kafka
1、名词介绍
broker :一台kafka服务器就是一个broker
Partition:是实际存储消息的物理单元,一个Topic内部可以包含多个partition。为什么要有多个partition?如果只有一个partition的话,我们发消息写数据都只能保存到一个节点上,这样的话就算这个服务器节点性能再好最终也支撑不住,partition带来了横向扩展能力。Topic内部的partition是从0开始,顺序编号,消息在Partition内部用offset编号,每条新消息offset增加1。使用Topic名称 + partition num + offset可以唯一确定一条消息。Partiton有如下性质(下面所说的consumer行为都是同group的情形下)
1) 每个Partition都有独立的物理文件存储,Topic增加Partition是能够达到扩容的目的。
2) parition内部消息的发送和消费保证顺序性,partition之间消息消费不保证顺序
3) 一个partition只能被一个consumer消费,一个consumer可以消费多个partition
4) 如果consumer没有变动,在整个期间消费的partition是固定的。如果consumer新增或者下线,如果partion数量改变,partition和consumer的对应关系需要重新调整,以保证消息能够继续被顺利消费。即rebalance。rebalance会带来什么问题:
a、消费暂停:考虑在只有Consumer 1的情况下,其负责消费所有5个队列;在新增Consumer 2,触发Rebalance时,需要分配2个队列给其消费。那么Consumer 1就需要停止这2个队列的消费,等到这两个队列分配给Consumer 2后,这两个队列才能继续被消费。
b、重复消费:Consumer 2 在消费分配给自己的2个队列时,必须接着从Consumer 1之前已经消费到的offset继续开始消费。然而默认情况下,offset是异步提交的,如consumer 1当前消费到offset为10,但是异步提交给broker的offset为8;那么如果consumer 2从8的offset开始消费,那么就会有2条消息重复。也就是说,Consumer 2 并不会等待Consumer1提交完offset后,再进行Rebalance,因此提交间隔越长,可能造成的重复消费就越多。
c、消费突刺:由于rebalance可能导致重复消费,如果需要重复消费的消息过多;或者因为rebalance暂停时间过长,导致积压了部分消息。那么都有可能导致在rebalance结束之后瞬间可能需要消费很多消息
5) 如果consumer数量大于partition数量,则会出现冷备consumer,因为没有partition分配给这个consumer。这时consumer会打日志提示;并不影响正常消费
6) Java consumer里还有 --consumer-thread概念,consumer实例数量 * 每个实例的--consumer-thread数量是总的消费线程数,这个数应当小于等于partition数量,否则会有冷备的消费线程;同时这个数量应能整除partition数量,否则各个消费线程的任务量会不均匀。默认consumerThread都是1
7) 一个topic在集群中可以有多个partition,那么发送消息怎么确定应该发送到哪个分区上?有两种基本的策略,一是采用Key Hash算法,如果消息指定key,那么会根据消息的key进行hash,然后对partition分区数量取模,决定落在哪个分区上,所以,对于相同key的消息来说,总是会发送到同一个分区上,也是我们常说的消息分区有序性;一是采用Round Robin算法,即轮询方式,没有指定的时候经常采用这种方式
2、工作线程和消费线程
kafka consumer有worker threads和--consumer-threads,默认情况下工作线程和consumer线程数量都是1
--consumer-threads 是指Kafka IO线程的个数,主要用于从broker拉取message
--worker-threads是指Kafka实际执行消费逻辑的线程,一般消费能力不足时扩容这个参数即可。特殊情况: 当topic吞吐特别大,且消费逻辑是不堵塞行为时,可以考虑使用--worker-threads 0,这样消费逻辑就会在Kafka IO线程中直接执行,减少了转发到工作线程池的开销 这个时候,消费扩容就只能依赖提高--consumer-threads数来进行了 再次强调:如果没有特殊理由,我们一般不使用--consumer-threads参数
--worker-threads 4096
--consumer-threads 5,一个consumer thread会消费一个partition
注意consumer的main函数中不能有\n和换行符等
分别指定两者的数量
3、Consumer Group
1)是Kafka组织消费时的概念。对于一个Topic的消费,由Kakfa的consumer负责记录消费到了partition的哪个offset。
2)Group内部的consumer是按照一定策略去分配一个Topic下的partition。不同的Group侧消费相同的topic时独立互相不影响,也就是说,对于同一个topic,可以通过启动不同的group来消费多份全量数据。
3)由于Kafka实现机制的原因,不同topic的consumer,使用了相同的group,在发生rebanlance时,会互相影响。因此不推荐group复用:即对于不同的topic,不要使用相同的group消费。
4)由多个消费者组成,一个组内只会由一个消费者去消费一个分区的消息
4、如果多个consumer消费同一个partition会有什么问题?
