

05 RDD编程
一、词频统计
1.读文本文件生成RDD lines
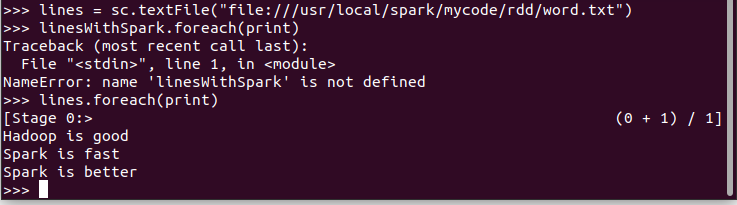
2.将一行一行的文本分割成单词 words flatmap()
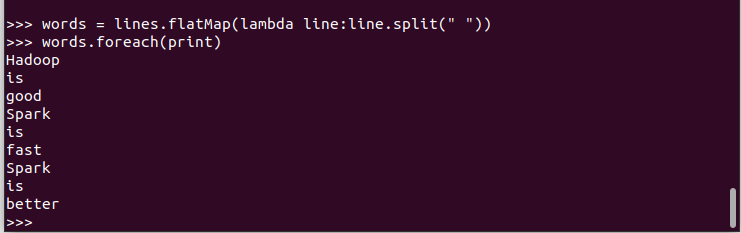
3.全部转换为小写 lower()

4.去掉长度小于3的单词 filter()

5.去掉停用词

6.转换成键值对 map()
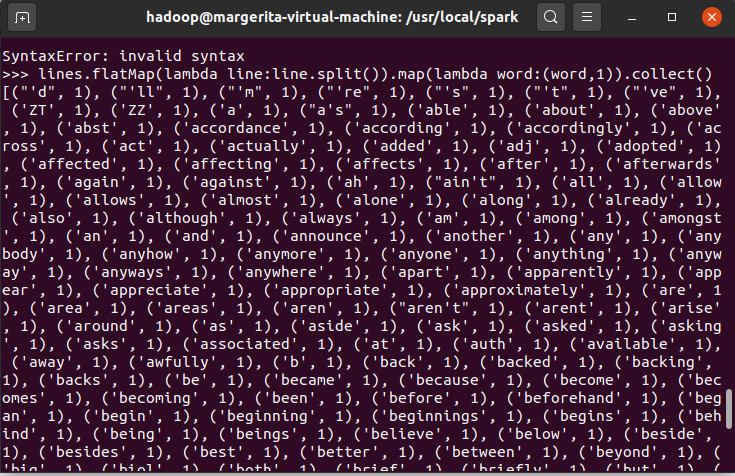
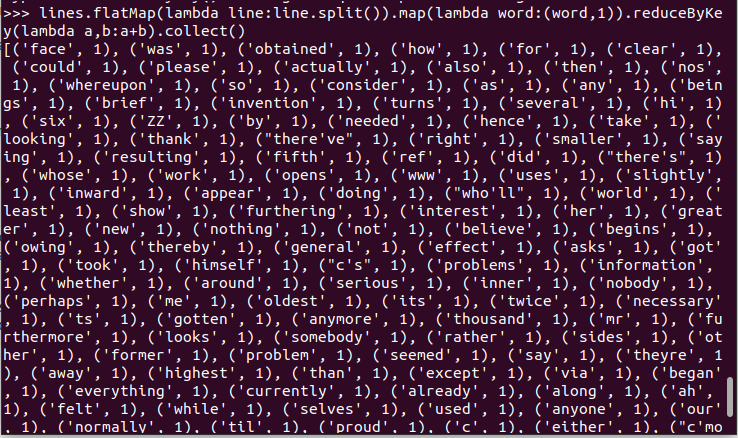
7.统计词频 reduceByKey()
8.按字母顺序排序 sortBy(f)

9.按词频排序 sortByKey()

10.结果文件保存 saveAsTextFile(out_url)

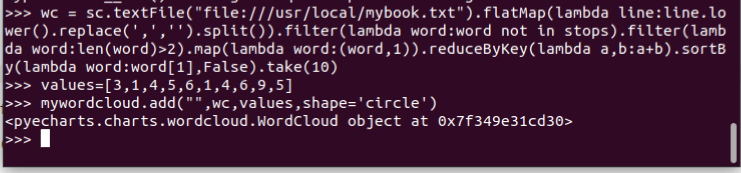
11.词频结果可视化charts.WordCloud() (调用render()没有反应)
12.比较不同框架下(Python、MapReduce、Hive和Spark),实现词频统计思想与技术上的不同,各有什么优缺点.
Python实现词频统计通过代码,就是自定义循环列表读取文件。
MapReduce通过提交任务的方法来完成。
Hive通过自己的HQL语言实现
Spark可以使用多种语言实现
综上,Map和Reduce两种操作,编写好的代码要打包运行,不能通过shell进行交互式处理,如果程序改动需要重新打成jar包。Hive的HQL表达能力有限迭代式算法无法表达,调优比较困难,可控性差。而Spark更快,容易使用,通用性高。
二、学生课程案例分析
1.总共有多少学生?map(), distinct(), count()

2.开设了多少门课程?

