
【软件测试】4.编程数据结构python学习day05day06
3 容器
学习目标
1. 能够说出容器类型有什么用
2. 能够说出常用 Python 容器的名字
3. 能够说出切片语法的用途
4. 能够说出容器中的索引指的是什么
5. 能够说出如何定义一个字符串
6. 能够说出字符串容器的特性
7. 能够说出至少5个字符串方法名字和作用
8. 能够使用切片语法获得指定索引区间的子串
9. 能够说出如何使用 while 和 for 循环来遍历字符串
10. 能够说出如何定义一个列表
11. 能够说出列表容器和字符串容器的区别
12. 能够说出至少5个列表方法名字和作用
13. 能够使用切片语法获得列表指定索引区间的元素
14. 能够说出如何使用 while 和 for 循环来遍历列表中的元素
15. 能够说出如何定义一个列表
16. 能够说出元组和列表的区别
17. 能够说出如何使用 while 和 for 循环来遍历元组中的元素
18. 能够说出元组支持哪些操作
19. 能够说出如何定义一个字典
20. 能够说出字典和列表的区别
21. 能够说出如何使用 for 循环来遍历列表中的键、值和键值
22. 能够说出字典键和值的特点
容器分类?
学习容器类型就是在学习容器的特点、以及容器对元素的操作
为了便于学习, 我们根据不同容器的特性, 将常用容器分为序列式容器和非序列式容器
1. 序列式容器中的元素在存放时都是连续存放的, 也就是序列式容器中, 除了第一个元素的前面没有元素,
最后一个元素的后面没有元素, 其他所有的元素前后都有一个元素. 包括字符串、列表、元组
2. 非序列式容器在存储元素时不是连续存放的, 容器中的任何一个元素前后都可能没有元素. 包括字典、集合
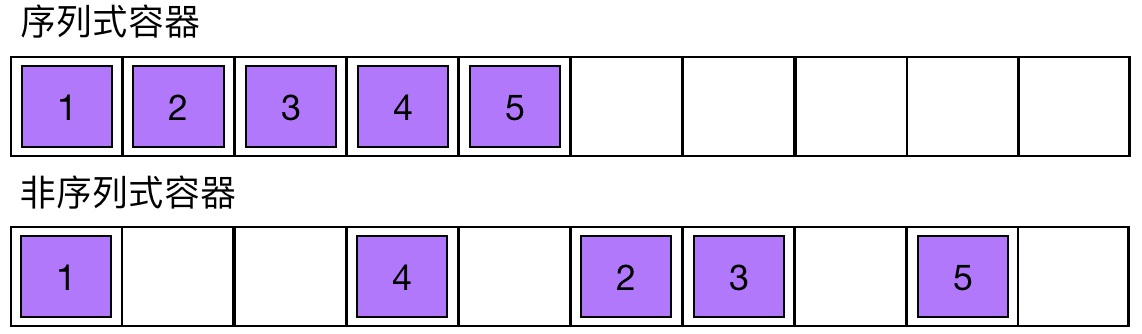
- 序列式容器支持根据索引(下标)访问元素, 而非序列式容器不支持索引(下标)的方式访问元素
- 序列式容器支持切片操作, 而非序列式容器不支持切片操作
什么是切片?
通过索引可以获取序列式容器中的某个元素, 切片语法主要用于获得一个指定索引区间的多个元素, 例如获取从索引值为 0 到索引值为 5 之间的所有元素
上面所说的 "方法", 就是我们所说所学的函数, 本质上 "方法"和"函数"指的是同一个东西
3.1 字符串
学习目标
1. 能够说出如何定义一个字符串
2. 能够说出字符串容器的特性
3. 能够说出如何对字符串中的子串进行替换
4. 能够说出如何对字符串中的字符串进行查找
5. 能够说出如何去除字符串两侧的空格
6. 能够说出如何判断字符串是否全部为字母
7. 能够说出字符串如何根据某个分隔符进行切分
8. 能够使用切片语法获得指定索引区间的子串
9. 能够说出如何使用 while 和 for 循环来遍历字符串
3.1.1 字符串语法格式
如何定义字符串?
