[NLP复习笔记] Seq2Seq 模型、Attention机制
1. Seq2Seq 模型
1.1 Seq2Seq 简介
\(\text{Seq2Seq}\)(\(\text{Sequence to Sequence}\))通常由两部分构成:编码器(\(\text{Encoder}\)) 和 解码器(\(\text{Decoder}\))。
\(\text{Encoder}\) 和 \(\text{Decoder}\) 通常使用 循环神经网络 (\(\text{RNN}\)) 模型 例如长短期记忆 \(\text{LSTM}\) 或 门控制单元 \(\text{GRU}\) 等实现。
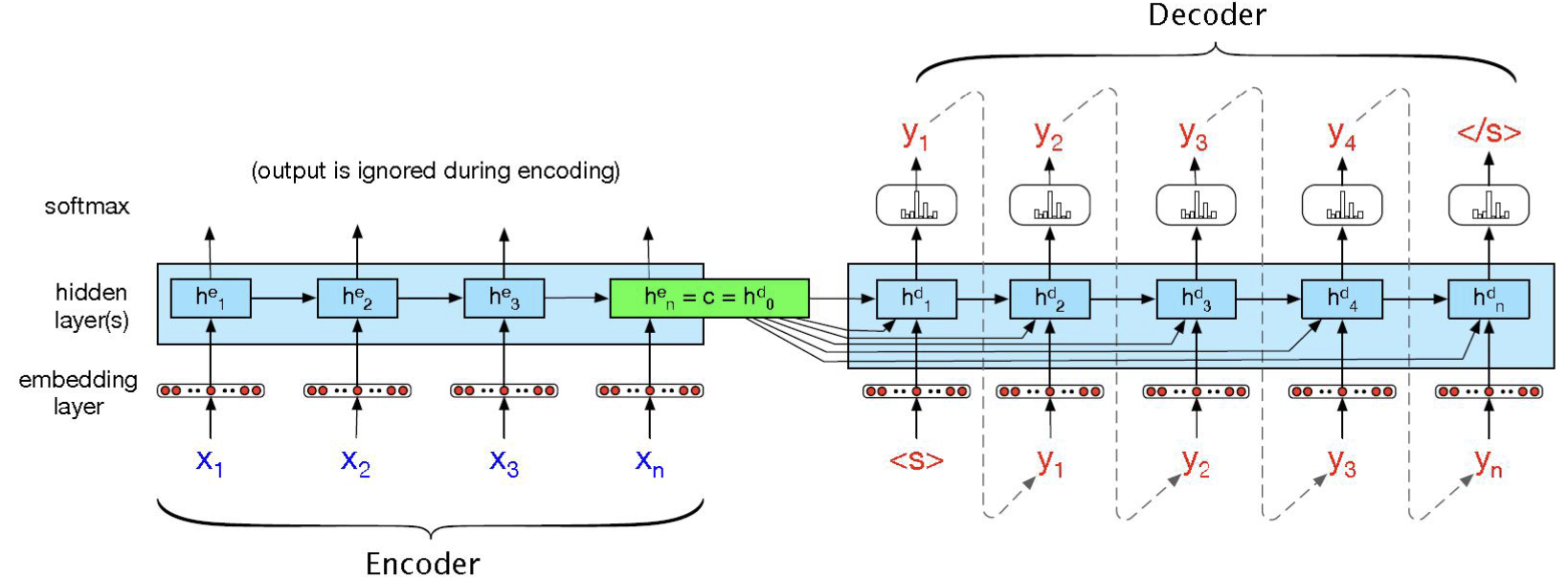
1.2 Seq2Seq 结构
-
\(\text{Encoder}\) 部分
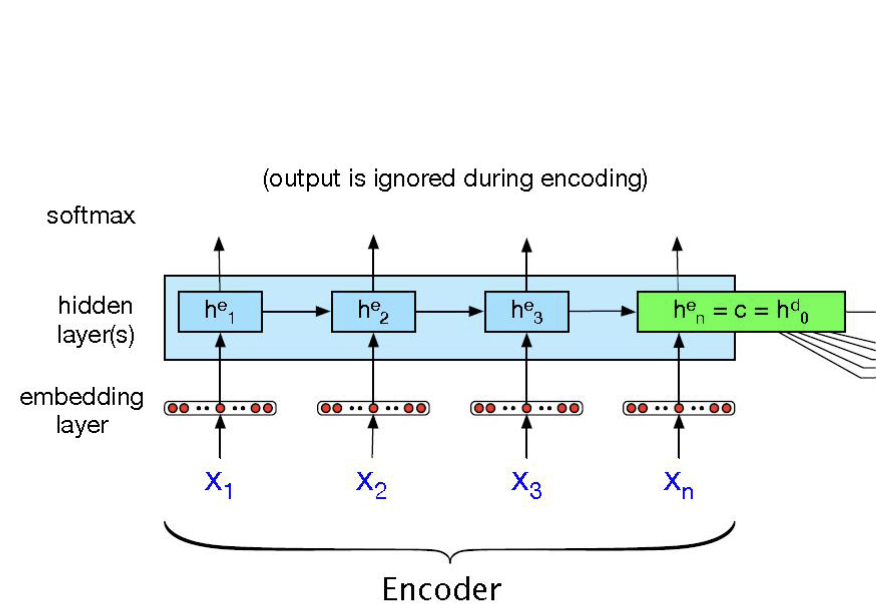
\(x\) 是输入的文本,经过 \(\text{embedding}\) 之后(词嵌入,通常采用的方法有 \(\text{Word2Vec、Glove}\) 等)。
编码器按照时间步骤顺序,将每个输入元素传入 \(\text{RNN}\) 模型,并更新其隐藏状态 \(h_t^e\)。RNN 状态更新过程
最后一步得到的隐藏状态 \(h_n^e\),作为我们的 上下文向量 \(c\),同时用作编码器的输出。上下文向量 \(c\) 被认为已经捕获了整个输入序列的所有重要信息,之后将被用于进一步的解码部分,同时作为 解码部分的输入 \(h^d_0\)。
