一句简单的SQL查询语句的背后...
当我们在SQL Server Management Studio的查询里面输入: SELECT * FROM t1 WHERE c1=2;
背后发生了什么?数据库怎么去执行查询的? - 知其然不知其所以然。
1. Query Parsing, Synatax Error Check, and Authorization: Query Processer check the user is authorized to run the query;(查询处理器首先进行语法解析,语法检查,并检查授权。如果没有获得授权执行相关的操作,或者语法错误,将报错。)
2. Query Re-writing,Semantic Optimization; (查询处理器重新写SQL语句并做相应的优化)。
例如:SELECT Emp.name, Emp.salary
FROM Emp, Dept
WHERE Emp.deptno = Dept.dno
Join是多余的,查询处理器会重写该语句并删除到表Dept的Join。
3. Compile the SQL into internal query Plan; (编译SQL到内部查询计划)
数据库会选择最佳的方法来计算结果集。例如进行全表扫描,或是使用索引(pairs of key and location,类似书的目录)。数据库会比较它们的成本,并形成内部执行计划。数据库内部负责计算选择最佳执行计划的组件叫优化器(Optimizer)。
4. The query plan is handled by plan executor, which consists of many operators, e.g. joining, sorting, grouping... (查询计划被计划执行器执行。计划执行器包含很多操作者,例如执行Join, Sort, Group等,还要有访问方法管理器来决定存取哪些数据页或索引页,或是直接缓存命中,这些有缓冲管理器负责... ...)
5. Transaction manager is started as well to ensure the ACID of operations. (事务管理器同时启动来保证原子操作的并发一致性, 其他例如锁管理器、索引管理器、行管理器、页面文件管理器、缓冲管理器、日志管理器和等也会执行,而不是有查询执行器一人包办所有。)
执行如下语句:SELECT * FROM t1 WHERE c1=2的简单过程:
1. 扫描t1表,如果是开始则取第一条记录,否则取下一条记录;如果读到表的最后一条记录了那么跳到第4步。
2. 检查记录是否满足WHERE条件;是则进入第3步,否则回到第1步。
3. 把记录加到结果集。
4. 返回结果集给客户端。
如果表有索引,优化器可能比较全表扫描和索引,并可能决定执行计划为扫描索引。则步骤类似,不过第1步变成:
扫描索引(Clustered or no-clustered)并定位到记录。
例如:
SELECT * FROM Customers WHERE contactID IN
(SELECT contactID FROM Contacts WHERE contactID=86)
ORDER BY CustomerName DESC;
增加的步骤有:
1. 在表[Contacts]中扫描索引并定位记录。
2. 在表[Customers]中扫描索引并定位记录。
3. Hash match (inner join),哈希匹配,连接。
4. Sort,排序
有关Join
SQL Server employs three types of join operations:
- Nested loops joins
- Merge joins
- Hash joins
- 如果Join的输入很小,例如小于10行,然后其他的Join输入很大并且索引在其列上,则Nested loops joins是最快的。(原因参考Understanding Nested Loops Joins)
- 如果两个Join输入都不小,但在索引列上排序(例如是在扫描排序的索引后获得的 scanning sorted indexes),则Merge joins是最快的。(原因参考Understanding Merge Joins)
- Hash joins可以有效的处理大量的、没有排序的、没有索引的输入。尤其对复杂查询的中间结果处理很有效。(更多参考Understanding Hash Joins)
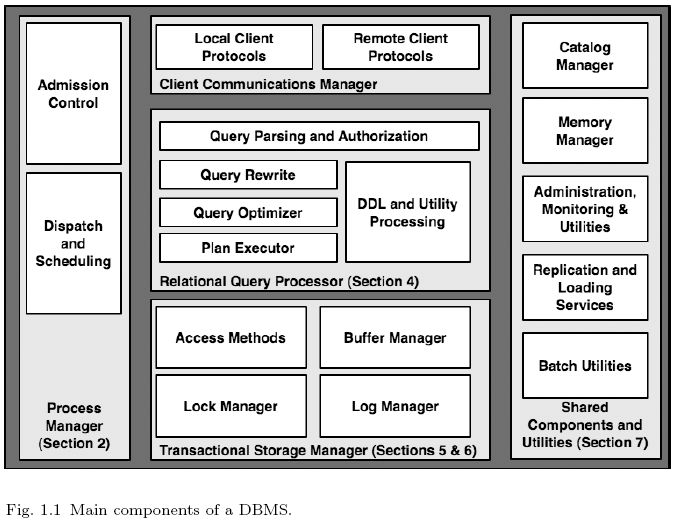
这些只是一些简单的过程,其实数据库内部执行过程是相当复杂的。虽然我们不是数据库开发人员,但了解上下游的知识是必须的,能够有助于我们的开发和应用。技术不仅要知道怎么用,而且要知道为什么,不能知其然不知其所以然。最后附上一张数据库内部简单结构图供有兴趣的人参考。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述