大数据
大数据处理之分治思想,分而治之/hash映射 + hash统计 + 堆/快速/归并排序,说白了,就是先映射,而后统计,最后排序。
分而治之/hash映射: 针对数据太大,内存受限,只能是: 把大文件化成(取模映射)小文件,即16字方针: 大而化小,各个击破,缩小规模,逐个解决hash_map
统计: 当大文件转化了小文件,那么我们便可以采用常规的hash_map(ip,value)来进行频率统计。
堆/快速排序: 统计完了之后,便进行排序(可采取堆排序),得到次数最多的IP
1、如何在40亿个数中判断某个数是否存在
如果用set存储数据,一个整数4B,40亿个就是40*10^8*4B=16G,内存肯定装不下。
判断一个数是否存在,可以用0或1来表示,1表示存在,所以可以用一个bit来代表。可以申请2^32个bit,大概是42亿多点。1代表第一个bit,2代表第二个bit,2^32代表最后一个位。新来一个数,比如2563,就找一下第2563位,如果是0,就表示不存在(并把这个值设为1),如果是1,就表示存在。这样只需要2^32个bit,相当于2^29B,约等于500MB,所以只需要申请500MB内存。因为原来的32位整数,转化为了1位的bit,所以数据空间就是原来的1/32。这就是bitmap算法。如下图所示:

上面BitMap描述的值是1,3,5
2、海量日志数据,提取出某日访问百度最多的ip
把这一天访问百度的IP取出来,ip是32位的,可以采用映射的方法比如ip取hash值,然后%1000,将所有ip映射到1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map对那1000个文件中的所有IP进行频率统计,然后依次找出各个文件中频率最大的那个IP)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求
3、300万个查询字符串中统计最热门的10个查询
跟上面题目类似,将数据分到1000个小文件中,统计每个字符串出现次数并排序。最后需要建立最小堆,容量为10,存储出现次数最多的10个字符串
4、海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10
遍历一遍所有数据,重新hash取摸,如此使得同一个元素只出现在单独的一台电脑中,然后采用上面所说的方法,统计每台电脑中各个元素的出现次数找出TOP10,继而组合100台电脑上的TOP10,找出最终的TOP10
5、100w个数中找出最大的100个数
用一个含100个元素的最小堆完成
6、如何快速检索文本中是否包含敏感词
https://www.cnblogs.com/jmcui/p/11925777.html
可以建立类似字典树的数据结构:
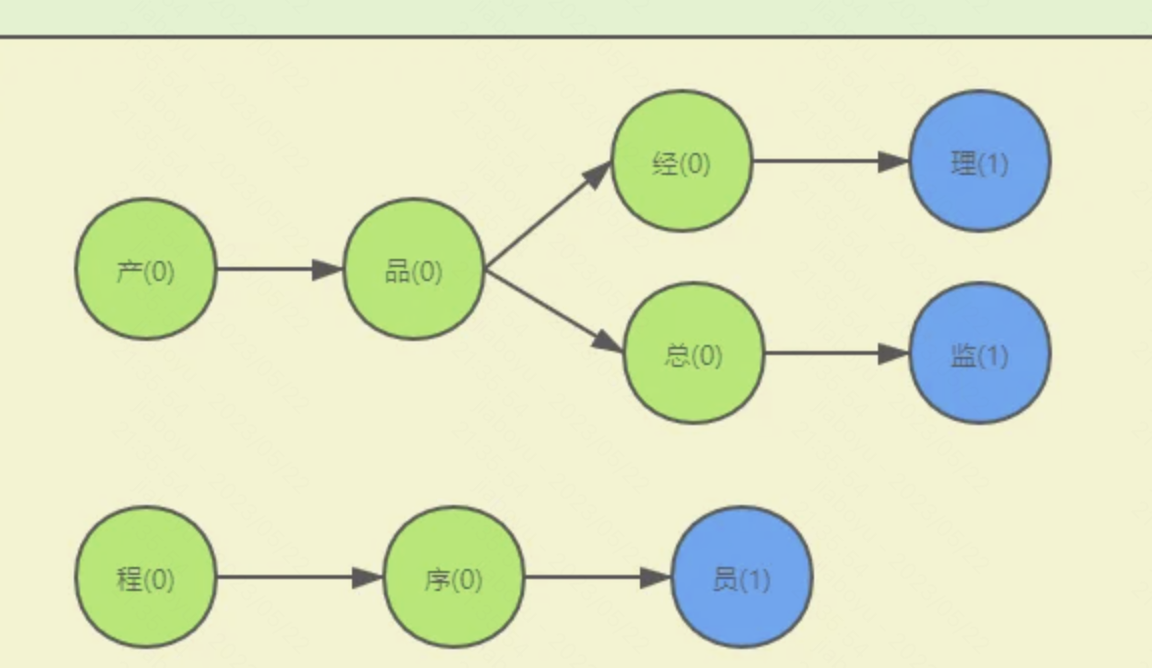
把字典放到map中,比如敏感词是王八蛋,map的结构是 {王={isEnd=0, 八={isEnd=0, 蛋={isEnd=1}}}}
然后遍历文本,对文本中每个汉字都到map中进行get操作,比如文本出现了王,则从map中get("王"),如果王对应的value不为空,则把value转为map,继续get("八"),以此类推。时间复杂度O(n),只要遍历文本内容即可。
7、怎么判断海量url中是否存在某个url?
a、hashmap
b、bitmap
c、布隆过滤器可以用来判断一个元素是否在一个集合中,可能存在误判,可以建立白名单等机制补偿
8、在推荐视频中如何过滤一个用户最近三个月看过的视频
a、使用redis的set,空间占用太大
b、使用布隆过滤器,用来判断一个元素是否在集合中,实现高效的插入和查询,在空间和时间方面都有巨大优势

 浙公网安备 33010602011771号
浙公网安备 33010602011771号