java的HashMap的几个问题
HashMap处理hash冲突的几种方法
一、 开放定址法
Hi=(H(key) + di) MOD m i=1,2,...k(k<=m-1)其中H(key)为哈希函数;m为哈希表表长;di为增量序列。
开放定址法根据步长不同可以分为3种:
1)线性探查法(Linear Probing):di=1,2,3,...,m-1
简单地说就是以当前冲突位置为起点,步长为1循环查找,直到找到一个空的位置就把元素插进去,循环完了都找不到说明容器满了。就像你去一条街上的店里吃饭,问了第一家被告知满座,然后挨着一家家去问是否有位置一样。
2)线性补偿探测法:di=Q 下一个位置满足 Hi=(H(key) + Q) mod m i=1,2,...k(k<=m-1) ,要求 Q 与 m 是互质的,以便能探测到哈希表中的所有单元。
继续用上面的例子,现在你不是挨着一家家去问了,拿出计算器算了一下,然后隔Q家问一次有没有位置。
3)伪随机探测再散列:di=伪随机数序列。还是那个例子,这是完全根据心情去选一家店来问了
缺点:
- 这种方法建立起来的hash表当冲突多的时候数据容易堆聚在一起,这时候对查找不友好;
- 删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点
- 当空间满了,还要建立一个溢出表来存多出来的元素。
二、再哈希法
Hi = RHi(key),i=1,2,...k
RHi均是不同的哈希函数,即在同义词产生地址冲突时计算另一个哈希函数地址,直到不发生冲突为止。这种方法不易产生聚集,但是增加了计算时间。
缺点:增加了计算时间。
三、建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0...m-1]为基本表,每个分量存放一个记录,另设立向量OverTable[0....v]为溢出表。所有关键字和基本表中关键字为同义词的记录,不管他们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。
简单地说就是搞个新表存冲突的元素。
四、链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中,也就是把冲突位置的元素构造成链表。
拉链法的优点:
- 拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
- 由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
- 在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
拉链法的缺点:
- 指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度
HashMap在java1.8中为什么用红黑树?
在jdk1.8版本后,java对HashMap做了改进,在链表长度大于8的时候,将后面的数据存在红黑树中,以加快检索速度。
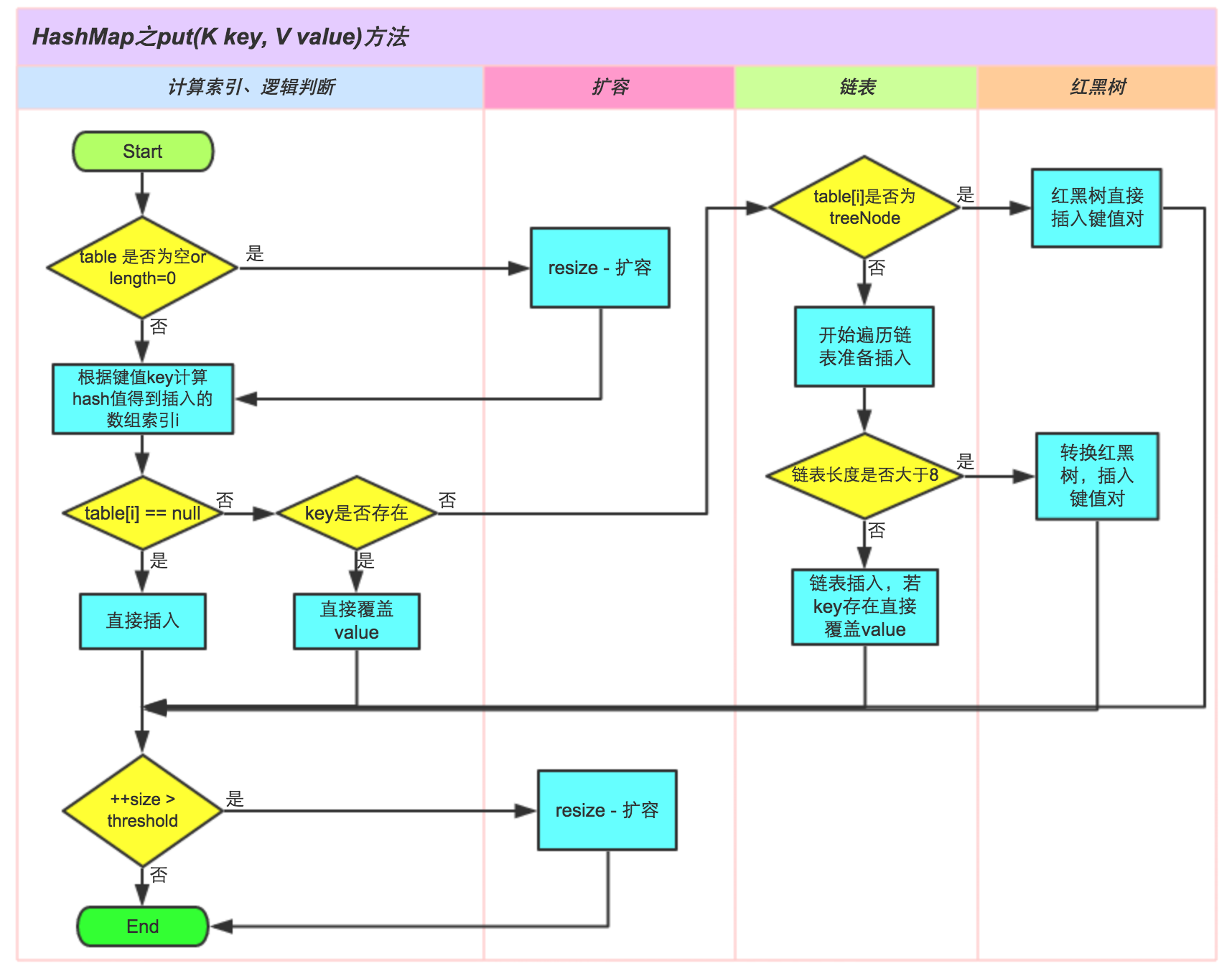
举例:HashMap的put操作:
HashMap中数组的长度为什么是2的n次幂?
在HashMap中采用indexFor方法返回保存该对象的位置信息:
1 2 3 4 5 6 7 8 9 10 11 | static int indexFor(int h,int length){ return h & (length - 1);}static int hash(int h){ h ^= (h >>> 20) ^ (h >>>12); return h ^ (h >>> 7) ^ (h >>> 4);} |
所以数组长度是2的n次方:
- h & (table.length - 1)的到对象的保存位,2的n次幂减去1在每个位数的值都是1,全部为1进行与操作速度会大大提高;
- 数组长度为2的n次慕时候,不同的key值算得的index相同概率较小,减小了hash碰撞的几率,同样查询也不需要总是遍历链表,查询的效率得到了提高;
参考:
链接:https://www.jianshu.com/p/dff8f4641814
链接:https://blog.csdn.net/wushiwude/article/details/75331926
感谢您的阅读,如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮。本文欢迎各位转载,但是转载文章之后必须在文章页面中给出作者和原文连接。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步