编码器部分的输出通常被忽略掉。
-
\(\text{Decoder}\) 部分
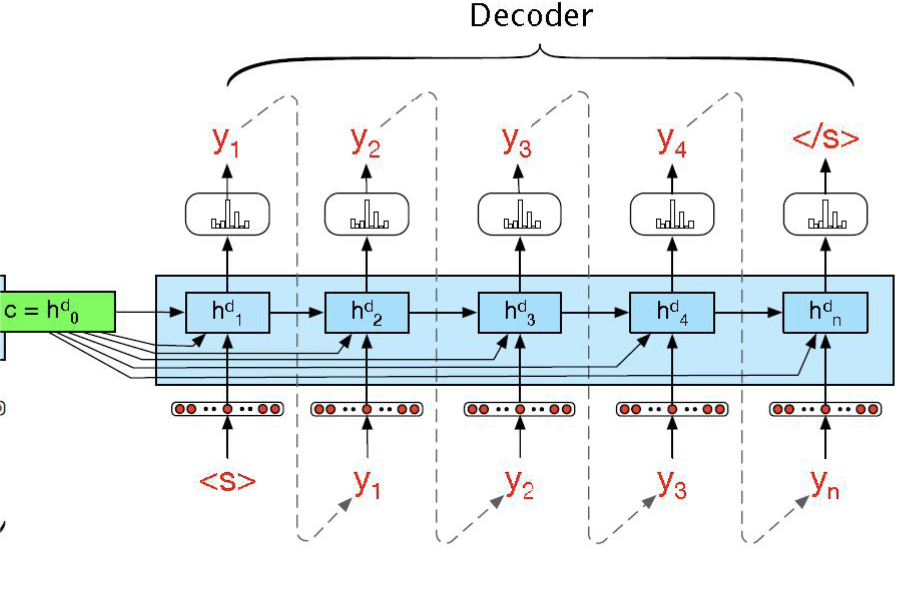
解码器的输入隐藏状态 \(h_0^d\) 通常被设置为编码器的上下文向量 \(c\)。
在训练过程中,当前隐藏状态 \(h_t^d\) 来源于 上一个时间点的隐藏状态 \(h_{t-1}^d\) 和 上下文向量 \(c\),并且通常还会将 上一个时间的输出 \(y_{t-1}\) 也作为 \(h_t^d\) 的一部分,故在编码器部分,有以下状态更新公式:
\[\begin{split} h_0^d &= c \\\\ h_t^d &= f(h^d_{t-1}, y_{t-1}, c) \\\\ z_t &= f^{'}(h_t^d) \\\\ y_t &= \text{softmax}(z_t) \end{split} \]其中 \(f\) 和 \(f^{'}\) 通常是某种激活函数。\(\hat y_t\) 表示的就是当前的输出预测。
1.3 Seq2Seq 模型训练
在此模型的 \(\text{Decoder}\) 部分中,对于时刻 \(t\) 的输出,其条件概率分布为:
其中 \(g\) 为 \(\text{softmax}\) 函数。(Softmax函数可以将上一层的原始数据进行归一化,数值范围为 \([0,1]\),故可以表示为一个概率。)
最后,编码器-解码器的两个组成部分联合训练,转换为一个最优化问题,即最大化条件对数似然概率:
1.4 Teacher Forcing