1. 字符串使用一对单引号来定义
2. 字符串使用一对双引号来定义
3.1.2 字符串操作
1 字符串遍历
字符串属于序列式容器, 支持依据索引的操作
注意: 序列式容器的索引都是以 0 开始的, 并不是从 1 开始
my_string = '我叫做司马相如,我今年16岁了!' i = 0 while i < len(my_string): print(my_string[i], end=' ') i += 1
Python 是一门简单易用的语言, 对于容器的遍历, 提供了另外一种简单方式, for 循环
my_string = '我叫做司马相如,我今年16岁了!' for ch in my_string: print(ch, end=' ')
2 字符串替换
使用字符串的 replace 方法完成上面两步. 该方法默认会将字符串中所有指定字符或子串替换为新的字符串,
我们可以指定第三个参数, 替换多少次
poetry = '远看泰山黑乎乎, 上头细来下头粗. 茹把泰山倒过来, 下头细来上头粗. 茹' # 将所有的 '茹' 替换为 '如' right_poetry = poetry.replace('茹', '如') # 只替换第一次出现的 '茹' right_poetry = poetry.replace('茹', '如', 1)
3 字符串查找和切片
现在有一邮箱地址如下:
user_email = 'simagousheng@itcast.cn’
我们希望从邮箱地址字符串中获取用户名和邮箱后缀名, 那么这个问题如何解决?
1. 由分析可知, @符号之前为用户名, @符号之后的内容为邮箱后缀名
2. 首先获得 @ 符号的位置, 从开始位置截取到 @ 符号位置, 即可获得用户
3. 从 @ 符号位置开始截取到字符串最后, 即可获得邮箱后缀名
如何获得 @ 符号的位置?
可以使用字符串提供的 find 方法, 该方法可返回查找字符串第一次出现的位置, 查找字符串不存在则会返回-1
备注: find 方法默认从字符串开始位置(0位置)开始查找, 我们也可以指定从哪个位置范围开始查找, 设置 find 的
第二个参数表示从哪个位置开始查找, 第三个参数, 表示查找结束位置
poetry = '远看泰山黑乎乎, 上头细来下头粗. 茹把泰山倒过来, 下头细来上头粗.' # 从 10 位置开始查找 '上' position = poetry.find('上', 10, 100)
如何获得指定范围的字符串?
字符串属于序列式容器, 可以根据索引获得某一个字符, 也可以根据由两个索引标识的区间获得区间内的字符序列


poetry = '远看泰山黑乎乎, 上头细来下头粗. 茹把泰山倒过来, 下头细来上头粗.' # 从0位置开始到7位置之前, 不包含7位置字符 print(poetry[0: 7]) # 起始位置不写, 默认就是0 print(poetry[: 7]) # 从0位置开始到最后, 结束位置不写默认字符最后一个位置的下一个位置. print(poetry[9:]) # 步长, 每隔2个字符选取一个字符, 组成一个序列 print(poetry[0: 7: 2]) # 如果步长为负数, 那么起始位置参数和结束位置参数就会反过来. print(poetry[6:: -1]) # 位置也可以使用负数 print(poetry[-3: -1]) print(poetry[-3:]) print(poetry[::-1])
下面我们看看如何解决这个问题?
