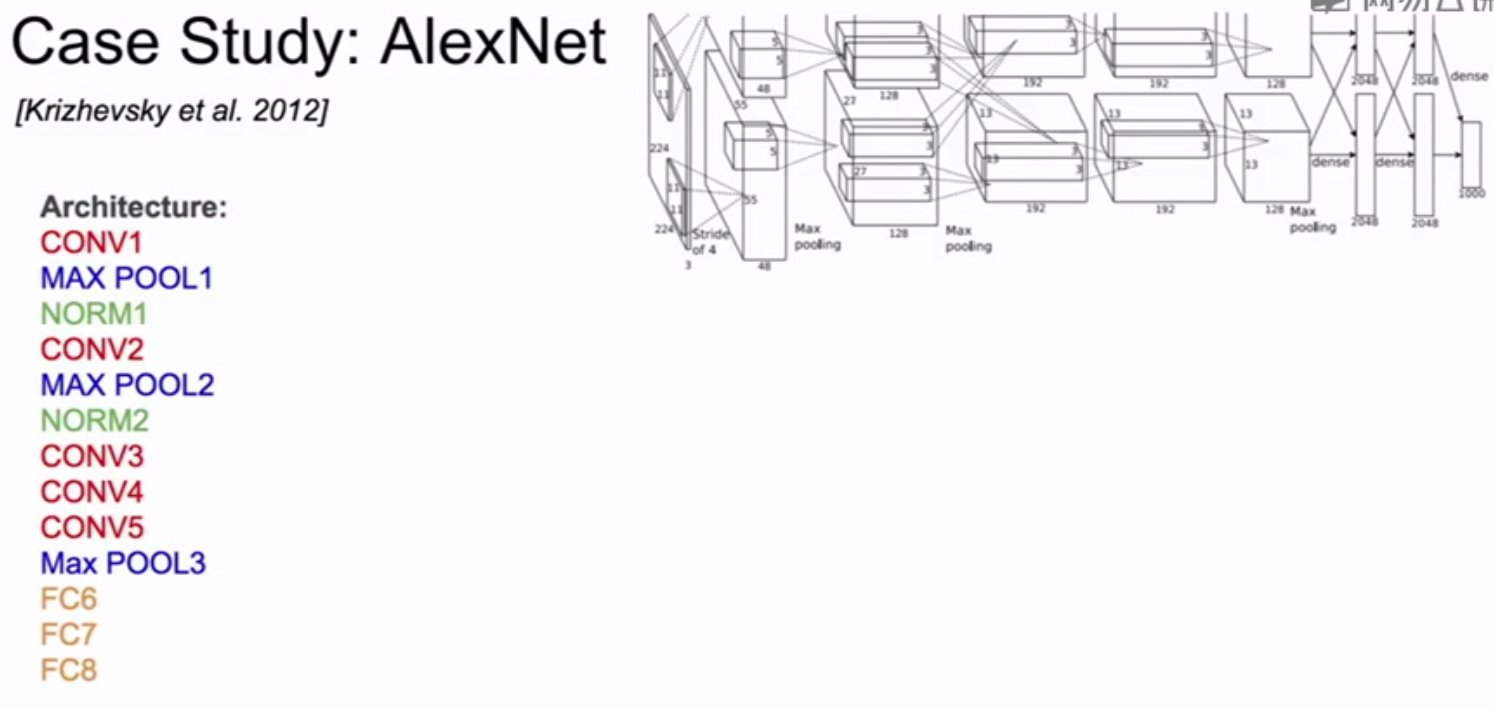
AlexNet:


VGGNet:

用3x3的小的卷积核代替大的卷积核,让网络只关注相邻的像素

3x3的感受野与7x7的感受野相同,但是需要更深的网络
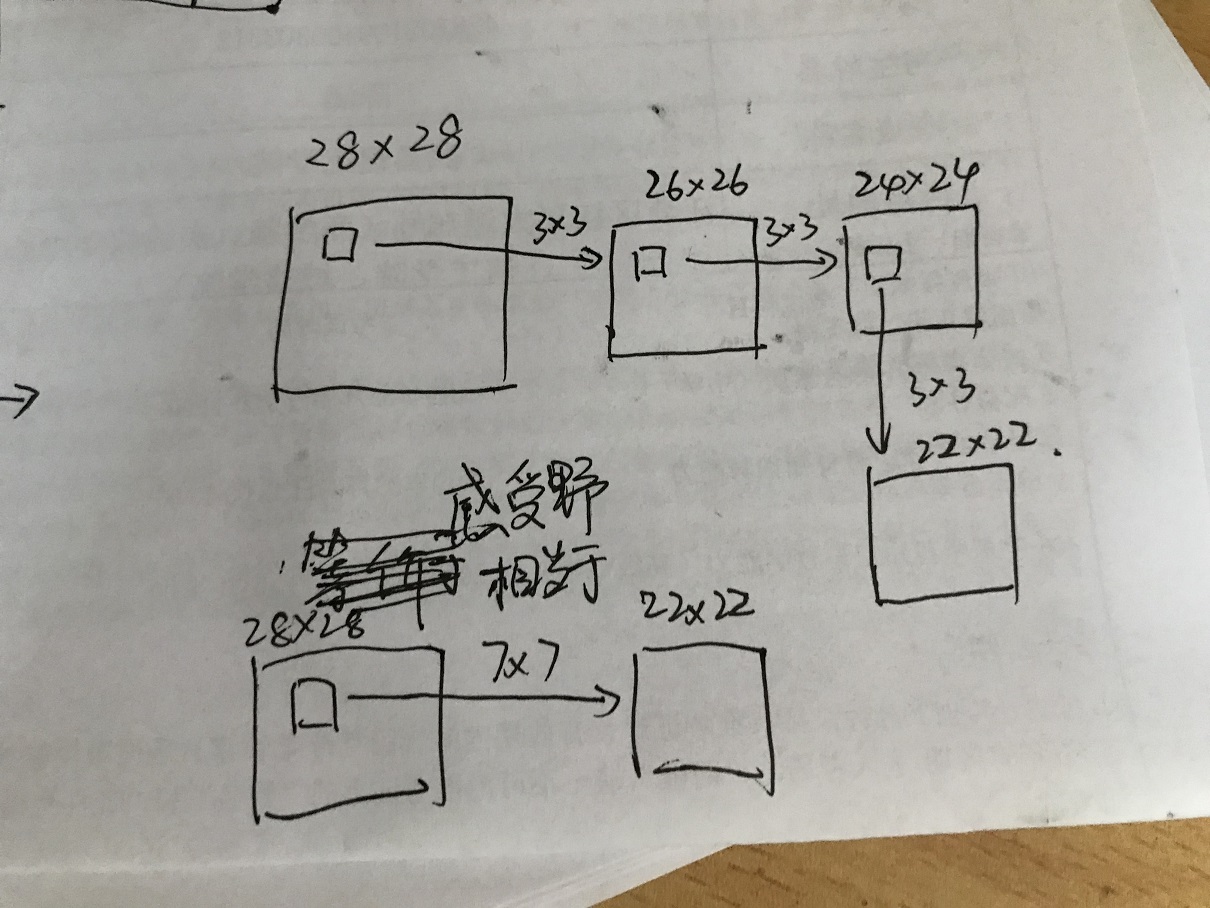
这样使得参数更少


大多数内存占用在靠前的卷积层,大部分的参数在后面的全连接层

