
1.下载官网的YOLOv3,打开终端输入:git clone https://github.com/pjreddie/darknet
下载完成之后,输入:cd darknet,然后再输入:make,
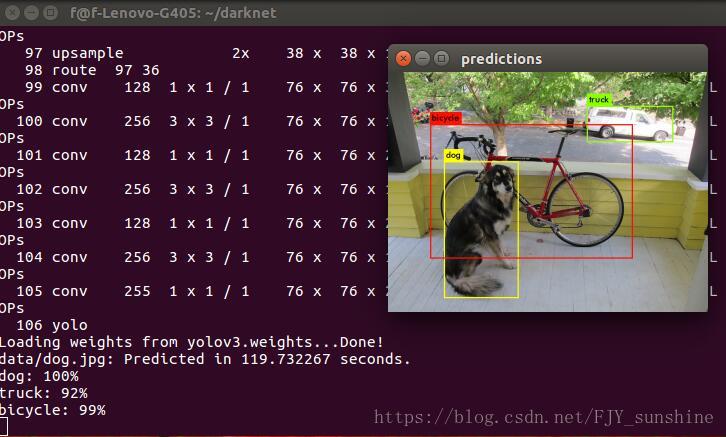
make完成之后,下载预先训练的weights文件,通过在终端里输入:wget https://pjreddie.com/media/files/yolov3.weights,然后就可以运行检测器了,在终端里输入:./darknet detect cfg/yolov3.cfg yolov3.weights data/doa.jpg(这条命令得在darknet目录下运行),会得到这样的结果:
2.开始训练自己的数据
(1)在darknet目录下新建一个voc命名的文件夹,voc文件夹里新建VOCdevkit文件夹,在VOCdevkit文件夹里新建VOC2018文件夹,在VOC2018文件夹下新建Annotations,ImageSets,JPEGImages,SegmentationClass,SegmentationObject这五个文件夹,在ImageSets文件夹下新建Main文件夹。其中Annotations里存放所有标注了图片的xml文件,JPEGImages文件夹里存放所有的图片,Main中放train.txt和test.txt,至于SegmentationClass,SegmentationObject这两个文件夹我没有用到。
(2)图片重命名,使用VOC的命名方式,这种:000012。重命名代码如下,根据自己的路径修改后就可以用:
# -*- coding: utf-8 -*-
import os
path = "/home/f/image/Aft_Original_Crack_DataSet_Second"
filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
count=0
for file in filelist:
print(file)
for file in filelist: #遍历所有文件
Olddir=os.path.join(path,file) #原来的文件路径
if os.path.isdir(Olddir): #如果是文件夹则跳过
continue
filename=os.path.splitext(file)[0] #文件名
filetype=os.path.splitext(file)[1] #文件扩展名
Newdir=os.path.join(path,str(count).zfill(6)+filetype) #用字符串函数zfill 以0补全所需位数
os.rename(Olddir,Newdir)#重命名
count+=1
(3)标注图片,我使用的是labelImg。下载网址:https://github.com/tzutalin/labelImg
下载完成之后,再根据这个网址里面的安装方法进行安装即可(我在执行最后这条语句:python labelImg.py时报错了,然后加上sudo python labelImg.py执行就好了),然后就可以开始标注图片了,标注方法参见:https://blog.csdn.net/cgt19910923/article/details/80211220。
(4)生成train.txt和test.txt,里面的内容是这样的:000606,没有任何后缀名,我的生成后是用于测试的图片会在train.txt里面显示为001234.j,同理用于训练的图片在test.txt里也会这样显示,我们此时只需把这两个.txt文件里的所有.j删除即可,否则后面会报错。Python代码如下,根据自己的路径以及照片数量修改后就可以用:
# -*- coding: utf-8 -*-
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/f/darknet/voc/VOCdevkit/VOC2018/JPEGImages/'#地址是所有图片的保存地点
dest='/home/f/darknet/voc/VOCdevkit/VOC2018/ImageSets/Main/train.txt' #保存train.txt的地址
dest2='/home/f/darknet/voc/VOCdevkit/VOC2018/ImageSets/Main/test.txt' #保存test.txt的地址
file_list=os.listdir(source_folder) #赋值图片所在文件夹的文件列表
train_file=open(dest,'a') #打开文件
test_file=open(dest2,'a') #打开文件
for file_obj in file_list: #访问文件列表中的每一个文件
file_path=os.path.join(source_folder,file_obj)
#file_path保存每一个文件的完整路径
file_name,file_extend=os.path.splitext(file_obj)
#file_name 保存文件的名字,file_extend保存文件扩展名
file_num=int(file_name)
#把每一个文件命str转换为 数字 int型 每一文件名字都是由四位数字组成的 如 0201 代表 201 高位补零
if(file_num<1000): #保留1000个文件用于训练
#print file_num
train_file.write(file_name+'\n') #用于训练前149个的图片路径保存在train.txt里面,结尾加回车换行
else :
test_file.write(file_name+'\n') #其余的文件保存在test.txt里面
train_file.close()#关闭文件
test_file.close()
(5)下载和修改voc_label.py
下载:wget https://pjreddie.com/media/files/voc_label.py
修改:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2018', 'train'), ('2018', 'test')] #根据自己的数据修改
classes = ["bridgecrack"] #根据自己的类别进行修改
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('/home/f/darknet/voc/VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) #根据自己的路径修改
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('/home/f/darknet/voc/VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() #根据自己的路径修改
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
运行:在终端里输入:python voc_label.py 之后会在Main文件夹下生成2018_train.txt和2018_test.txt,以及文件夹VOCdevkit(这里用到了之前main下的train和test文本文件,使得xml和jpg文件一一对应,并且生成最后的图片路径。)
(6)下载预训练模型:在终端里输入:wget https://pjreddie.com/media/files/darknet53.conv.74
(7)修改cfg/voc.data
classes= 1 #根据自己的类型修改
train = /home/f/darknet/voc/2018_train.txt #根据自己的路径修改
valid = /home/f/darknet/voc/2018_test.txt #根据自己的路径修改
names = /home/f/darknet/data/voc.names #根据自己的路径修改
backup = backup
(8)修改data/voc.names
里面把自己的类别一一列出就好,这样子的:
car
cat
(9)修改cfg/yolov3-voc.cfg
一共修改三处filters,classes,找到每个yolo的上面的filters,以及yolo下面的classes修改为自己的即可,修改根据:calsses是分类数,filters=3*(classes+5),random=0即关闭多尺度训练。
具体每个参数的意思,参见这里:https://blog.csdn.net/qq_33485434/article/details/80907040
(10)开始训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
训练时,我的报cannot load image的错误,因为我的2018_train.txt里面的图片路径下没有照片,所以我就按里面的路径吧我的照片移动到了相应的路径下,就没有错误了。
(11)测试数据
在终端里输入:./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_600.weights data/001335.jpg
转自:
---------------------
作者:FJY_sunshine
来源:CSDN
原文:https://blog.csdn.net/FJY_sunshine/article/details/82590440
版权声明:本文为博主原创文章,转载请附上博文链接!