在 \(\text{Seq2Seq}\) 模型中,有时会采用 \(\text{Teacher Forcing}\),其基本思想是 直接使用实际序列(也就是训练数据的标准答案) 提供给下一个时刻的解码器的输入,而不使用上一时刻的输出结果。这对于模型的训练和收敛可能会更有利,可以将模型的训练速度加快。
2. Attention 注意力机制
2.1 Attention 简介
通俗地讲,\(\text{Attention}\) 机制 就是模型在处理序列数据时更加关注输入的一些比较重要的部分,并且忽视一些不太重要的部分。通过学习不同部分的权重,将输入的序列中的重要部分显式地加权,从而使得模型可以更好地关注与输出有关的信息。
一下是一些 \(\text{Attention}\) 机制的计算方式:

可以看到最后一个是 \(\text{Scaled Dot-Product Attention}\),这其实就是 \(\text{Transformer}\) 中的 \(\text{Self-Attention}\)。Transformer Self-Attention 自注意力机制
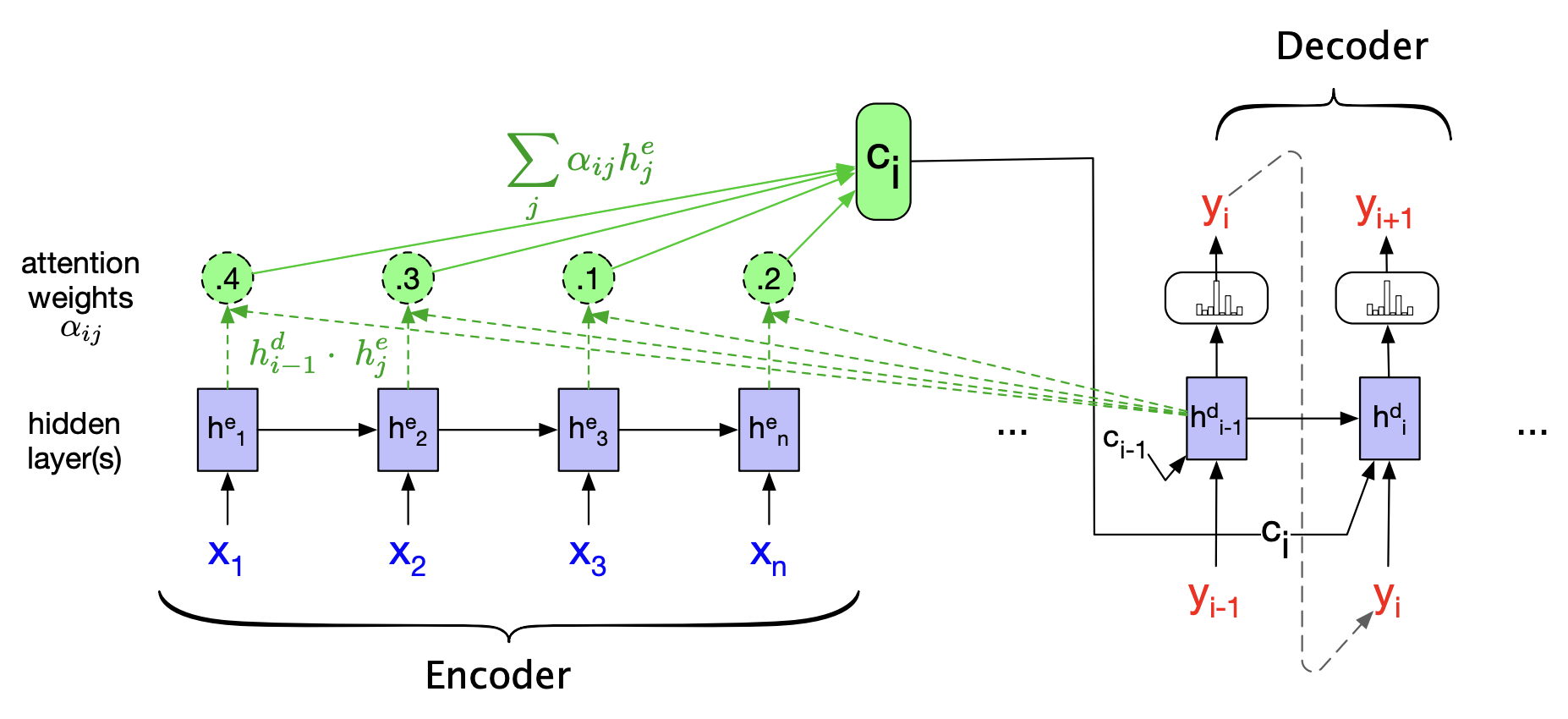
2.2 Seq2Seq 引入 Attention
\(\text{Seq2Seq}\) 是最早引入 \(\text{Attention}\) 机制的模型之一。其一般采用 点积注意力:
通常会再经过一个 \(\text{softmax}\) 函数进行归一化处理。由上述公式结合 \(\text{softmax}\) 可以得到每一个输入位置 \(h_j^e\) 对当前位置 \(i\) 的影响 \(\alpha_{ij}\):