由于消费者自己可以控制读取消息的offset,就有可能C1和C2读到相同的消息并消费。则会造成很多浪费,因为这就相当于多线程读取同一个消息,会造成消息处理的重复。
5、partition怎么确定应该分给哪个consumer
1)range策略,是默认的策略。range分配策略针对的是topic,将一个topic中分区按数字顺序排行序,消费者按消费者名称的字典序排好序。例如,假设有两个消费者C0和C1,两个主题t0和t1,并且每个主题有3个分区,分区的情况是这样的:t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么,基于以上信息,最终消费者分配分区的情况是这样的:
C0: [t0p0, t0p1, t1p0, t1p1]
C1: [t0p2, t1p2]
为什么不是两个消费者各三个分区呢?partition分配原则:对于一个topic,用partition总数除以消费者总数。如果能够除尽,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区。topic t0有3个partition,3 / 2除不尽,所以C0会多分配一个partition。对于topic t1,也是相同道理。
如果只有一个topic,对c0和c1影响不大,如果有多个 topic,那么针对每个topic,消费者c0都将多消费1个分区,topic越多,c0 消费的分区会比其他消费者多。这就是 Range 范围分区的一个很明显的弊端了
2)round robin(轮询)
这个会根据所有的主题进行轮询分配,不会出现Range那种主题越多可能导致分区分配不均衡的问题。P0->A,P1->B,P1->A。。。以此类推。轮询分两种情况:
a:所有consumer消费的topic相同,则RoundRobin策略的分区分配会是均匀。例如三个消费者c0,c1,c2都消费相同的topic(t0,t1),每个topic都有3个分区(p0,p1,p2),那么所有的分区标识为t0p0、t0p1、t0p2、t1p0、t1p1、t1p2,最终分区分配的结果如下:
c0消费 t0p0 、t1p0 分区
C1消费 t0p1 、t1p1 分区
C2消费 t0p2 、t1p2 分区
b:consumer消费的topic不同,例如,有3个消费者C0、C1和C2,有3个topic:t0,t1,t2,t0有1个分区(p0),t1有2个分区(p0、p1),t2有3个分区(p0、p1、p2),c0消费t0,c1消费t0和t1,c2消费t0和t1和t2,最终分区分配结果如下:
C0消费 t0p0分区
C1消费 t1p0分区
C2消费 t1p1、t2p0、t2p1、t2p2分区
从如上实例,可以看到RoundRobin策略也并不是十分完美,这样分配其实并不是最优解,因为完全可以将分区t1p1分配给消费者 C1。所以,如果想要使用RoundRobin 轮询分区策略,必须满足如下两个条件:
①每个consumer消费的topic,必须是相同的
②每个topic的消费者实例都是相同的
6、为什么会出现消息顺序错乱的情况?
比如kafka中,消费者从partition取数据时,如果搞多个线程来并发处理消息,顺序可能就乱了,本来MQ中数据是data1,data2,data3。消费了消息后,写到db中顺序可能就变成了data1,data3,data2。
怎么解决?
