redis基础知识
1、redis jedis客户端 pipeline中可以传入function或consumer,里面可以写多条语句。pipeline不是原子,只是命令的封装,节省网络时间(有句话说的好,Redis性能瓶颈是网络),使用pipeline也要注意避免发送的命令过大,或管道内的数据太多而导致的网络阻塞,管道技术本质上是客户端提供的功能,而非Redis服务器端的功能
2、redis客户端setnx: key不存在时才set,存在时则忽略
3、redis数据类型:
hash数据类型:即键值(key=>value)对集合,例子如下:
HMSET runoob field1 "Hello" field2 "World",其中runoob是key,field1和field2是field,Hello和world是value。
一个key可以存储2^32-1个键值对
HGET runoob field1 会返回Hello,HGET runoob field2 会返回World。
list数据类型:value是字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边),列表最多可以存储2^32-1个元素。使用场景:消息队列(lpush和brpop可实现阻塞队列)、文章列表
lpush runoob mongodb
lpush runoob rabbitmq
lpush runoob kaffff
相当于给key添加了三个元素, lpush从头部插入,rpush从尾部插入数据
lrange runoob 0 10 可以返回该key指定范围里的元素
ltrim(String key, long start, long end) 可以修剪list中元素,只包含指定范围个数的元素
lrange(String key, long start, long end) 返回该key的列表里指定范围内的元素
llen(String key) 返回存储在key里的list的长度。 如果 key 不存在,那么就被看作是空list,并且返回长度为 0
lpop(String key) 移除并且返回key对应的 list 的第一个元素
rpop(String key) 移除并返回存于key的 list 的最后一个元素
set数据类型:Set中元素是惟一的,set中最多可以存储2^32-1个元素。使用场景:用户感兴趣的标签、社交场景,
sadd runoob redis
sadd runoob mongodb
sadd runoob kafff
zset (sorted set:有序集合),和set一样,只是每个元素会关联个double类型的分数,redis会按照分数从小到大给元素排序。常见于排行榜系统,ZRANGE 命令用于返回指定KEY 中,指定区间内的成员。其中成员的位置按 score 值递增(从小到大)来排序
192.168.98.70:6379> ZADD haicoder 100 Redis 50 Mongo 200 Mysql 10 SqlServer
(integer) 4
192.168.98.70:6379> ZRANGE haicoder 0 2
1) "SqlServer"
2) "Mongo"
3) "Redis"
我们首先,使用 ZADD 命令,同时向键为 haicoder 的集合插入元素 Redis,分数为 100,元素 Mongo,分数为 50,元素 Mysql,分数为 200,元素 SqlServer,分数为 10。
最后,我们使用 ZRANGE 命令,获取键为 haicoder 的集合下标 0 到 2 的元素列表,元素是按照分数从小到大排序的。
负数索引,表示从列表最后一个元素开始往前获取
192.168.98.70:6379> ZADD haicoder 100 Redis 50 Mongo 200 Mysql 10 SqlServer
(integer) 4
192.168.98.70:6379> ZRANGE haicoder 0 -2
1) "SqlServer"
2) "Mongo"
3) "Redis"
192.168.98.70:6379> ZRANGE haicoder 0 -1
1) "SqlServer"
2) "Mongo"
3) "Redis"
4) "Mysql"
ZADD后,成员排序为:SqlServer,Mongo,Redis,Mysql(分数从小到大)
接着,使用 ZRANGE 命令,获取键为 haicoder 的集合下标 0 到 -2 的元素列表,即获取第一个元素到倒数第二个元素的列表。
最后,我们使用 ZRANGE 命令,获取键为 haicoder 的集合下标 0 到 -1 的元素列表,即获取第一个元素到最后一个元素的列表。
使用 WITHSCORES 选项,可以获取元素的分数
192.168.98.70:6379> ZADD haicoder 100 Redis 50 Mongo 200 Mysql 10 SqlServer
(integer) 4
192.168.98.70:6379> ZRANGE haicoder 0 -1 WITHSCORES
1) "SqlServer"
2) "10"
3) "Mongo"
4) "50"
5) "Redis"
6) "100"
7) "Mysql"
8) "200"
最后,我们使用 ZRANGE 命令,获取键为 haicoder 的集合的第一个元素到最后一个元素的列表,同时返回每个元素对应的分数值,这里可以看出元素的分数值按照从小到大进行排序。
zset其他命令:
zscore(key, member) 返回member的分数。
zadd(key, score, member) 插入元素,如果元素存在,score会覆盖
zrem(key, member) 删除member
zincrby(key, score, member) 给member在之前分数基础上增加score
zrank(key, member) 返回member在zset的排名(从小到大)
zcount(key, double min, double max) score在min和max之间member的数量
随着Redis版本的更新,后面又支持了四种数据类型:
BitMap(2.2 版新增): 二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等,bitmap的api:
setbit(String key, long offset, boolean value)用来设置指定bit位置的值,
getbit(String key, long offset)用来获取指定bit位置的值,
bitcount(String key)用来统计1的个数
HyperLogLog(2.8 版新增): 海量数据基数统计的场景