得到一个权重向量,表示的就是对输入部分的注意力。
然后,利用 \(\alpha_{ij}\) 进行加权求和得到相应的 动态平均上下文向量 \(c_i\) :
表示前一个解码器隐藏状态与每一个编码器隐藏状态的相关性。
3. Beam Search 波束搜索
通常情况下,在序列生成模型中,我们往往会选取可能性最高的单词作为输出预测,这种方法其实也被称为 "贪心搜索"(\(\text{Greedy Search}\))。然而,这种方法由于每次选取局部最优,可能会导致全局不是最优的结果。
波束搜索(\(\text{Beam Search}\))是对贪心搜索的一种改进,其选择每一步最优的 \(K\) 个解作为输出预测。这里的 \(K\) 也被称为 波束宽度。
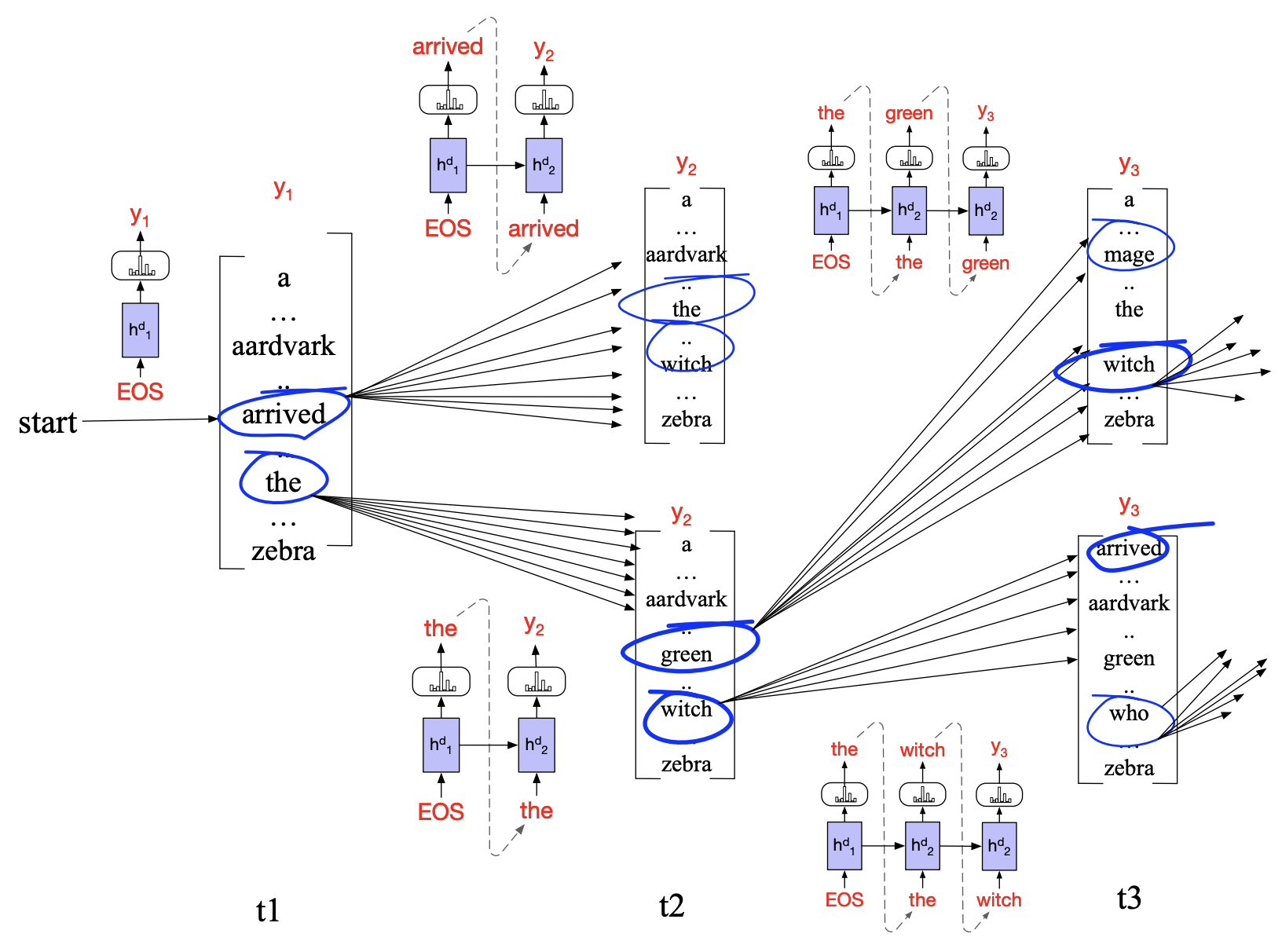
如上图所示,每一步选取概率前 \(K\) 高的单词,并且后续产生 \(K\times V\) 个假设(\(V\) 表示单词总数)来生成句子。
对于一个输出 \(y\),概率通常用 长度归一化 的 对数似然概率 进行估计:
长度归一化主要是为了应对出现对数概率相同但是输出序列长度不一样的情况。
在实际应用中,通常宽度 \(K\) 在 \([5, 10]\) 的区间内取值,而且每一步可以选取最优解,也可以选取任意 \(K\) 及以内的假设。
4. BLEU 评估指标