producer具有相同key的数据都写到同一个partition中,比如相同订单id的数据写到同一个partition里面。
如果consumer使用线程池异步消费,由于线程池每个线程处理进度可能不一样,所以也有可能导致非顺序消费。所以需要让提交任务的线程去完成消费。
7、kafka集群元数据的在Zookeeper中管理,以及集群的协调工作,在每个kafka服务器启动的时候去连接到Zookeeper,把自己注册到Zookeeper当中
8、kafka消息系统有两类:点对点:也就是消息只能被一个消费者消费,消费完后消息删除。发布订阅:相当于广播模式,消息可以被所有消费者消费
kafka其实通过Consumer Group同时支持了这两个模型。如果所有消费者都属于一个Group,消息只能被同一个Group内的一个消费者消费,那就是点对点模式。如果每个消费者都是一个单独的Group,那么就是发布订阅模式
9、kafka通信过程
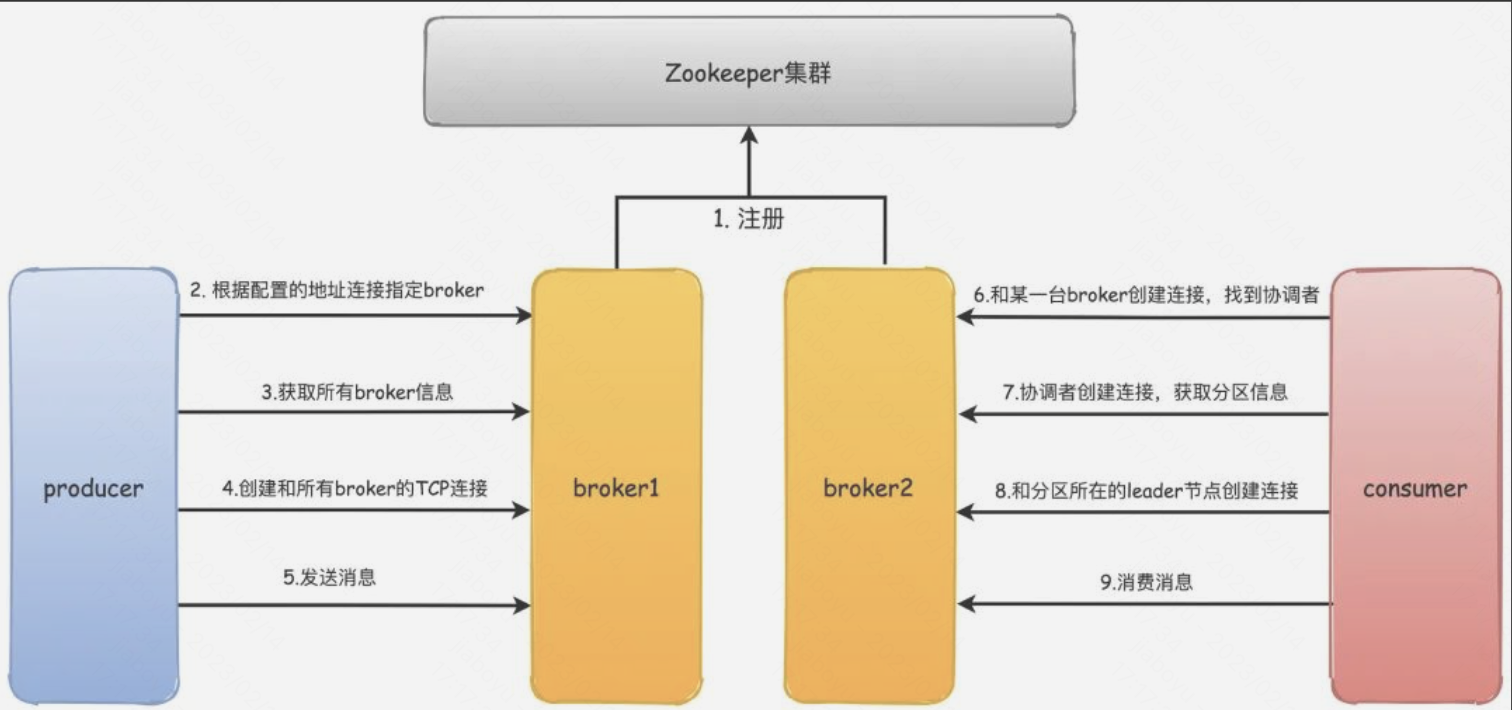
1)首先kafka broker启动的时候,会去向Zookeeper注册自己的ID(创建临时节点),这个ID可以配置也可以自动生成,同时会去订阅Zookeeper的brokers/ids路径,当有新的broker加入或者退出时,可以得到当前所有broker信息
2) 生产者启动的时候会指定bootstrap.servers,通过指定的broker地址,Kafka就会和这些broker创建TCP连接
3) 随便连接到任何一台broker之后,然后再发送请求获取元数据信息
4) 接着会创建和所有broker的TCP连接
7) 然后再和协调者broker创建TCP连接,获取元数据
8) 根据分区Leader节点所在的broker节点,和这些broker分别创建连接
9) 最后开始消费消息
10、kafka检测消息丢失的方法
在Producer给每个发出的消息附加一个连续递增的序号,然后在Consumer端来检查这个序号的连续性。如果没有消息丢失,Consumer收到消息的序号必然是连续递增的,如果检测到序号不连续,那就是丢消息了。还可以通过缺失的序号来确定丢失的是哪条消息,方便进一步排查原因。这个方法能保证在同一个partition上检测是否有消息丢失,所以序号要加入partition信息。
10、kafka消息的可靠性怎么保证,怎么保证不丢消息
消息从生产到消费,需要经历三个过程:
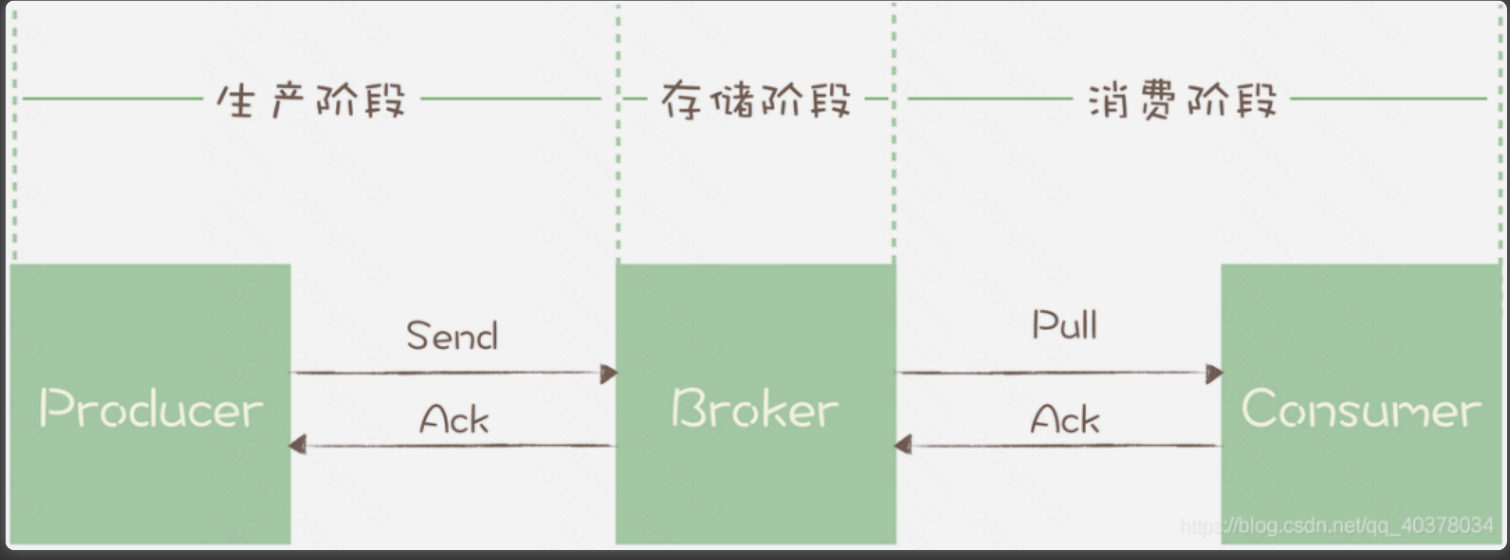
- 生产阶段:在这个阶段,消息在Producer创建出来,经过网络传输发送到Broker端
