
第 4 章 WebDriver API - 4.1 从定位元素开始 - Selenium3 自动化测试
第 4 章 WebDriver API
从本章开始正式学习 WebDriver API,它可用来操作浏览器元素的一些类和方法。
4.1 从定位元素开始
例如百度的首页,页面上有输入框、按钮、文字链接、图片等元素。自动化测试要做的就是模拟鼠标和键盘来操作这些元素,如单击、输入、鼠标悬停等。
操作这些元素的前提是要定位它们,那么自动化工具,如何定位这些元素呢?
通过浏览器自带的(F12)开发者工具可以看到,页面元素都是由 HTML 代码组成的,它们之间有层级地组织起来,每个元素有不同的标签名和属性值。WebDriver 就是根据这些信息来定位元素的。
WebDriver 提供了 8 种元素定位方法,在 Python 中,对应的方法如下:
● id 定位 → find_element_by_id()
● name 定位 → find_element_by_name()
● tag 定位 → find_element_by_tag_name()
● class 定位 → find_element_by_class_name()
● link_text → find_element_by_link_text()
● partial link 定位 → find_element_by_partial_link_text()
● XPath 定位 → find_element_by_xpath()
● CSS_selector 定位 → find_element_by_css_selector()
如果把页面上的元素看作人,那么在现实世界中如何找到某人呢?
首先,可以通过人本身的属性进行查找,例如他的姓名、手机号、身份证号等,这些都是用于区别于他人的属性。在 Web 页面上的元素也有本身的属性,例如,id、name、tag name 等。
其次,可以通过位置进行查找,例如,x 国、x 市、x 路、x 号。XPath 和 CSS 可以通过标签层级关系的方式来查找元素。
最后,还可以借助相关人的属性来找到某人。例如,我没有小明的联系方式,但是我有他爸爸的手机号,那么通过他爸爸的手机号最终也可以找到小明。XPath 和 CSS 同样提供了相似的定位策略来查找元素。
理解了这些查找规则之后,下面介绍的几种元素定位方法就很好理解了。
4.1.1 id 定位
HTML 规定,id 在 HTML 文档中必须是唯一的,这类似于我国公民的身份证号,具有唯一性。WebDriver 提供的 id 定位方法是通过元素的 id 来查找元素的。通过 id 定位百度输入框与百度搜索按钮的用法如下。

find_element_by_id()方法是通过 id 来定位元素的。
4.1.2 name 定位
HTML 规定,name 用来指定元素的名称,因此它的作用更像是人的姓名。通过 name 定位百度输入框的用法如下。
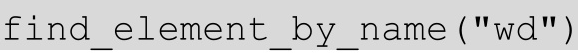
find_element_by_name()方法是通过 name 来定位元素的。
4.1.3 class 定位
HTML 规定,class 用来指定元素的类名,其用法与 id、name 类似。通过 class 定位百度输入框的用法如下。

find_element_by_class_name()方法是通过 class 来定位元素的。
4.1.4 tag 定位
HTML 通过 tag 来定义不同页面的元素。例如,<input> 一般用来定义输入框,<a> 标签用来定义超链接等。不过,因为一个标签往往用来定义一类功能,所以通过标签识别单个元素的概率很低。例如,我们打开任意一个页面,查看前端代码时都会发现大量的 <div>、<input>、<a> 等标签。
通过标签名(tag name)定位百度输入框的用法如下。

find_element_by_tag_name()方法是通过元素的标签名来定位元素的。
4.1.5 link 定位
link 定位与前面介绍的几种定位方法有所不同,它专门用来定位文本链接。百度输入框上面的几个文字链接的代码如下。

查看上面的代码可以发现,通过 name 定位是个不错的选择。不过这里为了演示 link 定位的使用,现给出通过 link 定位链接的用法如下。

find_element_by_link_text()方法是通过元素标签对之间的文字信息来定位元素的。
4.1.6 partial link 定位
partial link 定位是对 link 定位的一种补充,有些文字链接比较长,这个时候我们可以取文字链接的部分文字进行定位,只要这部分文字可以唯一地标识这个链接即可。

通过 partial link 定位链接的用法如下。

find_element_by_partial_link_text()方法是通过元素标签对之间的部分文字定位元素的。
前面介绍的几种定位方法相对来说比较简单,在理想状态下,一个页面当中每个元素都有唯一的 id 值和 name 值,可以通过它们来查找元素。但在实际项目中并非想象得这般美好,有时候一个元素没有 id 值和 name 值,或者页面上有多个元素属性是相同的;又或者 id 值是随机变化的,在这种情况下,如何定位元素呢?
下面介绍 XPath 定位与 CSS 定位,与前面介绍的几种定位方式相比,它们提供了更加灵活的定位策略,可以通过不同的方式定位想要的元素。
4.1.7 XPath 定位
因为 HTML 可以看作 XML 的一种实现,在 XML 文档中,XPath 是一种定位元素的语言。所以 WebDriver 提供了这种在 Web 应用中定位元素的方法。
1.绝对路径定位
XPath 有多种定位策略,最简单直观的就是写出元素的绝对路径。如果把元素看作人,假设这个人没有任何属性特征(手机号、姓名、身份证号),但这个人一定存在于某个地理位置,如 xx 省 xx 市 xx 区 xx 路 xx 号。对于页面上的元素而言,也会有这样一个绝对地址。
参考F12开发者工具所展示的代码层级结构,我们可以通过下面的方式找到百度输入框和百度搜索按钮。

