
14 微服务电商【黑马乐优商城】:day02-springcloud(理论篇四:配置Robbin负载均衡)
本项目的笔记和资料的Download,请点击这一句话自行获取。
day01-springboot(理论篇) ;day01-springboot(实践篇)
day02-springcloud(理论篇一) ;day02-springcloud(理论篇二) ;day02-springcloud(理论篇三:搭建Eureka注册中心) ;day02-springcloud(理论篇四:配置Robbin负载均衡)
14 微服务电商【黑马乐优商城】:day02-springcloud
0.学习目标
- 了解系统架构的演变
- 了解RPC与Http的区别
- 掌握HttpClient的简单使用
- 知道什么是SpringCloud
- 独立搭建Eureka注册中心
- 独立配置Robbin负载均衡
7.负载均衡Robbin
在刚才的案例中,我们启动了一个user-service,然后通过DiscoveryClient来获取服务实例信息,然后获取ip和端口来访问。
但是实际环境中,我们往往会开启很多个user-service的集群。此时我们获取的服务列表中就会有多个,到底该访问哪一个呢?
一般这种情况下我们就需要编写负载均衡算法,在多个实例列表中进行选择。
不过Eureka中已经帮我们集成了负载均衡组件:Ribbon,简单修改代码即可使用。
什么是Ribbon:

接下来,我们就来使用Ribbon实现负载均衡。
7.1.启动两个服务实例
首先我们启动两个user-service实例,一个8081,一个8082。
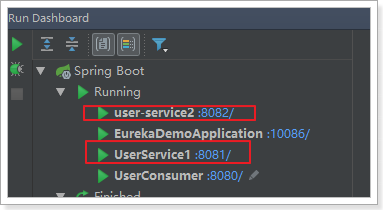
Eureka监控面板:

7.2.开启负载均衡
因为Eureka中已经集成了Ribbon,所以我们无需引入新的依赖。直接修改代码:
在RestTemplate的配置方法上添加@LoadBalanced注解:
@Bean @LoadBalanced public RestTemplate restTemplate() { return new RestTemplate(new OkHttp3ClientHttpRequestFactory()); }
修改调用方式,不再手动获取ip和端口,而是直接通过服务名称调用:
@Service public class UserService { @Autowired private RestTemplate restTemplate; @Autowired private DiscoveryClient discoveryClient; public List<User> queryUserByIds(List<Long> ids) { List<User> users = new ArrayList<>(); // 地址直接写服务名称即可 String baseUrl = "http://user-service/user/"; ids.forEach(id -> { // 我们测试多次查询, users.add(this.restTemplate.getForObject(baseUrl + id, User.class)); // 每次间隔500毫秒 try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } }); return users; } }
