
数据挖掘领域十大经典算法
目录
一、C4.5算法
【参考视频】( https://www.youtube.com/watch?v=A_YIP2e8xfM )
1.简介:
-
决策树算法(分类算法)一种,将P维特征的n个样本分到c个类别中去。
-
![]()
-
常见的决策树算法有ID3(用信息增益),C4.5(用信息增益率),CART(用gini系数)

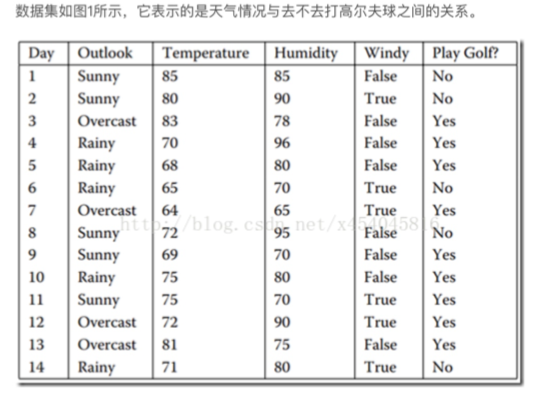
2.天气情况与去不去打高尔夫之间的关系:
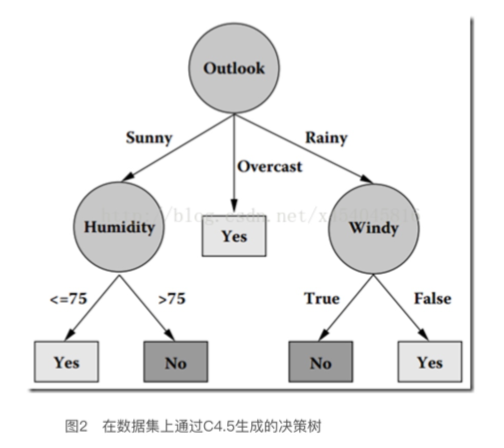
3.算法描述:
-
![]()
-
通过属性选择度量来判断优先选择优先对哪个属性进行判断

4.属性选择度量(分裂规则)
- 决定给定节点上的元组如何分裂;
- 提供了每个属性描述给定训练元组的秩评定,具有最好的度量得分的属性被选作给定元组的分裂属性
- 目前比较流行的属性选择度量-信息增益、增益率、gini指数
4.1 信息增益
- ID3算法中用来进行属性选择度量的
- 选择具有高信息增益的属性来作为节点N的分裂属性
- 该属性使结果划分中的元组分类所需信息量最小
- 对D中的元组分类所需期望信息为(期望:是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。 它反映随机变量平均取值的大小。)
![]()
- Info(D)又称之为 “熵”
![]()
- 熵越大,不确定性就越高;熵越小确定性就越大!
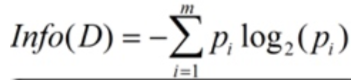