find_element_by_xpath()方法是用 XPath 来定位元素的。这里主要用标签名的层级关系来定位元素的绝对路径,最外层为 html,在 body 文本内,一级一级往下查找。如果一个层级下有多个相同的标签名,那么就按上下顺序确定是第几个。例如,div[2]表示当前层级下第二个 div 标签。
2.利用元素属性定位
除使用绝对路径外,XPath 还可以使用元素的属性值来定位。

//input 表示当前页面某个 input 标签,[@id='kw'] 表示这个元素的 id 值是 kw。下面通过 name 和 class 来定位。

如果不想指定标签名,那么可以用星号(*)代替。当然,使用 XPath 不局限于 id、name 和 class 这三个属性值,元素的任意属性都可以使用,只要它能唯一标识一个元素。

3.层级与属性结合
如果一个元素本身没有可以唯一标识这个元素的属性值,那么我们可以查找其上一级元素。如果它的上一级元素有可以唯一标识属性的值,就可以拿来使用。参考 baidu.html 文本。

假如百度输入框没有可利用的属性值,那么可以查找它的上一级属性。例如,小明刚出生的时候没有名字,也没有身份证号,那么亲朋好友来找小明时可以先找到小明的爸爸,因为他爸爸是有很多属性特征的。找到小明的爸爸后,就可以找到小明了。通过 XPath 描述如下:

//span[@class='s_ipt_wr'] 通过 class 定位到父元素,后面的/input 表示父元素下面的子元素。如果父元素没有可利用的属性值,那么可以继续向上查找父元素的父元素。
我们可以通过这种方法一级一级向上查找,直到找到最外层的 <html> 标签,那就是一个绝对路径的写法了。
4.使用逻辑运算符
如果一个属性不能唯一区分一个元素,那么我们可以使用逻辑运算符连接多个属性来查找元素。

and 表示必须满足两个条件来定位元素。
5.使用 contains 方法
contains 方法用于匹配一个属性中包含的字符串。例如,span 标签的 class 属性为「bg s_ipt_wr」。

contains 方法只取了 class 属性中的「s_ipt_wr」部分。
6.使用 text()方法
text()方法用于匹配显示文本信息。例如,前面通过 link text 定位的文字链接。

当然,contains 和 text()也可以配合使用。

它实现了 partial link 定位的效果。
4.1.8 CSS 定位
CSS 是一种语言,用来描述 HTML 文档的样式表现。CSS 使用选择器为页面元素绑定属性。
CSS 选择器可以较为灵活地选择控件的任意属性,一般情况下,CSS 定位速度比 XPath 定位速度快,下面介绍 CSS 选择器的语法与使用。
表 4-1 CSS 选择器的常见语法
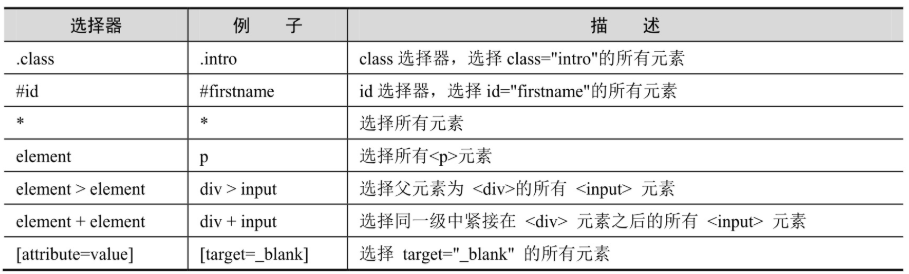
下面同样以百度输入框和百度搜索按钮为例,介绍 CSS 定位的用法。

1.通过 class 定位

find_element_by_css_selector()方法用于在 CSS 中定位元素,点号(.)表示通过 class 来定位元素。
2.通过 id 定位

井号(#)表示通过 id 来定位元素。
3.通过标签名定位

在 CSS 中,用标签名定位元素时不需要任何符号标识,直接使用标签名即可。
4.通过标签层级关系定位

这种写法表示有父元素,父元素的标签名为 span。查找 span 中所有标签名为 input 的子元素。
5.通过属性定位

在 CSS 中可以使用元素的任意属性定位,只要这些属性可以唯一标识这个元素。对属性值来说,可以加引号,也可以不加,注意和整个字符串的引号进行区分。
6.组合定位
我们可以把上面的定位策略组合起来使用,这就大大加强了定位元素的唯一性。