user_email = 'simagousheng@itcast.cn' # 查找 @ 位置 position = user_email.find('@') # 根据 postion 截取用户名和邮箱后缀 user_name = user_email[: position] mail_suffix = user_email[position + 1:]
另外一种解决该问题的思路
1. 先根据 @ 符号将邮箱分割成两部分
2. 分别获取每一部分, 即可得到用户名和邮箱后缀
user_email = 'simagousheng@itcast.cn' # 判断 user_email 是否有多个 @ at_count = user_email.count('@') if at_count > 1: print('邮箱地址不合法, 出现了多个@符号!') else: # 根据 @ 将字符串截取为多个部分 result = user_email.split('@') # 输出用户名和邮箱后缀 print(result[0], result[1])
4 字符串去除两侧空格、是否为字母
我们经常在各个网站进行会员注册, 一般注册的处理流程如下:
1. 获得用户输入的注册用户名
2. 用户在输入用户名时, 可能在用户名两个不小心输入多个空格. 我们需要去除用户名两侧的空格
3. 判断用户名是否全部为字母(用户名的组成由我们来规定, 这里我们规定必须是字母)
4. 处理完毕之后, 显示注册成功
# 获得用户注册用户名 register_username = input('请输入您的用户名:') # 去除用户名两侧的空格 register_username = register_username.strip() # 判断字符串是否全部为字母 if register_username.isalpha(): print('恭喜您:', register_username, '注册成功!') else: print('注册失败!')
3.2 列表
学习目标
1. 能够说出如何定义一个列表
2. 能够说出列表容器和字符串容器的区别
3. 能够说出如何向列表中添加元素
4. 能够说出如何删除列表中的一个元素
5. 能够说出如何对列表中的元素进行排序
6. 能够说出如何对列表中元素进行查询
7. 能够说出如何判断列表中是否存在某个元素
8. 能够使用切片语法获得列表指定索引区间的元素
9. 能够说出如何使用 while 和 for 循环来遍历列表中的元素
3.2.1 列表语法格式
如果需要存储的数据并非单一类型, 并且需要频繁修改, 如何解决?
我们可以使用列表容器类型, 列表中存储的元素可以是多种数据类型, 甚至存储的数据类型都不一样, 并且列表支持对元素的修改、删除等操作
列表也是一个序列式容器, 同样支持索引和切片语法
# 创建空列表 my_list = [] # 创建带有元素的列表 my_list = [10, 20, 30] # 通过索引来访问列表中元素 print(my_list[0]) # 也可以通过索引来修改元素 my_list[0] = 100 # 通过切片语法获得区间元素 print(my_list[1:]) # 列表可存储不同类型的数据 my_list = ['John', 18, True] # 列表中也可存储列表 my_list = [[10, 20], [30, 40], [50, 60]]
注意: 列表中支持存储不同类型的数据, 如果有没有特殊需求, 建议存储相同类型数据. 这样可以对数据应用统一的操作
3.2.2 列表操作
1 列表遍历
my_list = [1, 2, 3, 4, 5] i = 0 while i < len(my_list): print(my_list[i], end=' ') i += 1
我们也可以用 for 循环来简化列表的遍历操作
my_list = [1, 2, 3, 4, 5] for val in my_list: print(val, end=' ')
2 列表查找和修改
已知: 列表中包含 5 个元素, 分别为: 10、 20、 30、 40、 50. 需要将列表中 40 这个元素替换成 100, 如何实现?
1. 列表不存在类似字符串 replace 的方法
2. 查询 40 这个元素在列表中的索引位置
3. 根据索引位置修改元素为 100
index 方法可以根据值查找, 查找到返回该值元素所在的位置, 查找失败会报错, 程序终止. 我们可以先使用 count 方法
统计值出现的次数, 如果不为0, 再使用 index 方法
my_list = [10, 20, 30, 40, 50] # 要修改的值 old_value = 40 # 更新的新值 new_value = 100 # 判断要修改的值是否存在 if my_list.count(old_value): # 获得指定值的位置 position = my_list.index(old_value) # 根据值来修改元素 my_list[position] = new_value print(my_list)
如果我们只是关心值是否存在, 而并不关心出现多少次, 可以使用 in 或者 not in 运算符
1. in 可以判断元素是否存在, 存在返回 True, 不存在返回 False
2. not in 可以判断元素是否不存在, 不存在返回 True, 存在返回 False
以上代码可修改为:
my_list = [10, 20, 30, 40, 50] # 要修改的值 old_value = 40 # 更新的新值 new_value = 100 # 判断要修改的值是否存在 if old_value in my_list: # 获得指定值的位置 position = my_list.index(old_value) # 根据值来修改元素 my_list[position] = new_value print(my_list)
3 列表的插入和删除元素
列表是一个容器, 我们可以向容器中添加和删除元素.