访问页面,查看结果:
7.3.源码跟踪
为什么我们只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然有人帮我们根据service名称,获取到了服务实例的ip和端口。它就是LoadBalancerInterceptor
我们进行源码跟踪:
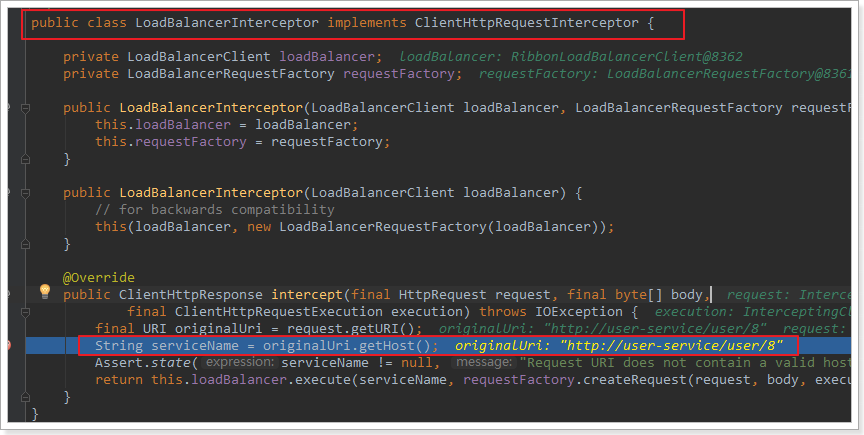
继续跟入execute方法:发现获取了8082端口的服务
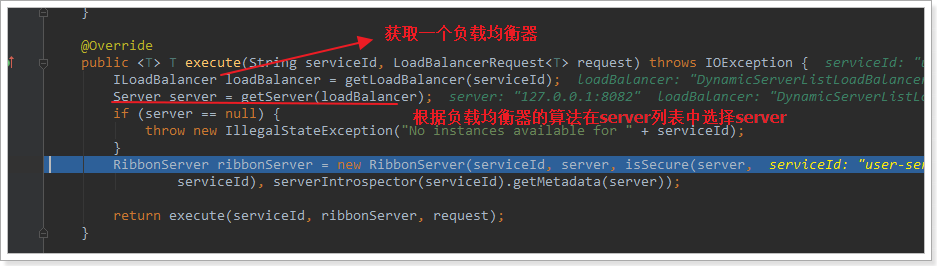
再跟下一次,发现获取的是8081:
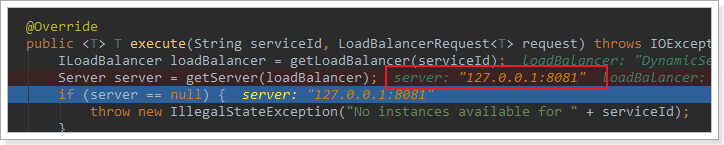
7.4.负载均衡策略
Ribbon默认的负载均衡策略是简单的轮询,我们可以测试一下:
编写测试类,在刚才的源码中我们看到拦截中是使用RibbonLoadBalanceClient来进行负载均衡的,其中有一个choose方法,是这样介绍的:
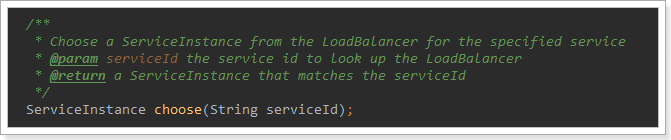
现在这个就是负载均衡获取实例的方法。
我们对注入这个类的对象,然后对其测试:
@RunWith(SpringRunner.class) @SpringBootTest(classes = UserConsumerDemoApplication.class) public class LoadBalanceTest { @Autowired RibbonLoadBalancerClient client; @Test public void test(){ for (int i = 0; i < 100; i++) { ServiceInstance instance = this.client.choose("user-service"); System.out.println(instance.getHost() + ":" + instance.getPort()); } } }
结果:
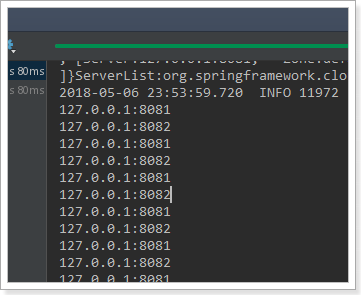
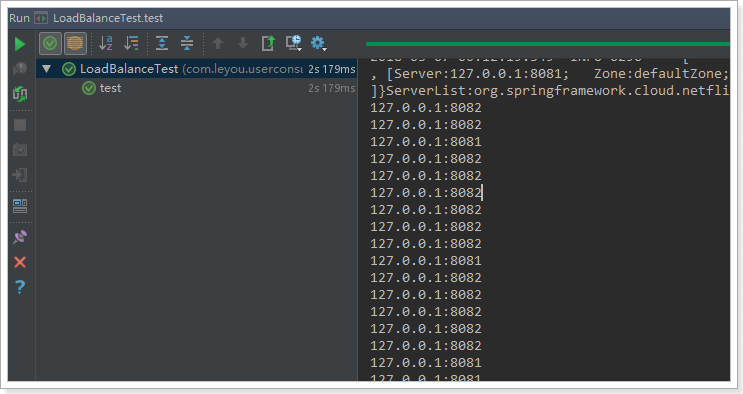
符合了我们的预期推测,确实是轮询方式。
我们是否可以修改负载均衡的策略呢?
继续跟踪源码,发现这么一段代码:

我们看看这个rule是谁:
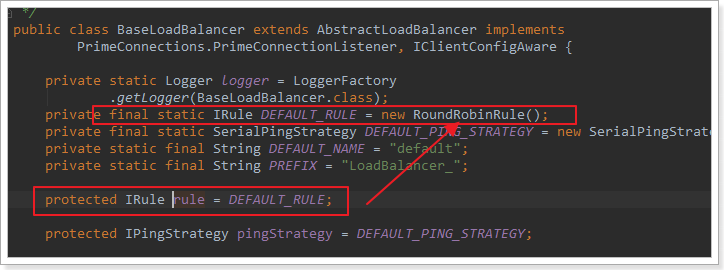
这里的rule默认值是一个RoundRobinRule,看类的介绍:
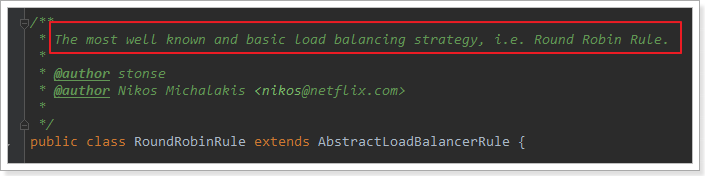
这不就是轮询的意思嘛。
我们注意到,这个类其实是实现了接口IRule的,查看一下:
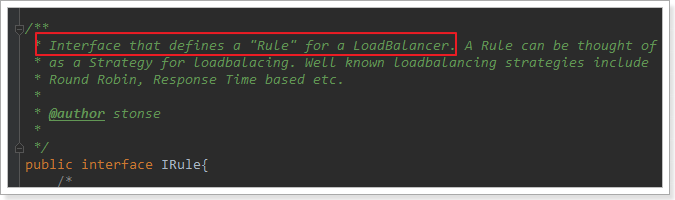
定义负载均衡的规则接口。