GEO(3.2 版新增): 存储地理位置信息的场景
Stream(5.0 版新增): 消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据
相当于setnx同时设置过期时间
如果setnx和expire分开两步执行,则不是原子的。如果用new SetArgs().nx().ex(xxx)方式,则两者是原子执行的
new SetArgs().ex() 设置过期的秒数
new SetArgs().px() 设置过期的毫秒数
5、incr和incrBy命令:如果key不存在,key的值会先被初始化为0,然后再增加
6、redis客户端对比:jedis, lettuce
jedis
优点:支持全面的 Redis 操作特性(可以理解为API比较全面)
缺点:
1、使用阻塞的 I/O,且其方法调用都是同步的,程序流需要等到 sockets 处理完 I/O 才能执行,不支持异步
2、Jedis 客户端实例不是线程安全的,所以需要通过连接池来使用 Jedis
lettuce:
优点:支持同步异步通信模式。Lettuce 的 API 是线程安全的,同步api:命令调用之后立即返回结果,可以保证命令的执行顺序。异步api:会返回一个Lazy的RedisAsyncCommands接口的代理对象,代理对象在执行每一条命令时,都会调用invoke方法,使用一个随机的Lettuce客户端来执行命令。所以async方法不保证命令的执行顺序
7、redis mset:
命令用于同时设置一个或多个 key-value 对
redis 127.0.0.1:6379> MSET key1 "Hello" key2 "World"
OK
redis 127.0.0.1:6379> GET key1
"Hello"
redis 127.0.0.1:6379> GET key2
"World"
mget:批量查询,查询所有给定key的值
redis 127.0.0.1:6379> SET key1 "hello"
OK
redis 127.0.0.1:6379> SET key2 "world"
OK
redis 127.0.0.1:6379> MGET key1 key2 someOtherKey
1) "Hello"
2) "World"
3) (nil)
redis客户端批量操作:
Map<String, String> result = jedisHelper.pipeline(keys, RedisPipeline::get) // 批量读取
jedisHelper.pipeline(keys, (redisPipeline, s) -> redisPipeline.del(s)) //批量删除
8、热key:瞬间有几十万的请求去访问redis某个固定的key,从而压垮缓存服务的情况。这样会造成流量过于集中,达到物理网卡上限,从而导致这台redis的服务器宕机。比如XX明星结婚。那么关于XX明星的Key就会瞬间增大,就会出现热数据问题。接下来这个key的请求,就会直接怼到你的数据库上,导致你的服务不可用。
怎么解决热key问题:
a、数据分片,key的构成为:xx_1, xx_2,将热点数据分到多个实例节点上
b、使用本地缓存,将热key数据加载到本地缓存中。读取时只从本地缓存获取即可
9、redis4.0版本后是多线程。之前版本是单线程,单线程指的是网络IO线程和Set/Get操作是由一个线程完成的。但是Redis 的持久化、集群同步还是使用其他线程来完成。4.0之后添加了多线程的支持,主要是体现在大数据的异步删除功能上,例如unlink key(此命令和del类似,用于删除指定的key,区别是此命令将键与键空间断开连接,实际的删除将稍后异步进行)、flushdb async(清空当前db中所有key)、flushall async(清空所有db的key)等。Redis6.0 使用了多线程Thread I/O,Theaded IO指的是在网络IO处理方面上了多线程,如网络数据的读写和协议解析等,需要注意的是,执行命令的核心模块还是单线程的。Redis 的瓶颈并不在 CPU,而在内存和网络。内存不够的话,可以加内存或者做数据结构优化和其他优化等,但网络的性能优化才是大头,网络IO的读写在Redis整个执行期间占用了大部分的 CPU 时间,如果把网络处理这部分做成多线程处理方式,那对整个Redis的性能会有很大的提升。
10、redis单线程:选择单线程原因是使用简单,不存在锁竞争,可以在无锁的情况下完成所有操作,不存在死锁和线程切换带来的性能和时间上的开销,但同时单线程也不能完全发挥出多核 CPU 的性能。
redis为什么快:
1)Redis的大部分操作都在内存中完成,内存中的执行效率本身就很快,并且采用了高效的数据结构,比如哈希表和跳表。redis的键值对都存在哈希表中,查找的时间复杂度是O(1)
2)使用单线程避免了多线程的竞争,省去了多线程切换带来的时间和性能开销,并且不会出现死锁。
3)采用I/O多路复用机制处理大量客户端的Socket请求,因为这是基于非阻塞的I/O模型,这就让Redis可以高效地进行网络通信,I/O的读写流程也不再阻塞
11、redis和memcache相同不同点:
相同:
数据都是放在内存中,由于读写的是内存,所以速度很快
都有过期策略
不同:
数据结构:memcache只支持kv形式,redis支持多种数据类型。
过期策略:memcache在set时就指定,redis可以通过expire方法指定过期时间。
线程数:Redis是单线程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题;性能受限于内存和网络,单实例QPS在4-6w。Memcached是多线程,可以利用多核优势,单实例在正常情况下,可以达到写入60-80w qps,读80-100w qps。
持久化:redis数据可以做持久化,将内存中的数据保持在磁盘中,重启的时候可以再次加载使用。memcache挂掉后数据不可恢复
分布式存储:redis支持数据的备份,即master-slave模式的数据备份。可以实时进行数据的同步复制。Memcached无法进行数据同步,不能将实例中的数据迁移到其他MC实例中
使用场景:
如果有数据持久方面的需求或对数据类型和处理有要求的应该选择redis
如果简单的kv存储,可以选memcache。对于一些超高QPS(例如千万级别)、超大big key、以及存在较高热点的业务,在memcahced满足相关功能需求的情况下,建议大家使用memcached;否则建议大家使用redis。
12、客户端和服务端之间的通信协议是在TCP协议之上构建的,客户端将命令封装成符合RESP的格式,发送一条命令的格式
/ set hello world
// 格式:
*参数数量
$参数1字节数
参数1
$参数2字节数
参数2
...