插入元素分为:
1. 插入单一元素. 1.1 尾插. 1.2 指定位置插入.
2. 插入一个列表(多个元素).
Python 提供了 append 方法, 用于向列表尾部添加元素, insert 方法用于向列表指定的索引位置插入元素,
extend 方法用于将另外一个列表中的所有元素追加到当前列表的尾部.
删除分为两种:
1. 根据值删除, 使用 remove 方法. 该方法只能删除第一次出现的值
2. 根据索引删除, 使用 pop 方法, 该方法不传递索引时默认删除最后一个元素, 传递索引则根据索引删除元素
# 插入元素分为两种: 尾部插入 指定位置插 # 创建空列表 my_list = [] # 向列表中添加元素 my_list.append(10) my_list.append('Obama') # 在指定位置插入元素 my_list.insert(1, 20) # 输出内容 print(my_list) # 创建新的列表 new_list = [100, 200, 300] # 合并两个列表 my_list.extend(new_list) print(my_list) # 删除分为两种: 根据值删除, 根据位置(索引)删除 my_list = [10, 20, 30, 20] # 根据索引删除 my_list.pop(2) print(my_list) # 根据值删除 my_list.remove(20) print(my_list) # 删除所有元素 my_list.clear() # 显示列表中还剩下多少元素 print(len(my_list))
4 列表元素排序
排序指的是记录按照要求排列. 排序算法在很多领域得到相当地重视.
列表提供了相关方法来对列表中的元素进行排序. 分别是:
1. 将列表中的元反转
2. 列表中的元素升序(从小到大)、降序排列(从大到小)
import random my_list = [] # 产生一个包含10个随机数的列表 i = 0 while i < 10: random_number = random.randint(1, 100) my_list.append(random_number) i += 1 # 打印列表中的元素 print('my_list:', my_list) # 对列表中的反转 my_list.reverse() # 打印列表中的元素 print('my_list:', my_list) # 对列表中的元素排序, 默认升序 my_list.sort() print('my_list:', my_list) # 对列表中的元素排序, 降序排列 my_list.sort(reverse=True) print('my_list:', my_list)
5 列表练习
一个学校, 有3个办公室, 现在有 8 位老师等待工位的分配, 请编写程序, 完成随机的分配
思路分析如下:
1. 待分配的 8 位老师需要存储, 我们可以用列表来暂时存储 8 位老师
2. 一个学校中包含了多个办公室, 学校可用列表来表示, 学校中又包含了多个办公室, 每个办公室里可能有多个老师, 办公室仍然可用列表来表示
3. 从待分配老师列表中取出数据, 随机产生办公室编号, 将该老师分配到该办公室
4. 打印各个办公室中的老师列表
import random # 定义一个列表用来存储8位老师的名字 teacher_list = [] i = 0 while i < 8: teacher_name = '老师' + str(i + 1) teacher_list.append(teacher_name) i += 1 # 定义学校并包含3个办公室 school = [[], [], []] # 获取每个老师并随机分配办公室 for teacher in teacher_list: office_nunmber = random.randint(0, 2) school[office_nunmber].append(teacher) # 打印各个办公室的老师列表 for office in school: for teacher in office: print("%s" % teacher, end=' ') print('\n' + '*' * 20)
3.3 元组
学习目标
1. 能够说出如何定义一个列表
2. 能够说出元组和列表的区别
3. 能够说出如何使用 while 和 for 循环来遍历元组中的元素
4. 能够说出元组支持哪些操作
3.3.1 元组语法和方法
Python的元组与列表类似, 不同之处在于元组的元素不能修改. 元组改用小括号来定义, 列表使用方括号来定义
由于元组不支持修改, 所以元组只支持遍历、查找操作.