- 存储阶段:在这个阶段,消息在Broker端存储,如果是集群,消息会在这个阶段被复制到其他的副本上
- 消费阶段:在这个阶段,Consumer从Broker上拉取消息,经过网络传输发送到Consumer上
1)生产阶段
在生产阶段,消息队列通过最常用的请求确认机制,来保证消息的可靠传递:当在代码中调用发送消息方法时,消息队列的客户端会把消息发送到Broker,Broker收到消息后,会给客户端返回一个确认响应,表明消息已经收到了。客户端收到响应后,完成了一次正常消息的发送。只要Producer收到了Broker的确认响应就可以保证消息在生产阶段不会丢失。有些消息队列在长时间没收到发送确认响应后,会自动重试,如果重试再失败,就会以返回值或者异常的方式告知用户,用户如果正确处理返回值或者捕获异常,就可以保证这个阶段的消息不会丢失。
2)存储阶段
在存储阶段正常情况下,只要Broker在正常运行,就不会出现丢失消息的问题,但是如果Broker出现了故障,比如进程死掉了或者服务器宕机了,还是可能会丢失消息的。如果对消息的可靠性要求非常高,可以通过配置Broker参数来避免因为宕机丢消息。如果Broker是由多个节点组成的集群,需要将Broker集群配置成:至少将消息发送到2个以上的节点或者将消息发送到所有节点,再给客户端回复发送确认响应,即producer把消息发给leader,x个follower从leader拉取消息,拉取并写入本地后,follower给leader返回ack,ack向producer返回ack。这样当某个Broker宕机后,其他的Broker可以替代宕机的Broker,也不会发生消息丢失。
该阶段可能丢失消息的case:
a、配置为把消息只发送给leader节点就给生产者返回ack,可以保证leader不丢,但是如果leader挂了,恰好选了一个没有ACK的follower,那也丢了
b、broker存储消息时会先写到缓存里,然后操作系统决定什么时候把缓存中的数据刷到磁盘里,kafka没有同步刷磁盘的机制,所以要完全让kafka保证单个broker不丢失消息是做不到的,只能通过调整刷盘机制的参数缓解该情况。比如,减少刷盘间隔,减少刷盘数据量大小。
3)消费阶段
消费阶段采用和生产阶段类似的确认机制来保证消息的可靠传递,客户端从Broker拉取消息后,执行用户的消费业务逻辑,成功后,才会给Broker发送消费确认响应。如果Broker没有收到消费确认响应,下次拉消息的时候还会返回同一条消息,确认消息不会在网络传输过程中丢失,也不会因为客户端在执行消费逻辑中出错导致丢失。在编写消费代码时需要注意的是,不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认
