第三次作业_201731062533
2019-04-01 12:36 MarkarovZ 阅读(314) 评论(4) 收藏 举报 作业地址:https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass2/homework/2879
作业地址:https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass2/homework/2879
GIT仓库地址:https://github.com/MarkarovZ/WordCount.git
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
10 | 15 |
|
· Estimate |
· 估计这个任务需要多少时间 |
120 | 140 |
|
Development |
开发 |
100 | 120 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
10 | 5 |
|
· Design Spec |
· 生成设计文档 |
0 | 0 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
0 | 0 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
10 | 30 |
|
· Design |
· 具体设计 |
15 | 15 |
|
· Coding |
· 具体编码 |
45 | 45 |
|
· Code Review |
· 代码复审 |
10 | 5 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
10 | 20 |
|
Reporting |
报告 |
20 | 20 |
|
· Test Report |
· 测试报告 |
10 | 10 |
|
· Size Measurement |
· 计算工作量 |
5 | 5 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
5 | 5 |
|
合计 |
120 | 140 |
一、开始前的讨论
因为大一的时候写过类似的检测txt文本内容并进行分类的程序,这次讨论很快就把任务定下来了,并开始着手开始开发。
我负责代码的编写和功能实现,宋杰同学负责复审与测试。
这个作业要求内容不多,也就没去查或者学习什么新能力。
二、设计部分:
以下是代码设计图:

我并没有把对行、字符与单词以及词组的检索计数分开,因为这几个任务可以在一次遍历内完成,如果分成几个单独的函数的话,反而会因为多次重复遍历增加时间上的开销。但这样就造成了主要功能函数MainCount的圈复杂度高,可维护性低,可扩展性低。不同功能之间的耦合度高,所以要改写成带图形界面的窗口程序的话,需要重构该函数。
三、实际编码部分:


/// <summary> /// 对字符、单词、行计数 /// </summary> void MainCount() { int wordJudge = 0;//单词长度标记 int MutiWords = 0;//判断目前是否为词组记录状态的标志变量 int MutiWordsJudge = 0;//词组长度标记 bool isWord = true; string _word = ""; foreach (var str in Lines) { int lineJudge = 0; foreach (var word in str) { //判断当前检测字符是否为空 if (word != ' ') { lineJudge++; characters++; //判断当前是否为单词检测状态,判断当前检测字符是否为字母 if ((isWord == true) && (((word >= 65) && (word <= 90)) || ((word >= 97) && (word <= 122))))//判断是否为字母内容 { wordJudge++; _word = _word + word; } else { //切换至非单词状态 if (wordJudge == 0) { isWord = false; MutiWords++; } else { //判断当前是否为单词数字后缀 if ((wordJudge >= 4) && ((word >= 48) && (word <= 57))) { _word = _word + word; } else { //判断是否已经构成单词 if (wordJudge >= 4) { WordAdd(_word); wordJudge = 0; _word = ""; } //结束当前判断周期,重新切换至单词检测状态 else { wordJudge = 0; _word = ""; isWord = true; MutiWords = 0; } } } } } else { MutiWordsJudge++; //检测到空字符时结束当前判断周期,开启新周期 isWord = true; MutiWords = 0; //判断当前检测结果是否构成单词 if (wordJudge >= 4) { WordAdd(_word); wordJudge = 0; _word = ""; } else { MutiWords++; wordJudge = 0; _word = ""; MutiWordsJudge = 0; } if ((MutiWords == 0) && (MutiWordsJudge == number)) { MutiWordsAdd(); MutiWordsJudge = 0; } } } //在行末判断是否已构成单词 if (wordJudge >= 4) { WordAdd(_word); wordJudge = 0; _word = ""; if ((MutiWords == 0) && (MutiWordsJudge == number - 1)) { MutiWordsAdd(); MutiWordsJudge = 0; } } //判断当前行是否为有效行 if (lineJudge != 0) { lines++; } } }
以下是运行截图
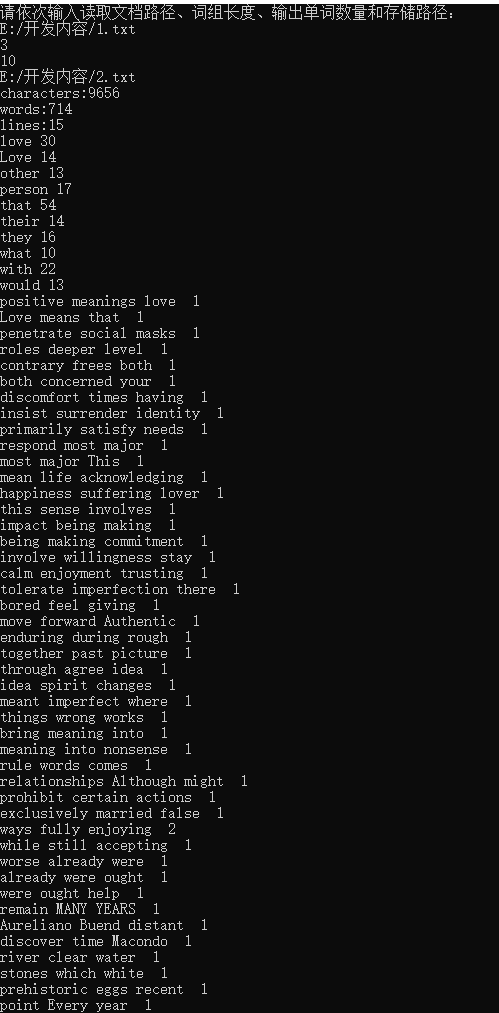

四、测试部分



从性能分析的结果上来看,负责输出部分的函数占用时间都比主要功能算法多,输出部分的时间开销基本都在对要输出结果的遍历上,目前我没想到有什么能优化的地方。
[TestMethod] public void TestMethod1() { string l_path = "E:/开发内容/1.txt"; string r_path = "E:/开发内容/2.txt"; int num = 5; int outNum = 3; Program program = new Program(); program.TestMethod(l_path, r_path, num, outNum); var res = Program.program; Assert.AreEqual(9656, res.characters); Assert.AreEqual(15, res.lines); }
在单元测试中宋杰同学对检索的有效行数目以及有效字符数进行了断言测试,测试结果正常。
五、总结
我有在编码过程中每结束一个小模块的编写,就进行测试检验的习惯,所以在后面宋杰同学复测的时候并没有遇到什么严重错误,运行时一次过的,但发现了几个没怎么遍历或者遍历不到的分支,也在随后进行了修正。
具体的改动过程,体现在几次对仓库的上传更新中。这次作业锻炼了和他人协同开发的能力,也发现了对于统一编码规范的重要性(一开始我看不懂他的,他看不懂我的T-T)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号