// 示例
*3
$3
SET
$5
hello
$5
world
// 实际格式
*3\r\n$3\r\nSET\r\n$5hello\r\n$5\r\n$5\r\nworld\r\n
13、redis淘汰策略
Redis内存淘汰策略共有八种,这八种策略大体分为「不进行数据淘汰」和「进行数据淘汰」两类策略。
1)、不进行数据淘汰的策略
Redis3.0之后,默认的内存淘汰策略:它表示当运行内存超过最大设置内存时,不淘汰任何数据,而是不再提供服务,直接返回错误。
2)、进行数据淘汰的策略
可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。 在设置了过期时间的数据中进行淘汰:
volatile-random:随机淘汰设置了过期时间的任意键值
volatile-ttl:优先淘汰更早过期的键值
volatile-lru(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值
volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值
在所有数据范围内进行淘汰:
allkeys-random:随机淘汰任意键值;
allkeys-lru:淘汰整个键值中最久未使用的键值;
allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值
redis怎么实现lru?
传统lru需要双向链表,需要额外存储next和prev指针,牺牲存储空间,Redis实现的是一种近似LRU算法,目的是为了更好的节约内存,它的实现方式是在Redis的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
当Redis进行lru内存淘汰时,会维护大小为16的候选池,候选池中的key会根据访问时间排序,第一次随机选取的key都会放入池中,随后每次随机选取key时会从redis的key空间中随机取x个值(此值可配置,默认为5),如果某个key的访问时间小于池中最小的访问时间才会放入池中,直到候选池被放满。当放满后,如果有新的key需要放入,则将池中访问时间最大(最近被访问)的key从池中移除。当需要淘汰的时候,则直接从池中选取最近访问时间最小(最久未被访问)的key淘汰。如果候选池中某个key被访问到,则该key会更新访问时间,并被移动到池中最安全的位置。
Redis实现的LRU算法的优点:
1)不用为所有的数据维护一个大链表,节省了空间占用
2)不用在每次数据访问时都移动链表项,提升了缓存的性能
Redis实现的LRU算法的缺点:
它无法正确的表示一个Key的热度,如果一个key从未被访问过,仅仅发生内存淘汰的前一会儿被用户访问了一下,在LRU算法中这会被认为是一个热key
redis怎么实现LFU?
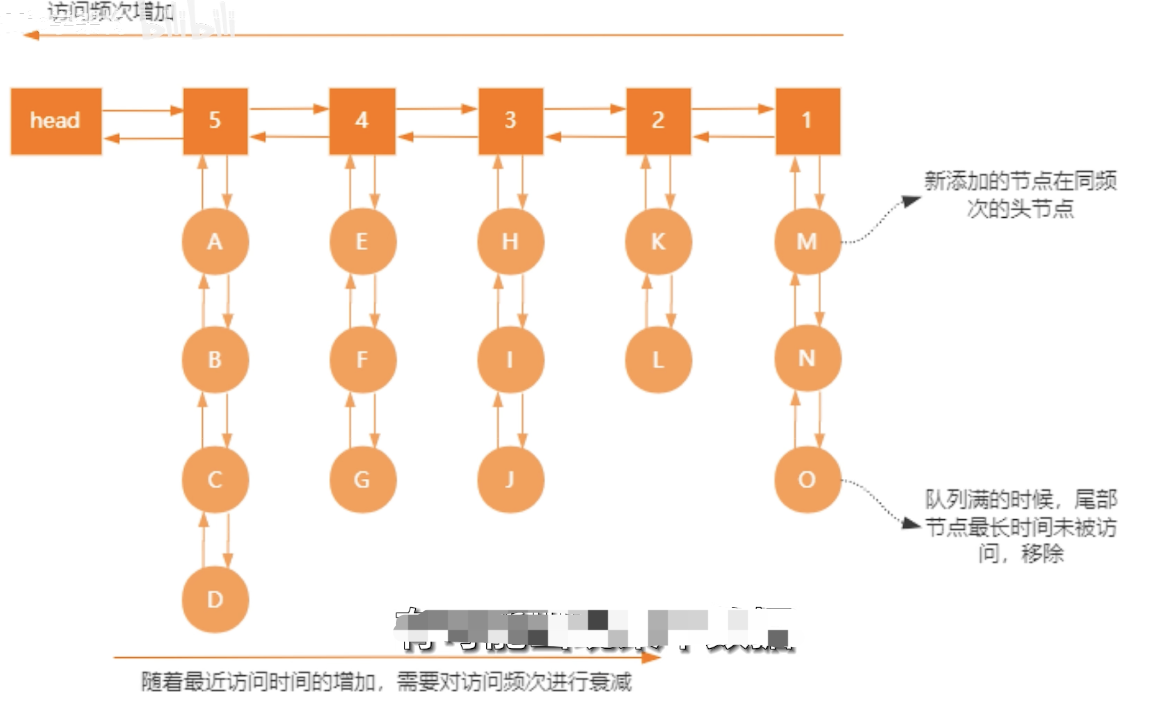
LFU算法会记录每个数据的访问次数。当一个数据被再次访问时,就会增加该数据的访问次数。这样就解决了偶尔被访问一次之后,数据留存在缓存中很长一段时间的问题,相比于LRU算法也更合理一些。LFU算法中redis对象记录了数据的访问频次,是访问频率。LFU是个二维双向链表,一个链表保存访问频率,另一个链表保存访问频率相同的所有元素。如果一个key上一次访问的时间与这一次访问的时间差距很大,那么频次值会衰减很多,这个key被淘汰的概率越大。
LFU算法的缺点:
1)对于每个缓存项,LFU都需要记录其访问次数,算法复杂度较高且需要额外内存开销;
2)如果一条缓存曾经访问了很多次,但是如果业务逻辑发生了改变,这条缓存被访问的次数已经很少或者不再会被访问,这条缓存由于其历史访问次数很高,会长时间留在缓存中不被淘汰。即导致缓存污染问题
14、redis集群扩容过程
1)向集群中添加节点
2)假设之前有三个master,现在扩容为4个master,则之前每个master的槽数量是16384/3=5411,扩容后每个master槽的数量是4096。需要向新master迁移4096个槽位。具体过程:启动一个新的master机器,然后通过与任意一个集群中的节点握手使得新的节点加入集群。每个master超过4096个槽的部分迁移到新的master中,然后开始以slot为单位进行迁移,每个slot的迁移过程如下:
- 对目标节点发送cluster setslot {slot_id} importing {sourceNodeId}命令,目标节点的状态被标记为"importing",准备导入这个slot的数据
- 对源节点发送cluster setslot {slot_id} migrating {targetNodeID}命令,源节点的状态被标记为"migrating",准备迁出slot的数据
- 源节点执行cluster getkeysinslot {slot_id} {count}命令,获取这个slot的所有的key列表(分批获取,count指定一次获取的个数),然后针对每个key进行迁移
- 在源节点执行migrate {targetIp} {targetPort} "" 0 {timeout} keys {keys}命令,把一批批key迁移到目标节点,目标节点给源节点返回"OK",然后源节点删除这个key,这样,一个key的迁移过程就结束了
- 所有的key都迁移完成后,一个slot的迁移就结束了
- 所有的slot迁移完成后,新集群的slot就重新分配完成了,向集群内所有master发送cluster setslot {slot_id} node {targetNodeId}命令,通知他们哪些槽被迁移到了哪些master上,让它们更新自己的信息
