

python之有参装饰器和迭代器用法
1.有参装饰器:是无参装饰器的加强版
在无参装饰器上面再包个函数(相当于多增加一个值)
无参装饰器函例图:
def check(func): # index()运行的先运行@check=check(index)把index内存地址赋值给func 得到check_user内存地址返回值并赋值新的index变量名
def check_user(*args, **kwargs):
while True:
user_info = input("请输入用户名:").strip()
pwd_info = input('请输入密码:').strip()
if user_info == name and pwd_info == pwd:
print("loging successfull")
else:
print('用户名和密码错误')
continue
res = func(*args, **kwargs)
return res
return check_user
@check
def index(): # 运行@check(index) func内存地址=index赋值 返回check_user内存地址 在重新赋值一个新的index=check_info实际上内存地址已经更换了
# 最后直接调用index()指向的是check_info()的内存地址
print('welcome to index')
time.sleep(2)
return 123
import time
current_user={'user':None}
def deco(func):
def wrapper(*args,**kwargs):
if current_user['user']:
#已经登陆过
res = func(*args, **kwargs)
return res
user=input('username>>: ').strip()
pwd=input('password>>: ').strip()
if user == 'egon' and pwd == '123':
print('login successful')
# 记录用户登陆状态
current_user['user']=user
res=func(*args,**kwargs)
return res
else:
print('user or password error')
return wrapper
@deco
def index():
print('welcome to index page')
time.sleep(1)
@deco
def home(name):
print('welecome %s to home page' %name)
time.sleep(0.5)
index()
home('egon')
'''
有参可以增加认证来源的判断,根据传入的参数进行多种分类比如如下多种登录认证
import time
current_user={'user':None}
def auth(engine='file'):
def deco(func):
def wrapper(*args,**kwargs):
if current_user['user']:
#已经登陆过
res = func(*args, **kwargs)
return res
user=input('username>>: ').strip()
pwd=input('password>>: ').strip()
if engine == 'file':
# 基于文件的认证
if user == 'egon' and pwd == '123':
print('login successful')
# 记录用户登陆状态
current_user['user']=user
res=func(*args,**kwargs)
return res
else:
print('user or password error')
elif engine == 'mysql':
print('基于mysql的认证')
elif engine == 'ldap':
print('基于ldap的认证')
else:
print('无法识别认证来源')
return wrapper
return deco
@auth(engine='mysql') # @deco #index=deco(index) #index=wrapper
def index():
print('welcome to index page')
time.sleep(1)
@auth(engine='mysql')
def home(name):
print('welecome %s to home page' %name)
time.sleep(0.5)
index()
2.什么是迭代器
1.迭代器即迭代取值的工具
2.迭代就是一个重复的过程,每一次都要重复是基于上次的结果而来
单纯的重复并不是迭代
迭代:
l=['a','b','c']
def iterator(item):
i=0
while i <len(itme):
print(l[i])
i+=1
2.为什么要有迭代器
基于索引的迭代器取值方式只适用于列表、元组、字符串
对于没有索引的字典、集合、文件、则不适合
所以必须找到一种通用的并且不依赖索引的迭代器取值方式=》迭代器
迭代器适用于可迭代的类型
3.如何用迭代器
s='hello'
def iterator(item):
i=0
while i <len(item):
print (item[i])
i+=1
iterator(s)
可迭代对象:在python中但凡内置有—iter—方法的对象都是可迭代对象
(字符串,列表,元组,字典,集合,文件都是可迭代的对象)
迭代器对象=可迭代的对象——iter——()
迭代器对象:即内置有——iter——方法,有内置有—next——方法的对象
迭代器对象本身=迭代器对象——iter——()
拿到的是下一个值=迭代器对象——next——()
##执行可迭代对象的——iter——方法得到的就是内置的迭代器对象
###文件对象本身就是迭代器对象
强调:
迭代器对象一定是可迭代的对象,反之则不让
一旦迭代器取取值干净,在继续取就会抛出stopiteration
迭代器对象:指的是既内置有——iter——方法,又内置有——next——方法的对象
执行迭代器对象的——next——得到的是迭代器下一个值
执行迭代器对象的——iter——得到的仍然是迭代器本身
实例:

for循环:迭代器循环
info={‘name’:'egon','agon':18}
#in后面跟的一定要是可迭代的对象
for k in info: #info_iter=info._iter_() for循环底层原理就是用迭代器方式定义 (检测运行完毕后自动结束)
print(k)
while循环需要定义一个检测机制,运行完毕后才不会报错

总结迭代器对象的优缺点:
指的是既内置有——iter方法:
优点:提供一种通用的、可以不依赖索引的迭代取值方式
2.迭代器对象更加节省内存 (比如读取大文件时候,读一行就取一行)

缺点:
1.迭代器的取值不按照索引的方式更灵活,因为他只能往后不能往前退
2.无法预测迭代器值的个数
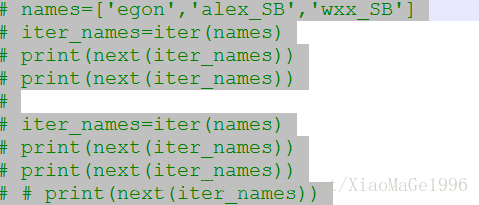
比如:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号