元组同样属于序列式容器, 支持索引和切片语法
1. 查询元素: count 、 index
2. 遍历操作: while、 for
# 定义元组 my_tuple = (10, 20, 30) my_tuple = ((10, 20, 30), (100, 200, 300)) # 遍历 for ele in my_tuple: for val in ele: print(val) # 查找 my_tuple = (10, 20, 30) # 判断元素是否存在 if my_tuple.count(20) > 0: index = my_tuple.index(20) print('元素的位置:', index) if 20 in my_tuple: index = my_tuple.index(20) print('元素的位置:', index)
注意: 如果定义的元素中只有一个元素, 需要额外添加一个逗号在元素后
my_tuple = (10,) my_tuple = ((10, 20, 30), ) my_tuple = ((10, ), )
3.3.2 小结
1. 元组使用一对小括号来定义, 在定义之后不允许对元素进行修改.
2. 元组中只有一个元素时, 需在最尾部添加一个逗号.
3. 元组是序列式容器, 支持索引、切片操作.
4. 元组比列表更节省空间.
3.4 字典
学习目标
1. 能够说出如何定义一个字典
2. 能够说出字典和列表的区别
3. 能够说出如何使用 for 循环来遍历列表中的键、值和键值对
4. 能够说出字典键和值的特点
Python 提供了字典这种容器类型, 字典中存储的每一个元素都是键值对, 并且在字典中根据键(关键字)去查找某个元素的效率非常高
为了实现高的查询效率, 字典被实现成了一种非序列式容器, 也就导致字典无法根据索引获得元素, 同样也不支持切片操作
3.4.1 字典语法格式
字典是另一种可存储任意类型对象. 字典中的每一个元素都是一个 "键值对", 键值之间用冒号(:)分割, 每个字典元素
(键值对)之间用逗号(,)分割, 整个字典包括在花括号 {} 中, 格式如下所示:
my_dict = {key1: value1, key2: value2, key3: value3}
字典键和值的特点:
1. 键一般是唯一的, 如果重复最后的一个键值对会替换前面的, 键的类型一般情况下使用字符串、数字类型
2. 值不需要唯一, 可以为任何的数据类型
3.4.2 字典操作
3.4.2.1 访问元素
字典中根据键获得值的操作, Python 提供了两种方式:
1. 直接通过键来获得, 但当键不存在时, 会抛出错误
2. 通过 get 方法来根据键获得值, 如果键不存在则会返回 None, 该返回默认值也可自定义
person = {'name': 'Obama', 'age': 18, 'sex': '男'}
# 如果 key 不存在会报错
print(person['name'])
# 如果 key 不存在可设置默认值
print(person.get('gender', 'default'))
3.4.2.2 添加和修改元素
在字典中修改元素, 直接通过键来修改即可. 这时需要注意, 如果键不存在, 默认为新增元素操作, 只有键存在时, 才为修改操作
person = {'name': 'Obama', 'age': 18, 'sex': '男'}
# 如果 key 不存在则为添加新元素
person['salay'] = 12000
# 如果 key 存在则为修改元素
person['age'] = 20
3.4.2.3 删除元素
Python 中字典中元素的删除, 需要根据键来进行, 我们可以使用 pop 方法根据 key 来删除字典中的元素
person = {'name': 'Obama', 'age': 18, 'sex': '男'}
# 删除某个元素
person.pop('name')
# 清空字典
person.clear()
3.4.2.4 遍历元素
由于字典是非序列式容器, 无法通过逐个获取元素, 所以遍历字典的方式就是先将字典转换成类似列表的形式, 再对
其进行遍历. 在获得字典的列表时, 我们有以下三个方案:
1. 获得字典键的列表, 通过字典的 keys 方法
2. 获得字典值的列表, 通过字典的 values 方法
3. 字典的 items 方法将每一个键值对存放到元组中, 然后将'元组' 构成的'列表'返回
person = {'name': 'Obama', 'age': 18, 'sex': '男'}