16、redis过期策略底层是如何实现的
每当我们对一个key设置了过期时间时,Redis会把该key带上过期时间存储到一个过期字典中,也就是说「过期字典」保存了数据库中所有key的过期时间。当我们查询一个key时,Redis首先检查该key是否存在于过期字典中,如果不在,则正常读取键值。如果存在,则会获取该key的过期时间,然后与当前系统时间进行比对,如果比系统时间大,那就没有过期,否则判定该key已过期。redis的过期删除策略是惰性删除+定期删除。
惰性删除:当某个key被设置了过期时间之后,客户端每次对该key的访问(读写)都会事先检测该key是否过期,如果过期就直接删除。
优点:每次访问时,才会检查 key 是否过期,所以此策略只会使用很少的系统资源,因此,惰性删除策略对 CPU 时间最友好
缺点:如果一个key已经过期了,如果长时间没有被访问,那么这个key就会一直存留在内存之中,严重消耗了内存资源。
定期删除:Redis会将所有设置了过期时间的key放入一个字典中,然后每隔一段时间从字典中随机一些key检查过期时间并删除已过期的key。
Redis默认每秒进行10次过期扫描:
-
从过期字典中随机20个key
-
删除这20个key中已过期的
-
如果超过25%的key过期,则重复第一步
同时,为了保证不出现循环过度的情况,Redis还设置了扫描的时间上限,默认不会超过25ms。
优点:通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用
缺点:难以确定删除操作执行的时长和频率。如果执行的太频繁,就会对 CPU 不友好;如果执行的太少,那又和惰性删除一样了,过期 key 占用的内存不会及时得到释放
17、redis不能执行keys命令,因为要遍历整个redis的所有key,遍历非常耗时。而且是个阻塞命令,会阻塞所有客户端对server的访问,直到keys命令完成,可以用scan代替,scan每次被调用之后,都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数, 以此来延续之前的迭代过程。scan提供limit参数,可以控制返回结果的最大条数。如果新游标返回0表示迭代已结束。redis还有hscan用于迭代hash里面的元素,避免field过多一次扫出太多数据。sscan用于迭代set里面的元素,zscan用于迭代zset里面的元素。
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了
18、redis读写流量都打到master,可以防止主从延迟带来的数据不一致。所以代码中在写入后可以直接读
19、redis大key:
大key影响:
a、阻塞工作线程。由于Redis执行命令是单线程处理,然后在操作大key时会比较耗时,那么就会阻塞Redis,从客户端这一视角看,就是很久很久都没有响应。
b、引发网络阻塞。每次获取大key产生的网络流量较大,如果一个key的大小是1MB,每秒访问量为1000,那么每秒会产生1000MB的流量,这对于普通千兆网卡的服务器来说是灾难性的。
c、内存分布不均。集群模型在slot分片均匀情况下,会出现数据和查询倾斜情况,部分有大key的Redis 节点占用内存多,QPS也会比较大。
d、rdb持久化的时候,fork子线程时对主线程阻塞较大。rdb持久化时,大key发生改动,写时复制耗时较大
大key判断依据:
string类型value大于500kb可以判断为大key,hash,list,set,zset元素数量超过10000个可以判断为大key。
怎么排查大key?
a、redis-cli --bigkeys
注意事项:
1)最好选择在从节点上执行该命令。因为主节点上执行时,会阻塞主节点
2)如果没有从节点,那么可以选择在Redis实例业务压力的低峰阶段进行扫描查询,以免影响到实例的正常运行;或者可以使用-i参数控制扫描间隔,避免长时间扫描降低Redis实例的性能
该方式的不足之处:
1)这个方法只能返回每种类型中最大的那个bigkey,无法得到大小排在前N位的bigkey;
2)对于集合类型来说,这个方法只统计集合元素个数的多少,而不是实际占用的内存量。但是,一个集合中的元素个数多,并不一定占用的内存就多。因为,有可能每个元素占用的内存很小,这样的话,即使元素个数有很多,总内存开销也不大
b、scan命令查找大key
使用SCAN命令对数据库扫描,然后用TYPE命令获取返回的每一个key的类型。
1)对于String类型,可以直接使用STRLEN命令获取字符串的长度,也就是占用的内存空间字节数。
2)对于集合类型,如果知道集合元素的平均大小,可以使用下面的命令获取集合元素的个数,然后乘以集合元素的平均大小,这样就能获得集合占用的内存大小了。List类型:LLEN命令;Hash类型:HLEN命令;Set类型:SCARD命令;Sorted Set类型:ZCARD命令。如果不能提前知道写入集合的元素大小,可以使用 MEMORY USAGE命令(需要 Redis 4.0 及以上版本),查询一个键值对占用的内存空间
c、使用rdbtools工具查找大key
使用RdbTools第三方开源工具,可以用来解析redis快照(RDB)文件,找到其中的大key。
比如,下面这条命令,将大于10kb的key输出到一个表格文件。rdb dump.rdb -c memory --bytes 10240 -f redis.csv
怎么删除大key?
