[模式识别复习笔记] 第3章 线性判别函数
1. 线性判别函数
1.1 定义
在 \(d\) 维特征空间中,有 线性判别函数:
其中,\(w = [w_1, w_2, \ldots, w_d]^T\) 称为 权值向量,\(b\) 称为 偏置,都是需要学习的参数。\(G(x) = 0\) 为 决策边界方程。
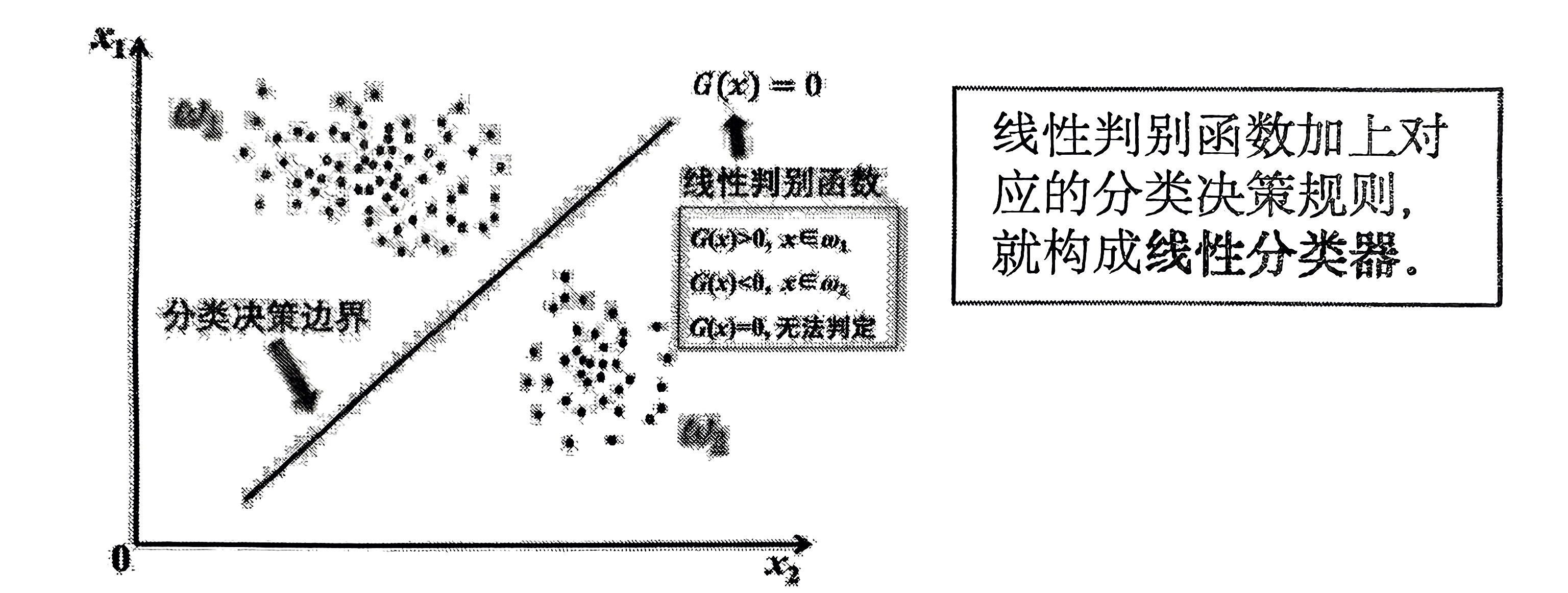
PS:只能解决二分类问题。
1.2 几何意义
\(w\) 为超平面 \(w^{\text{T}} x + b = 0\) 的法向量,\(r\) 为实例 \(x\) 到决策边界的距离。
-
\(x\) 在决策边界的正侧:\(r = \frac{G(x)}{||w||}\)
-
\(x\) 在决策边界的负测:\(r = - \frac{G(x)}{||w||}\)
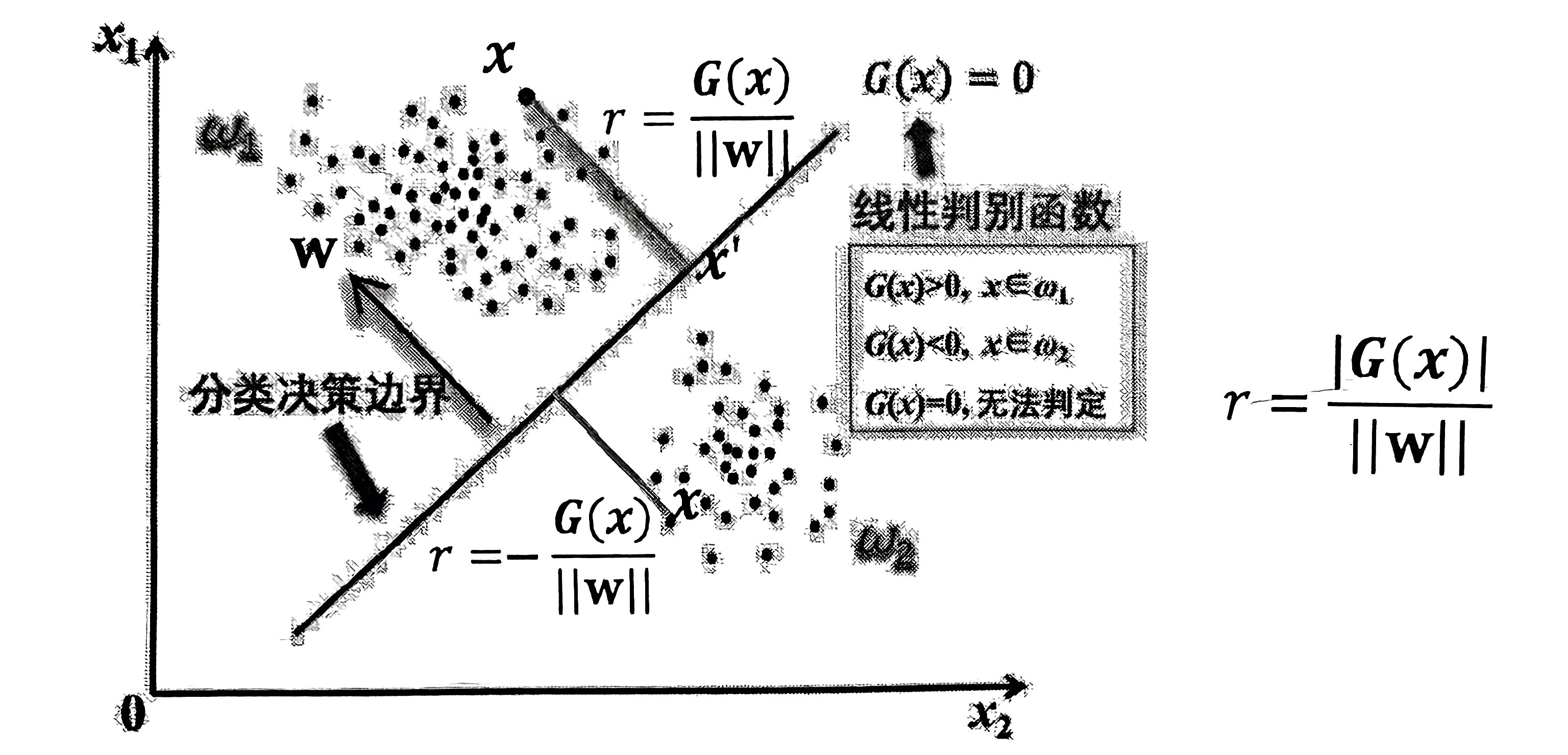
\(w\) 仅代表决策边界的法向量方向,其长度不会影响决策边界在特征空间的位置,因此可以视作 \(||w|| = 1\)。故 判别函数的绝对值 即 实例到决策边界的距离。
1.3 广义线性化
对于一个 线性不可分 问题,可以通过一个非线性变换,映射到高维空间,将识别问题变得线性可分:
2. 感知机
2.1 感知机
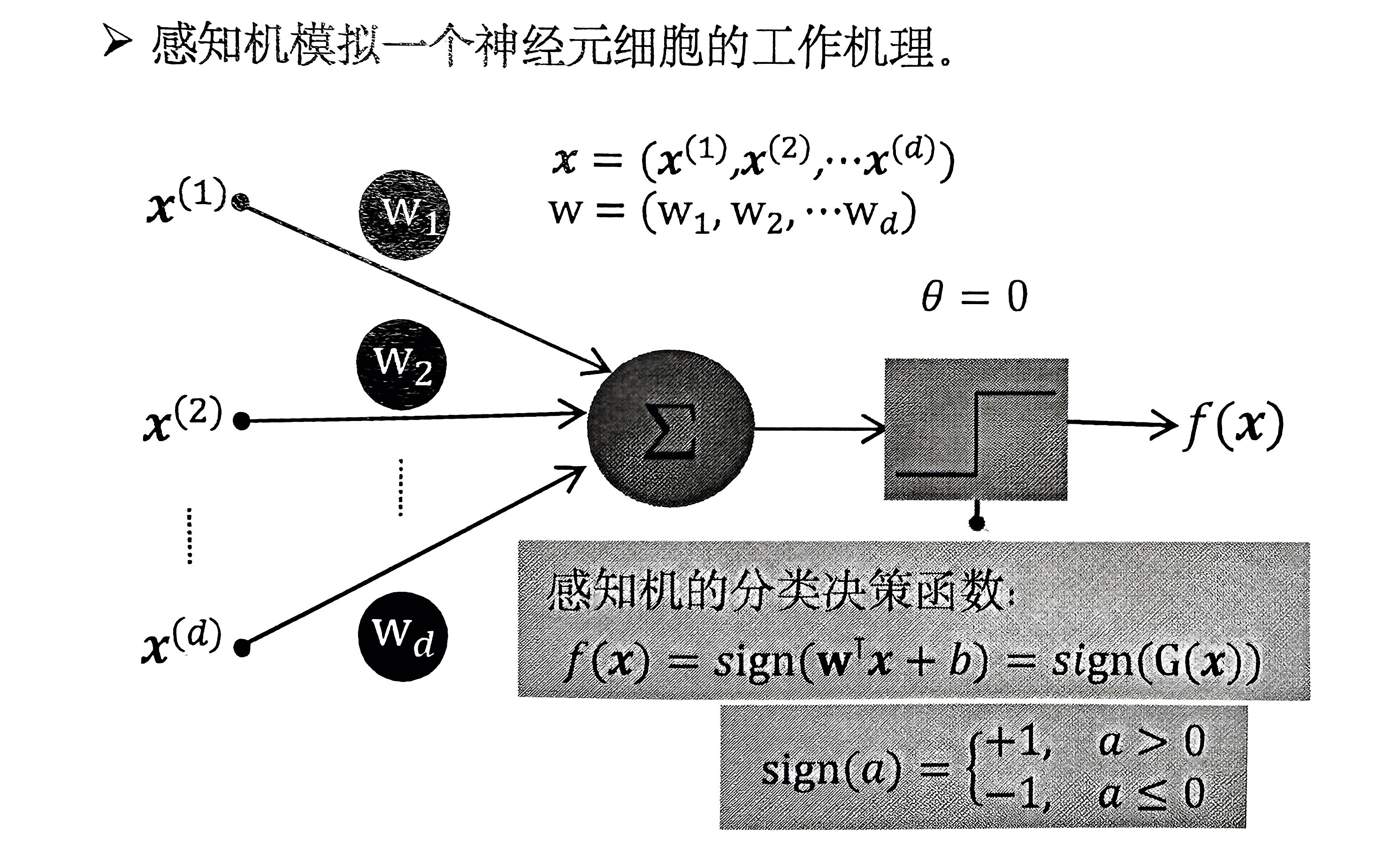
感知机的判别函数:
也就是一个线性判别函数。为了方便表示,将偏置 \(b\) 加入到 \(w\) 中,使得 \(w^{'} = [w_1, w_2, \ldots, w_d, b]^{\text{T}}\),\(x^{'} = [x_1, x_2, \ldots, x_d, 1]^{\text{T}}\),因此判别函数变为:
PS: 后续的表示也都采用 \(G(x) = w^{\text{T}}x\) 的形式。
2.2 感知机训练
给定一个线性可分的二分类训练集:
其中 \(x_i \in \mathbb{R}^d\),\(y_i \in \{ -1, +1 \}\) ,分别表示实例和类标。\((x_i, y_i)\) 称为一个样本。(此处的 \(x_i\) 为已经扩展的特征向量)
感知机的训练目标即:求得一个权值向量 \(w\),使得其对所有训练样本正确分类:
等价于:求得一个权值向量 \(w\),对于所有训练样本有:
2.3 感知机准则函数、学习算法
定义:所有误分类的样本到当前决策超平面的距离之和。
