[模式识别复习笔记] 第4章 SVM
1. SVM 简介
1.1 SVM 支持向量机
给定如图所示的线性可分训练集,能够将两类样本正确分开的直线很多。 感知机算法可以找到一条直线,且找到的直线不唯一。
然而感知机无法确定哪一条直线最优,但是 \(\text{SVM}\) 可以。 \(\text{SVM}\) 可以找到能够将训练样本正确分类的直线中 具有最大间隔 的那条直线。
1.2 间隔
-
点到超平面的垂直距离
给定一个分割超平面 \(w^{\text{T}} x + b = 0\),线性判别函数 \(g(x) = w^{\text{T}} x + b = 0\) 将整个特征空间分为两个决策域:\(g(x) > 0\) 和 \(g(x) < 0\)。
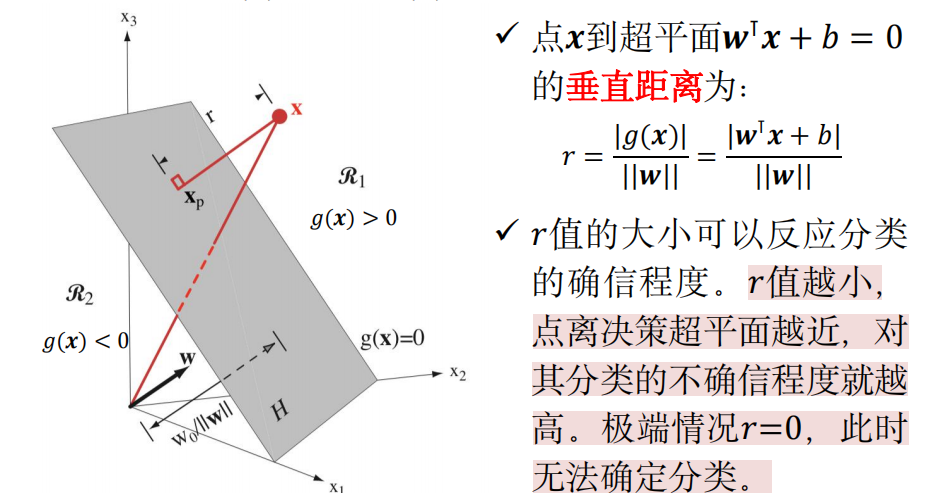
-
间隔
给定一个训练数据集 \(\{ (x_1, y_1), (x_2, y_2), \ldots, (x_N, y_N) \}\),\(x_i \in \mathbb{R}^d\), \(y_i \in \{ +1, -1 \}\)。
超平面 \(w^{\text{T}} x + b = 0\) 关于 样本点 \((x_i, y_i)\) 间隔:
\[r_i = \frac{w^{\text{T}}x + b}{||w||} \]超平面 \(w^{\text{T}} x + b = 0\) 关于训练集 的 间隔:
\[r_{min} = \min_{i=1,\ldots, N} r_i \]即 所有样本点的间隔中的最小间隔。
2. 线性 \(\text{SVM}\) (硬间隔)
2.1 问题描述
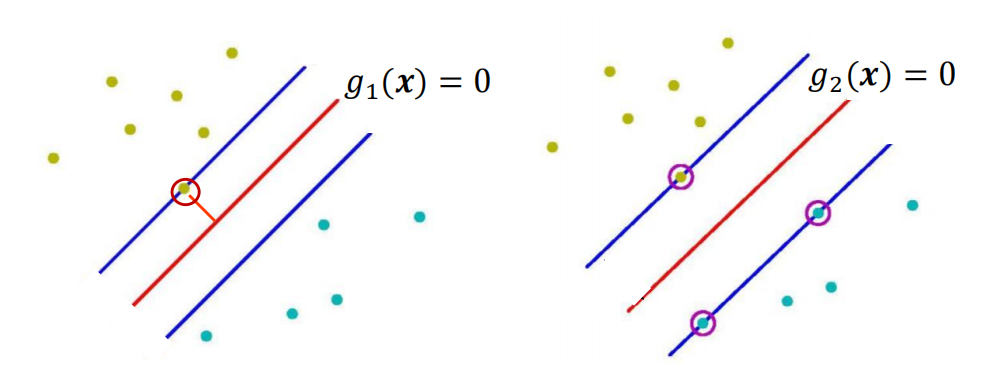
\(\text{SVM}\) 思想: 寻找能够 正确划分训练数据集 并且 在训练数据集上具有最大间隔 的超平面。
PS:上图中左图的间隔小于右图中的间隔,所以右图的超平面更优。
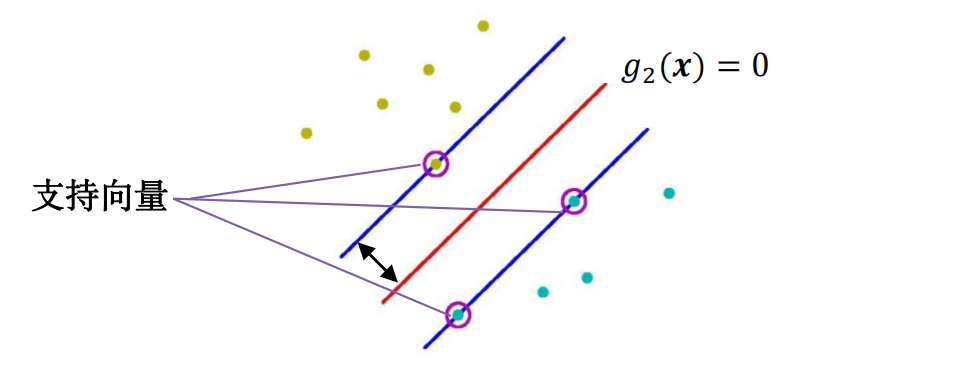
间隔最大化,即将训练集中距离超平面最近的样本点,能够以最大的置信度分类。(最小间隔最大化)。 训练集中具有 最小间隔的样本点 称为 支持向量。
2.2 形式化描述
\(\text{SVM}\) 形式化描述:
-
假设训练数据集线性可分
-
找到一个划分超平面 \(w^{\text{T}}x + b = 0\),满足:
-
正确划分训练样本。即 \(\forall i = 1, \ldots, N\),有 \(y_i(w^{\text{T}}x_i + b) > 0\)。
-
最大化训练集上的间隔(最小间隔最大化)
\[\max_{w, b}(\min_{i=1,\ldots,N} \frac{|w^{\text{T}}x_i + b|}{||w||}) \]
-
-
由 \(|w^{\text{T}}x_i + b| = y_i(w^{\text{T}}x_i + b)\),则:
\[\max_{w, b}(\min_{i=1,\ldots,N} \frac{|w^{\text{T}}x_i + b|}{||w||}) = \max_{w, b}(\frac{1}{||w||} \min_{i=1,\ldots,N}y_i(w^{\text{T}}x_i + b)) \] -
令 \(\min_{i=1,\ldots,N}y_i(w^{\text{T}}x_i + b) = 1\),则:
\[\forall i, \ y_i(w^{\text{T}}x_i + b) \ge 1 \] -
原优化问题等价于:
\[\begin{split} & \max_{w, b} \frac{1}{||w||} \\\\ & \text{s.t.} \ y_i(w^{\text{T}}x_i + b) \ge 1, \forall i = 1, \ldots, N \end{split} \] -
由于:
\[\text{argmax}_{w} \frac{1}{||w||} = \text{argmin}_{w} \frac{1}{2} ||w||^2 \]原问题等价于:
\[\begin{split} & \min_{w, b} \frac{1}{2} ||w||^2 \\\\ & \text{s.t.} \ y_i(w^{\text{T}}x_i + b) \ge 1, \forall i = 1, \ldots, N \end{split} \]此问题为凸二次规划问题。由此得到 硬间隔最大化 的表达式。
求解上述优化问题得到最优解 \(w^{*}\), \(b^{*}\)。划分超平面为 \({w^{*}}^{\text{T}} x + b^{*} = 0\),分类决策函数 \(f(x) = \text{sign}({w^{*}}^{\text{T}} x + b^{*})\)。
训练集中具有 最小间隔的样本点 称为 支持向量。满足:
故支持向量到划分超平面的距离为 \(\frac{1}{||w^{*}||}\)。
-
对于正类(\(y_i = +1\))的支持向量,有:
\[{w^{*}}^{\text{T}} x + b^{*} = 1 \] -
对于负类(\(y_i = -1\))的支持向量,有:
\[{w^{*}}^{\text{T}} x + b^{*} = -1 \]
在决定分类决策超平面的位置时,只有支持向量起作用,其它样本点不起作用,即使删除这些样本点,也不影响分类决策边界。所以这种分类模型称为“支持向量机”。
2.3 对偶优化问题
-
\(\text{SVM}\) 原始优化问题:
\[\begin{split} & \min_{w, b} \frac{1}{2} ||w||^2 \\\\ & \text{s.t.} \ y_i(w^{\text{T}}x_i + b) \ge 1, \forall i = 1, \ldots, N \end{split} \] -
推导出其 对偶优化问题:
引入拉格朗日乘子 \(\alpha \ge 0\),定义拉格朗日函数:
\[L(w, b, \alpha) = \frac{1}{2}||w||^2 + \sum_{i=1}^{N} \alpha_i (1 - y_i (w^{\text{T}}x_i + b)) \]对偶优化目标函数为:
\[\theta_D(\alpha) = \min_{w,b}L(w, b, \alpha) \]令 \(L(w, b, \alpha)\) 关于 \(w\) 和 \(b\) 的偏导数分别为 \(0\):
\[\nabla_{w}L(w, b, \alpha) = 0 \rightarrow w = \sum_{i=1}^{N}\alpha_i y_i x_i \]\[\nabla_{b}L(w, b, \alpha) = 0 \rightarrow \sum_{i=1}^{N} \alpha_i y_i = 0 \]带入拉格朗日函数 得:
\[\theta_D(\alpha) = \frac{1}{2}(\sum_{i=1}^{N}\alpha_i y_i x_i)^{\text{T}}(\sum_{i=1}^{N}\alpha_i y_i x_i) + \sum_{i=1}^{N} \alpha_i - (\sum_{i=1}^{N}\alpha_i y_i x_i)^{\text{T}}(\sum_{i=1}^{N}\alpha_i y_i x_i) - \sum_{i=1}^{N} \alpha_i y_i b \]化简得到:
\[\theta_{D}(\alpha) = -\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_i y_j x^{\text{T}}_i x_j + \sum_{i=1}^{N} \alpha_i \]由于 \(\text{argmax}_{\alpha} \theta_{D}(\alpha)\) 等价于 \(\text{argmin}_{\alpha} - \theta_{D}(\alpha)\),故 \(\text{SVM}\) 的对偶优化问题为:
\[\begin{split} & \min_{\alpha}\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j x_i^{\text{T}} x_j - \sum_{i=1}^{N} \alpha_i \\\\ & s.t. \ \alpha_i \ge 0, \forall \ i = 1, \ldots , N \\\\ & \quad \sum_{i=1}^N \alpha_i y_i = 0 \end{split} \] -
通过上述对偶问题求解出 \(\alpha^{*}\),由此构造出划分超平面的 \(w^{*}\) 和 \(b^{*}\)
将 \(\alpha^{*}\) 带入得:
\[w^{*} = \sum_{i=1}^N \alpha_i^{*} y_i x_i \]\[\sum_{i=1}^N \alpha_i^{*} y_i = 0 \]由 \(\text{KKT}\) 条件得到:
-
对偶互补条件:
\[\alpha_{i}^{*}(1 - y_i({w^{*}}^{\text{T}}x_i + b^{*})) = 0, \ i = 1, \ldots , N \] -
原问题约束:
\[y_i({w^{*}}^{\text{T}}x_i + b^{*}) \ge 1, \ i = 1, \ldots, N \] -
对偶约束:
\[\sum_{i=1}^N \alpha_i^{*} y_i = 0 \]\[\alpha_{i}^{*} \ge 0, \ i = 1, \ldots, N \]
根据上述的 \(\text{KKT}\) 条件可得,至少有一个拉格朗日乘子 \(\alpha_j > 0\)。
若所有拉格朗日乘子都满足 \(\alpha_i = 0\),则 \(w^{*} = 0\),这不是问题的可行解,故矛盾。
由 \(\alpha_j \not = 0\),得 \(1 - y_j({w^{*}}^{\text{T}}x_i + b^{*}) = 0\),结合 \(y_j^2 = 1\) 可得:
\[b^{*} = y_j - {w^{*}}^{\text{T}}x_j = y_j - \sum_{i=1}^{N}\alpha^{*} y_i x_i^T x_j \] -
-
综上,若 \(\text{SVM}\) 对偶问题得最优解为 \(\alpha^{*} = (\alpha_1^{*} , \cdots, \alpha_{N}^{*})\),则存在 \(\alpha_j^{*} > 0\),由此求得最优解:
最后,得到划分超平面 \({w^{*}}^{\text{T}} x + b^{*} = 0\),分类决策函数为 \(f(x) = \text{sign}({w^{*}}^{\text{T}} x + b^{*})\)。
3. 线性 \(\text{SVM}\) (软间隔)
3.1 问题描述
数据集中存在少量的噪声/异常样本点,导致数据集线性不可分。
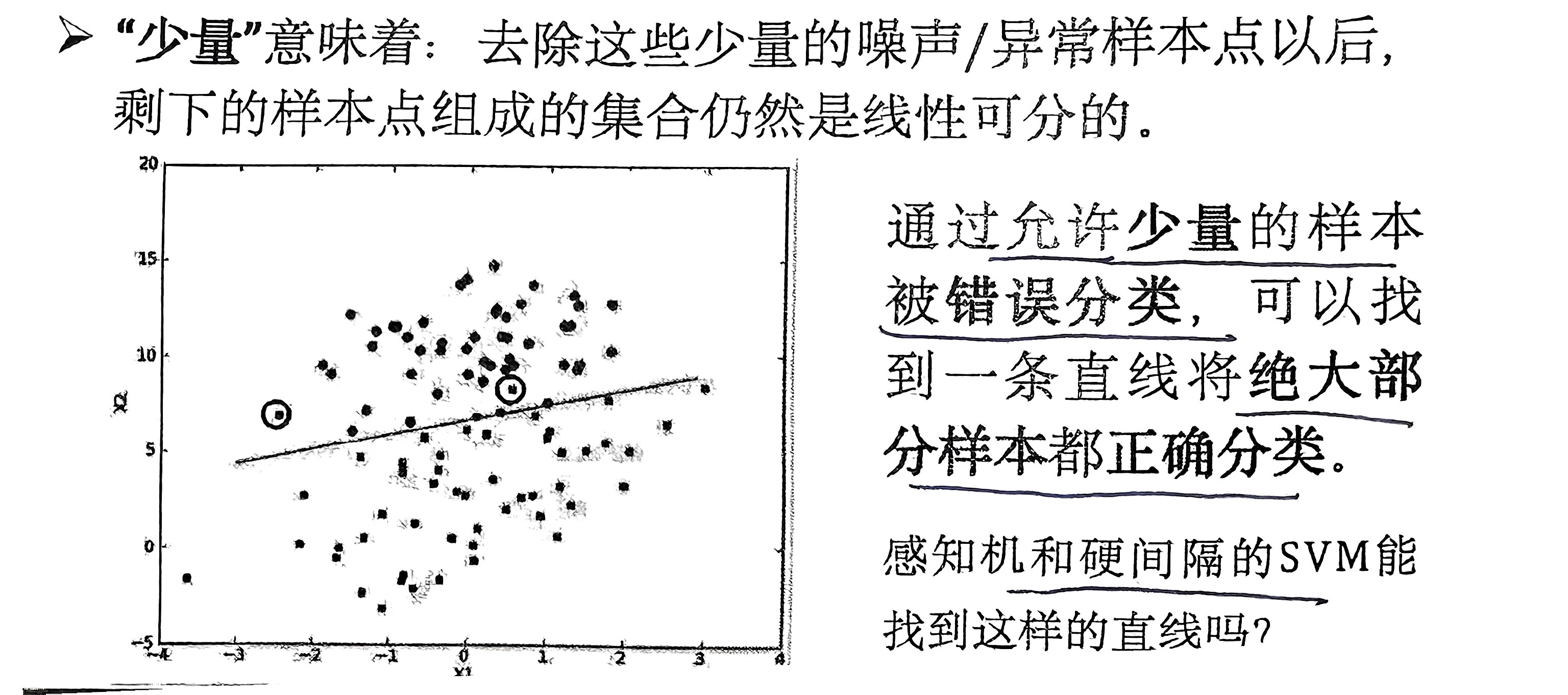
3.2 形式化描述
数据集中存在少量样本点 \((x_i, y_i)\),不能满足 \(y_i(w^{\text{T}}x_i + b) \ge 1\)。因此,可以对每个样本引入一个 松弛变量 \(\xi_i \ge 0\),使得 \(y_i(w^{\text{T}}x_i + b) \ge 1 - \xi_i\),同时 最小化 松弛变量 \(\xi_i\) 的取值。由此优化问题变为:
也就是 软间隔最大化 的表达式。
\(C > 0\) 是一个预定义的常数,称为 惩罚系数,\(C\) 值越大表明对误分类的惩罚越大。
\(C\) 越大,意味着要求更多样本以足够大的置信度被正确分类;\(C\) 越小(\(C \rightarrow 0\)),意味着允许更多的样本被错误分类。
对于近似线性可分的数据集,绝大部分样本点对应的松弛变量 \(\xi_i = 0\),少部分异常点 \(\xi_i > 0\)。
