[机器学习复习笔记] BGD, SGD, MBGD
BGD, SGD, MBGD
1. BGD 批量梯度下降法(Batch Gradient Descent)
1.1 批量梯度下降法介绍
在 梯度下降法 每次迭代中,将 所有样本 用来进行参数 \(\theta\) (梯度)的更新,这其实就是 批量梯度下降法。
批量梯度下降法 的 损失函数表达式:
参数更新 表达式:
1.2 BGD 的优缺点
优点:
-
在训练过程中,使用固定的学习率,不必担心学习率衰退现象的出现。
-
由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,一定能收敛到全局最小值,如果目标函数非凸则收敛到局部最小值。
-
它对梯度的估计是 无偏 的。样例越多,标准差越低。
-
一次迭代是对所有样本进行计算,此时利用向量化进行操作,实现了并行。
缺点:
-
遍历全部样本仍需要 大量时间,尤其是当数据集很大时(几百万甚至上亿)。
-
遍历全部样例,有时一些样本可能是多余的,对参数更新没有太大的作用。
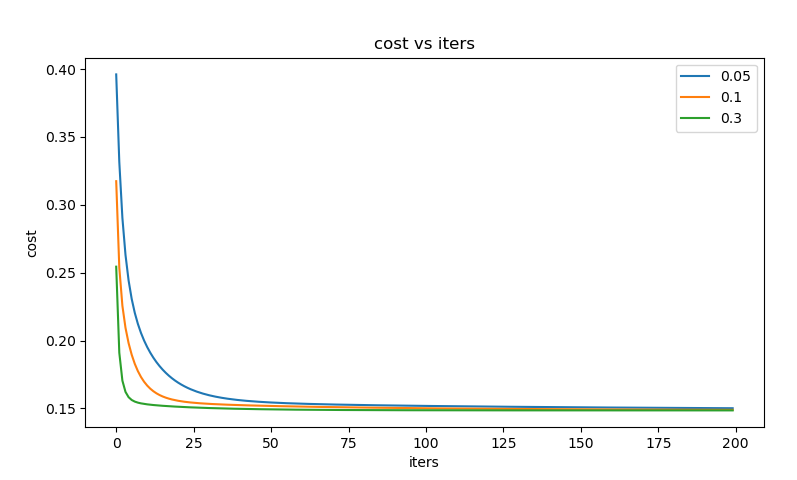
2. SGD 随机梯度下降法(Stochastic Gradient Descent)
2.1 随机梯度下降法介绍
随机梯度下降法 不同于批量梯度下降,在每次迭代时 只使用一个样本 来对参数进行更新(mini-batch size = 1)
随机梯度下降法 的 损失函数 表达式:
参数更新 表达式:
2.2 SGD 的优缺点
优点:
-
在学习过程中加入了噪声,提高了泛化误差。
-
随机优化某一条训练数据上的损失函数,这样每一轮参数的 更新速度大大加快。
缺点:
-
最终的结果是 不收敛的,在最小值附近波动。
-
由于每次只选取一个样本,学习过程会非常慢。
-
单个样本并不能代表全体样本的趋势,最后的效果很有可能不理想。
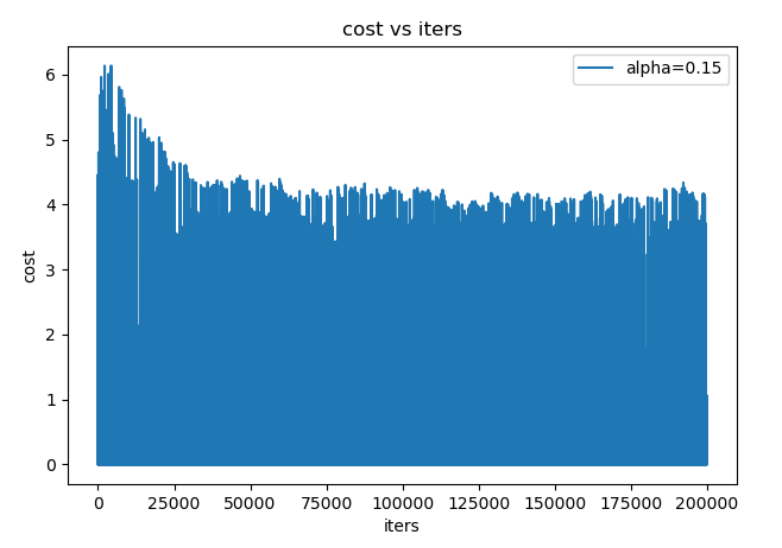
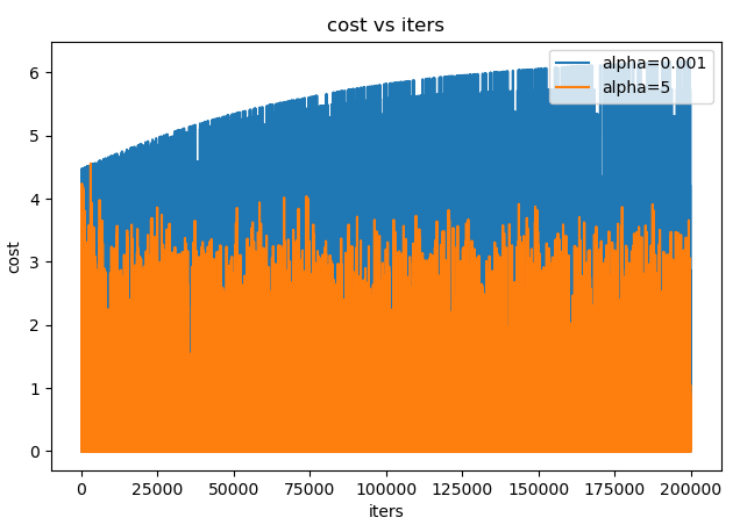
3. MBGD 随机梯度下降法(Mini-batch Gradient Descent)
3.1 小批量梯度下降法介绍