记 \(M\) 为被决策超平面 \(G(x) = w^{\text{T}}x = 0\) 误分类的样本集合。对于 \(\forall (x_i, y_i) \in M\),有 \(y_iw^{\text{T}}x \le 0\)。
因此,\(\forall (x_i, y_i) \in M\),其到决策超平面的距离为:
视 \(||w_{1:d-1}|| = 1\),则感知机的准则函数为:
我们需要最小化这个函数。即求解最优化问题:
对于此无约束优化问题,我们采用梯度下降法解决。准则函数对 \(w\) 的梯度为:
因此,权值向量更新公式为:
其中 \(\eta\) 为学习率,\(\nabla_w J = \sum_{x_i \in M} -y_i x_i\)。
2.4 MGD、SGD训练感知机的流程
-
\(\text{MGD}\)(批量梯度下降算法)
-
随机选取超平面,权值向量初始为 \(w\);
-
令集合 \(M = \emptyset\)。对训练集每个样本进行处理,并将 \(y_i w^{\text{T}}x_i \le 0\) 的样本加入到 \(M\) 中;
-
如果集合 \(M \not = \emptyset\),进行更新:
\[w \leftarrow w - \eta (\sum_{x_i \in M} -y_i x_i) \]其中 \(\eta\) 为学习率。更新完后返回步骤 \(2\)。