GoogleNet:
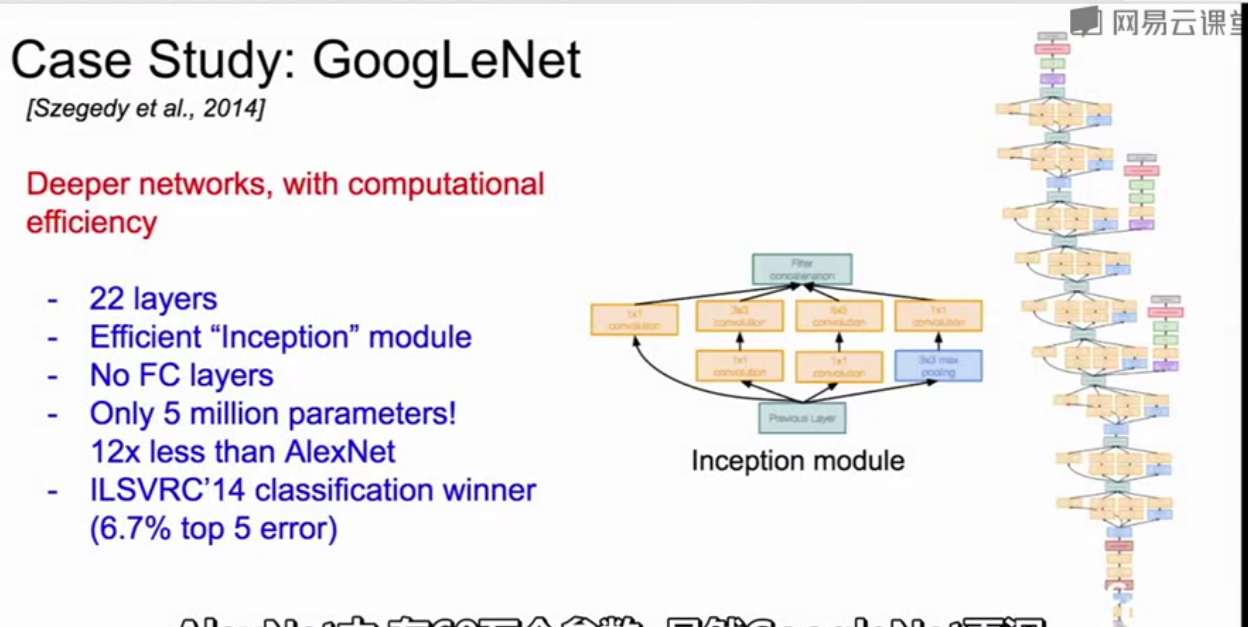

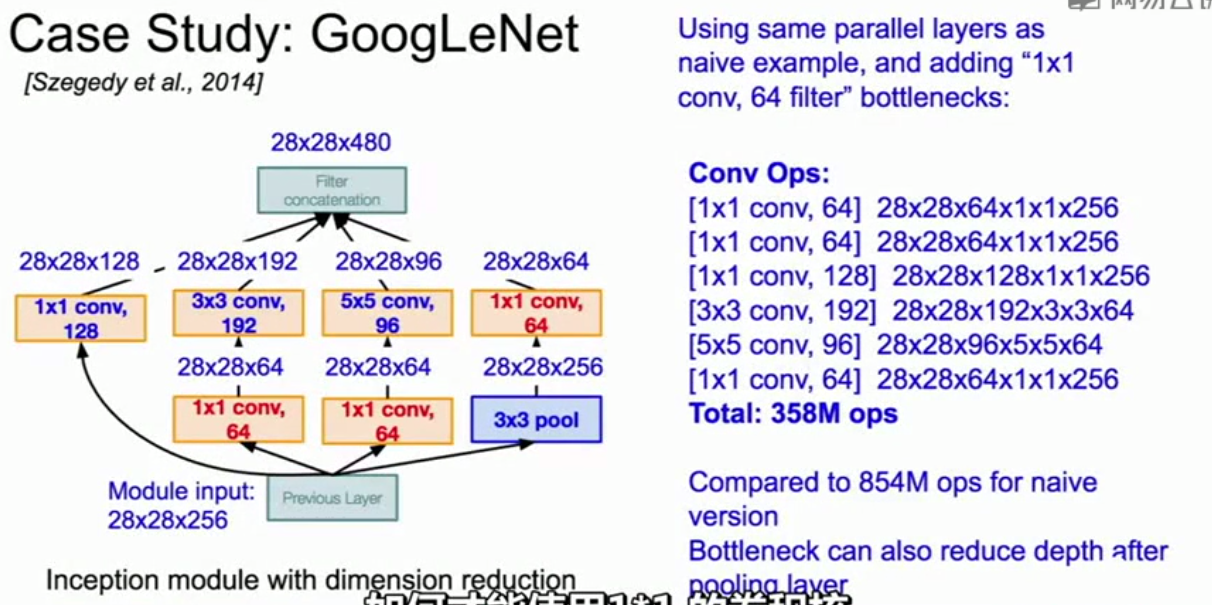
Inception模块:设计了一个局部网络拓扑结构,然后堆放大量的局部拓扑在每一个的顶部
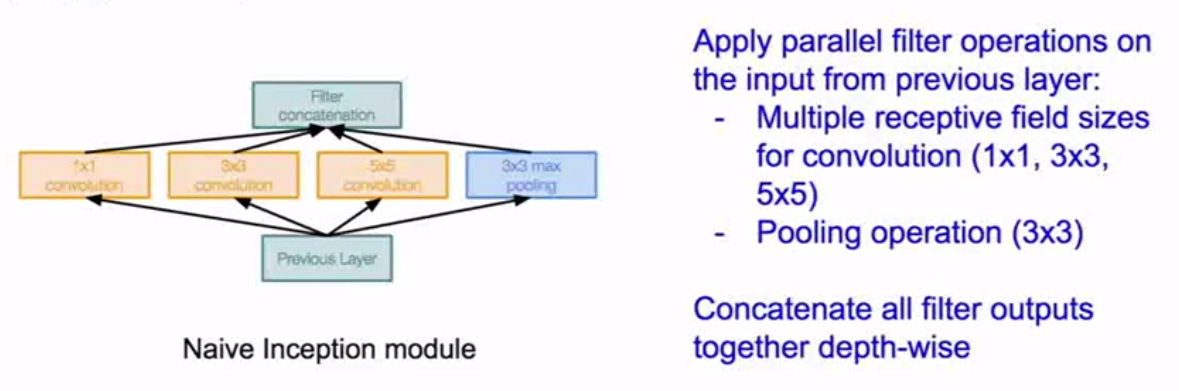
目的是将卷积和池化(filter)操作并行,最后在顶层将得到的输出串联得到一个张量进入下一层