我们要定位的这个元素标签名为 input,这个元素的 class 属性为 s_ipt;并且它有一个父元素,标签名为 span。它的父元素还有父元素,标签名为 form,class 属性为 fm。我们要找的就是必须满足这些条件的一个元素。
CSS 选择器的更多用法可以查看 W3CSchool 网站中的 CSS 选择器参考手册(http://www.w3school.com.cn/cssref/css_selectors.asp)
通过前面的学习我们了解到,XPath 和 CSS 都提供了非常强大而灵活的定位方法。相比较而言,CSS 语法更加简洁,但理解和使用的难度要大一点。
7.更多定位用法

查找 class 属性包含「s_ipt_wr」字符串的元素。

查找 class 属性以「bg」字符串开头的元素。

查找 class 属性以「wrap」字符串结尾的元素。
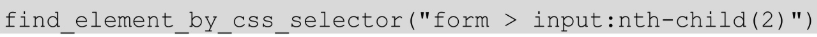
查找 form 标签下面第 2 个 input 标签的元素。
4.1.9 用 By 定位元素
针对前面介绍的 8 种定位方法,WebDriver 还提供了另外一套写法,即统一调用 find_element()方法,通过 By 来声明定位,并且传入对应定位方法的定位参数,具体如下。

find_element()方法只用于定位元素,它需要两个参数。第一个参数是定位的类型,由 By 提供;第二个参数是定位的值,在使用 By 之前需要先导入。

通过查看 WebDriver 的底层实现代码可以发现,它们其实是一回事儿。例如,id 定位方法的实现。



""" * name → find_element_by_name() * tag_name → find_element_by_tag_name() * class_name → find_element_by_class_name() * link_text → find_element_by_link_text() * partial_link_text → find_element_by_partial_link_text() * xpath → find_element_by_xpath() * css_selector → find_element_by_css_selector() """ from selenium import webdriver driver = webdriver.Chrome() # id 定位 driver.find_element_by_id("kw") driver.find_element_by_id("su") # name 定位 driver.find_element_by_name("wd") # class 定位 driver.find_element_by_class_name("s_ipt") # tag定位 driver.find_element_by_tag_name("input") # link text定位 driver.find_element_by_link_text("新闻") driver.find_element_by_link_text("hao123") driver.find_element_by_link_text("地图") driver.find_element_by_link_text("视频") driver.find_element_by_link_text("贴吧") # partial link定位 driver.find_element_by_partial_link_text("一个很长的") driver.find_element_by_partial_link_text("文本链接") # XPath 定位 # 1、绝对路径定位 driver.find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span/input") driver.find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span[2]/input") # 2、利用元素属性定位 driver.find_element_by_xpath("//input[@id='kw']") driver.find_element_by_xpath("//input[@id='su']") driver.find_element_by_xpath("//*[@name='wd']") driver.find_element_by_xpath("//*[@class='s_ipt']") driver.find_element_by_xpath("//input[@maxlength='100']") driver.find_element_by_xpath("//input[@autocomplete='off']") driver.find_element_by_xpath("//input[@type='submit']") # 3、层级与属性结合 driver.find_element_by_xpath("//span[@class='bg s_ipt_wr']/input") driver.find_element_by_xpath("//form[@id='form']/span/input") driver.find_element_by_xpath("//form[@id='form']/span[2]/input") # 4、使用逻辑运算符 driver.find_element_by_xpath("//input[@id='kw' and @class='s_ipt']") # 5、使用contains方法 driver.find_element_by_xpath("//span[contains(@calss,'s_ipt_wr')]/input") # 6、使用text()方法 driver.find_element_by_xpath("//a[text(),'新闻')]") driver.find_element_by_xpath("//a[contains(text(),'一个很长的')]") # CSS 定位 # 1.通过class属性定位 driver.find_element_by_css_selector(".s_ipt") driver.find_element_by_css_selector(".s_btn") # 2、通过id属性定位 driver.find_element_by_css_selector("#kw") driver.find_element_by_css_selector("#su") # 3、通过标签名定位 driver.find_element_by_css_selector("input") # 4、通过标签层级关系定位 driver.find_element_by_css_selector("span > input") # 5、通过属性定位 driver.find_element_by_css_selector("[autocomplete=off]") driver.find_element_by_css_selector("[name='kw']") driver.find_element_by_css_selector('[type="submit"]') # 6、组合定位 driver.find_element_by_css_selector("form.fm > span > input.s_ipt") driver.find_element_by_css_selector("form#form > span > input#kw") # 7、更多定位用法 driver.find_element_by_css_selector("[class*=s_ipt_wr]") driver.find_element_by_css_selector("[class^=bg]") driver.find_element_by_css_selector("[class$=wrap]") driver.find_element_by_css_selector("form > input:nth-child(2)")
对于 Web 自动化来说,学会元素的定位相当于自动化已经学会了一半,剩下的就是学会使用 WebDriver 中提供的各种方法,接下来我们将通过实例介绍这些方法的具体使用。

