
考研数据结构与算法(五)数组
考研数据结构与算法(五)数组
@
一、数组的定义
数组是由 \(n(n >= 1)\) 个相同类型的数据元素构成的有限序列,每个数据元素称为一个数组元素,每个元素在 \(n\) 个线性关系中的序号称为该元素的下标,下标的取值范围称为数组的维界
数组和线性表的关系:数组是 线性表的推广 。一维数组可视为一个线性表;二维数组可视为其元素也是定长线性表的线性表,以此类推。数组一旦被定义,其维数和维界就不再改变。因此,除结构的初始化和销毁外,数组只会有存取元素和修改元素的操作。
二、二维数组的存储方式
对于数组而言占用的内存是一个连续的空间,那么在二维数组或者是多维数组的情况,对于地址映射的方式大题分为两种:
2.1 按行优先
顾名思义,我们元素地址是一行一行的填充,那么假设当前的二维数组是一个 \(N\times N\) 的结构(下标从0开始),每一个元素占用 \(L\) 的空间,那么假设我们要求 \(a[i][j]\) 的地址的话:
\(Loc_{a[i][j]} = Loc_{a[0][0]} + [i\times n + j] \times L\)
2.2 按列优先
这样的话我们是一列一列的填充,那么和上面的假设一样的话,要想求 \(a[i][j]\) 的地址,则需要小小的变化:
\(Loc_{a[i][j]} = Loc_{a[0][0]} + [j\times n + i] \times L\)
三、特殊矩阵和压缩矩阵
3.1 特殊矩阵
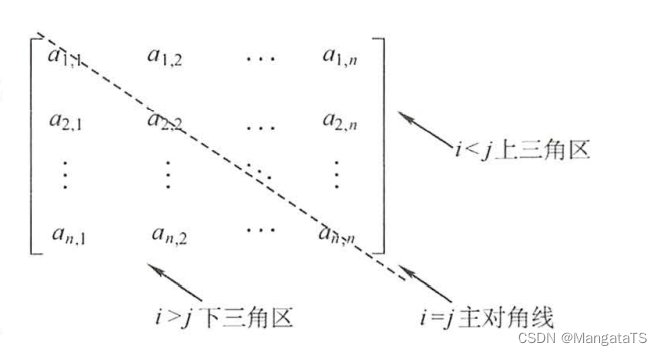
一个二维矩阵可以根据主对角线分为上三角区和下三角区:
3.1.1 对称矩阵
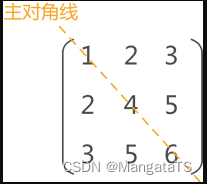
如果对于一个二维矩阵而言,其中所有单位元素满足:\(a[i][j] = a[j][i] (1<=i,j<=n)\) 那么就称其为对称矩阵,顾名思义就是沿着对角线对称,如下图所示
由于存在这样的结构,那么我们可以发现空间是重复了,为了提高空间利用率,我们将这个二维数组压缩到一个一维数组里面,那么我们其实可以发现我们只需要保存上三角区或者下三角区的数据就能完整的恢复整个矩阵的数据,这样的话我们就节约了近一半的空间,于是我们将元素 \(a[i][j]\) 存放到一位数组 \(b[k]\) 的位置,那么 \(k\) 和 \(i、j\) 的关系为(这里的 \(i、j\) 从 \(1\) 开始,而 \(k\) 从 0开始):
3.1.2 上(下)三角矩阵
下三角矩阵其实就是上三角区全部为相同常量的一个矩阵,这个存储方式和压缩方式和上面的对称矩阵类似,只需要使用一半的空间即可,压缩后的元素下标之间的对应关系如下:
那么我们会发现这里的空间比上面的对称矩阵多一个,即 \((n+1)n/2 + 1\) ,这里多出来的也就是存储整个上三角区的数据,下三角矩阵在一维数组的压缩存储如下:

那么上三角矩阵也就是同理了
3.1.3 稀疏矩阵
稀疏矩阵其实只是一个概念性的东西,也就是在一个矩阵中有效的数据元素很少的矩阵,就称为稀疏矩阵,假设在一个 \(m\times n\) 的矩阵中,有 \(t\) 个元素不为 \(0\) ,令 \(k = \frac{t}{m\times n}\) ,则 \(k\) 为矩阵的 稀疏因子 ,通常认为当 \(k<=0.05\) 的时候称为稀疏矩阵。
那么对于一个稀疏矩阵我们应当如何压缩呢,其实我们可以只需要存储稀疏矩阵中不为 \(0\) 的元素的特征,如行、列、值三个信息,这样就构成了一个三元组,我们只需要存储这些有意义的三元组即存储了整个矩阵,例如:
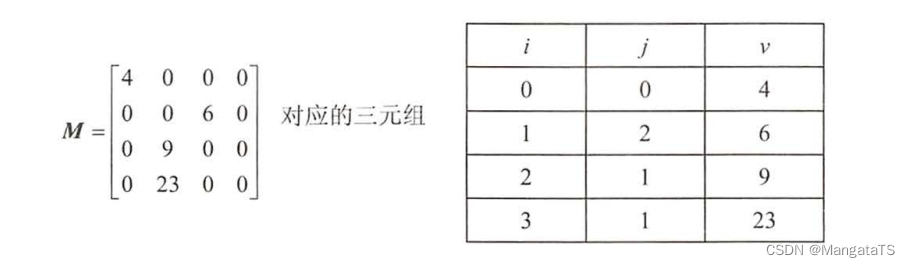
这就是一个简单的例子
3.1.4 三对角矩阵
对角矩阵也称带状矩阵。对于一个 \(n\) 阶矩阵 \(A\) 中任意元素 \(a_{i,j}\) ,当 \(|i-j| > 1\) 时,有 \(a_{i,j} = 0 (1<=i,j<=n)\) 则称为三对角矩阵,在三对角矩阵中所有非零元素都集中在以主对角线为中心的三条线的区域。
结构如图:
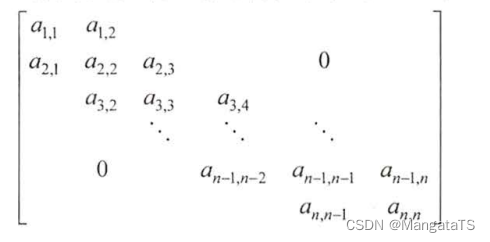
如果想将这样一个矩阵压缩到一维数组中,实际上我们不难发现这样一个规律,元素 \(i,j\) 和 \(k\) 的关系为:
\(k = 2i + j - 3\)
结构如图:

反之,若知道元素 \(a[i][j]\) 存放在一维数组中的第 \(k\) 个位置的话,可以得到:
例如,当 \(k\) 等于 \(0\) 的时候,\(i = \left \lfloor (0+1)/3 + 1 \right \rfloor = 1,j = 0-2\times 1 + 3 = 1\) 即第一个位置存放的是矩阵元素 \(a[1][1]\)
四、广义表的定义和存储结构
4.1 广义表的定义
广义表,又称列表,也是一种线性存储结构,既可以存储不可再分的元素,也可以存储广义表,记作:\(LS = (a_1,a_2,…,a_n)\) ,其中,LS 代表广义表的名称,\(a_n\) 表示广义表存储的数据,广义表中每个 \(a_i\) 既可以代表 单个元素 ,也可以代表另一个 广义表 ,分别称为广义表 \(LS\) 的 原子 和 子表
之前我们讲到的线性表其中的元素就是单一的,只能为相同元素结构,而广义表对于每一个单元,都允许其数据类型不同,甚至是另一个广义表
4.2 广义表的存储结构
正是由于广义表这种每个单元的数据元素结构可以不同,因此很难使用顺序存储结构,一半多使用链式存储结构,对于每个结点而言,其中的值并不重要,只需要通过指针串联起来即可
那么一个表结点可以由三个部分构成:标识域、指示表头的指针域和表尾的指针域,而 原子结点 只需要标识域和值域,于是我们得到了一个大概的结构:
typedef enum{ATOM,LIST}ElemTag;//ATOM=0表示原子结点,ATOM=1表示子表
typedef struct GLNode{
ElemTag tag;
union {
ATomType atom;
struct {struct GLNode *hp,*tp} ptr;
};
}*Glist;
4.3 广义表的深度和长度
-
广义表的长度,指的是
广义表中所包含的数据元素的个数。 -
计算元素个数时,广义表中存储的每个原子算作一个数据,同样每个子表也只算作是一个数据
- \(LS = {a_1,a_2,…,a_n}\) 的长度为 \(n\) ;
- 广义表 \({a,{b,c,d}}\) 的长度为 2;
- 广义表 \({{a,b,c}}\) 的长度为 1;
- 空表 \({}\) 的长度为 0。
广义表的深度,可以通过观察该表中所包含括号的层数间接得到,也就是表的层数,线性表的深度就是一层,如下示例,该广义表的深度为2。
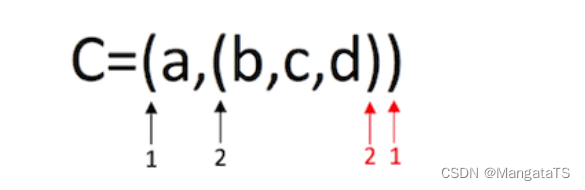

 浙公网安备 33010602011771号
浙公网安备 33010602011771号