这种做法会增加庞大的计算量:

(图中输入输出尺寸不变是因为增加了零填充)
为了降低计算量,会在inception之前增加一个瓶颈层通过1x1的卷积核进行降维操作

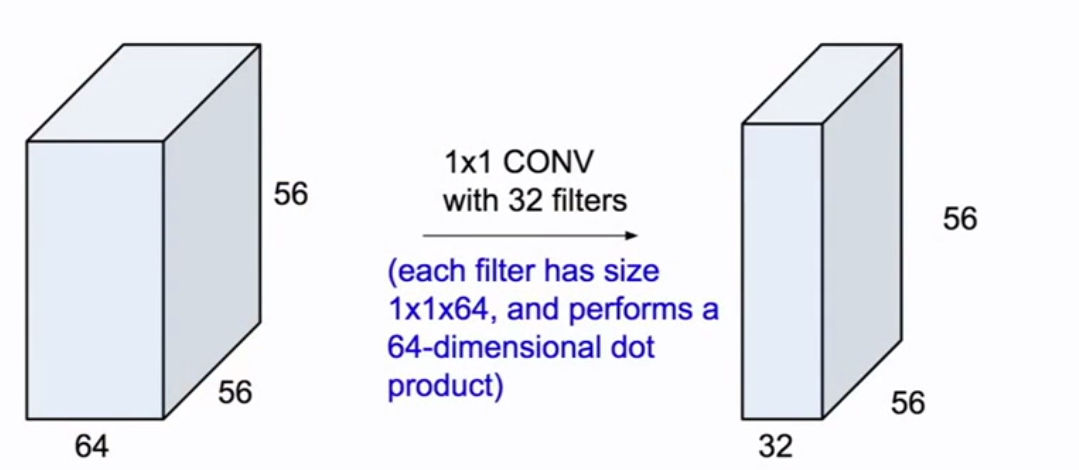


相比没有1x1卷积核的降维,计算量从8.54亿次减小到3.58亿次
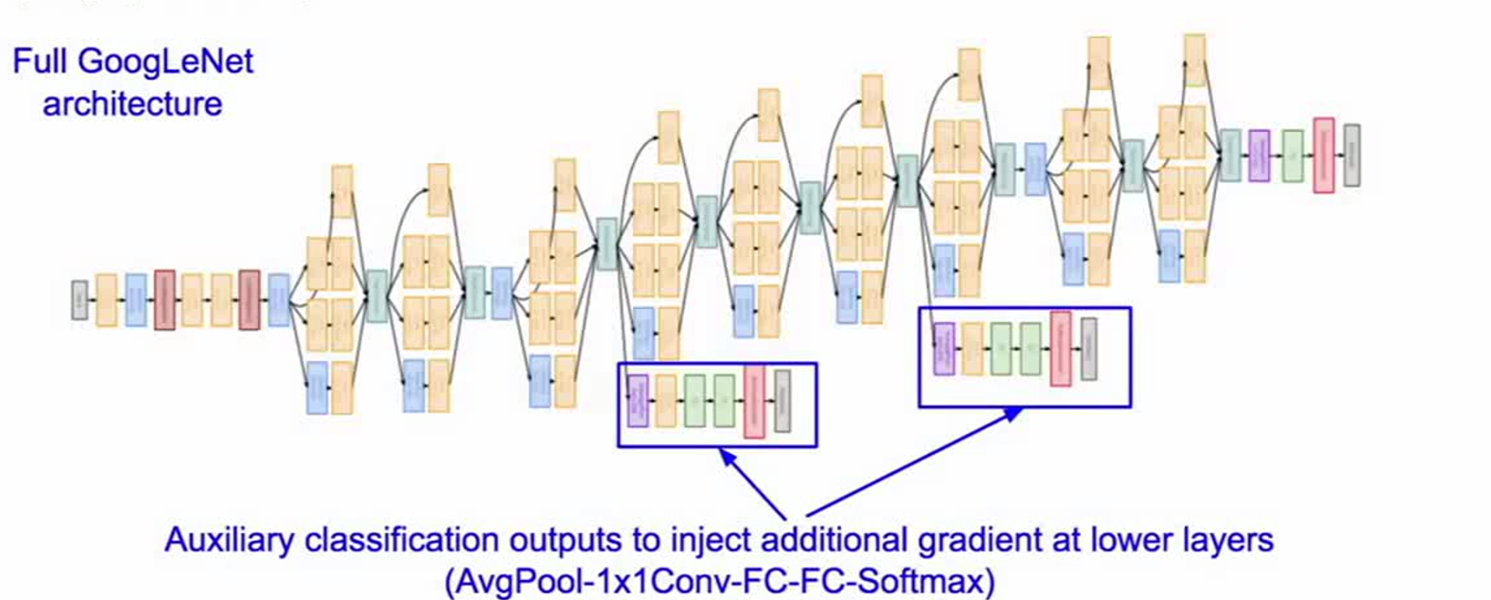
