
Linux 链接详解(1)
可执行文件的生成过程:
hello.c ----预处理---> hello.i ----编译----> hello.s -----汇编-----> hello.o -----链接----->hello -----加载---->hello进程
其中预处理器根据hello.c中的#开头的命令解析, 如将include 头文件放在此处,选择条件编译等等; 编译阶段 就是将.i 文件翻译为更低级的汇编指令; 而后这些汇编指令通过汇编器汇编为目标文件; 最后在由连接器将目标文件与库文件链接为可执行文件; 程序要运行时 再由加载器将之加载到内存运行。
对于链接的阶段又可以分为静态链接和动态链接,接下来主要讲解它们各自的特点和原理。
符号表和Linux目标文件格式ELF
首先这里先说明一下符号表和Linux目标文件格式ELF:
如代码:
//main.c
void swap(); int buf[2] = {1,2}; int main() { swap(); return 0; }
//swap.c
extern int buf[];
int *bufp0 = &buf[0];
int *bufp1;
void swap()
{
int temp;
bufp1 = &buf[1];
temp = *bufp0;
*bufp0 = *bufp1;
*bufp1 = temp;
}
先将文件main.c变为汇编:
.file "main.c"
#表示全局的数据段
.globl buf
.data
.align 4
.type buf, @object
.size buf, 8
buf: .long 1 .long 2
#表示全局的代码段 .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $0, %eax call swap movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret
这里的section标记buff,main就是用来生成符号表的,.c 文件经过语法分析后变成汇编语言,再由汇编中的.text .data 表示目标文件.o 的代码段和数据段,各个段的不同内容再用符号表来表示。目标文件可以是可重定位文件或者可执行文件, 那么为什么要是elf格式呢? 这里就牵扯到可执行文件加载的问题,加载器将可执行文件加载到到内存,其实质就是解析可执行文件的elf, 将按照其格式将代码段 数据段 只读数据段 bss段等加载到虚拟地址空间。我们可以简单看一下linux 0.12 exec.c 源代码:


//a.out.h 早期的elf struct exec { unsigned long a_magic; /* Use macros N_MAGIC, etc for access */ unsigned a_text; /* length of text, in bytes */ unsigned a_data; /* length of data, in bytes */ unsigned a_bss; /* length of uninitialized data area for file, in bytes */ unsigned a_syms; /* length of symbol table data in file, in bytes */ unsigned a_entry; /* start address */ unsigned a_trsize; /* length of relocation info for text, in bytes */ unsigned a_drsize; /* length of relocation info for data, in bytes */ }; 再看exec.c 的exec函数 int do_execve(unsigned long * eip,long tmp,char * filename, char ** argv, char ** envp) { struct m_inode * inode; struct buffer_head * bh; struct exec ex;//elf 格式struct unsigned long page[MAX_ARG_PAGES]; int i,argc,envc; int e_uid, e_gid; int retval; int sh_bang = 0; unsigned long p=PAGE_SIZE*MAX_ARG_PAGES-4; if ((0xffff & eip[1]) != 0x000f) panic("execve called from supervisor mode"); for (i=0 ; i<MAX_ARG_PAGES ; i++) /* clear page-table */ page[i]=0; if (!(inode=namei(filename))) /* get executables inode */ return -ENOENT; argc = count(argv); envc = count(envp); restart_interp: if (!S_ISREG(inode->i_mode)) { /* must be regular file */ retval = -EACCES; goto exec_error2; } i = inode->i_mode; e_uid = (i & S_ISUID) ? inode->i_uid : current->euid; e_gid = (i & S_ISGID) ? inode->i_gid : current->egid; if (current->euid == inode->i_uid) i >>= 6; else if (in_group_p(inode->i_gid)) i >>= 3; if (!(i & 1) && !((inode->i_mode & 0111) && suser())) { retval = -ENOEXEC; goto exec_error2; } if (!(bh = bread(inode->i_dev,inode->i_zone[0]))) { retval = -EACCES; goto exec_error2; } ex = *((struct exec *) bh->b_data); /* read exec-header 读取elf 信息*/ if ((bh->b_data[0] == '#') && (bh->b_data[1] == '!') && (!sh_bang)) { /* * This section does the #! interpretation. * Sorta complicated, but hopefully it will work. -TYT */ char buf[128], *cp, *interp, *i_name, *i_arg; unsigned long old_fs; strncpy(buf, bh->b_data+2, 127); brelse(bh); iput(inode); buf[127] = '\0'; if (cp = strchr(buf, '\n')) { *cp = '\0'; for (cp = buf; (*cp == ' ') || (*cp == '\t'); cp++); } if (!cp || *cp == '\0') { retval = -ENOEXEC; /* No interpreter name found */ goto exec_error1; } interp = i_name = cp; i_arg = 0; for ( ; *cp && (*cp != ' ') && (*cp != '\t'); cp++) { if (*cp == '/') i_name = cp+1; } if (*cp) { *cp++ = '\0'; i_arg = cp; } /* * OK, we've parsed out the interpreter name and * (optional) argument. */ if (sh_bang++ == 0) { p = copy_strings(envc, envp, page, p, 0); p = copy_strings(--argc, argv+1, page, p, 0); } /* * Splice in (1) the interpreter's name for argv[0] * (2) (optional) argument to interpreter * (3) filename of shell script * * This is done in reverse order, because of how the * user environment and arguments are stored. */ p = copy_strings(1, &filename, page, p, 1); argc++; if (i_arg) { p = copy_strings(1, &i_arg, page, p, 2); argc++; } p = copy_strings(1, &i_name, page, p, 2); argc++; if (!p) { retval = -ENOMEM; goto exec_error1; } /* * OK, now restart the process with the interpreter's inode. */ old_fs = get_fs(); set_fs(get_ds()); if (!(inode=namei(interp))) { /* get executables inode */ set_fs(old_fs); retval = -ENOENT; goto exec_error1; } set_fs(old_fs); goto restart_interp; } brelse(bh); //代码段 数据段 bss段检测 if (N_MAGIC(ex) != ZMAGIC || ex.a_trsize || ex.a_drsize || ex.a_text+ex.a_data+ex.a_bss>0x3000000 || inode->i_size < ex.a_text+ex.a_data+ex.a_syms+N_TXTOFF(ex)) { retval = -ENOEXEC; goto exec_error2; } if (N_TXTOFF(ex) != BLOCK_SIZE) { printk("%s: N_TXTOFF != BLOCK_SIZE. See a.out.h.", filename); retval = -ENOEXEC; goto exec_error2; } if (!sh_bang) { p = copy_strings(envc,envp,page,p,0); p = copy_strings(argc,argv,page,p,0); if (!p) { retval = -ENOMEM; goto exec_error2; } } /* OK, This is the point of no return */ /* note that current->library stays unchanged by an exec */ if (current->executable) iput(current->executable); current->executable = inode; current->signal = 0; for (i=0 ; i<32 ; i++) { current->sigaction[i].sa_mask = 0; current->sigaction[i].sa_flags = 0; if (current->sigaction[i].sa_handler != SIG_IGN) current->sigaction[i].sa_handler = NULL; } for (i=0 ; i<NR_OPEN ; i++) if ((current->close_on_exec>>i)&1) sys_close(i); current->close_on_exec = 0; free_page_tables(get_base(current->ldt[1]),get_limit(0x0f)); free_page_tables(get_base(current->ldt[2]),get_limit(0x17)); if (last_task_used_math == current) last_task_used_math = NULL; current->used_math = 0; p += change_ldt(ex.a_text,page); p -= LIBRARY_SIZE + MAX_ARG_PAGES*PAGE_SIZE; p = (unsigned long) create_tables((char *)p,argc,envc); //加载各个段 current->brk = ex.a_bss + (current->end_data = ex.a_data + (current->end_code = ex.a_text)); current->start_stack = p & 0xfffff000; current->suid = current->euid = e_uid; current->sgid = current->egid = e_gid; eip[0] = ex.a_entry; /* eip, magic happens :-) */ eip[3] = p; /* stack pointer */ return 0; exec_error2: iput(inode); exec_error1: for (i=0 ; i<MAX_ARG_PAGES ; i++) free_page(page[i]); return(retval); }
目前的可执行文件加载要复杂的多, 但是基本原理差不多。
x86_64的ELF 结构如下
//ELF头信息 typedef struct { unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */ Elf64_Half e_type; /* Object file type */ Elf64_Half e_machine; /* Architecture */ Elf64_Word e_version; /* Object file version */ Elf64_Addr e_entry; /* Entry point virtual address */ Elf64_Off e_phoff; /* Program header table file offset */ Elf64_Off e_shoff; /* Section header table file offset */ Elf64_Word e_flags; /* Processor-specific flags */ Elf64_Half e_ehsize; /* ELF header size in bytes */ Elf64_Half e_phentsize; /* Program header table entry size */ Elf64_Half e_phnum; /* Program header table entry count */ Elf64_Half e_shentsize; /* Section header table entry size */ Elf64_Half e_shnum; /* Section header table entry count */ Elf64_Half e_shstrndx; /* Section header string