# 获得字典的值列表
print(person.values())
# 获得字典的键列表
print(person.keys())
# 获得字典的键值对列表
print(list(person.items()))
for key, value in person.items():
print(key, value)
3.5 集合
学习目标
1. 能够说出如何创建集合
2. 能够说出字典和集合的区别
3. 能够说出如何向集合中添加元素
4. 能够说出如何删除集合中的某个元素
5. 能够说出如何使用 for 循环来遍历集合
6. 能够说出如何计算两个集合的交集
7. 能够说出如何计算两个集合的并集
set集合是一个无序不重复元素集。由于set是一个无序集合, set并不记录元素位置,所以不支持下标操作和切片操作
3.5.1 创建集合
# 1. 创建一个空的set集合 my_set = set() # 2. 创建一个包含元素的集合 my_set = {10, 20, 30, 40} print(my_set) # 3. 用一个容器来创建集合 # 注意: set会剔除重复元素 my_set = set([1, 2, 3, 4, 5, 5]) print(my_set) # 4. 创建一个唯一元素的字符集合 my_set = set("hello world!") print(my_set)
3.5.2 集合添加元素
向set集合中添加元素,可以使用add()函数和update()函数, add()可以一次添加一个元素, update()函数可以一次添加多个元素
# 创建一个空的集合 my_set = set() # add()函数向set中添加元素 my_set.add(10) my_set.add(20) my_set.add(30) # 打印set集合 print(my_set) # update()函数添加多个元素 my_set.update([60, 40, 80, 90]) my_set.update((160, 140, 180, 190)) my_set.update("hello") # 如果添加的元素是一个字典,那么将字典的key添加到集合中 # my_set.update({"name": "smith", "age": 1030}) print(my_set)
3.5.3 集合删除元素
删除set集合中的元素可以使用pop()、 remove()函数、 discard()函数
1. pop()函数会删除set集合中的任意一个元素,如果set集合为空,会抛出KeyError错误。
2. remove(element)函数从集合中删除一个元素,如果元素不存在,会抛出KeyError错误。
3. discard(val)函数删除集合中的一个元素,如果不存在,则不做任何事。
my_set = set([9, 2, 3, 4, 7]) # 删除任意一个元素 my_set.pop() print(my_set) # 删除指定元素 my_set.remove(4) print(my_set) # 删除元素 my_set.discard(3) print(my_set)
3.5.4 集合遍历
# 创建一个空的集合 my_set = set([1, 2, 3, 4]) # 遍历set集合 for value in my_set: print(value, end="|")
3.5.5 集合交集和并集
my_set1 = set([1, 2, 3, 4, 5]) my_set2 = set([3, 4, 5, 6, 7]) # 1. 求两个集合的并集 new_set1 = my_set1.union(my_set2) # 或者 new_set2 = my_set1 | my_set2 print(new_set1) print(new_set2) # 2. 求两个集合的交集 new_set3 = my_set1.intersection(my_set2) # 或者 new_set4 = my_set1 & my_set2 print(new_set3) print(new_set4)
3.5.6 set应用: 统计字符个数
# 统计字符串中字符的个数 my_string = input("请输入任意字符串:") # 先对字符串去重 new_string = set(my_string) # 字典记录字符出现次数 my_count = {} # 遍历new_string for ch in new_string: my_count[ch] = my_string.count(ch) # 输出结果 print(my_count)