网络结构尾部完全移除全连接层,大量减少参数;有两个额外的辅助分类层
![]()
ResNet:

单纯不停的堆叠卷积层池化层plain convolutional neural network不使用残差结构)来加深网络的深度并不能表现得更好(不是因为过拟合,在训练集上表现得也不如20层的网络)
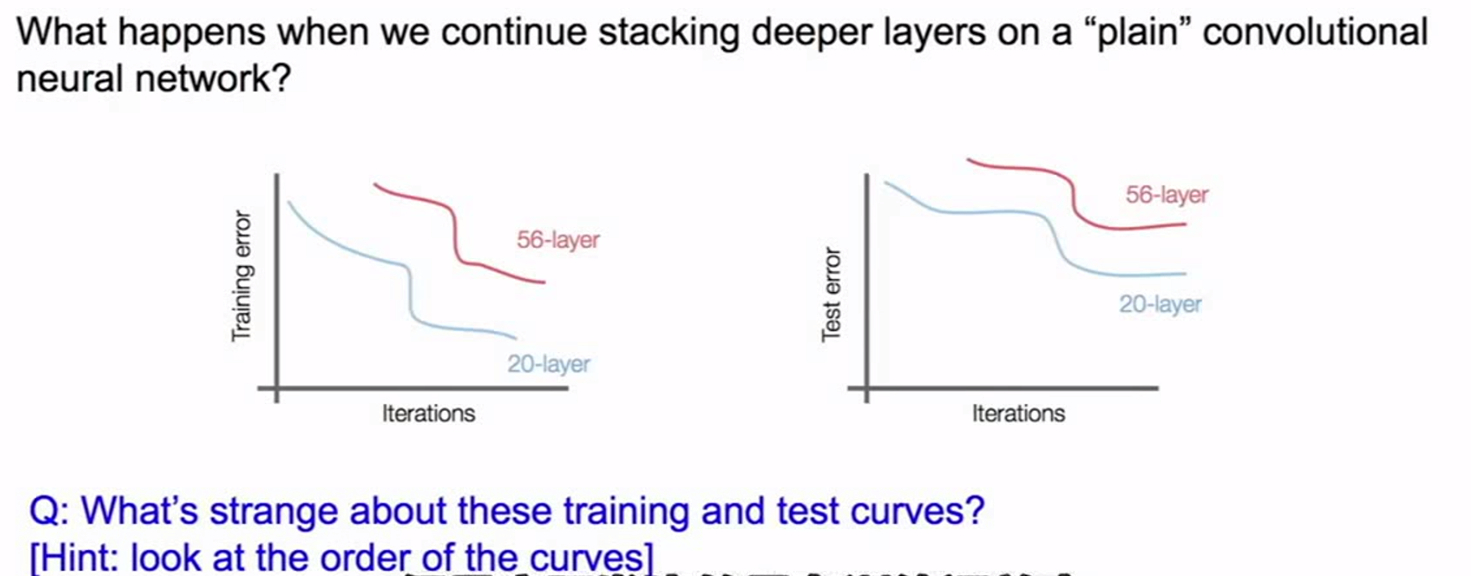