table index */ } Elf64_Ehdr; //section信息 typedef struct { Elf64_Word sh_name; /* Section name (string tbl index) */ Elf64_Word sh_type; /* Section type */ Elf64_Xword sh_flags; /* Section flags */ Elf64_Addr sh_addr; /* Section virtual addr at execution */ Elf64_Off sh_offset; /* Section file offset */ Elf64_Xword sh_size; /* Section size in bytes */ Elf64_Word sh_link; /* Link to another section */ Elf64_Word sh_info; /* Additional section information */ Elf64_Xword sh_addralign; /* Section alignment */ Elf64_Xword sh_entsize; /* Entry size if section holds table */ } Elf64_Shdr; //符号表入口 typedef struct { Elf64_Word st_name; /* Symbol name (string tbl index) */ unsigned char st_info; /* Symbol type and binding */ unsigned char st_other; /* Symbol visibility */ Elf64_Section st_shndx; /* Section index */ Elf64_Addr st_value; /* Symbol value */ Elf64_Xword st_size; /* Symbol size */ } Elf64_Sym; //重定位信息 typedef struct { Elf64_Addr r_offset; /* Address */ Elf64_Xword r_info; /* Relocation type and symbol index */ } Elf64_Rel;
使用命令readelf -a main.o 查看elf信息得(x86_64平台):
ELF 头:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (可重定位文件)
Machine: Advanced Micro Devices X86-64
Version: 0x1
入口点地址: 0x0
程序头起点: 0 (bytes into file)
Start of section headers: 296 (bytes into file)
标志: 0x0
本头的大小: 64 (字节)
程序头大小: 0 (字节)
Number of program headers: 0
节头大小: 64 (字节)
节头数量: 12
字符串表索引节头: 9
节头:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040 //已编译程序的机器代码 目标文件从0开始 偏移量就是段的开始地址,size 段大小 Entsize如果段中持有表 表的入口地址
0000000000000015 0000000000000000 AX 0 0 4 Align 对齐方式
[ 2] .rela.text RELA 0000000000000000 00000548
0000000000000018 0000000000000018 10 1 8
[ 3] .data PROGBITS 0000000000000000 00000058 入口地址 00000058 长度8个字节 4字节对齐
0000000000000008 0000000000000000 WA 0 0 4
[ 4] .bss NOBITS 0000000000000000 00000060 未初始化段 不占字节 4字节对齐
0000000000000000 0000000000000000 WA 0 0 4
[ 5] .comment PROGBITS 0000000000000000 00000060
000000000000002d 0000000000000001 MS 0 0 1
[ 6] .note.GNU-stack PROGBITS 0000000000000000 0000008d
0000000000000000 0000000000000000 0 0 1
[ 7] .eh_frame PROGBITS 0000000000000000 00000090
0000000000000038 0000000000000000 A 0 0 8
[ 8] .rela.eh_frame RELA 0000000000000000 00000560
0000000000000018 0000000000000018 10 7 8
[ 9] .shstrtab STRTAB 0000000000000000 000000c8
0000000000000059 0000000000000000 0 0 1
[10] .symtab SYMTAB 0000000000000000 00000428
0000000000000108 0000000000000018 11 8 8
[11] .strtab STRTAB 0000000000000000 00000530 //符号表的符号串
0000000000000016 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), l (large)
I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
There are no section groups in this file.
本文件中没有程序头。
重定位节 '.rela.text' 位于偏移量 0x548 含有 1 个条目:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000a 000a00000002 R_X86_64_PC32 0000000000000000 swap - 4
重定位节 '.rela.eh_frame' 位于偏移量 0x560 含有 1 个条目:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0
The decoding of unwind sections for machine type Advanced Micro Devices X86-64 is not currently supported.
Symbol table '.symtab' contains 11 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS main.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 6
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 5
8: 0000000000000000 8 OBJECT GLOBAL DEFAULT 3 buf
9: 0000000000000000 21 FUNC GLOBAL DEFAULT 1 main
10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND swap
由elf信息我们试着在main.o 中找到buf的值。hexdump命令

偏移量58 机器为小端 4 字节对齐 我们可以看到最后8个字节 即是buf 的1 和 2.