3.3 对偶优化问题
-
原始优化问题:
\[\begin{split} & \min_{w,b,\xi} \frac{1}{2} ||w||^2 + C\sum_{i=1}^{N} \xi_i \\\\ & \text{s.t.} \ y_i(w^{\text{T}}x_i + b) \ge 1 - \xi_i, \ \forall i = 1, \ldots, N \\\\ & \quad \xi_i \ge 0, \ i = 1, \ldots, N \end{split} \] -
推导出 对偶优化问题:
- 定义拉格朗日函数,引入拉格朗日乘子 \(\alpha \ge 0\), \(\beta \ge 0\):
\[L(w, b, \xi, \alpha, \beta) = \frac{1}{2} ||w||^2 + C\sum_{i=1}^{N}\xi_i + \sum_{i=1}^{N} \alpha_i (1 - \xi_i - y_i(w^{\text{T}}x_i + b)) - \sum_{i=1}^{N} \beta_i \xi_i \]- 对偶优化目标函数:
\[\theta_{D}(\alpha, \beta) = \min_{w, b, \xi} L(w, b, \xi, \alpha, \beta) \]令 \(L\) 关于 \(w, b, \xi_i\) 的偏导数分别为 \(0\):
\[\nabla_{w}L(w, b, \xi, \alpha, \beta) = 0 \rightarrow w = \sum_{i=1}^{N} \alpha_i y_i x_i \]\[\nabla_{b}L(w, b, \xi, \alpha, \beta) = 0 \rightarrow \sum_{i=1}^{N}\alpha_i y_i = 0 \]\[\nabla_{\xi_i}L(w, b, \xi, \alpha, \beta) = 0 \rightarrow C = \alpha_i + \beta_i, \ \forall i = 1, \ldots, N \]带入拉格朗日函数 得:
\[\begin{split} \theta_{D}(\alpha, \beta) = \frac{1}{2}(\sum_{i=1}^{N}\alpha_i y_i x_i)^{\text{T}}(\sum_{i=1}^{N}\alpha_i y_i x_i) + C\sum_{i=1}^{N} \xi_i + \sum_{i=1}^{N} \alpha_i - \sum_{i=1}^{N} \alpha_i \xi_i - (\sum_{i=1}^{N}\alpha_i y_i x_i)^{\text{T}}(\sum_{i=1}^{N}\alpha_i y_i x_i) \\\\ - b\sum_{i=1}^{N}\alpha_i y_i - \sum_{i=1}^{N} \beta_i \xi_i \end{split} \]整理得到:
\[\theta_{D}(\alpha, \beta) = -\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_i y_j x^{\text{T}}_i x_j + \sum_{i=1}^{N} \alpha_i \](可以发现和线性SVM一样的表达式)
由于 \(\text{argmax}_{\alpha, \beta} \theta_{D}(\alpha, \beta)\) 等价于 \(\text{argmin}_{\alpha, \beta} - \theta_{D}(\alpha, \beta)\),故 \(\text{SVM}\) 的对偶优化问题为:
\[\begin{split} & \min_{\alpha}\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j x_i^{\text{T}} x_j - \sum_{i=1}^{N} \alpha_i \\\\ & \text{s.t.} \ \alpha_i \ge 0, \ \beta_i \ge 0 , \ \forall \ i = 1, \ldots , N \\\\ & \quad \sum_{i=1}^N \alpha_i y_i = 0 \\\\ & \quad \alpha_i + \beta_i = C, \ \forall \ i = 1, \ldots , N \end{split} \]去掉有关 \(\beta\) 的信息,由 \(C - \alpha_i = \beta_i \ge 0\),可以将对偶优化问题化简如下:
\[\begin{split} & \min_{\alpha}\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j x_i^{\text{T}} x_j - \sum_{i=1}^{N} \alpha_i \\\\ & \text{s.t.} \ 0 \le \alpha_i \le C, \ \forall \ i = 1, \ldots , N \\\\ & \quad \sum_{i=1}^N \alpha_i y_i = 0 \end{split} \]
-
通过上述对偶问题求解出 \(\alpha^{*}\),由此构造出划分超平面的 \(w^{*}\) 和 \(b^{*}\)
将 \(\alpha^{*}\) 带入得:
\[w^{*} = \sum_{i=1}^N \alpha_i^{*} y_i x_i \]\[\sum_{i=1}^N \alpha_i^{*} y_i = 0 \]\[\alpha_i^{*} + \beta_i^{*} = C, \ \forall i = 1, \ldots, N \]由 \(\text{KKT}\) 条件得到:
-
对偶互补条件:
\[\alpha_{i}^{*}(1 - \xi_i^{*} - y_i({w^{*}}^{\text{T}}x_i + b^{*})) = 0, \ \forall i = 1, \ldots , N \]\[\beta_i^{*} \xi_i^{*} = 0, \ \forall i = 1, \ldots, N \] -
原问题约束:
\[y_i({w^{*}}^{\text{T}}x_i + b^{*}) \ge 1 - \xi_i^{*}, \ i = 1, \ldots, N \]\[\xi_i^{*} \ge 0, \ \forall i = 1, \ldots, N \] -
对偶约束:
\[\sum_{i=1}^{N} \alpha_i^{*} y_i = 0 \]\[0 \le \alpha_{i}^{*} \le C, \ i = 1, \ldots, N \]
根据上述条件可得:
-
若 \(\alpha_j^{*} > 0\),则 \(y_j({w^{*}}^{\text{T}}x_j + b^{*}) = 1 - \xi_{i}^{*}\)
-
若 \(\alpha_j^{*} < C\),则 \(\beta_j^{*} > 0\),故 \(\xi_j^{*} = 0\)
故当 \(0 < \alpha_j^{*} < C\) 时,有 \(y_j({w^{*}}^{\text{T}}x_j + b^{*}) = 1\)。
-
-
综上,若 \(\text{SVM}\) 对偶问题得最优解为 \(\alpha^{*} = (\alpha_1^{*} , \cdots, \alpha_{N}^{*})\),则存在 \(0 < \alpha_j^{*} < C\),由此求得最优解:
最后,得到划分超平面 \({w^{*}}^{\text{T}} x + b^{*} = 0\),分类决策函数为 \(f(x) = \text{sign}({w^{*}}^{\text{T}} x + b^{*})\)。
3.4 推论
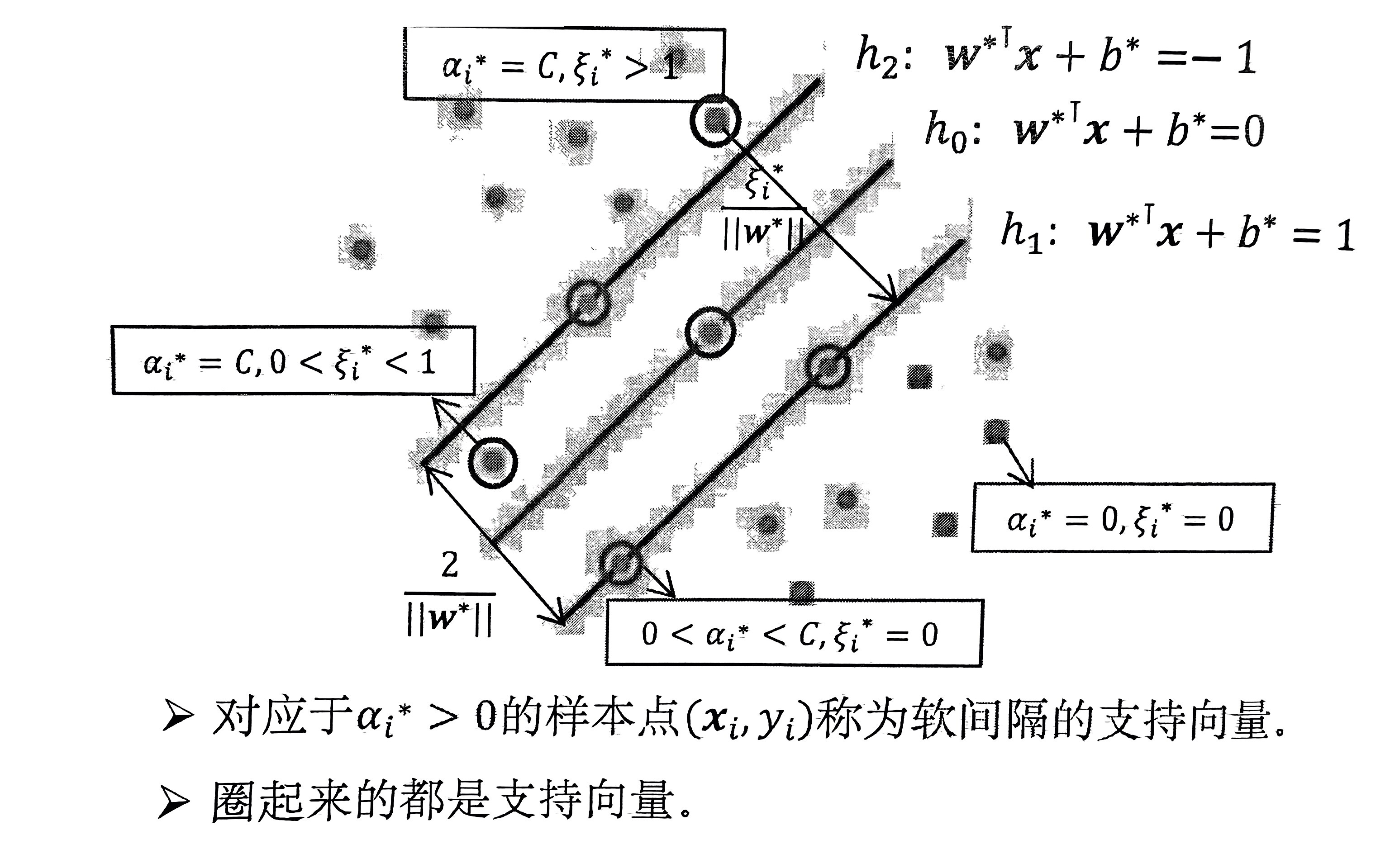
-
若 \(\alpha_i^{*} = 0\),则 \(\beta_i^{*} = C \rightarrow \xi_i^{*} = 0 \rightarrow y_i({w^{*}}^{\text{T}}x_i + b^{*}) \ge 1\)。
此时 \(\alpha_i^{*}\) 对应的 \((x_i, y_i)\) 能以充分的置信度被正确分类。
-
若 \(0 < \alpha_i^{*} < C\),则 \(y_i({w^{*}}^{\text{T}}x_i + b) = 1\)。
对应的 \((x_i, y_i)\) 是支持向量,在间隔边界上。
-
若 \(\alpha_i^{*} = C\),则 \(\beta_i^{*} = 0 \rightarrow \xi_i^{*} \ge 0\)。
-
若 \(0 < \xi_i < 1\),则 \(y_i({w^{*}}^{\text{T}}x_i + b^{*}) \ge 1 - \xi_i^{*} > 0\),表明 可以被正确分类,但没有充分的置信度。