如果集合 \(M = \emptyset\),则终止程序。
终止程序后得到的 \(w\) 满足:
\[\forall (x_i, y_i) \in M,有 \ y_i w^{\text{T}}x \le 0 \]训练得到感知机模型:\(f(x) = \text{sign}(w^{\text{T}}x)\)
-
-
\(\text{SGD}\)(随机梯度下降算法)
PS:每次处理一个样本,如果分类错误,就用这个样本来修正权值向量 \(w\)。
-
随机选取超平面,权值向量初始为 \(w\) 或者 \(w = 0\);
-
依次处理训练集的每个样本:
如果 \(y_i w^{\text{T}}x_i \le 0\),则进行更新:
\[w \leftarrow w - \eta (- y_i x_i) \]如果 \(y_i w^{\text{T}}x_i > 0\),则保持 \(w\) 不变,返回步骤 \(2\)。
直到所有样本都被正确分类。
-
2.5 感知机实例(作业)

-
数据规范化得到:
\[\begin{split} x_1 = (3, 3, 1), y_1 = +1 \\\\ x_2 = (5, 2, 1), y_2 = +1 \\\\ x_3 = (1, 1, 1), y_3 = -1 \end{split} \] -
利用 \(\text{SGD}\) 进行求解。初始化 \(w = 0\), \(\eta = 1\):
对于 \(x_1\),由于 \(y_1 w^{\text{T}}x_1 \le 0\),需要更新:\(w = w + \eta y_1 x_1 = (3, 3, 1)\);
对于 \(x_2\),无需更新;
对于 \(x_3\),由于 \(y_3 w^{\text{T}}x_3 \le 0\),需要更新:\(w = w + \eta y_3 x_3 = (2, 2, 0)\);
对于 \(x_1\),无需更新;对于 \(x_2\),无需更新;
对于 \(x_3\),由于 \(y_3 w^{\text{T}}x_3 \le 0\),需要更新:\(w = w + \eta y_3 x_3 = (1, 1, -1)\);
对于 \(x_1\),无需更新;对于 \(x_2\),无需更新;
对于 \(x_3\),由于 \(y_3 w^{\text{T}}x_3 \le 0\),需要更新:\(w = w + \eta y_3 x_3 = (0, 0, -2)\);