使用 一个以上而又不是全部的样本 进行训练,被称为 小批量(mini-batch) 或 小批量随机(mini-batch stochastic) 方法。
每一步,从 \(n\) 个样本的训练集(已经打乱样本的顺序)中随机抽出一小批量(mini-batch)样本 \(X = \{x^{(1)}, \cdots , x^{(m^{'})}\}\),\(m^{'}\) 为小批量大小。
随机梯度下降法 的 损失函数 表达式:
参数更新 表达式:
3.2 MBGD 的优缺点
优点
-
计算速度比BGD 快,只遍历部分样例就可执行更新。
-
随机选择样例有利于避免重复多余的样例和对参数更新较少贡献的样例。
-
每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
缺点
-
在迭代的过程中,因为噪音的存在,学习过程会出现波动。因此,它在最小值的区域徘徊,不会收敛。
-
学习过程会有 更多的振荡,为更接近最小值,往往 需要增加学习率衰减项,以降低学习率,避免过度振荡。
-
batch_size的 不当选择 可能会带来一些问题。
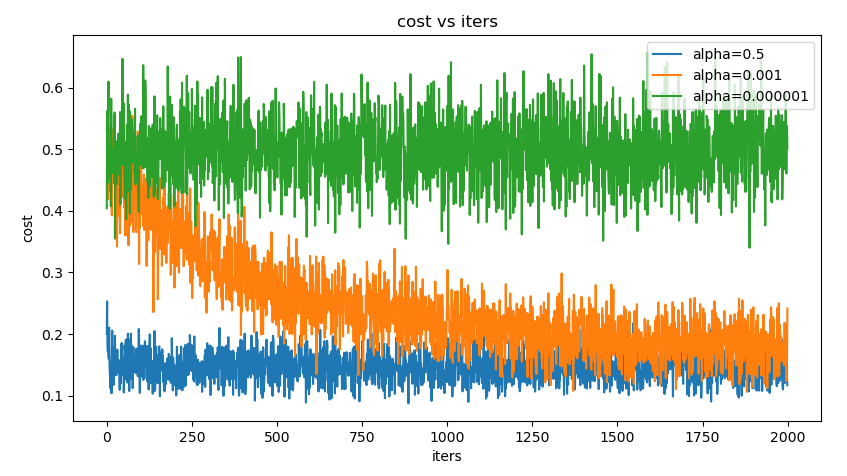
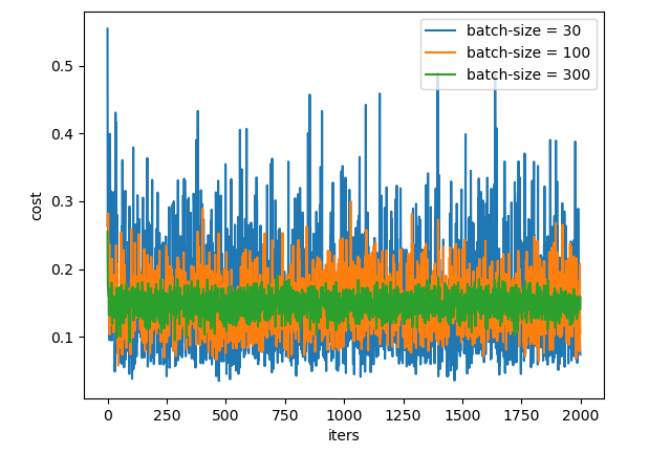
3.3 mini-batch size 的取值
小批量大小(mini-batch size)通常由以下几个因素决定:
-
更大的批量会计算更精确的梯度,但是回报却是小于线性的。
-
极小的批量通常难以充分利用多核结构。当批量低于某个数值时,计算时间不会减少。
-
批量处理中的所有样本可以并行处理,内存消耗和批量大小会成正比。对于很多硬件设备,这是批量大小的限制因素。
-
在使用GPU时,通常使用 2的幂数 作为批量大小可以获得 更少的运行时间。一般,2的幂数取值范围是 32~256。16 有时在尝试大模型时使用。
参考文章
一切都是命运石之门的选择,本文章来源于博客园,作者:MarisaMagic,出处:https://www.cnblogs.com/MarisaMagic/p/17818527.html,未经允许严禁转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号