-
若 \(\xi_i \ge 1\),则 \(y_i({w^{*}}^{\text{T}}x_i + b^{*}) \ge 1 - \xi_i^{*}, 1 - \xi_i^{*} \le 0\),此时对应的样本点被 错误分类。
-
4. 核函数 \(\text{SVM}\)
4.1 问题描述
有时候问题本质上就线性不可分,原本的样本空间不存在一个可以正确划分两类样本的划分超平面。而需要一个超曲面才可以将样本分开。

对于 线性不可分 问题,可以将样本空间映射到一个 更高维度 的空间,使得样本在此特征空间内线性可分。(广义线性化)
4.2 对偶优化问题
将原始空间样本 \(x_i\) 经过映射后变为 \(\Phi (x_i)\)。
其对应的 对偶问题 为:
综上,若 \(\text{SVM}\) 对偶问题得最优解为 \(\alpha^{*} = (\alpha_1^{*} , \cdots, \alpha_{N}^{*})\),则存在 \(0 < \alpha_j^{*} < C\),由此求得最优解:
最后,得到划分超平面 \({w^{*}}^{\text{T}} \Phi(x) + b^{*} = 0\),分类决策函数为 \(f(x) = \text{sign}({w^{*}}^{\text{T}} \Phi(x) + b^{*})\)。
式中涉及到计算 $\Phi(x_i)^{\text{T}}\Phi(x_j) $,由于特征空间维数可能很高,计算往往会非常困难。
所以这里可以设想一个函数:
即 \(x_i\) 和 \(x_j\) 在 特征空间的内积等于它们在原始的样本空间中通过 函数 \(\kappa\) 计算得出的结果。这就避免了高维度的计算,也就是采用了 核技巧。
由此 对偶问题 可以重写为:
由此求得最优解:
分类决策函数为:
4.3 常用核函数
然而一般情况下,我们不知道 \(\Phi\) 的具体形式。我们有如下定理:
令 \(\chi\) 为输入空间,\(\kappa\) 为定义在 \(\chi \times \chi\) 的对称函数,则 \(\kappa\) 是 核函数 当且仅当 对于任意数据 \(D = \{x_1, x_2, ... , x_n\}\) ,核矩阵 (\(\text{kernel}\) \(\text{matrix}\)) \(K\) 总是半正定的:
只要一个对称函数对应的核矩阵半正定,其可作为 核函数 使用。
常用核函数:
- 线性核函数
- 多项式核函数
- 高斯核函数(也称径向基RBF函数)
- 拉普拉斯核函数*
- \(\text{sigmoid}\) 核函数*
上述的核函数,也可以通过线性组合等方式,组成新的核函数。
一切都是命运石之门的选择,本文章来源于博客园,作者:MarisaMagic,出处:https://www.cnblogs.com/MarisaMagic/p/18257073,未经允许严禁转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号