对于 \(x_1\),由于 \(y_1 w^{\text{T}}x_1 \le 0\),需要更新:\(w = w + \eta y_1 x_1 = (3, 3, -1)\);
对于 \(x_2\),无需修正;
对于 \(x_3\),由于 \(y_3 w^{\text{T}}x_3 \le 0\),需要更新:\(w = w + \eta y_3 x_3 = (2, 2, -2)\);
对于 \(x_1\),无需更新;对于 \(x_2\),无需更新;
对于 \(x_3\),由于 \(y_3 w^{\text{T}}x_3 \le 0\),需要更新:\(w = w + \eta y_3 x_3 = (1, 1, -3)\);
对于 \(x_1\),无需更新;对于 \(x_2\),无需更新;对于 \(x_3\),无需更新。算法终止。
-
求得模型为: \(f(x) = \text{sign}(x^{(1)} + x^{(2)} - 3)\)。
3. 多分类问题的线性分类
3.1 一对多
对于训练集的每一类实例,训练一个线性判别函数。将属于该类和不属于该类的实例分开。
原则:对实例 \(x\) 进行分类时,当且仅当所有判别函数无冲突才能做出决策。
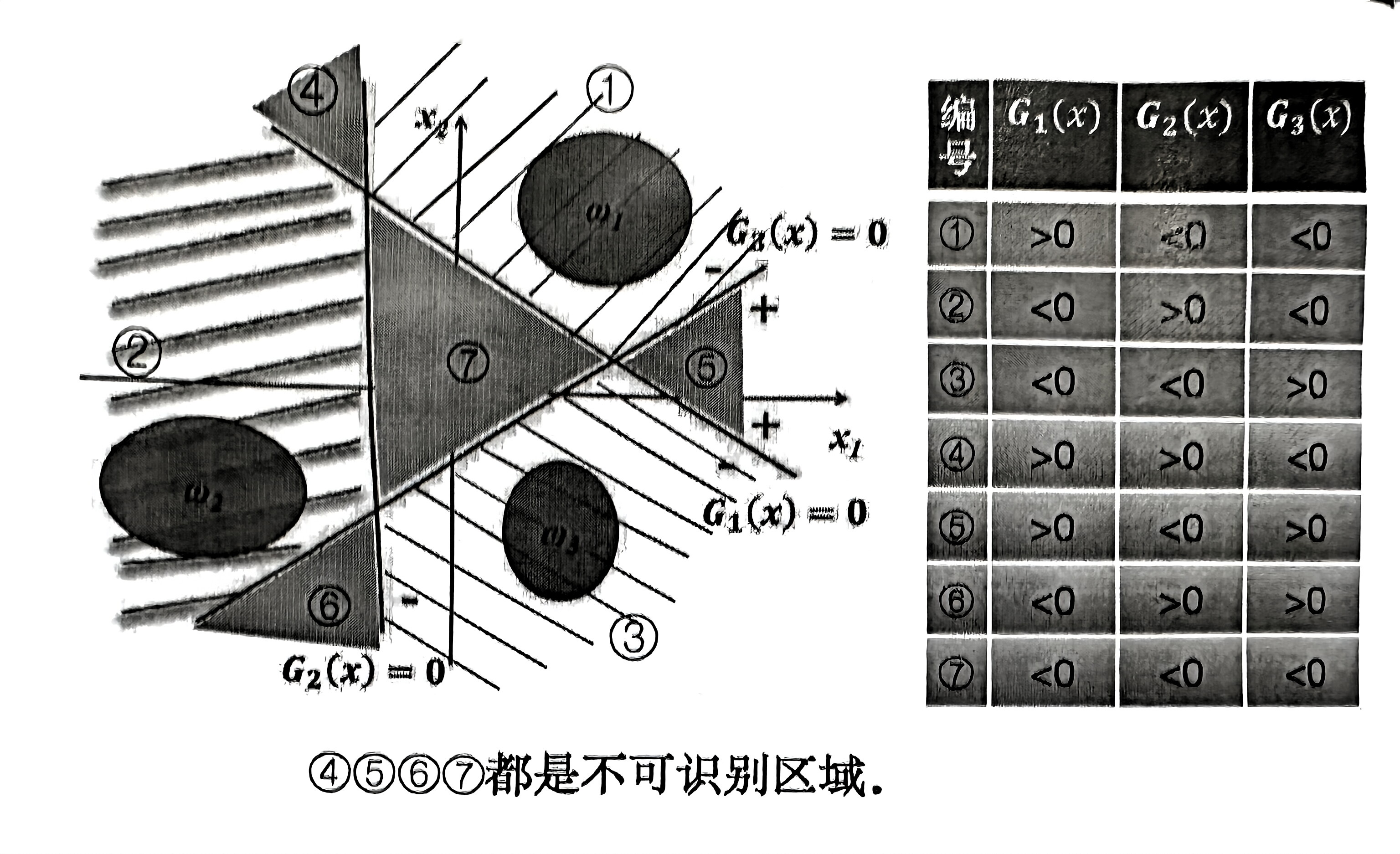