11、kafka为什么这么快
1)顺序IO:kafka写消息到broker的partition时采用追加的方式,也就是顺序写入磁盘,不是随机写入。磁盘是典型的IO块设备,每次读写都会经历寻址,其中寻址中寻道是比较耗时的。随机读写会导致寻址时间延长,从而影响磁盘的读写速度。顺序IO比随机IO速度有6000倍的提升,媲美内存随机访问的性能,磁盘不再是瓶颈点
2)Page Cache 和零拷贝:为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。通过操作系统的Page Cache,broker数据的读写操作基本上是基于内存的,读写速度得到了极大的提升。另外在消费消息的时候又通过sendfile实现了零拷贝,零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域,这种技术通常用于通过网络文件IO时节省CPU资源。
零拷贝:像传统的IO,如果服务端要提供文件传输的功能,需要将磁盘上的文件读取出来,然后通过网络协议发送给客户端。传统 I/O的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。一次IO操作涉及多次用户态和内核态的切换,还有多次数据的搬运,因为数据需要从磁盘搬运到缓冲区中。传统IO工作流程包括从磁盘读取文件即read()和发送数据send()流程:
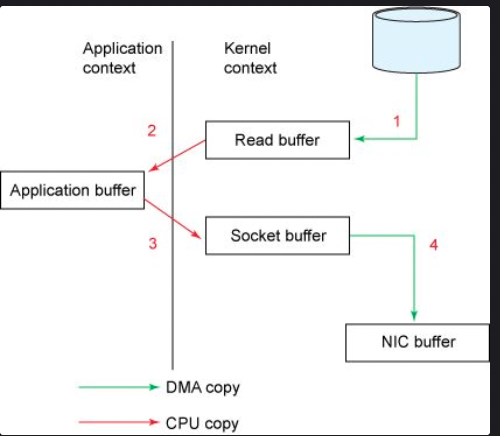
NIC buffer:NIC指的是网卡
a、read()调用导致上下文从用户态切换到内核态,DMA引擎执行第一次拷贝,从文件读取数据并存储到内核空间的读缓冲区
b、请求的数据从内核读缓冲区拷贝到用户缓冲区,上下文从内核态切换到用户态。
c、send()调用导致上下文从用户态切换到内核态,数据从用户缓冲区拷贝到内核缓冲区,只不过这次的内核缓冲区和之前不一样,是socekt buffer套接字缓冲区
d、send调用完成后,上下文又从内核态切换到用户态
其中磁盘到内核态的数据拷贝属于DMA拷贝,内核空间到用户空间的数据拷贝属于CPU拷贝,需要CPU全程参与
零拷贝技术包括mmap和sendfile,具体工作流程:
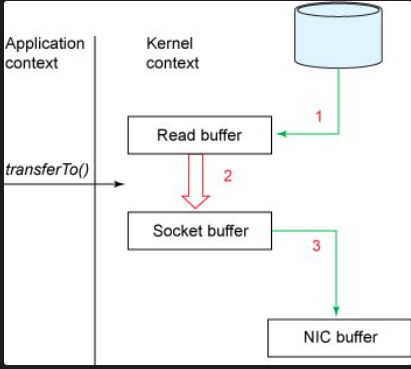
相比于传统IO,数据从内核空间的读缓冲区(read buffer)直接拷贝到了套接字缓冲区(socekt buffer)。相对于传统IO,零拷贝把上下文切换次数从4次减少到2次,把数据拷贝次数从4次减少到了3次,其中只有1次涉及CPU,2次涉及DMA。