这是一个优化问题,深层的网络更加难以优化

深层的网络至少会跟浅层的网络表现的一样好,解决方案是将从浅层模型学到的层通过恒等映射copy到较深的层。
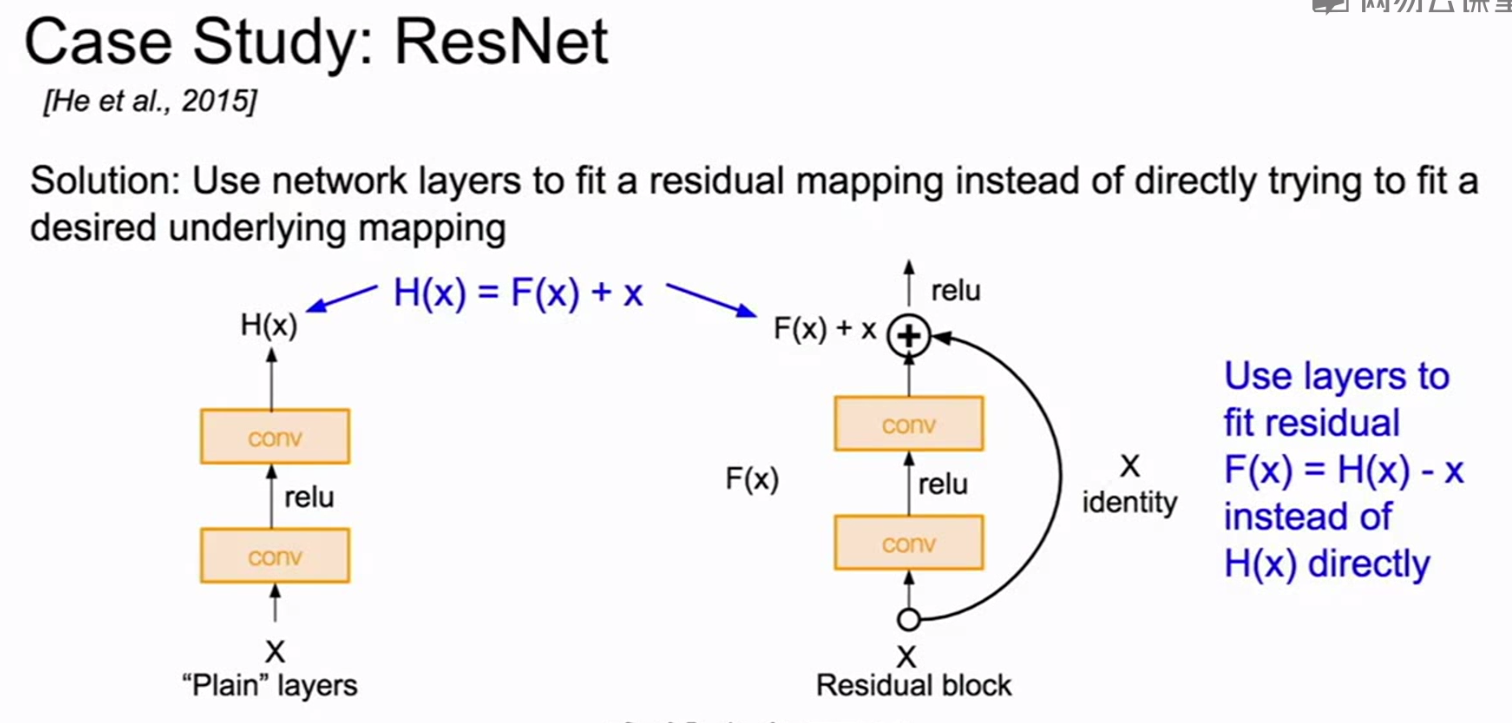
若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。
而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