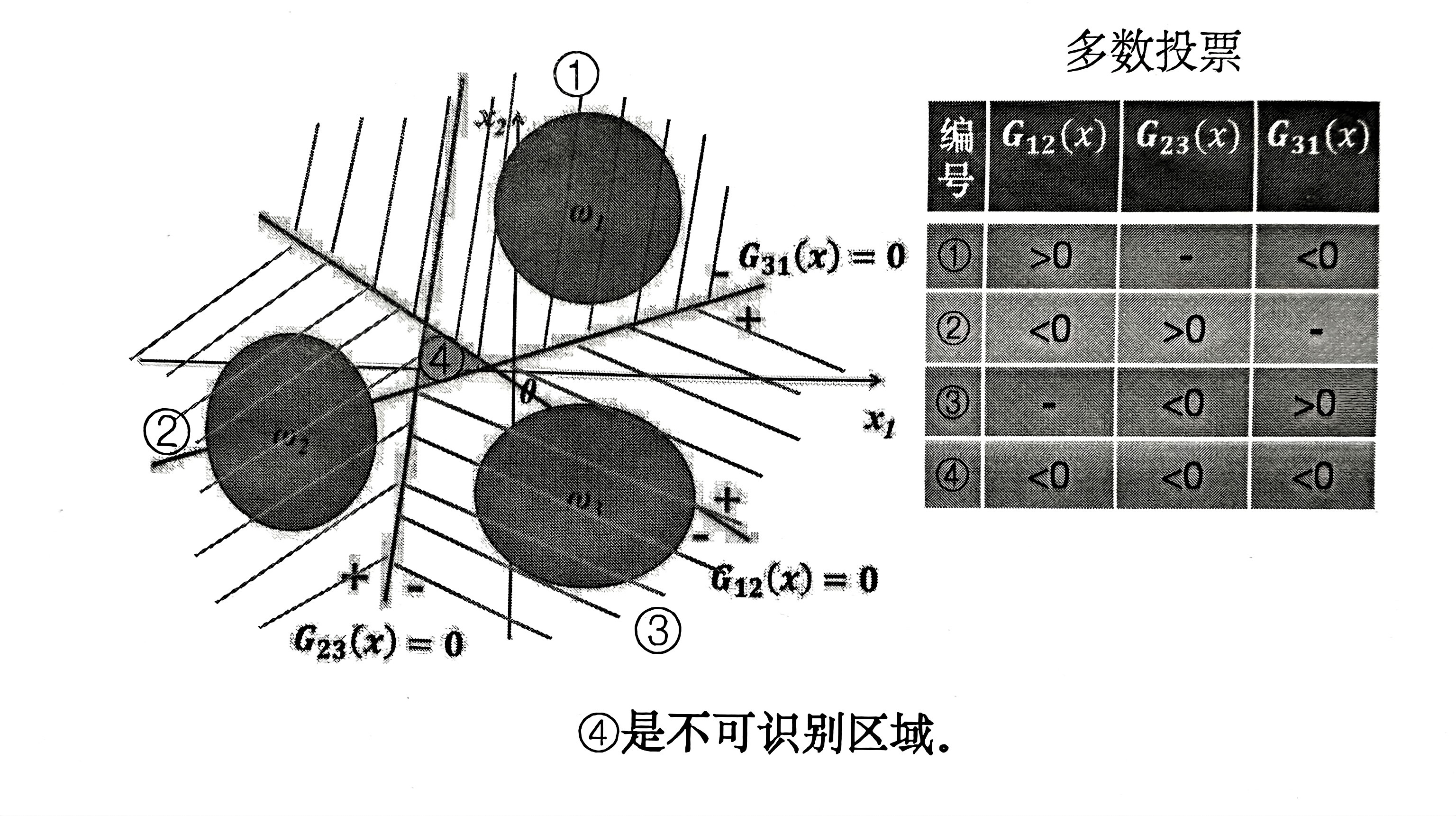
3.2 一对一
对于训练集中任意两个类的实例,训练一个线性判别函数。
原则:多数投票。如果绝大部分分类器认为将 \(x\) 分为 \(w_i\) 类,则将 \(x\) 分为 \(w_i\) 类。
3.3 最大值
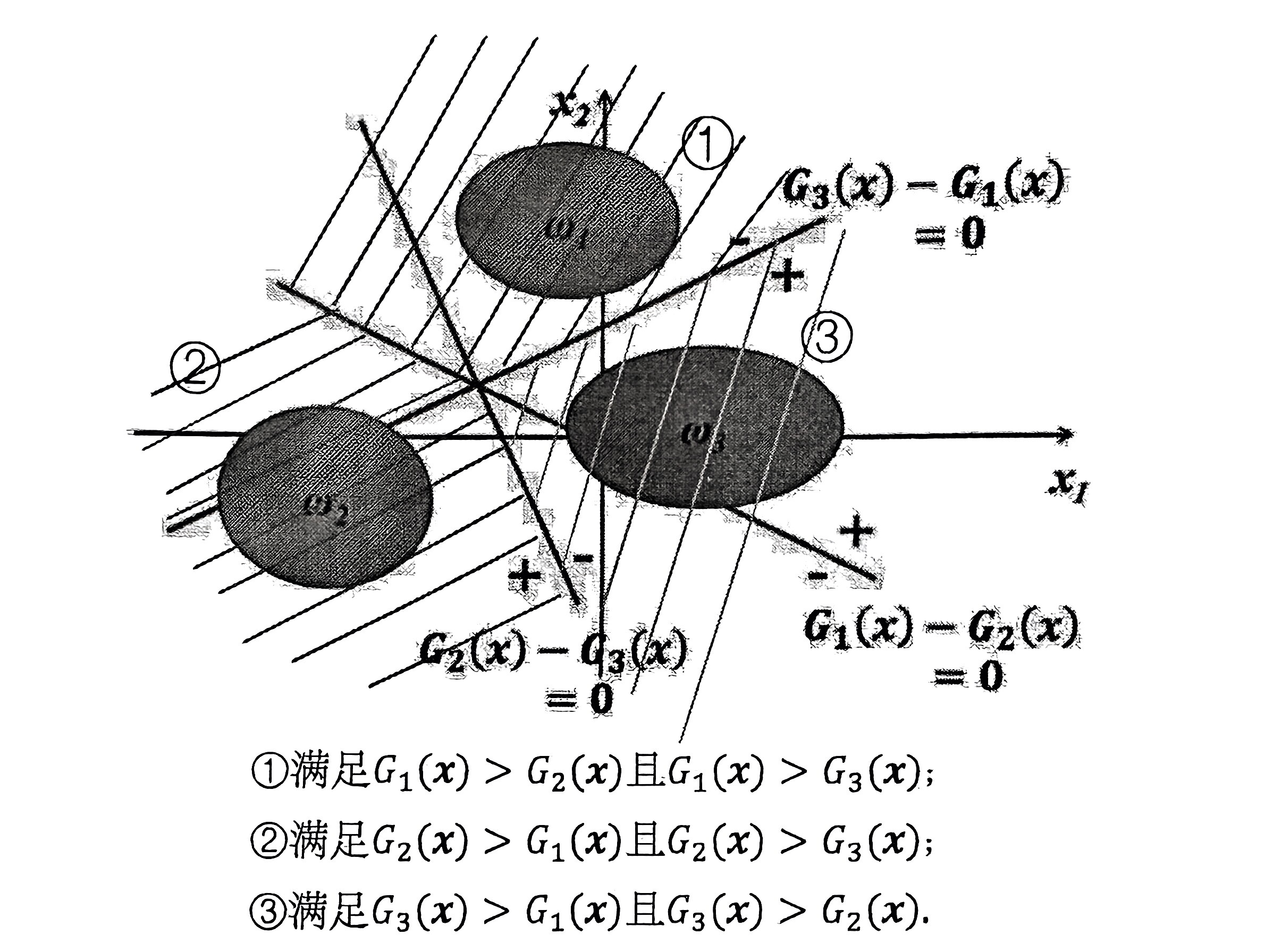
对于训练集中的每个类训练一个判别函数。
原则:将一个实例分到 取值最大的判别函数对应的类 中。
3.4 总结
对于一个 \(k\) 分类问题。
-
一对多:需要 \(k\) 个判别函数。不可识别区域较多。
-
一对一:需要 \(C_k^2\) 个判别函数。不可识别区域较少,但随着 \(k\) 增大,判别函数数量会大大增加,不适用于 \(k\) 较大的情况。
-
最大值:需要 \(k\) 个判别函数。无不可识别区域,但训练判别函数过程复杂。
一切都是命运石之门的选择,本文章来源于博客园,作者:MarisaMagic,出处:https://www.cnblogs.com/MarisaMagic/p/18257712,未经允许严禁转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号