3)批量处理:Kafka在发送消息的时候不是一条条的发送的,而是会把多条消息合并成一个批次进行处理发送,同时broker也是批量刷磁盘,减少IO次数。消费消息也是一个道理,一次拉取一批次的消息进行消费。
4)消息压缩:如果Kafka消息吞吐量达到千万级别,对网络带宽占用较大。Kafka的解决方案是消息压缩。发送消息时,如果增加参数compression.type,就可以开启消息压缩,producer缓存好消息后会进行压缩然后再发送。consumer会进行解压,注意压缩和解压都会消耗cpu资源
12、kafka高可用性保障:副本和同步:
Kafka每个partition数据都有Leader副本和Follower副本,也就是主副本和从副本,和其他的比如Mysql不一样的是,Kafka中只有Leader副本会对外提供服务,Follower副本只是单纯地和Leader保持数据同步,作为数据冗余容灾的作用。在Kafka中我们把所有副本的集合统称为AR(Assigned Replicas),和Leader副本保持同步的副本集合称为ISR(InSyncReplicas)。网络延迟比较高或者有故障的follower不会出现在ISR集合中,如果Leader挂掉了kafka会从follwer中选出一个leader。
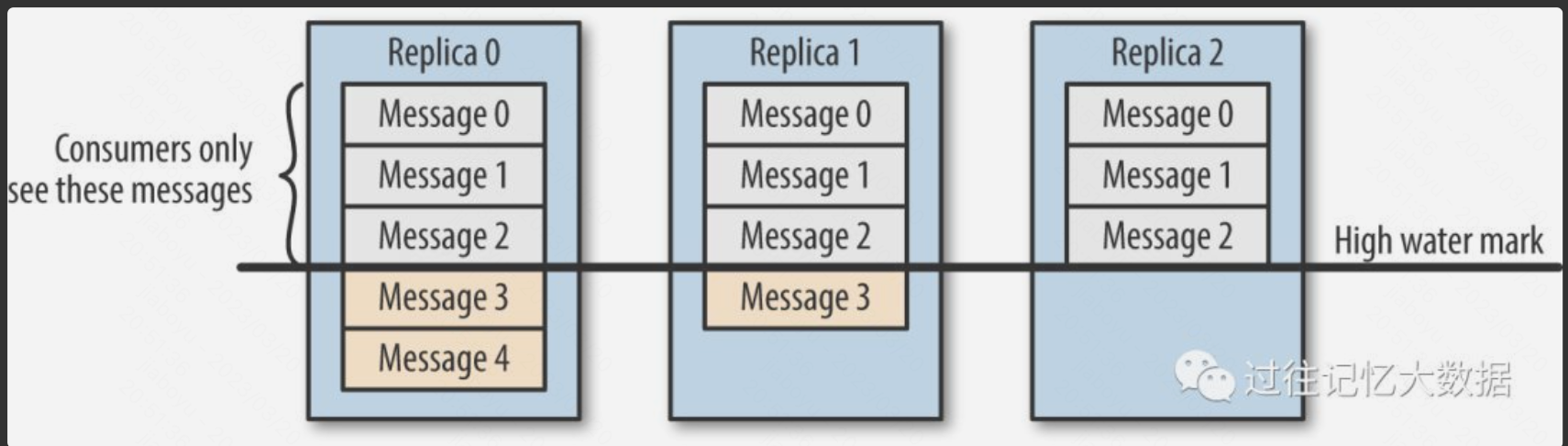
ISR机制中两个关键概念:
LEO(log end offset) ,即下一条消息的写⼊位置
HW(high watermark),即已同步消息标识,因其类似于⽊桶效应中短板决定⽔位高度
producer生产的消息到了leader副本后,leader副本更新自己的LEO, follower副本会从leader拉取消息进行同步,增加自己的LEO。
Leader的HW值由follower中最小的LEO决定。HW以下消息表示已同步到所有ISR,消费者仅可消费Leader副本HW以下的消息,
HW机制作用:
t1时刻consumer从leader副本拉取消息,
t2时刻consumer消费完数据提交offset,但t1到t2期间可能leader副本挂了,从ISR选举出的follower副本的offset可能比leader的offset小,t1到t2期间producer还在往新的leader副本生产消息。t2时刻consumer提交新的offset会把新leader副本未拉取的数据置为已消费,造成消息丢失。同时在故障容灾时,HW是新leader选举后数据对齐的核心依据,新leader会删除自身日志中HW之后的所有未同步消息;后续其他 follower同步新leader时,也会做同样的截断操作。HW机制可以保障安全消费,消费者基于HW读取消息,确保所消费的数据在所有Replica中都是一致的。