即H(X) - X即学习X -> (H(X) - X) + X。其中X这一部分为直接的identity mapping,而H(X) - X则为有参网络层要学习的输入输出间残差。
残差学习单元通过Identity mapping的引入在输入、输出之间建立了一条直接的关联通道,从而使得强大的有参层集中精力学习输入、输出之间的残差。一般我们用F(X, Wi)来表示残差映射,那么输出即为:Y = F(X, Wi) + X。
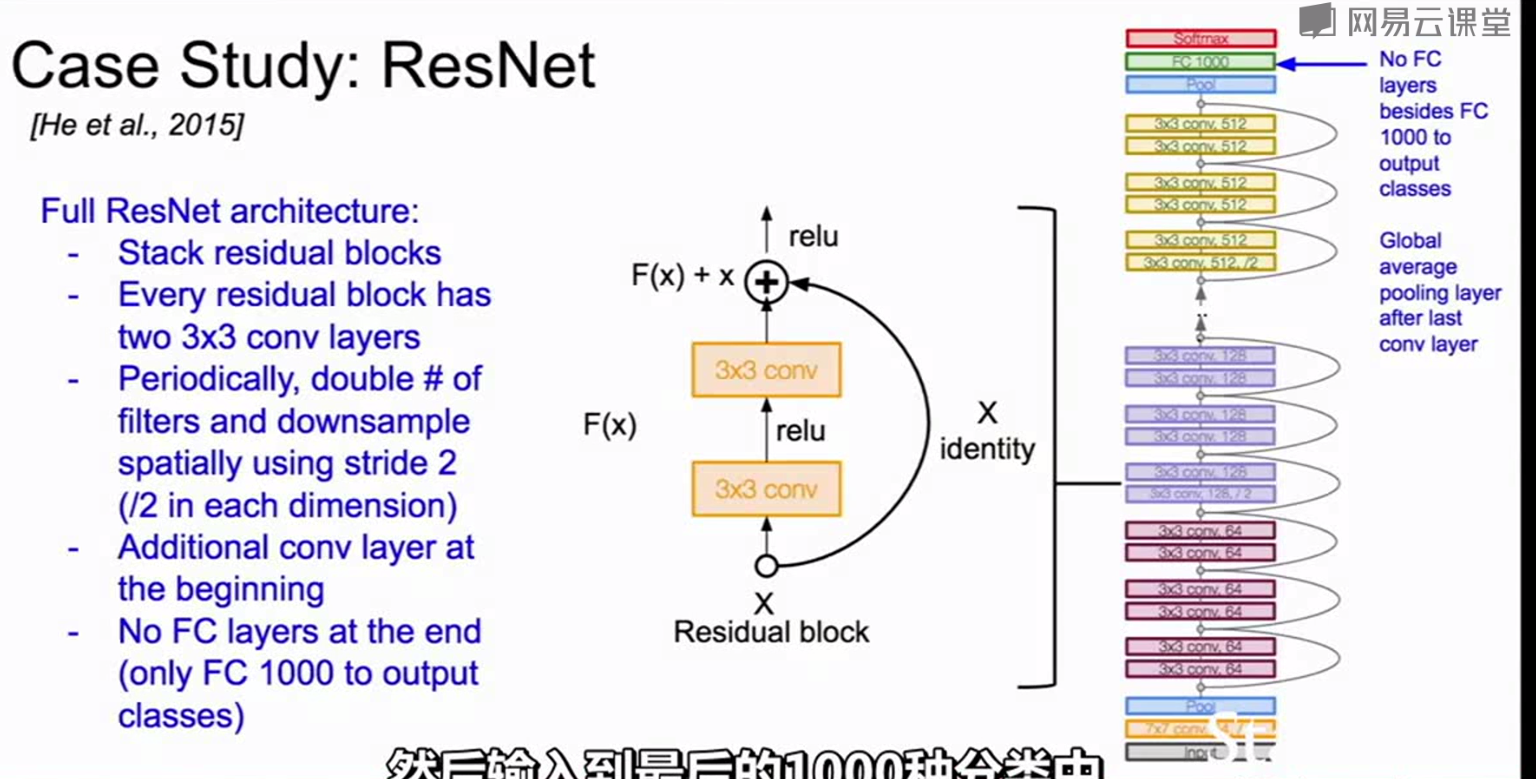
resnet也用到了GoogleNet中的瓶颈层操作


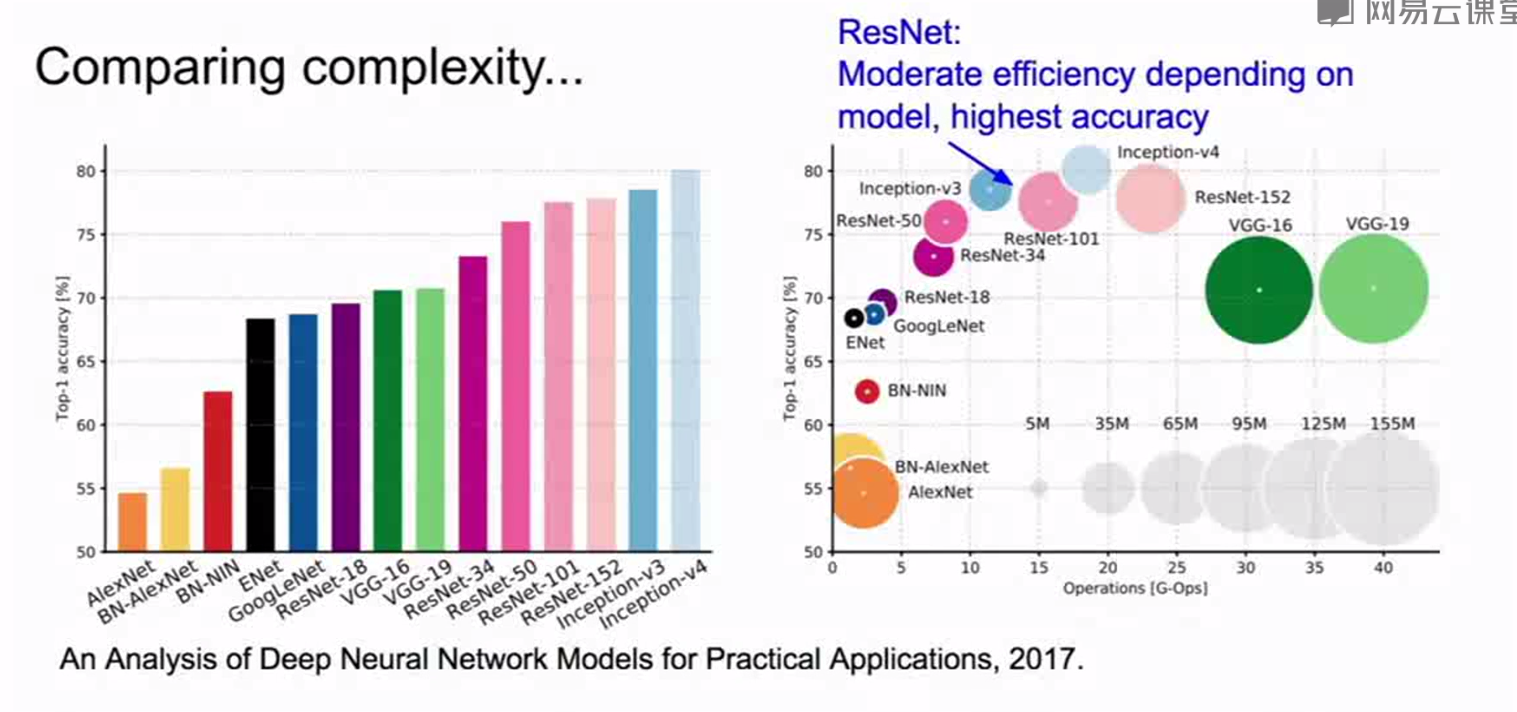
改进的残差:
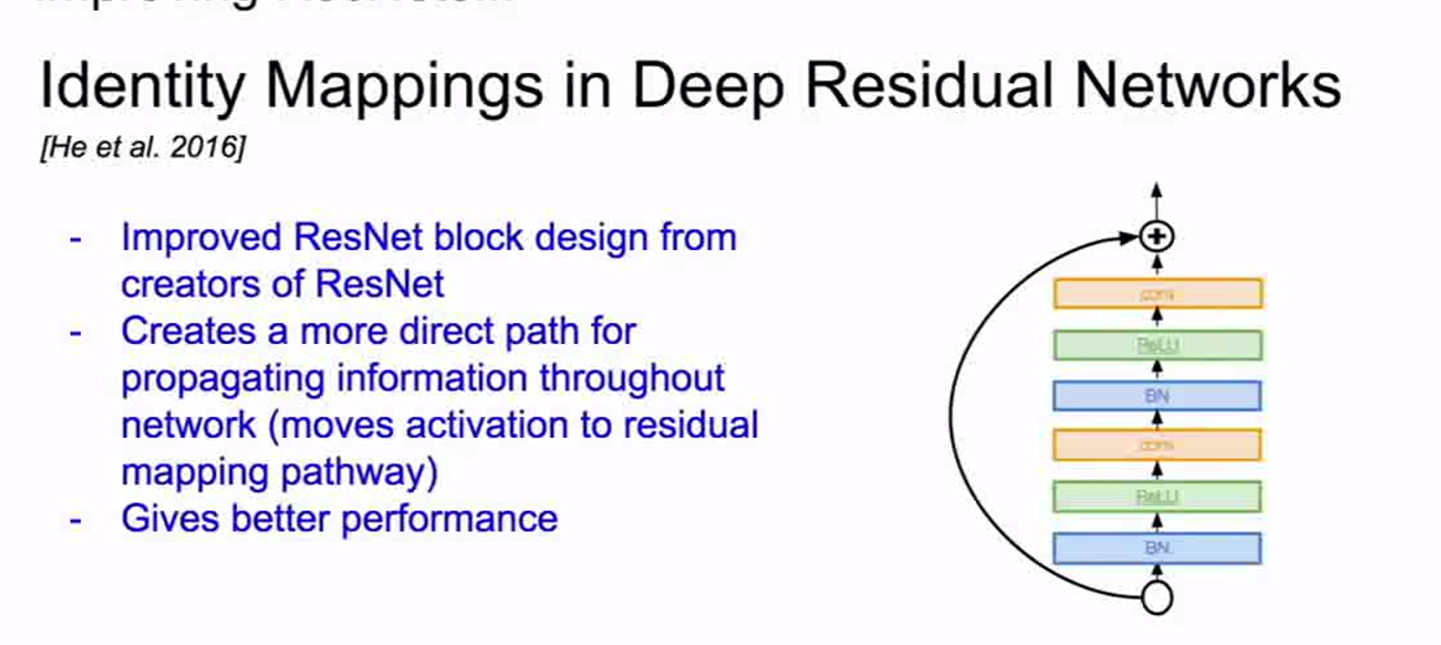
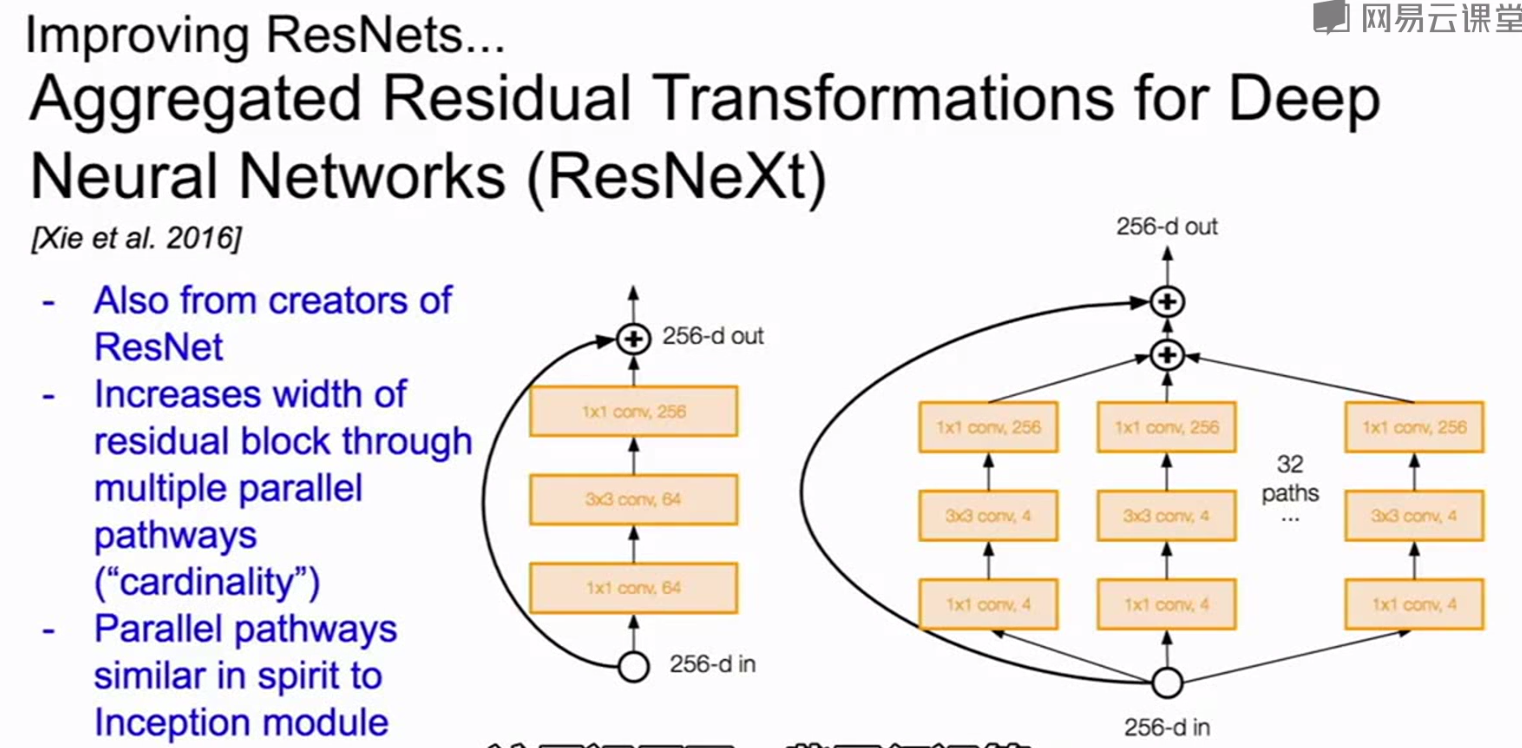