\(\text{BLEU}\)(\(\text{BiLingual Evaluation Understudy}\))是广泛使用的机器翻译评价指标,其计算方法是:统计机器译文与参考译文之间的 \(n\) 元文法(\(\text{N-gram}\))匹配的数目占机器译文中所有 \(n\) 元文法总数的比例。
具体公式如下:
其中,\(N\) 是考察的最长词序列长度(通常取 \(N=4\) ,记为\(\text{BLEU-4}\));
\(p_n = \frac{m_n}{h_n}\) 表示的第 \(n\) 元文法匹配的精确率(其中 \(m_n\) 是篇章中 正确匹配 的第 \(n\) 元文法数目,\(h_n\) 是篇章中机器译文第 \(n\) 元文法出现的总次数);
\(w_n\) 是第 \(n\) 元文法匹配的 权重(通常取值为 \(\frac{1}{N}\));
\(\text{BP}\) 是长度惩罚因子:
\(c\) 为 机器译文长度,\(r\) 为 参考译文长度。
在机器译文长度一定的情况下,匹配数目越多则代表该候选的译文质量越高。
参考
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
一文弄懂关于循环神经网络(RNN)的Teacher Forcing训练机制
一切都是命运石之门的选择,本文章来源于博客园,作者:MarisaMagic,出处:https://www.cnblogs.com/MarisaMagic/p/17968959,未经允许严禁转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号