
https://blog.csdn.net/m0_37605642/article/details/98358864
参考博客
目标定位和检测系列(3):交并比(IOU)和非极大值抑制(NMS)的python实现
一、NMS(非极大抑制)概念
NMS即non maximum suppression即非极大抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值。在最近几年常见的物体检测算法(包括rcnn、sppnet、fast-rcnn、faster-rcnn等)中,最终都会从一张图片中找出很多个可能是物体的矩形框,然后为每个矩形框为做类别分类概率。

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
所谓非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A<B<C<D<E<F。
(1) 从最大概率矩形框F开始,分别判断A、B、C、D、E与F的重叠度IOU是否大于某个设定的阈值;
(2) 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3) 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
(4) 重复这个过程,找到所有被保留下来的矩形框。
二、YOLO中的NMS
参考文章 目标检测算法之YOLO
对于每一个种类的概率,比如Dog,我们将所有98个框按照预测概率从高到低排序(为方便计算,排序前可以剔除极小概率的框,也就是把它们的概率置为0),然后通过非极大抑制NMS方法,继续剔除多余的框:
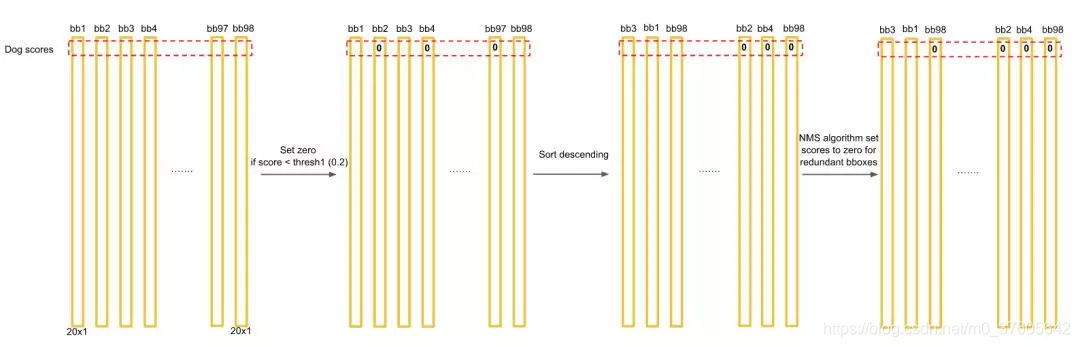
NMS方法在这里如何运行呢?首先因为经过了排序,所以第一个框是概率最大的框(下图橘色)。然后继续扫描下一个框跟第一个框,看是否IOU大于0.5:
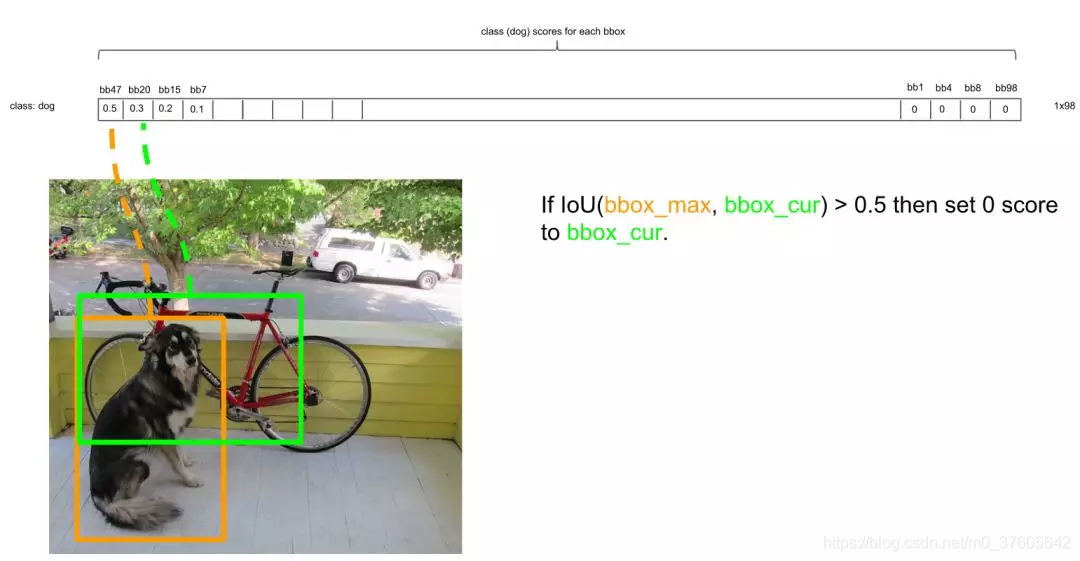
的确IOU大于0.5,那么第二个框是多余的,将它剔除:
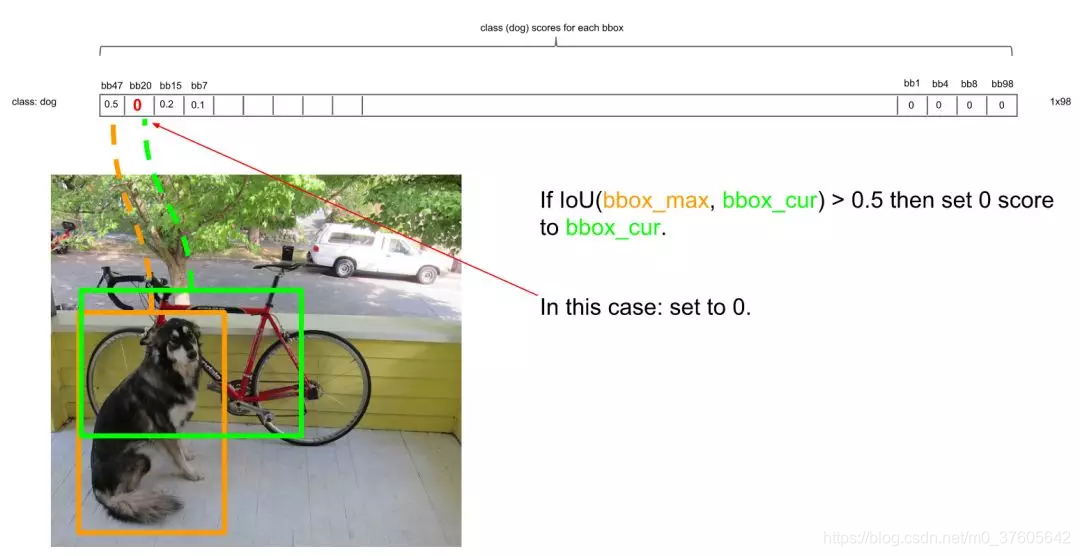
继续扫描到第三个框,它与最大概率框的IOU小于0.5,需要保留:
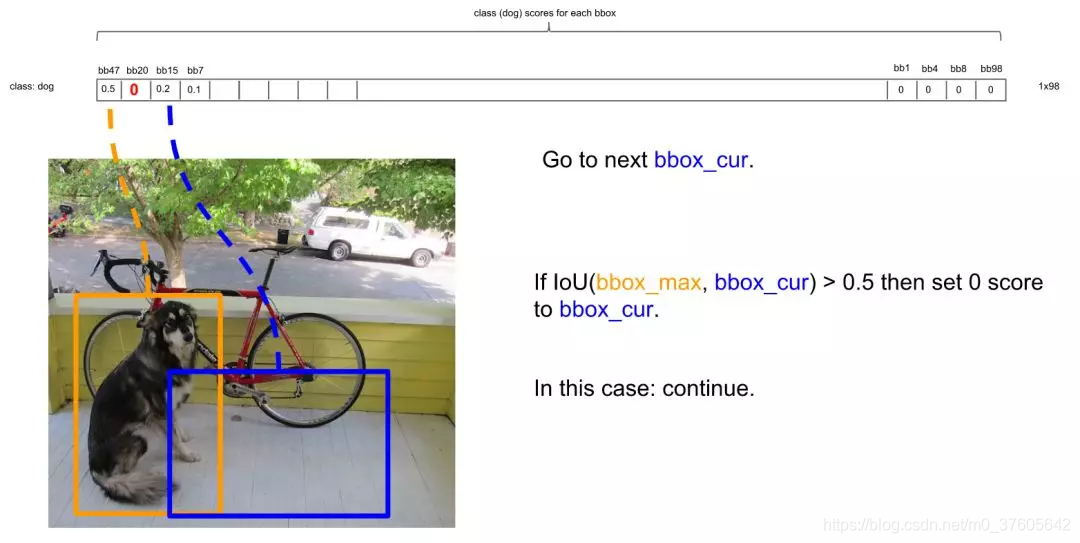
继续扫描到第四个框,同理需要保留:
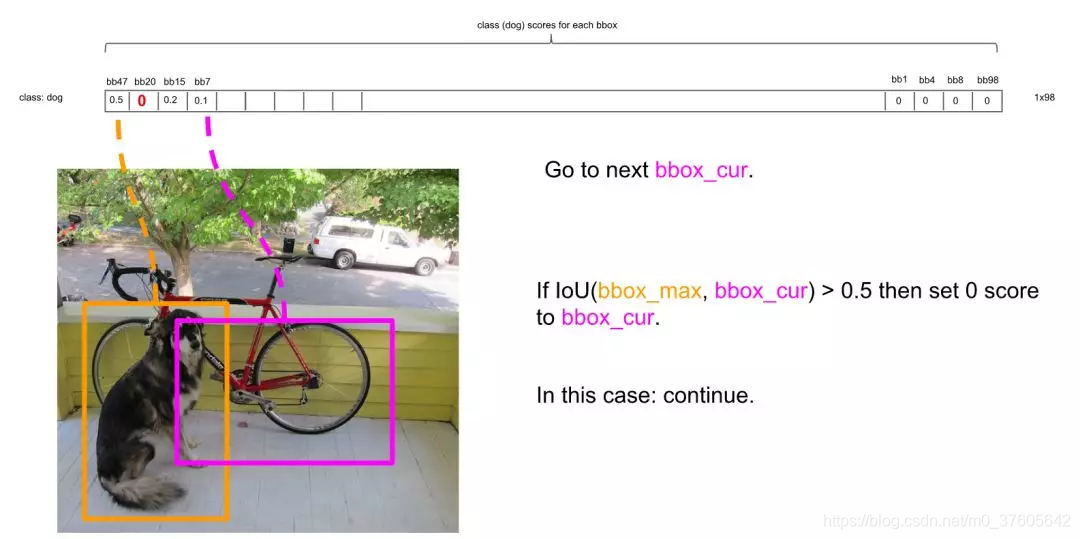
继续扫描后面的框,直到所有框都与第一个框比较完毕。此时保留了不少框。
接下来,以次大概率的框(因为一开始排序过,它在顺序上也一定是保留框中最靠近上一轮的基础框的)为基础,将它后面的其它框于之比较。
如比较第4个框与之的IOU:
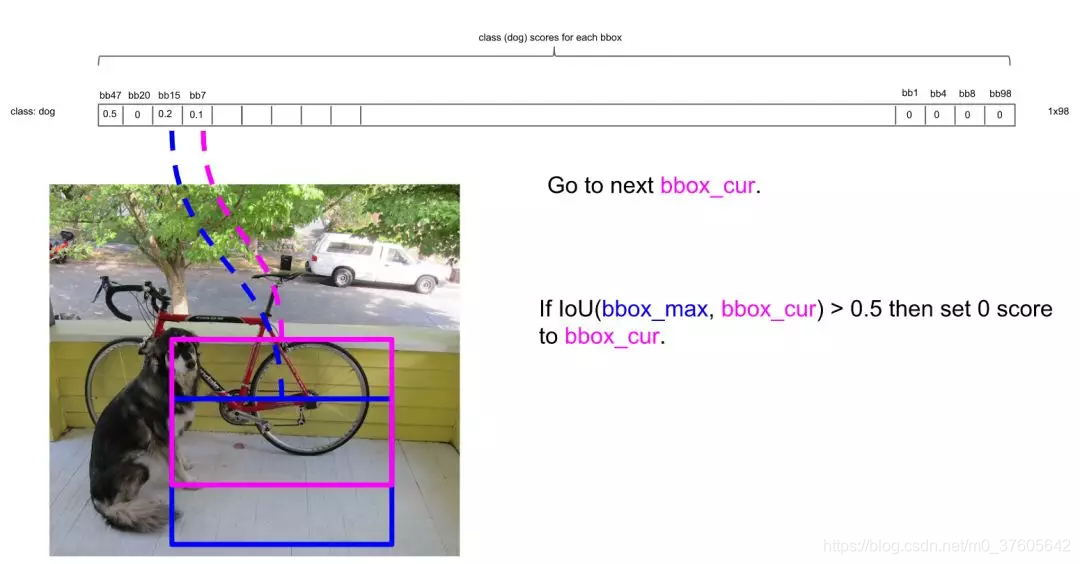
IOU大于0.5,所以可以剔除第4个框:
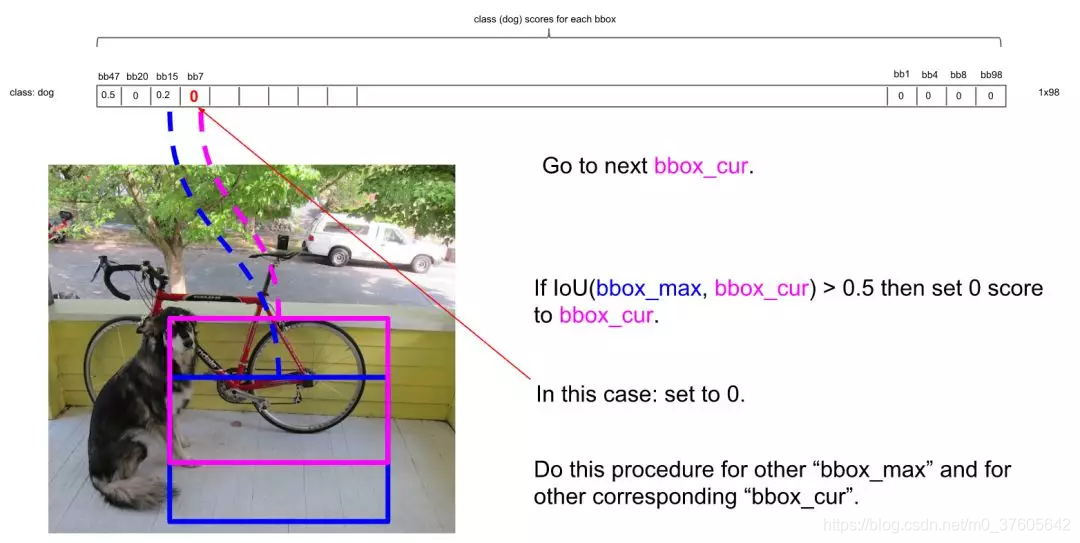
总之在经历了所有的扫描之后,对Dog类别只留下了两个框:
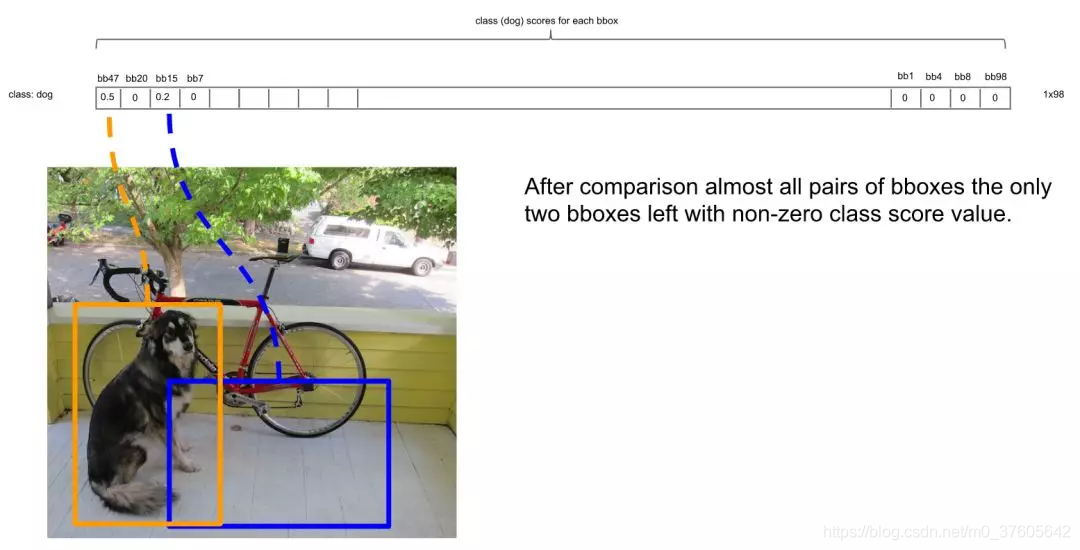