a、异步删除
从Redis4.0版本开始,可以采用异步删除法,用unlink命令代替del来删除,这样Redis会将这个key放入到一个异步线程中进行删除,这样不会阻塞主线程
b、分批次删除
如果不分批次删除,则内存一下子释放大量内存,操作系统需要把释放掉的内存块插入一个空闲内存块的链表,以便后续进行管理和再分配,这个过程本身需要一定时间,而且会阻塞当前释放内存的应用程序。即造成Redis主线程的阻塞,客户端超时等异常。
对于删除hash类型大key,使用hscan命令,每次获取100个字段,再用hdel命令,每次删除1个字段
对于删除list类型大key,使用ltrim命令,每次删除少量元素
对于删除set类型大key,使用sscan命令,每次扫描集合中100个元素,再用srem命令每次删除一个键
对于删除zset类型大key,使用zremrangebyrank命令,每次删除top100个元素
大key怎么处理?
a、把大key分割成多个小key存储,分到不同的cluster节点上
b、考虑压缩算法,减少空间占用
如何对redis大key(hash类型)在线优化,不影响现有业务?假设key为user:info:all,field为uid,value为用户信息
1)优化方案,将大key拆为1000个小key,新key的构成方式user:info:shared_id,shard_id为uid%1000的结果
2)双写单读,写操作时向新Key写入新数据的同时,也向老Key写入,确保数据一致性。读操作只读老key
3)渐进式迁移,实现新key、老key数据一致。后台任务 + 分批迁移的方式,将老Key数据迁移到新Key,使用hscan渐进式扫描老key,每次扫描100或1000个filed(不能用hgetAll命令,避免阻塞redis)写入到新key中
4)通过校验新老key的field数量,待新key数据完整后,逐步将读请求切换到新key。怎么验证新key数据是否完整?可以随机抽取1%的用户,对比新老key的查询结果。新key查询失败,请求可能穿透到数据库,需要做兜底设计(新key查询为空,再查老key或者数据库,将后者查询到的数据回写到新key中)
5)最后删除老key,注意不要用del命令,要用unlink命令异步删除防止阻塞redis
20、redis分布式锁:
之前大型活动中使用分布式锁都是防止用户并发访问,可能存在的问题:Redis主从复制模式中的数据是异步复制的,这样导致分布式锁的不可靠性。如果在Redis主节点获取到锁后,在没有同步到其他节点时,Redis主节点宕机了,此时新的Redis主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