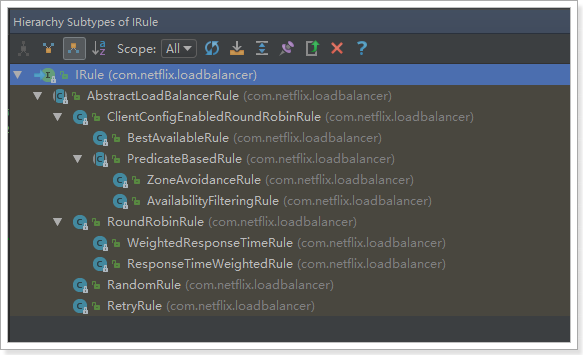
它有以下实现:
SpringBoot也帮我们提供了修改负载均衡规则的配置入口:
user-service:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
格式是:{服务名称}.ribbon.NFLoadBalancerRuleClassName,值就是IRule的实现类。
再次测试,发现结果变成了随机:
7.5.重试机制
Eureka的服务治理强调了CAP原则中的AP,即可用性和可靠性。它与Zookeeper这一类强调CP(一致性,可靠性)的服务治理框架最大的区别在于:Eureka为了实现更高的服务可用性,牺牲了一定的一致性,极端情况下它宁愿接收故障实例也不愿丢掉健康实例,正如我们上面所说的自我保护机制。
但是,此时如果我们调用了这些不正常的服务,调用就会失败,从而导致其它服务不能正常工作!这显然不是我们愿意看到的。
我们现在关闭一个user-service实例:
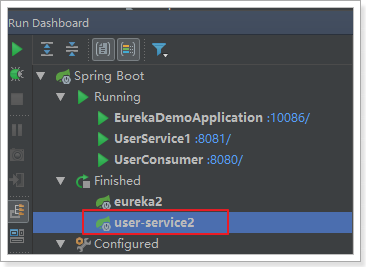
因为服务剔除的延迟,consumer并不会立即得到最新的服务列表,此时再次访问你会得到错误提示:
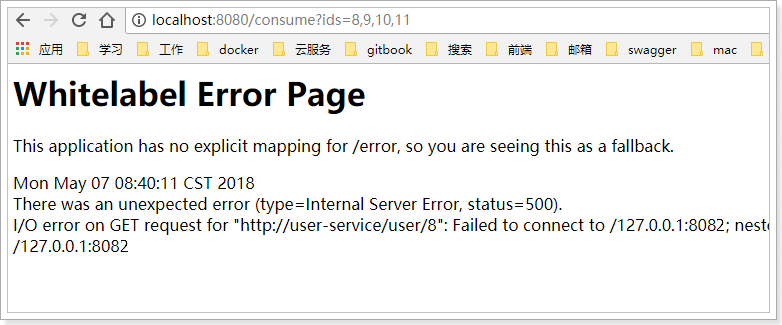
但是此时,8081服务其实是正常的。
因此Spring Cloud 整合了Spring Retry 来增强RestTemplate的重试能力,当一次服务调用失败后,不会立即抛出一次异常,而是再次重试另一个服务。
只需要简单配置即可实现Ribbon的重试:
spring: cloud: loadbalancer: retry: enabled: true # 开启Spring Cloud的重试功能 user-service: ribbon: ConnectTimeout: 250 # Ribbon的连接超时时间 ReadTimeout: 1000 # Ribbon的数据读取超时时间 OkToRetryOnAllOperations: true # 是否对所有操作都进行重试 MaxAutoRetriesNextServer: 1 # 切换实例的重试次数 MaxAutoRetries: 1 # 对当前实例的重试次数
根据如上配置,当访问到某个服务超时后,它会再次尝试访问下一个服务实例,如果不行就再换一个实例,如果不行,则返回失败。切换次数取决于MaxAutoRetriesNextServer参数的值。
引入spring-retry依赖
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
我们重启user-consumer-demo,测试,发现即使user-service2宕机,也能通过另一台服务实例获取到结果!
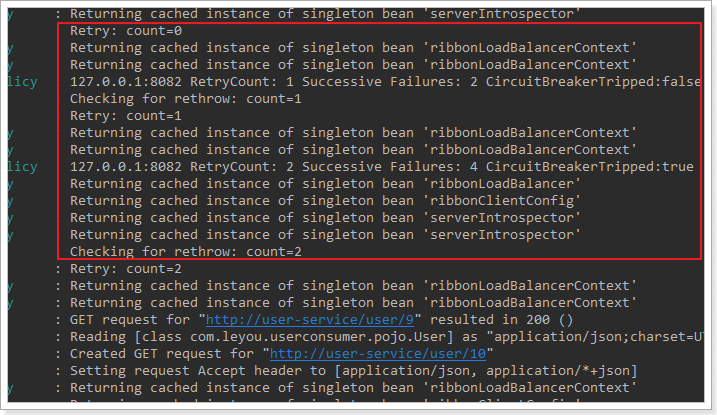
=============================================
参考资料:
Spring Cloud升级最新Finchley版本的所有坑
end