这时候,或许会有疑问:明显留下来的蓝色框,并非Dog,为什么要留下?因为对计算机来说,图片可能出现两只Dog,保留概率不为0的框是安全的。不过的确后续设置了一定的阈值(比如0.3)来删除掉概率太低的框,这里的蓝色框在最后并没有保留,因为它在20种类别里要么因为IOU不够而被删除,要么因为最后阈值不够而被剔除。
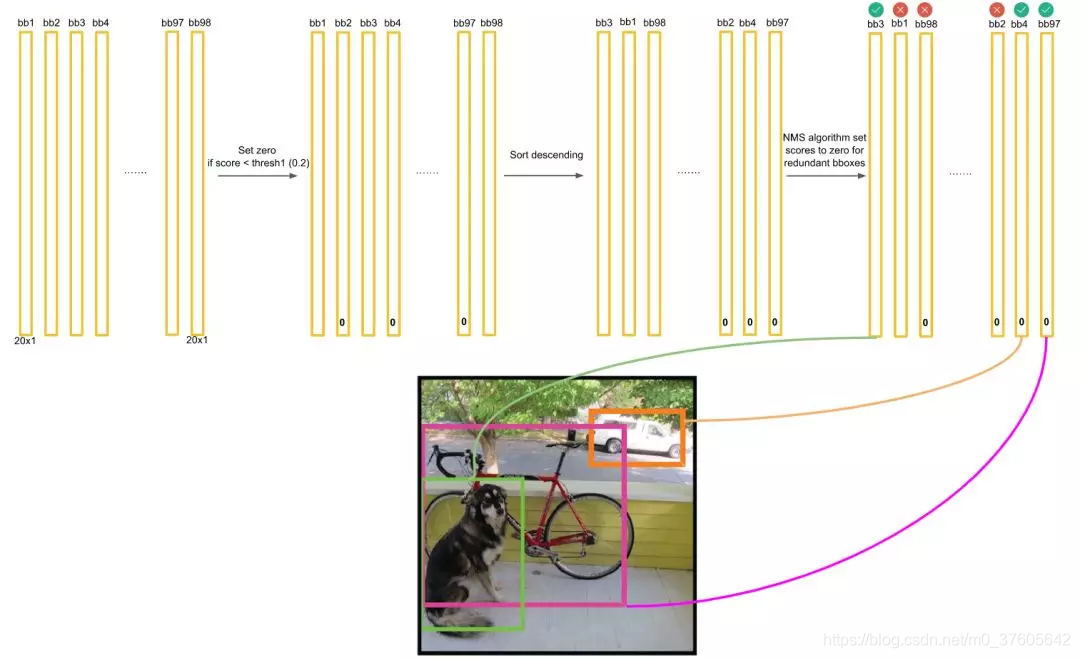
上面描述了对Dog种类进行的框选择。接下来,我们还要对其它19种类别分别进行上面的操作。最后进行纵向跨类的比较(为什么?因为上面就算保留了橘色框为最大概率的Dog框,但该框可能在Cat的类别也为概率最大且比Dog的概率更大,那么我们最终要判断该框为Cat而不是Dog)。判定流程和法则如下:
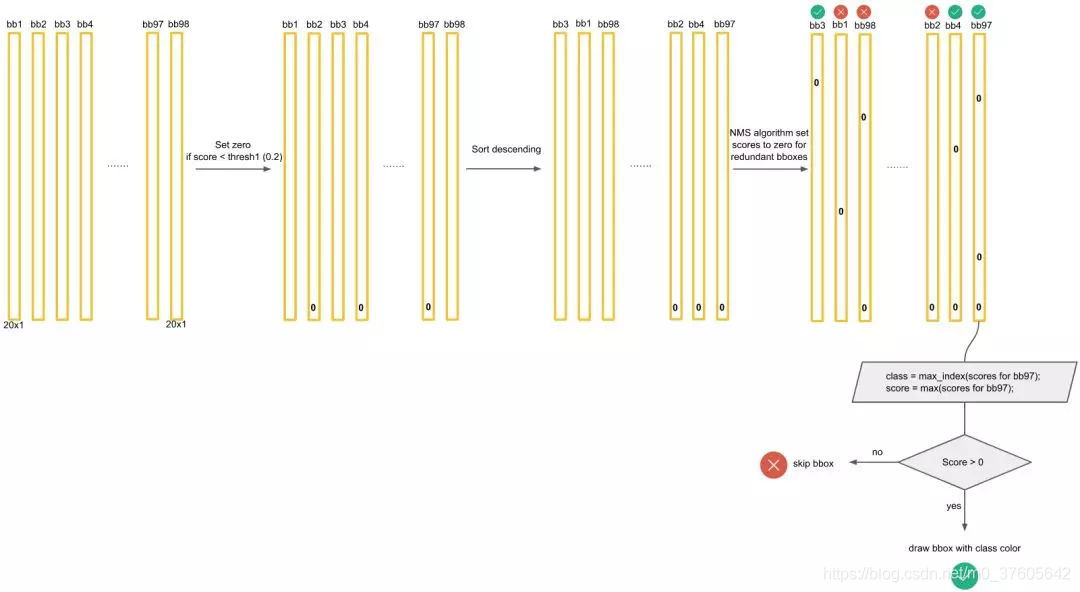
得到最后的结果:
三、Python程序实现NMS
NMS的算法步骤如下:
# INPUT:所有预测出的bounding box (bbx)信息(坐标和置信度confidence), IOU阈值(大于该阈值的bbx将被移除) for object in all objects: (1) 获取当前目标类别下所有bbx的信息 (2) 将bbx按照confidence从高到低排序,并记录当前confidence最大的bbx (3) 计算最大confidence对应的bbx与剩下所有的bbx的IOU,移除所有大于IOU阈值的bbx (4) 对剩下的bbx,循环执行(2)和(3)直到所有的bbx均满足要求(即不能再移除bbx)
需要注意的是,NMS是对所有的类别分别执行的。举个栗子,假设最后预测出的矩形框有2类(分别为cup, pen),在NMS之前,每个类别可能都会有不只一个bbx被预测出来,这个时候我们需要对这两个类别分别执行一次NMS过程。