其他形式的分布式锁:控制共享资源,比如一个进程内有多个线程竞争一个数据的使用权限,解决方式之一就是加分布式锁。
最简单的方式:每个线程直接setnx key1 value1 nx ex seconds。如果set成功,表示获取到了锁。
存在的问题:存在服务A释放了服务B的锁的可能。服务A获取了锁,由于业务流程比较长,或者网络延迟、GC卡顿等原因,导致锁过期,而业务还会继续进行。这时候,业务B已经拿到了锁,准备去执行,这个时候服务A恢复过来并做完了业务,就会释放锁,而B却还在继续执行。
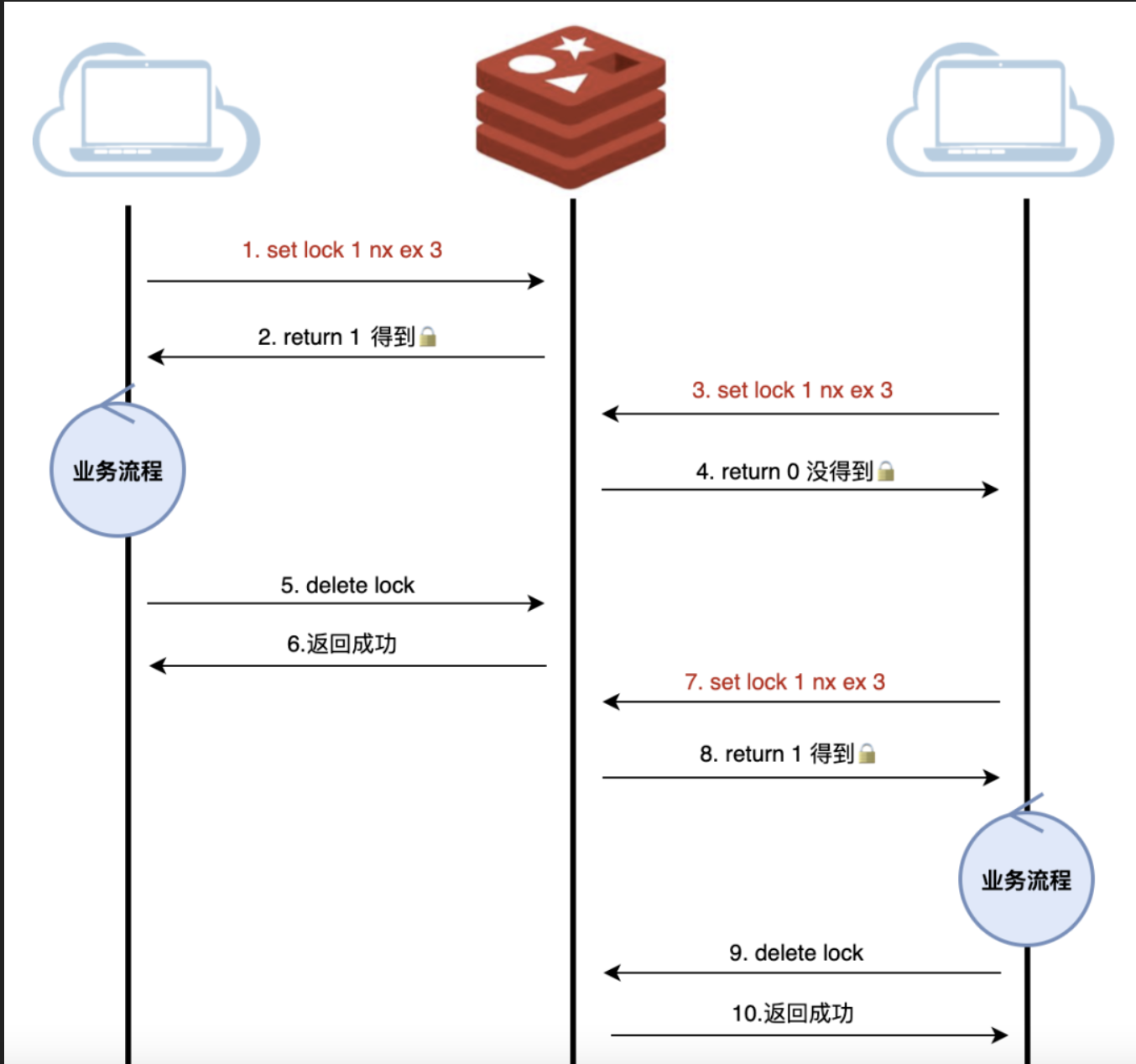
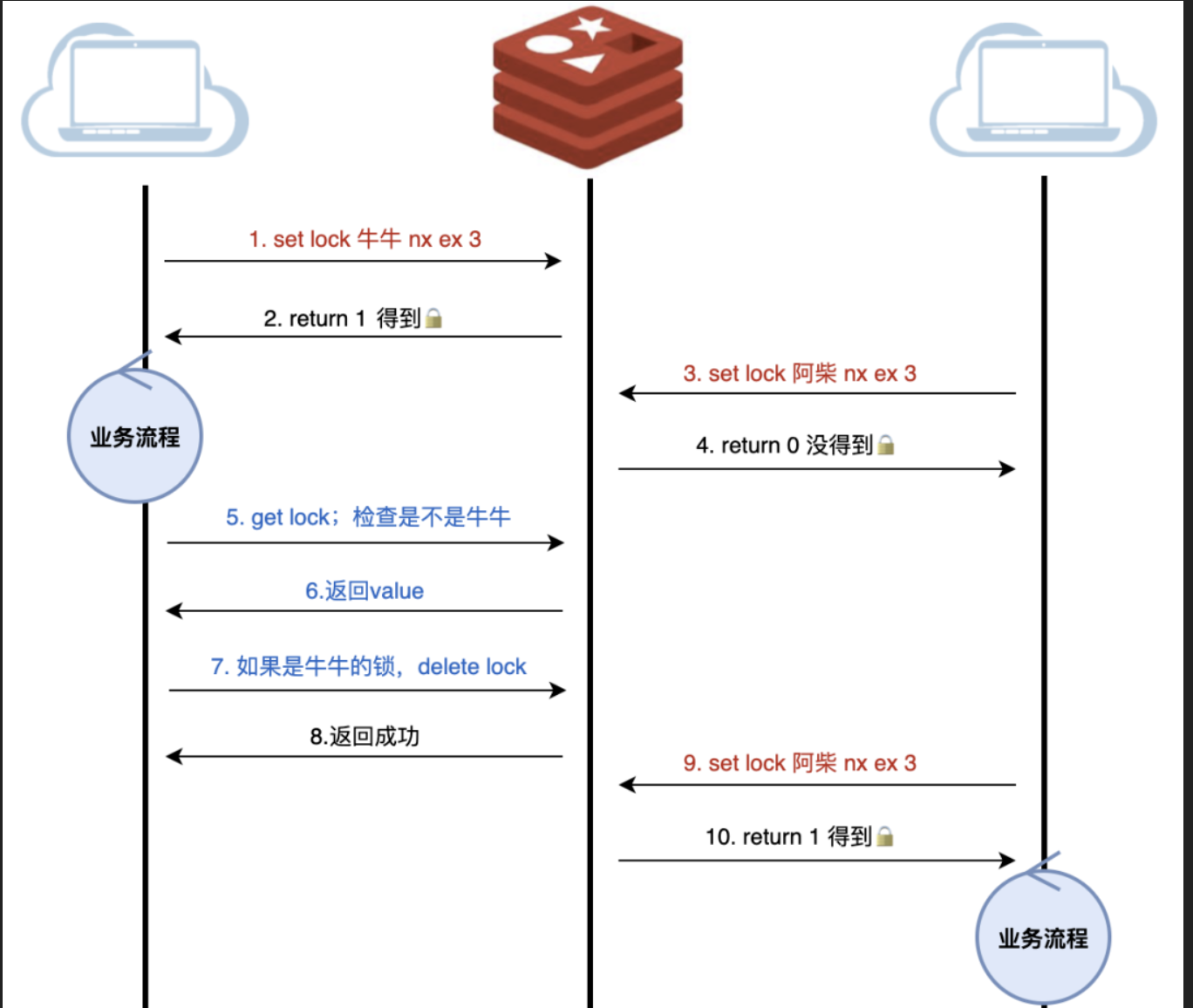
之前的方式进化:锁加上onwer,即redis的value是owner信息。
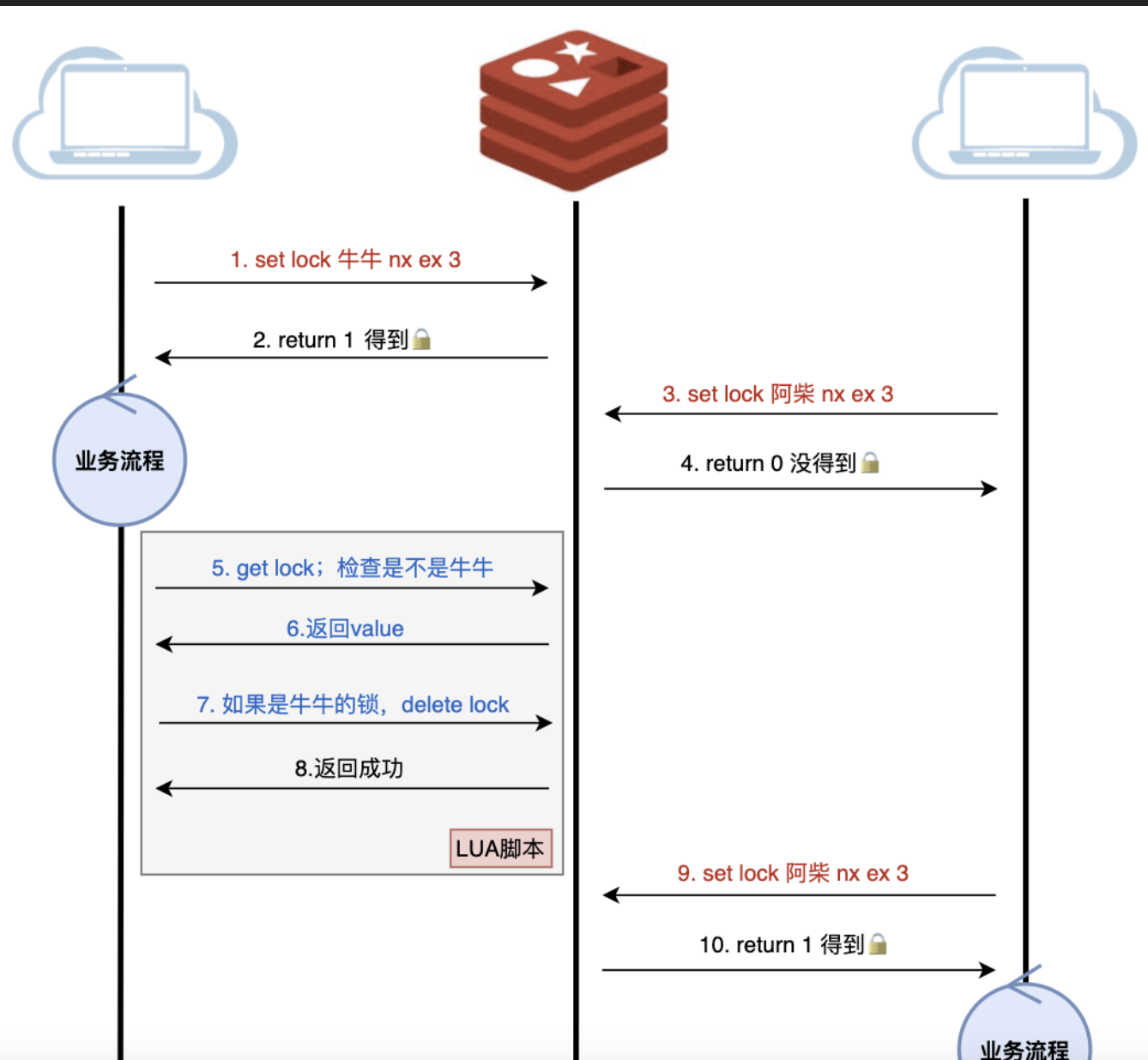
存在的问题:步骤5和步骤7不是原子的,可能步骤5是自己的,步骤7已经是别人的锁了。需要用lua把这几步打包成原子操作
再进化:需要用lua把上图的步骤5到步骤7这几步打包成原子操作
为了解决之前提到可能存在的问题,即master宕机主从切换后,从新的master节点仍然能获取锁。可以使用Redis官方设计的一个分布式锁算法Redlock即红锁:
它是基于多个Redis节点的分布式锁,即使有节点发生了故障,锁变量仍然是存在的,客户端还是可以完成锁操作。官方推荐是至少部署5个Redis节点,而且都是主节点,它们之间没有任何关系,都是一个个孤立的节点。Redlock算法的基本思路,是让客户端和多个独立的Redis节点依次请求申请加锁,如果客户端能够和半数以上的节点成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。这样一来,即使有某个Redis节点发生故障,因为锁的数据在其他节点上也有保存,所以客户端仍然可以正常地进行锁操作,锁的数据也不会丢失。
Redlock 算法加锁三个过程:
a)第一步,客户端获取当前时间(t1)。
b)第二步,客户端按顺序依次向N个Redis节点执行加锁操作,加锁操作使用SET命令,带上NX,EX/PX 选项,以及带上客户端的唯一标识。我们需要给「加锁操作」设置一个超时时间,加锁操作的超时时间需要远远地小于锁的过期时间,一般也就是设置为几十毫秒。
