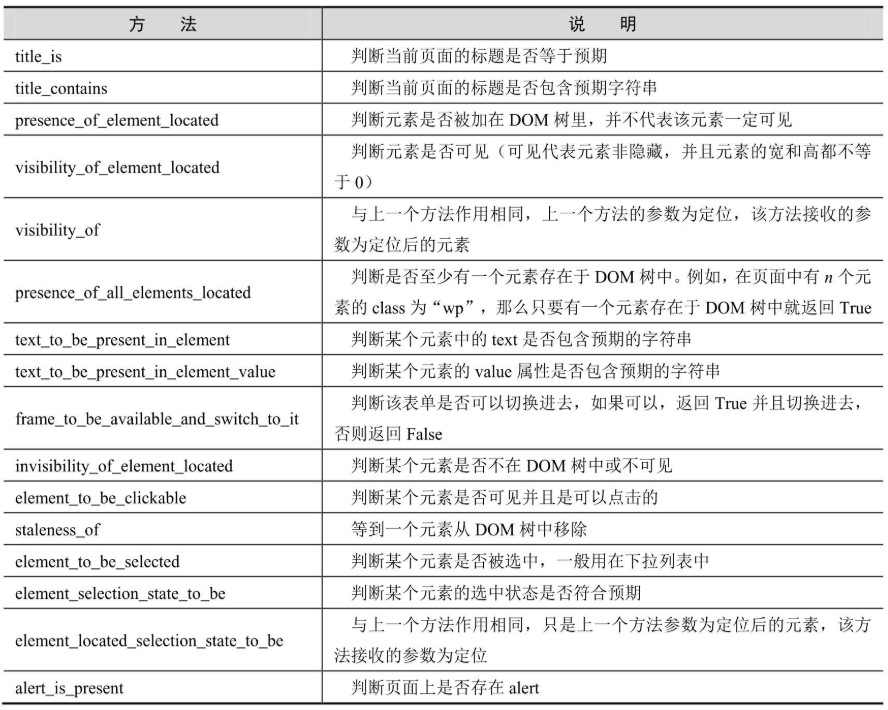
除 expected_conditions 类提供的丰富的预期条件判断方法外,还可以利用前面学过的 is_displayed()方法自己实现元素显示等待。
""" 自定义元素等待 """ from selenium import webdriver from time import sleep, ctime driver = webdriver.Chrome() driver.get("http://www.baidu.com") print(ctime()) for i in range(10): try: el = driver.find_element_by_id("kw22") if el.is_displayed(): break except: pass sleep(1) else: print("time out") print(ctime()) driver.quit()
4.7.2 隐式等待
WebDriver 提供的 implicitly_wait()方法可用来实现隐式等待,用法相对来说要简单得多。
7_element_wait03.py
""" * implicitly_wait() 隐式等待 """ from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from time import ctime driver = webdriver.Firefox() # 设置隐式等待为10秒 driver.implicitly_wait(10) driver.get("http://www.baidu.com") try: print(ctime()) driver.find_element_by_id("kw22").send_keys('selenium') except NoSuchElementException as e: print(e) finally: print(ctime()) driver.quit()
implicitly_wait()的参数是时间,单位为秒,本例中设置的等待时间为 10s。首先,这 10s 并非一个固定的等待时间,它并不影响脚本的执行速度。
其次,它会等待页面上的所有元素。当脚本执行到某个元素定位时,如果元素存在,则继续执行;如果定位不到元素,则它将以轮询的方式不断地判断元素是否存在。假设在第 6s 定位到了元素,则继续执行,若直到超出设置时间(10s)还没有定位到元素,则抛出异常。
这里同样故意将 id 定位设置为「kw22」,定位失败,执行结果如下。

4.8 定位一组元素
WebDriver 还提供了 8 种用于定位一组元素的方法。

定位一组元素的方法与定位单个元素的方法非常像,唯一的区别是单词「element」后面多了一个「s」,用来表示复数。
8_find_elements.py
""" * find_elements_xxx("xx") 定位一组元素 """ from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get("https://www.baidu.cn") driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() sleep(2) # 定位一组元素 texts = driver.find_elements_by_xpath("//div[@tpl='se_com_default']/h3/a") # 计算匹配结果个数 print(len(texts)) # 循环遍历出每一条搜索结果的标题 for t in texts: print(t.text) driver.quit()