详细说明一下符号表, 以main.o , swap.o为例:
Num: Value Size Type Bind Vis Ndx Name
8: 0000000000000000 8 OBJECT GLOBAL DEFAULT 3 buf 9: 0000000000000000 21 FUNC GLOBAL DEFAULT 1 main 10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND swap
8: 0000000000000000 8 OBJECT GLOBAL DEFAULT 3 bufp0 9: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND buf 10: 0000000000000008 8 OBJECT GLOBAL DEFAULT COM bufp1 11: 0000000000000000 59 FUNC GLOBAL DEFAULT 1 swap
Num在8之前的是本地符号供链接器使用,如static 全局变量只在本地使用。我们可以看到函数内部的局部变量不会在符号表的, 它是在栈中分配。 这里的Value是指符号的地址,对于可重定位的模块来说, value 是距离定义目标的节的起始位置的偏移:对于引用自其他模块的变量这里value 为0,将来链接时进行重定位。对于可执行文件来说该值是一个绝对运行地址。 size 是目标的大小, type 通常是数据或者函数, ABS 代表不该被重定位的符号, undef代表未定义的符号, 而common表示还未被分配位置的未初始化的数据。
链接器符号解析和重定位:
连接器将每个引用与它输入的可重定位目标文件的符号表中的一个确定符号定义联系起来, 如main中的swap引用和 swap.c 中的swap函数的定义; swap.c 中的buf引用和main.c 中buf的定义。对那些引用和定义都在同一模块中的本地符号的引用,符号解析是十分简单的。不过这里又牵涉到一个如何解析多处定义的全局符号问题,函数和已初始化的全局变量都是强符号,未初始化的全局变量是弱符号, 弱符号可能会造成很多的问题,造成程序中的隐藏bug。
静态库解析引用
静态库其实就是多个目标文件的打包,在符号解析阶段, 链接器从左到右按照它们在gcc 或ld 命令出现的顺序扫描可重定位文件,在扫描过程中链接器维持一个可重定位目标文件的集合E, 这个集合中的模块会被合并起来形成可执行文件(表示最终形成可执行文件的入口 即main函数所在的模块);为引用了但是模块中没有定义的符号建立集合U; 为已经定义的符号建立集合D。
例如 gcc -static main.o liba.a libb.a:
首先解析main.o 文件 发现是入口处, 就将它加入到集合E, 然后修改引用U 和定义D集合,对于main模块应该引用较多, 那么将引用其他模块的变量和函数加入到U集合 -------------> 接下来解析第二个存档文件lib.a。在lib.a中就会寻找匹配U中未解析符号但是在lib.a中定义的符号,例如,如果lib.a中定义了U中一个未定义的符号m, 就将m 加入到E中待将来组成可执行文件并修改UD集合。 对之后的所有文件都反复执行这个过程, 直到UD都不再变化 最后U 一定为空,否则不会形成可执行文件。这里指出的是目前gcc 默认选项的话会将所有定义模块加入到E中,不管main中是否用到了这个模块,gcc 编译和链接时都相关参数控制。-ffunction-sections, -fdata-sections会使compiler为每个function和data item分配独立的section。 --gc-sections会使ld删除没有被使用的section(具体没有试验过)。
静态库重定位:
经过了符号解析,它就把符号引用和符号定义联系起来,如 main.o 中swap的引用找到了swap.o 中swap的定义, swap符号定义被放到了E集合中,重定位就是对E集合中的引用和定义重新组成可执行文件。被定义的符号大小可以存原来的符号表读取,可执行文件也包含符号表,对E集合中的符号重新分配运行地址形成新的符号表。重定位包含两步: 1. 将所有类型相同的节拼接在一起,例如 来自输入的模块的.data 节全部合并成一个节, 这个节成为输出可执行目标文件的.data 节, 形成可执行文件并将地址修改为可运行地址---虚拟地址, 这时代码中的call jmp 等调转指令的目标地址还不是确定地址所以需要第二步。2. 重定位节中的符号引用。链接器修改代码节和数据节中对每个符号的引用, 使得它们指向正确的运行时地址。此时链接器依赖于重定位表目。例如main.o 中的swap表目:
重定位节 '.rela.text' 位于偏移量 0x548 含有 1 个条目:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000a 000a00000002 R_X86_64_PC32 0000000000000000 swap - 4