c)第三步,一旦客户端从超过半数(大于等于 N/2+1)的Redis节点上成功获取到了锁,就再次获取当前时间(t2),然后计算计算整个加锁过程的总耗时(t2-t1)。如果t2-t1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败。加锁成功后,客户端需要重新计算这把锁的有效时间,计算的结果是「锁最初设置的过期时间」减去「客户端从大多数节点获取锁的总耗时(t2-t1)」。如果计算的结果已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况
redission客户端已经支持了redlock
分布式锁过期了且业务逻辑没执行完怎么办
1)自己写个定时任务对指定的key续约,比如线程池定时执行任务,任务逻辑:定时检查下业务是否执行完成(业务完成后会设置标识符的值),如果没执行完成,执行redis.expire(key, time)命令重置过期时间
2)使用redission开源组件,内置了watch dog机制对key做续期
21、redis脑裂
脑裂怎么产生的
在Redis主从架构中,部署方式一般是「一主多从」,主节点提供写操作,从节点提供读操作。 如果主节点的网络突然发生了问题,它与所有的从节点都失联了,但是此时的主节点和客户端的网络是正常的,这个客户端并不知道Redis内部已经出现了问题,还在照样的向这个失联的主节点写数据(过程A),此时这些数据被旧主节点缓存到了缓冲区里,因为主从节点之间的网络问题,这些数据都是无法同步给从节点的。
这时,哨兵也发现主节点失联了,它就认为主节点挂了(但实际上主节点正常运行,只是网络出问题了),于是哨兵就会在「从节点」中选举出一个leader作为主节点,这时集群就有两个主节点了即出现了脑裂。
然后,网络突然好了,哨兵因为之前已经选举出一个新主节点了,它就会把旧主节点降级为从节点(A),然后从节点(A)会向新主节点请求数据同步,因为第一次同步是全量同步的方式,此时的从节点(A)会清空掉自己本地的数据,然后再做全量同步。所以,之前客户端在过程A写入的数据就会丢失了,也就是集群产生脑裂数据丢失的问题。
总结一句话就是:由于网络问题,集群节点之间失去联系。主从数据不同步;重新平衡选举,产生两个主服务。等网络恢复,旧主节点会降级为从节点,再与新主节点进行同步复制的时候,由于会从节点会清空自己的缓冲区,所以导致之前客户端写入的数据丢失了。
解决方案:
当主节点发现从节点小于x且主从同步延迟大于阈值y时,那么禁止主节点进行写数据,对于写操作直接把错误返回给客户端。x和y可以在配置文件中设置
22、redis缓冲区