4.2 信息增益率


4.3 Gini指标

5.优缺点
- 优点:
- 产生的分类规则易于理解,准确率较高
- 缺点:
- 在构造树的过程中,需要对数据及进行多次的顺序扫描和排序,因而导致算法的低效
6.代码(参考地址:https://github.com/fuqiuai/lihang_algorithms/blob/master/decision_tree/C45.py)
- 测试数据集为MNIST数据集,获取地址:https://github.com/fuqiuai/lihang_algorithms/blob/master/data/train.csv
# encoding=utf-8
import cv2
import time
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
# 二值化
def binaryzation(img):
cv_img = img.astype(np.uint8)
cv2.threshold(cv_img,50,1,cv2.THRESH_BINARY_INV,cv_img)
return cv_img
def binaryzation_features(trainset):
features = []
for img in trainset:
img = np.reshape(img,(28,28))
cv_img = img.astype(np.uint8)
img_b = binaryzation(cv_img)
# hog_feature = np.transpose(hog_feature)
features.append(img_b)
features = np.array(features)
features = np.reshape(features,(-1,feature_len))
return features
class Tree(object):
def __init__(self,node_type,Class = None, feature = None):
self.node_type = node_type # 节点类型(internal或leaf)
self.dict = {} # dict的键表示特征Ag的可能值ai,值表示根据ai得到的子树
self.Class = Class # 叶节点表示的类,若是内部节点则为none
self.feature = feature # 表示当前的树即将由第feature个特征划分(即第feature特征是使得当前树中信息增益最大的特征)
def add_tree(self,key,tree):
self.dict[key] = tree
def predict(self,features):
if self.node_type == 'leaf' or (features[self.feature] not in self.dict):
return self.Class
tree = self.dict.get(features[self.feature])
return tree.predict(features)
# 计算数据集x的经验熵H(x)
def calc_ent(x):
x_value_list = set([x[i] for i in range(x.shape[0])])
ent = 0.0
for x_value in x_value_list:
p = float(x[x == x_value].shape[0]) / x.shape[0]
logp = np.log2(p)
ent -= p * logp
return ent
# 计算条件熵H(y/x)
def calc_condition_ent(x, y):
x_value_list = set([x[i] for i in range(x.shape[0])])
ent = 0.0
for x_value in x_value_list:
sub_y = y[x == x_value]
temp_ent = calc_ent(sub_y)
ent += (float(sub_y.shape[0]) / y.shape[0]) * temp_ent
return ent
# 计算信息增益
def calc_ent_grap(x,y):
base_ent = calc_ent(y)
condition_ent = calc_condition_ent(x, y)
ent_grap = base_ent - condition_ent
return ent_grap
# C4.5算法
def recurse_train(train_set,train_label,features):
LEAF = 'leaf'
INTERNAL = 'internal'
# 步骤1——如果训练集train_set中的所有实例都属于同一类Ck
label_set = set(train_label)
if len(label_set) == 1:
return Tree(LEAF,Class = label_set.pop())
# 步骤2——如果特征集features为空
class_len = [(i,len(list(filter(lambda x:x==i,train_label)))) for i in range(class_num)] # 计算每一个类出现的个数
(max_class,max_len) = max(class_len,key = lambda x:x[1])
if len(features) == 0:
return Tree(LEAF,Class = max_class)
# 步骤3——计算信息增益,并选择信息增益最大的特征
max_feature = 0
max_gda = 0
D = train_label
for feature in features:
# print(type(train_set))
A = np.array(train_set[:,feature].flat) # 选择训练集中的第feature列(即第feature个特征)
gda = calc_ent_grap(A,D)
if calc_ent(A) != 0: ####### 计算信息增益比,这是与ID3算法唯一的不同
gda /= calc_ent(A)
if gda > max_gda:
max_gda,max_feature = gda,feature
# 步骤4——信息增益小于阈值
if max_gda < epsilon:
return Tree(LEAF,Class = max_class)
# 步骤5——构建非空子集
sub_features = list(filter(lambda x:x!=max_feature,features))
tree = Tree(INTERNAL,feature=max_feature)
max_feature_col = np.array(train_set[:,max_feature].flat)
feature_value_list = set([max_feature_col[i] for i in range(max_feature_col.shape[0])]) # 保存信息增益最大的特征可能的取值 (shape[0]表示计算行数)
for feature_value in feature_value_list:
index = []
for i in range(len(train_label)):
if train_set[i][max_feature] == feature_value:
index.append(i)
sub_train_set = train_set[index]
sub_train_label = train_label[index]
sub_tree = recurse_train(sub_train_set,sub_train_label,sub_features)
tree.add_tree(feature_value,sub_tree)
return tree
def train(train_set,train_label,features):
return recurse_train(train_set,train_label,features)
def predict(test_set,tree):
result = []
for features in test_set:
tmp_predict = tree.predict(features)
result.append(tmp_predict)
return np.array(result)
class_num = 10 # MINST数据集有10种labels,分别是“0,1,2,3,4,5,6,7,8,9”
feature_len = 784 # MINST数据集每个image有28*28=784个特征(pixels)
epsilon = 0.001 # 设定阈值
if __name__ == '__main__':
print("Start read data...")
time_1 = time.time()
raw_data = pd.read_csv('../data/train.csv', header=0) # 读取csv数据
data = raw_data.values
imgs = data[::, 1::]
features = binaryzation_features(imgs) # 图片二值化(很重要,不然预测准确率很低)
labels = data[::, 0]
# 避免过拟合,采用交叉验证,随机选取33%数据作为测试集,剩余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
time_2 = time.time()
print('read data cost %f seconds' % (time_2 - time_1))
# 通过C4.5算法生成决策树
print('Start training...')
tree = train(train_features,train_labels,list(range(feature_len)))
time_3 = time.time()
print('training cost %f seconds' % (time_3 - time_2))
print('Start predicting...')
test_predict = predict(test_features,tree)
time_4 = time.time()
print('predicting cost %f seconds' % (time_4 - time_3))
# print("预测的结果为:")
# print(test_predict)
for i in range(len(test_predict)):
if test_predict[i] == None:
test_predict[i] = epsilon
score = accuracy_score(test_labels, test_predict)
print("The accruacy score is %f" % score)
ID3 算法(多数选取分支最大的属性作为优先考虑点)

C4.5算法(增加信息增益率,优化)

二、K-Means算法
1.简介
- K-均值算法,是非监督学习中的聚类算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号