其他的网络:
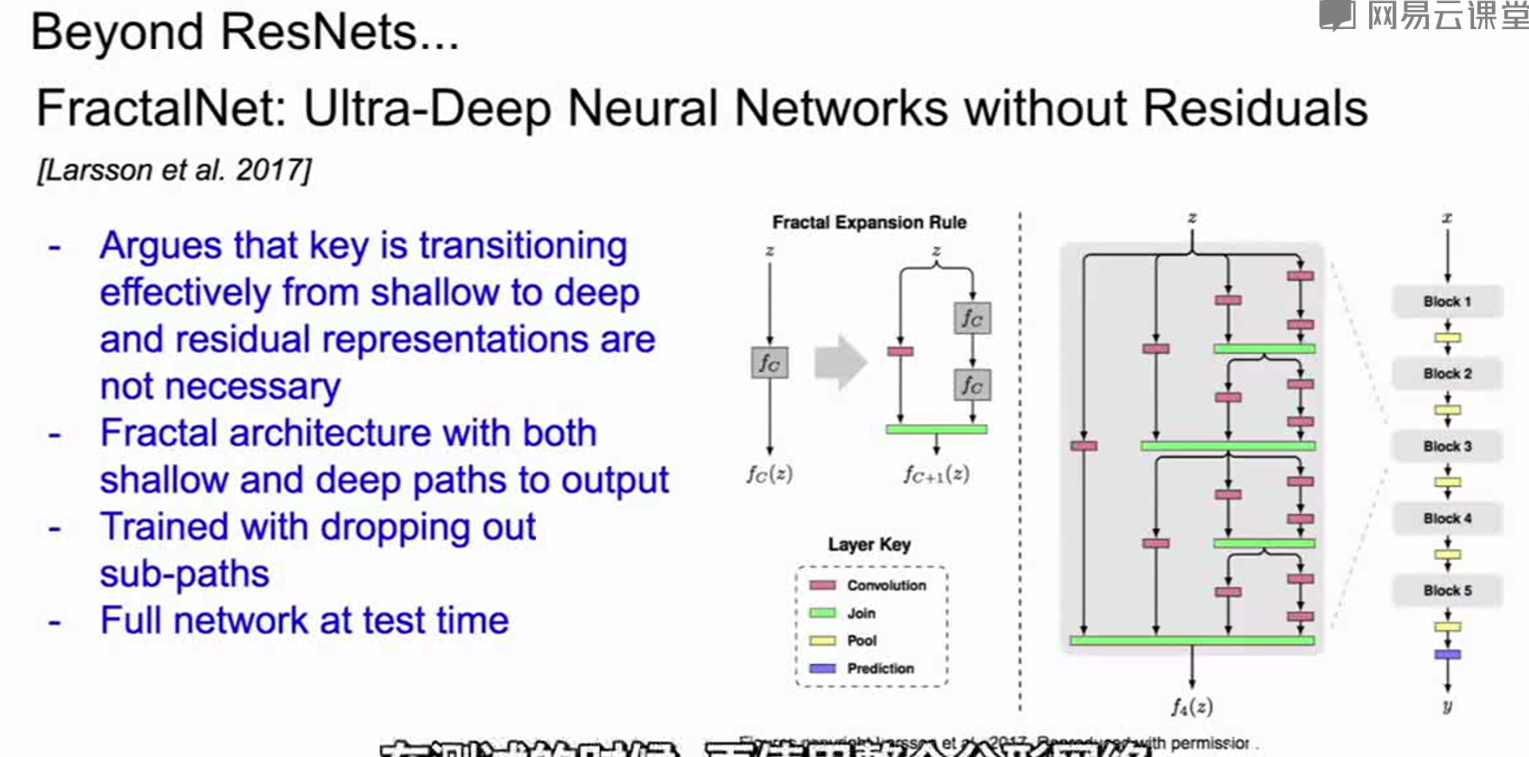
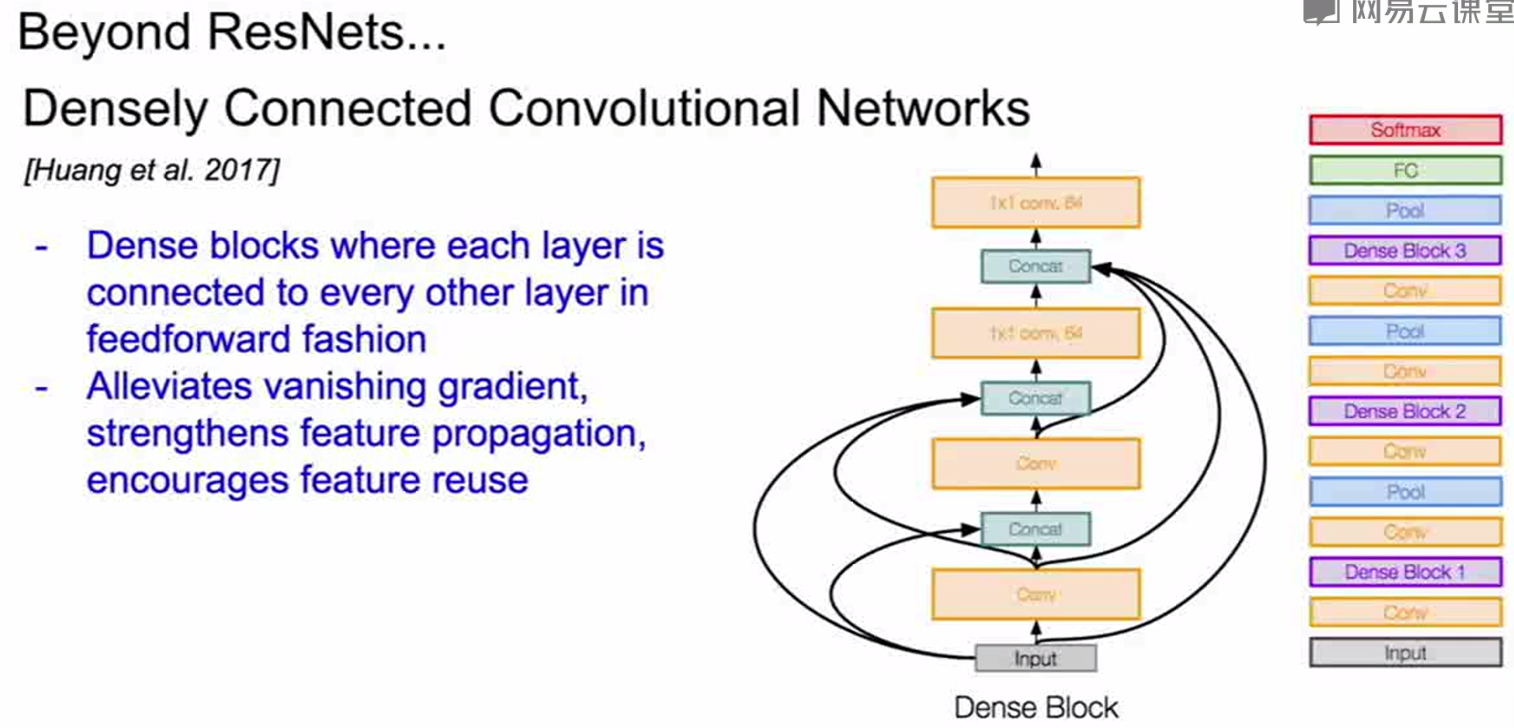
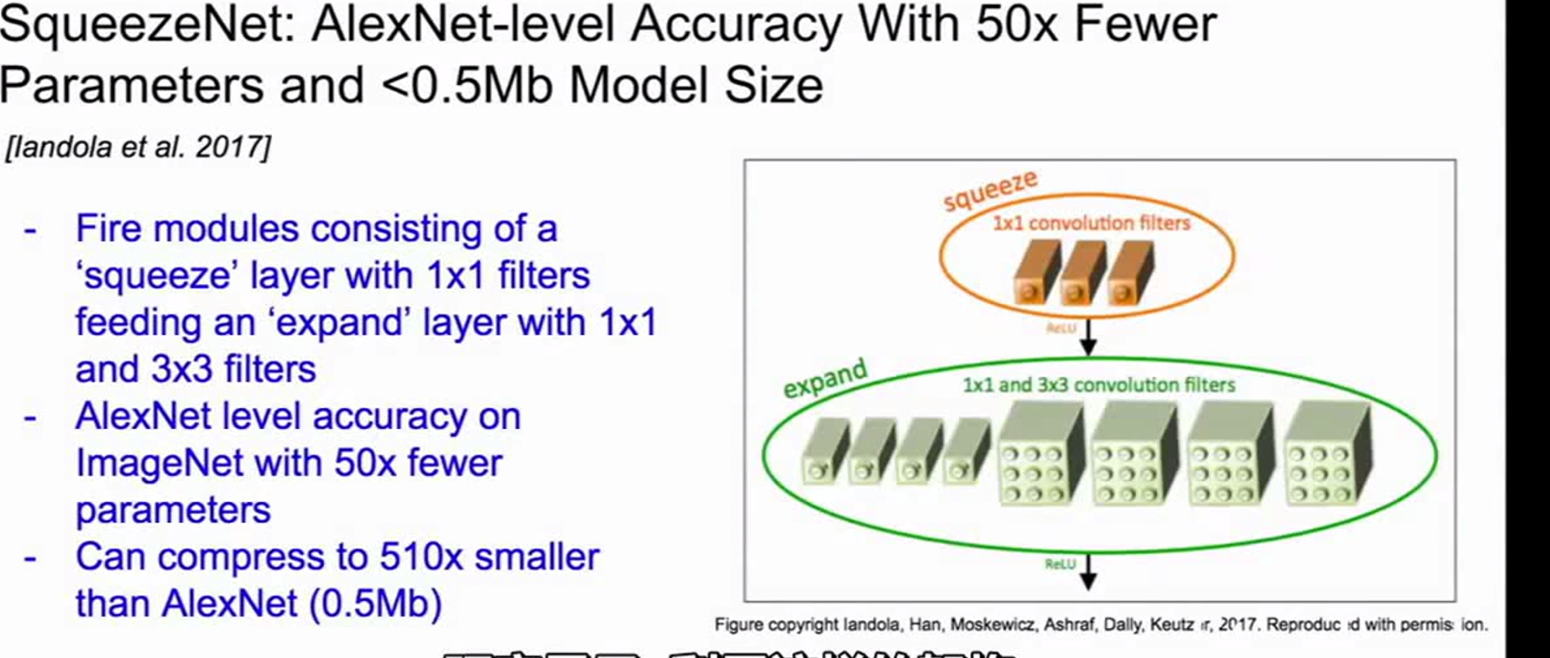

1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号