offset是指相对可重定位text 或data段的偏移量,当汇编器生成一个目标模块时, 它并不知道数据和代码最终将存放在存储器中的什么位置, 它也不知道这个模块引用其他模块的函数或者全局变量的位置。所以就生成了一个重定位表 告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。这个重定位表就告诉在链接器需要重定位的地方。如图:
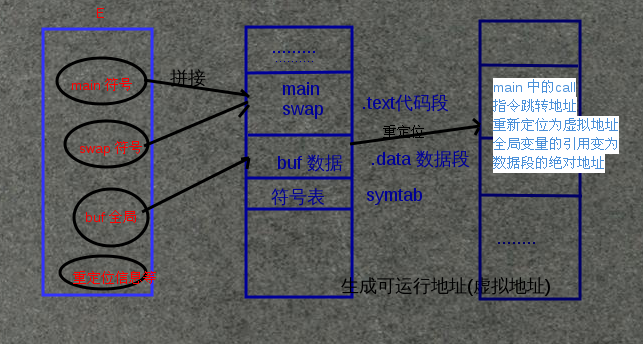
这里将最后生成的可执行文件反编译objdump -S main
00000000004004f0 <main>: 4004f0: 55 push %rbp 4004f1: 48 89 e5 mov %rsp,%rbp 4004f4: b8 00 00 00 00 mov $0x0,%eax 4004f9: e8 0a 00 00 00 callq 400508 <swap> 4004fe: b8 00 00 00 00 mov $0x0,%eax 400503: 5d pop %rbp 400504: c3 retq 400505: 0f 1f 00 nopl (%rax) 0000000000400508 <swap>: 400508: 55 push %rbp 400509: 48 89 e5 mov %rsp,%rbp 40050c: 48 c7 05 31 0b 20 00 movq $0x601030,0x200b31(%rip) # 601048 <bufp1> 400513: 30 10 60 00 400517: 48 8b 05 1a 0b 20 00 mov 0x200b1a(%rip),%rax # 601038 <bufp0> 40051e: 8b 00 mov (%rax),%eax 400520: 89 45 fc mov %eax,-0x4(%rbp) 400523: 48 8b 05 0e 0b 20 00 mov 0x200b0e(%rip),%rax # 601038 <bufp0> 40052a: 48 8b 15 17 0b 20 00 mov 0x200b17(%rip),%rdx # 601048 <bufp1> 400531: 8b 12 mov (%rdx),%edx 400533: 89 10 mov %edx,(%rax) 400535: 48 8b 05 0c 0b 20 00 mov 0x200b0c(%rip),%rax # 601048 <bufp1> 40053c: 8b 55 fc mov -0x4(%rbp),%edx 40053f: 89 10 mov %edx,(%rax) 400541: 5d pop %rbp 400542: c3 retq 400543: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1) 40054a: 00 00 00 40054d: 0f 1f 00 nopl (%rax)
再比对一下main.o的反汇编
0000000000000000 <main>: 0: 55 push %rbp 1: 48 89 e5 mov %rsp,%rbp 4: b8 00 00 00 00 mov $0x0,%eax 9: e8 00 00 00 00 callq e <main+0xe> e: b8 00 00 00 00 mov $0x0,%eax 13: 5d pop %rbp 14: c3 retq
call 指令是一个跳转指令 e8 为call 指令。 这里可以看到main.o 中指令callq swap 字节码e8 00 00 00 00 这里没有swap的定义,所以这边跳转偏移量为0,重定位即是把它赋予一个真正的值。更改跳转指令偏移量和引用全局变量地址是生成运行地址之后才做的,由之前目标文件的各个符号, 段的长度,和重定位符号表,生成运行地址后就不难进行重定位。
我们可以看到main 可执行文件中 call 之后相对偏移量已经变为a值。 4004f9: e8 0a 00 00 00 callq 400508 <swap> 后面的a表示跳转位移量 即跳转到的地址是PC + a PC(CS:IP) 是call指令的下一条指令地址即 4004fe。 4004fe + a = 400508 正是swap 函数的地址 (相对寻址修正)。 对于全局变量则是绝对地址修正,将数据引用变成数据段相应变量的绝对地址。
以上就是静态库符号解析和重定位过程,从上述过程来说整个过程并不复杂。只是这里我们可以看到链接过程中拼接和重定位,把所有模块都拼接到一个可执行文件中,那么这个可执行文件的size就会变的很大,当模块数量及复杂度再提升时那可想而知,而且带来的令一个问题是,一旦一个模块中有一个很小的改动 那么最后都要重新拼接重定位,效率会变得很低。那么这就是动态库引入的原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号