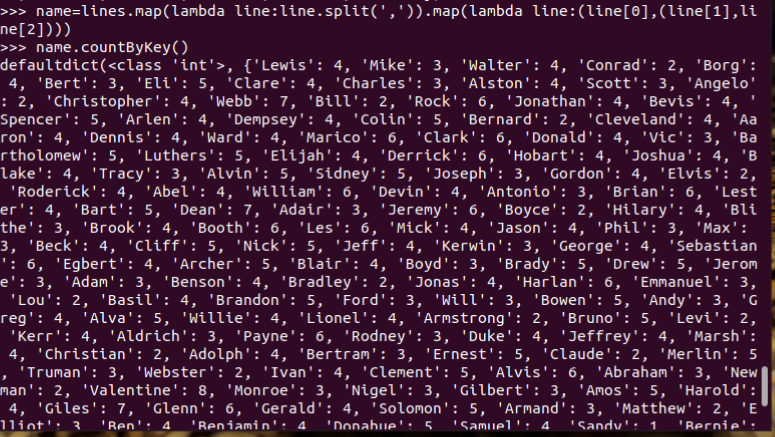
3.每个学生选修了多少门课?map(), countByKey()
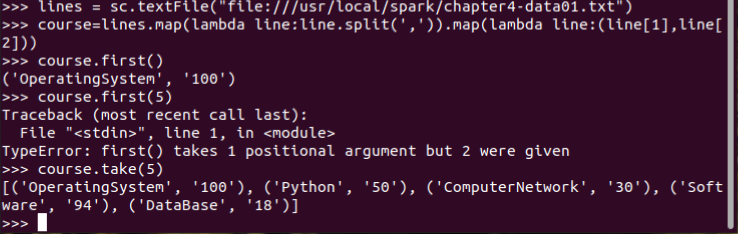
4.每门课程有多少个学生选?map(), countByValue()

5.Henry选修了几门课?每门课多少分?filter(), map() RDD

6.Henry选修了几门课?每门课多少分?map(),lookup() list

7.Henry的成绩按分数大小排序。filter(), map(), sortBy()

8.Henry的平均分。map(),lookup(),mean()

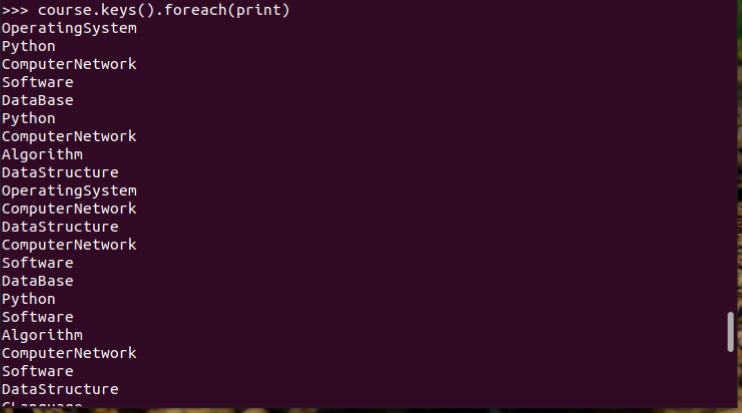
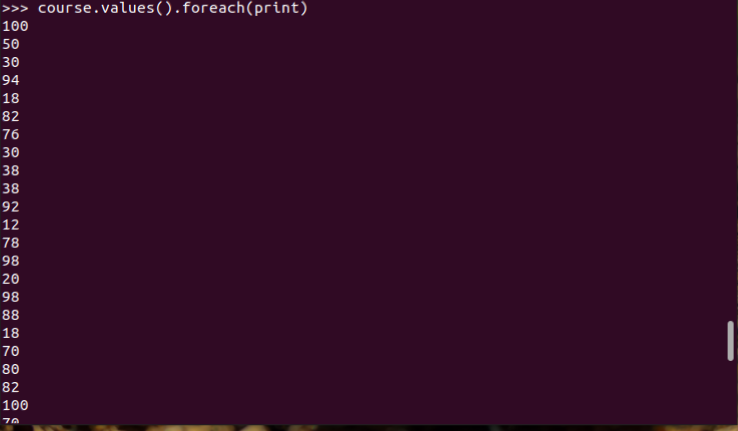
9.生成(课程,分数)RDD,观察keys(),values()
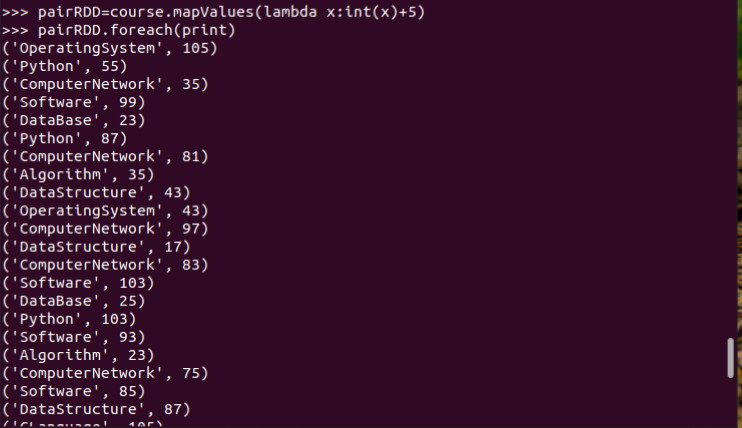
10.每个分数+5分。mapValues(func)
11.求每门课的选修人数及所有人的总分。combineByKey()

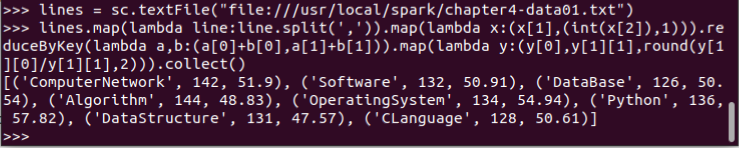
12.求每门课的选修人数及平均分,精确到2位小数。map(),round()

13.求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。
14.结果可视化。charts,Bar() course.keys()对上course.keys()是可以运行的,course.keys()对上course.values()或者course.map(lambda x:x[x]).collect()就会出现断言错误,*len(x_axis)=len(y_axis)*