我们用python编写NMS代码,假设对于一张图片,所有的bbx信息已经保存在一个字典中,保存形式如下:
predicts_dict: {"cup": [[x1_1, y1_1, x2_1, y2_1, scores1], [x1_2, y1_2, x2_2, y2_2, scores2], ...], "pen": [[x1_1, y1_1, x2_1, y2_1, scores1], [x1_2, y1_2, x2_2, y2_2, scores2], ...]}
即目标的位置和置信度用列表储存,每个列表中的一个子列表代表一个bbx信息。详细的代码如下:
import numpy as np def non_max_suppress(predicts_dict, threshold=0.2): """ implement non-maximum supression on predict bounding boxes. Args: predicts_dict: {"stick": [[x1, y1, x2, y2, scores1], [...]]}. threshhold: iou threshold Return: predicts_dict processed by non-maximum suppression """ for object_name, bbox in predicts_dict.items(): #对每一个类别的目标分别进行NMS bbox_array = np.array(bbox, dtype=np.float) ## 获取当前目标类别下所有矩形框(bounding box,下面简称bbx)的坐标和confidence,并计算所有bbx的面积 x1, y1, x2, y2, scores = bbox_array[:,0], bbox_array[:,1], bbox_array[:,2], bbox_array[:,3], bbox_array[:,4] areas = (x2-x1+1) * (y2-y1+1) #print("areas shape = ", areas.shape) ## 对当前类别下所有的bbx的confidence进行从高到低排序(order保存索引信息) order = scores.argsort()[::-1] print("order = ", order) keep = [] #用来存放最终保留的bbx的索引信息 ## 依次从按confidence从高到低遍历bbx,移除所有与该矩形框的IOU值大于threshold的矩形框 while order.size > 0: i = order[0] keep.append(i) #保留当前最大confidence对应的bbx索引 ## 获取所有与当前bbx的交集对应的左上角和右下角坐标,并计算IOU(注意这里是同时计算一个bbx与其他所有bbx的IOU) xx1 = np.maximum(x1[i], x1[order[1:]]) #当order.size=1时,下面的计算结果都为np.array([]),不影响最终结果 yy1 = np.maximum(y1[i], y1[order[1:]]) xx2 = np.minimum(x2[i], x2[order[1:]]) yy2 = np.minimum(y2[i], y2[order[1:]]) inter = np.maximum(0.0, xx2-xx1+1) * np.maximum(0.0, yy2-yy1+1) iou = inter/(areas[i]+areas[order[1:]]-inter) print("iou =", iou) print(np.where(iou<=threshold)) #输出没有被移除的bbx索引(相对于iou向量的索引) indexs = np.where(iou<=threshold)[0] + 1 #获取保留下来的索引(因为没有计算与自身的IOU,所以索引相差1,需要加上) print("indexs = ", type(indexs)) order = order[indexs] #更新保留下来的索引 print("order = ", order) bbox = bbox_array[keep] predicts_dict[object_name] = bbox.tolist() predicts_dict = predicts_dict return predicts_dict
四、行人检测中的NMS
参考博客:https://blog.csdn.net/weixin_38632246/article/details/100542184
如果两个人靠得很近,将很难确定NMS的阈值,太大则会导致误检多,太小导致漏检多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号