即使有HW机制,还是可能丢数据,因为如上所述,新leader选举后会删除自身日志中HW之后的数据
13、如何处理消息积压的问题
消费端降级非核心功能,增加topic的partition数量,增加consumer消费者的数量
14、kakfa怎么避免消息重复消费
broker的partition中有offset字段表示消费进度,consumer有消费时会提交更新offset。同时消费端也可以做唯一性控制,比如利用数据库唯一索引,或者redis做幂等校验
15、消息队列的劣势
1)在还未引进MQ之前,系统只需要关系生产端与消费端的接口一致性就可以了,现在引进后,系统需要关注生产端、MQ与消费端三者的稳定性,这增加系统的负担,系统运维成本增加
2)引入了MQ,需要考虑的问题就增加了,如何保障消息的一致性,消费不被重复消费等问题。
16、 kafka commit机制
consumer手动向broker提交offset流程:在业务处理之后提交消费进度。可能遇到的问题:手动提交消费进度之前,如果业务正常处理并入库,随后宕机。导致重复消费问题,而且手动提交offset如果失败,consumer会重试使得consumer处于阻塞状态,可能会影响系统处理请求能力。手动提交有异步模式,不会阻塞当前线程,如果提交失败也不会重试。
consumer自动向broker提交offset流程:consumer下一次poll数据的时候,把上一次的offset提交。可能遇到的问题:在默认情况下,Consumer 每 5 秒自动提交一次位移。现在,我们假设提交位移之后的 3 秒发生了 Rebalance 操作。在 Rebalance 之后,所有 Consumer 从上一次提交的位移处继续消费,但该位移已经是 3 秒前的位移数据了,故在 Rebalance 发生前 3 秒消费的所有数据都要重新再消费一次
总结:自动提交可靠性较低一般不建议使用,如果想保证高吞吐量,用手动提交的异步模式。如果想保证高可靠性,用手动提交的同步模式
17、消息队列的推和拉
推模式:消息从broker推送到consumer,如ActiveMq。
优点:消息实时性高,Broker接受完消息之后可以立马推送给Consumer。
缺点:如果消息流量高,可能打挂consumer,消费速率难以控制。
拉模式:consumer从broker拉取消息,如RocketMq和kafka。
优点:方便做拉取速率控制,控制拉取间隔。并且可以做到消息批量获取
缺点:消息延迟,因为consumer隔一段时间才去拉取消息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号