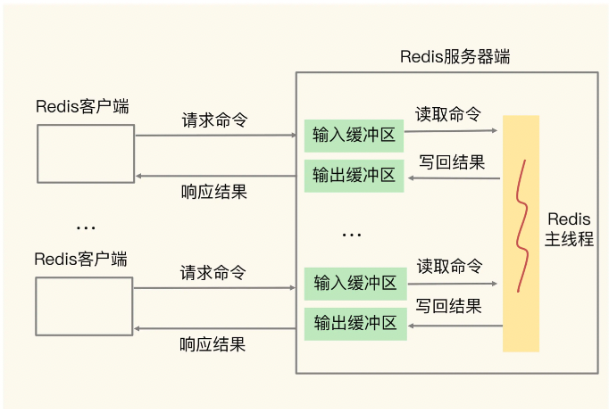
客户端输入缓冲区:
把客户端发送过来的命令暂存起来,Redis主线程再从输入缓冲区中读取命令,进行处理。缓冲区是一块固定大小的内存区域,如果把这个地方填满的话,Redis会直接把客户端连接关闭。服务端默认为每个客户端输入缓冲区分配的大小是1GB,填满的原因:1)往Redis里写大量数据,百万千万数量级那种。2)Redis服务端因执行耗时操作,阻塞住了,导致没法消费输入缓冲区数据
客户端输出缓冲区:
把服务端返回给客户端的数据结果暂存起来,Redis客户端再从输出缓冲区中读取数据,这样的好处是可以充分利用redis的IO多路复用,假如服务端和客户端A的网络较慢,服务端可以把客户端A的请求处理完放在对应的输出缓冲区中,等待客户端A消费数据。然后服务端可以处理客户端B的请求,把redis服务端解放
复制缓冲区:
用于主从复制,主节点上会为每个从节点都维护一个复制缓冲区,在全量复制时,主节点在向从节点传输RDB文件的同时,会继续接收客户端发送的写命令请求,并保存在复制缓冲区中,等RDB文件传输完成后,再把复制缓冲区内的命令发送给从节点去执行。如果从节点接收和加载RDB文件较慢,同时主节点接收到了大量的写命令,写命令在复制缓冲区中就会越积越多,最后就会溢出。
复制积压缓冲区:
详见 https://www.cnblogs.com/MarkLeeBYR/p/17177420.html
复制缓冲区和复制积压缓冲区区别:前者是主节点会为每个从节点都维护一个,应用于全量复制。后者主节点只维护一个,应用于部分复制
23、redis突然变慢原因
a、频繁的持久化,带来较多磁盘IO操作
b、阻塞操作,比如keys
c、网络问题
24、 redis实现数据去重的方式
a、使用redis的set,如果元素很多(比如上亿),占用内存很大
b、使用redis的bitmap,通过把1个bit设置为1或者0,表示元素是否存在,相比使用set可以节省内存
c、使用HyperLogLog,实现大数据量的唯一计数
d、使用布隆过滤器,用于检索一个元素是否在一个集合中
25、redis原子命令
set,get,incr,decr, lpush, rpush, sadd, zadd, exists, del等
26、本地安装redis,分别执行以下命令即可
brew install redis
brew services start redis
redis-cli -h 127.0.0.1 -p 6379

 浙公网安备 33010602011771号
浙公网安备 33010602011771号